今回は、前回までのYahooニュースをスクレイピングした結果を、
Googleスプレッドシートに連携することに挑戦します。
※環境:MacOS Catalina Python3.7.3
Pythonでのウェブスクレイピング学習のロードマップ
(1)ローカルでとりあえず目的のブツのスクレイピングに成功する。
(2)ローカルでスクレイピングした結果をGoogleスプレッドシートに連携する。 ←いまココ
(3)ローカルでcron自動実行を行う。
(4)クラウドサーバー上での無料自動実行に挑戦する。(Google Compute Engine)
(5)クラウド上で、サーバーレスでの無料自動実行に挑戦する。(たぶんCloud Functions + Cloud Scheduler)
GoogleスプレッドシートをPythonで扱うにあたっての事前準備
Googleスプレッドシートを扱うにあたっては、GoogleAPIを介してスプレッドシートのアクセス権を認証する必要があり、この手順ではGCP(Google Cloud Platform)への登録が必要となります。
(他のやり方があるかどうかはわかりません。)
GCPへの登録については、こちらが参考になるかと思います。
https://qiita.com/Brutus/items/22dfd31a681b67837a74
GCPには「Always Free枠」と、「登録から12ヶ月間300$の無料クレジット枠」がありますが、これから行うことは全てAlways Free枠で事足ります。
手順:
(1)GCP登録
(2)プロジェクトの作成
(3)GCPコンソールでのAPI登録
(4)GCPコンソールでのサービスアカウント作成と秘密鍵(JSON形式)のダウンロード
(5)Googleドライブ上のスプレッドシートに対して(4)で作成のサービスアカウントのアクセス権を付与
手順を一つずつ見ていきますが、その前に。
サービスアカウントってなんぞや?
