この記事の目的
こんにちは!
現在、業務でビッグデータ解析を行っていますが、LightGBMを使って
「どいつ(特徴量)が、こいつ(目的変数)に一番相性がいいかなぁ~???」
と重要度のインパクトを調べていたんですけど、うまくいかなかったので
「一旦、目的変数と全特徴量の相関係数出すか。」
という感じでビッグデータで大量の相関係数を算出しました。
今回はその過程を記録したいと思います。
データについて
どのようなデータを扱うかは言えませんが、データ量としてはおよそ52万行×2500列ほどのデータ量(これってビッグデータと言えますよね?(震え声))
このデータの相関係数をすべて算出するわけですが、今回扱うデータは時系列データですので
「過去のデータとの相関係数も見てみたいな。」
ということで、全特徴量に対して1分~5分の遅延をとったラグ特徴量も追加して、合計で1万2千個ほどの相関係数を算出します。
1つの特徴量に対して5つの特徴量を新たに算出するので、6倍にデータ量が膨れ上がります。
実際にプログラムを書いていく
今回はChatGPTに作成してもらいました。
前回投稿した記事にpythonのプログラムを精度よく出力させるためのプロンプトを紹介していますので良ければ見てみてください。
今回作成してもらう機能は以下の通り
- csvファイルを読み込み、目的変数とそれ以外の特徴量との相関係数を算出したい。
- 時系列データとして1列目に目的変数、2列目以降のカラムに特徴量が入力されている。
- 目的変数以外のカラムについて、200列ずつ分割してリスト化したい。
- 各リストを1~5行ずらしたラグ特徴量を作成し、各リストのカラムに追加したい。
- リストに格納されたデータフレームを横方向に結合したい。
- 目的変数に対して、各特徴量の相関係数を算出したい。
- 降順ソートし、どの特徴量が最も相関が高いか評価したい。
データ量が多すぎるので、計算負荷を考慮してforループにより負荷分散させようとしました。
ということでChatGPTにプロンプトとして渡した結果がこちら↓
import pandas as pd
# 1. CSVファイルを読み込む
data = pd.read_csv('your_data.csv')
# 2. 目的変数とそれ以外の特徴量を分ける
target_column = features['target']
features = features.drop(columns=['target'])
# 3. 特徴量を200列ずつに分割してリスト化
num_splits = (features.shape[1] - 1) // 200 + 1
feature_lists = [features.iloc[:, i:i+200] for i in range(1, features.shape[1], 200)]
# 4. ラグ特徴量を作成し、各リストのカラムに追加
lagged_feature_lists = []
lag_steps = [1,2,3,4,5]
for feature_list in feature_lists:
lagged_features = pd.concat([feature_list.shift(i) for i in range(lag_steps)], axis=1)
lagged_feature_lists.append(lagged_features)
# 5. データフレームを横方向に結合
lagged_features_concatenated = pd.concat(lagged_feature_lists, axis=1)
# 6. 目的変数と各特徴量の相関係数を算出
correlations = lagged_features_concatenated.corrwith(target_column)
# 7. 相関係数と特徴量名を結合してDataFrame作成
correlation_data = pd.DataFrame({'Feature': lagged_features_concatenated.columns, 'Correlation': correlations})
# 8. 相関係数を降順ソート
sorted_correlation_data = correlation_data.sort_values(by='Correlation', ascending=False)
# 9. 結果をCSVファイルに出力
sorted_correlation_data.to_csv('correlation_results.csv', index=False, encoding='utf-8-sig)
負荷分散させたのに、相関係数を算出する前にリストを結合してしまってますね。
相関係数の算出には少し時間がかかりました(結合しなくても時間はかかりそうな気もしなくはない)。
あとからcsvファイルとして出力させたいなどの追加プロンプトはありましたが、今回は割愛します。
# 3. 特徴量を200列ずつに分割してリスト化
num_splits = (features.shape[1] - 1) // 200 + 1
feature_lists = [features.iloc[:, i:i+200] for i in range(1, features.shape[1], 200)]
この部分なぜこのような式で分割しているのか気になったので聞いてみました。
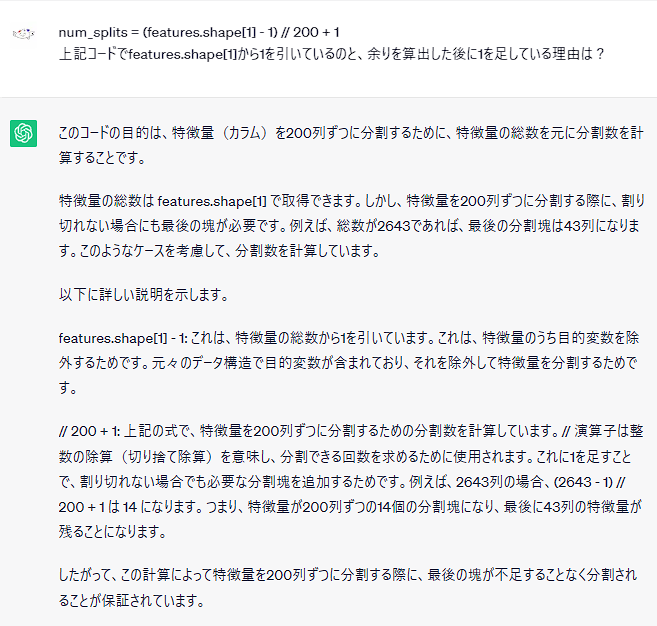
たしかに言っていることはわかるけども!!!
その発想がすぐに思い浮かばないあたり、わたしもまだまだですね(ChatGPTに出力させている奴の言葉)。
まあ、とにかく勉強になった!!!!!!
一応確認
同僚と話していると、
「正規化したら結果って変わんの?」
はい。正規化します。
from sklearn.preprocessing import StandardScaler
# 正規化(Zスコア正規化)
scaler = StandardScaler()
normalized_features = scaler.fit_transform(data)
# 正規化後のデータをデータフレームに変換
data = pd.DataFrame(normalized_features, columns=data.columns)
上記コードをcsvファイルを読み込んだあとに入れるだけです。
まあ、結果として正規化しても相関係数に影響はゼロだったんですけどね…
今回はZスコア正規化により正規化をおこないました。
これはデータの平均を0、標準偏差が1になるようにデータを変換します。
データ解析、統計学等の際によく用いられる正規化法ですので覚えておくといいでしょう。
他にもMin‐Maxスケーリングといった0~1の間でスケールを合わせる正規化法もあります(こっちが一般的?)が、
今回はZスコア正規化でやってみました。
どちらも知っておくといいかもしれませんね!
まとめ
ということでビッグデータ解析の一部である、相関係数を算出しました。
私自身、1万を超える相関係数を算出したことがないので、もっと壮大なプログラムになるのかなと思い、
「1か月くらいかかるかも…」
とマージンを取ったうえで実装したところ、30分で終わってしまいました。
ということで1か月仕事がなくなったわけなので、データ解析や機械学習について勉強しようかなと思います!!!
それでは!!!