サービス アカウントは、ユーザーではなく、アプリケーションや仮想マシン(VM)インスタンスで使用される特別なアカウントです。 アプリケーションはサービス アカウントを使用して、承認された API 呼び出しを行います。
引用:https://cloud.google.com/iam/docs/service-accounts?hl=ja
つまり、アプリからGCPで登録したサービスアカウントのcredensialsを使用してGoogleAPIを認証して、さらにspreadsheets側でもユーザーとしてサービスアカウントを登録しておくことで、認証されたAPI経由でspreadsheetsにアクセスできる仕組みです。
今回のPGMでは、以下GCP英語ドキュメントの
Preparing to make an authorized API call
に沿って、scopeとサービスアカウントの秘密鍵認証ファイル(JSON形式)を指定することで、APIを認証します。scopeでは何のAPIを認証するのか指定します。
https://developers.google.com/identity/protocols/oauth2/service-account?hl=ja#python
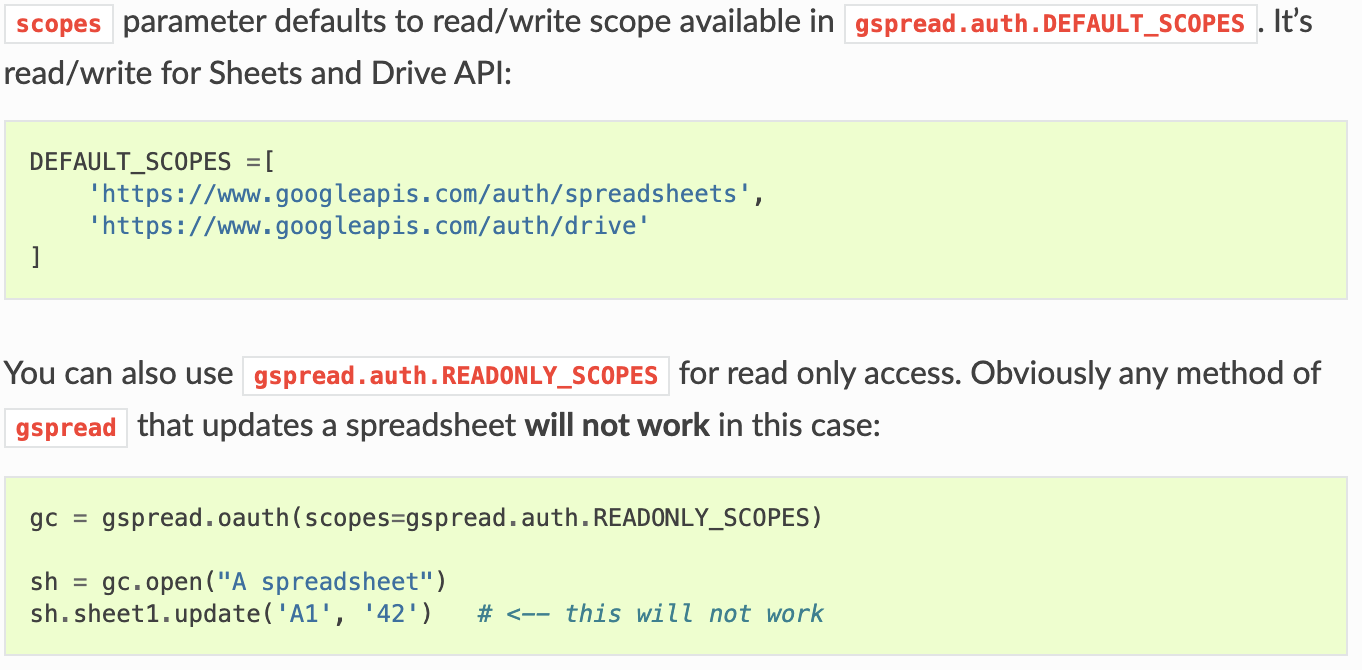
gspread API Reference
スプレッドシートの操作にあたっては、gspreadという外部ライブラリを使います。
gspreadのリファレンスはこちら。
https://gspread.readthedocs.io/en/latest/api.html?highlight=gspread.authorize
gspreadでは、APIリファレンスに従って、gspread.authorizeメソッドでcredentialsを指定することでAPIにログインします。
gspread.authorize(credentials)
# Login to Google API using OAuth2 credentials.
また、上でも説明したscopeはドキュメントにある通り以下のように設定していますが、
設定しなくてもDEFAULT_SCOPESが同じ内容なので、あえてscopeを設定しなくても動くことは動きます。ちなみに書き込みが不要の場合は、READONLYのSCOPEもあるようです。
ようやく手順詳細
GCP登録
先ほどご紹介したサイトをご参照。(※無料枠での使用であってもクレジットカードの登録は必要です。)
https://qiita.com/Brutus/items/22dfd31a681b67837a74
Googleアカウントの2段階認証も有効にしましょう。
(昨今、ドコモ口座問題を筆頭に世知辛い世の中ですので。。。)
プロジェクトの作成
GCPコンソールからでも、CloudSDKをインストールしてローカルからのgcloudコマンドからでも可能です。
gcloud projects create プロジェクト名
コンソールで作った場合、自動で請求先アカウントが設定されますが、
gcloudコマンドの場合は設定されないようなので、コンソールで別途設定が必要です。
GCPコンソールでのAPI登録
GCPコンソールから、[APIとサービス] > [ライブラリ]から、2つのAPIを有効化します。
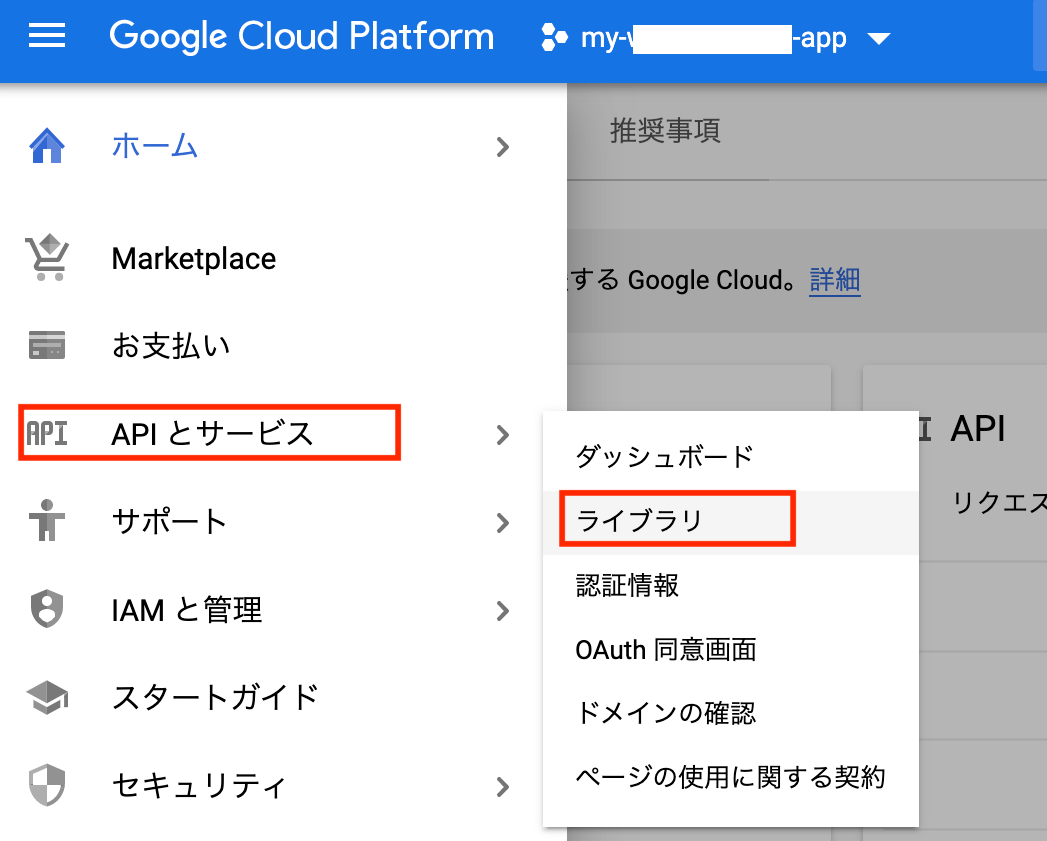
drive等で検索して、「Google Drive API」を追加。
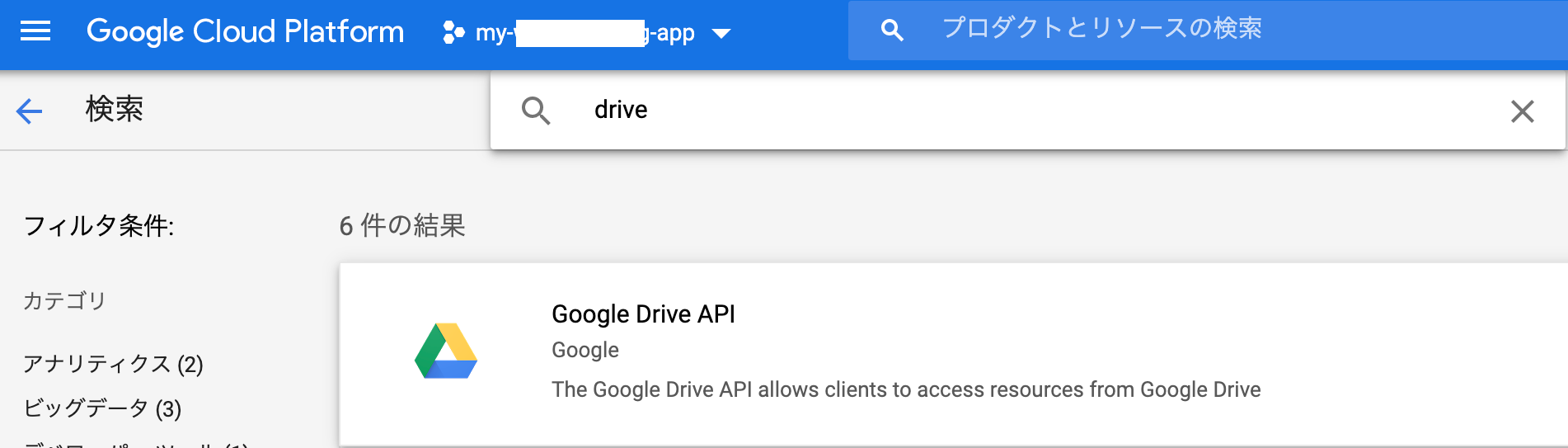
sheet等で検索して、「Google Sheets API」を追加。

APIが有効かどうかは、ダッシュボードでも確認ができますし、CLOUD SHELLのターミナル上で「gcloud services list」コマンドを叩いても確認できます。
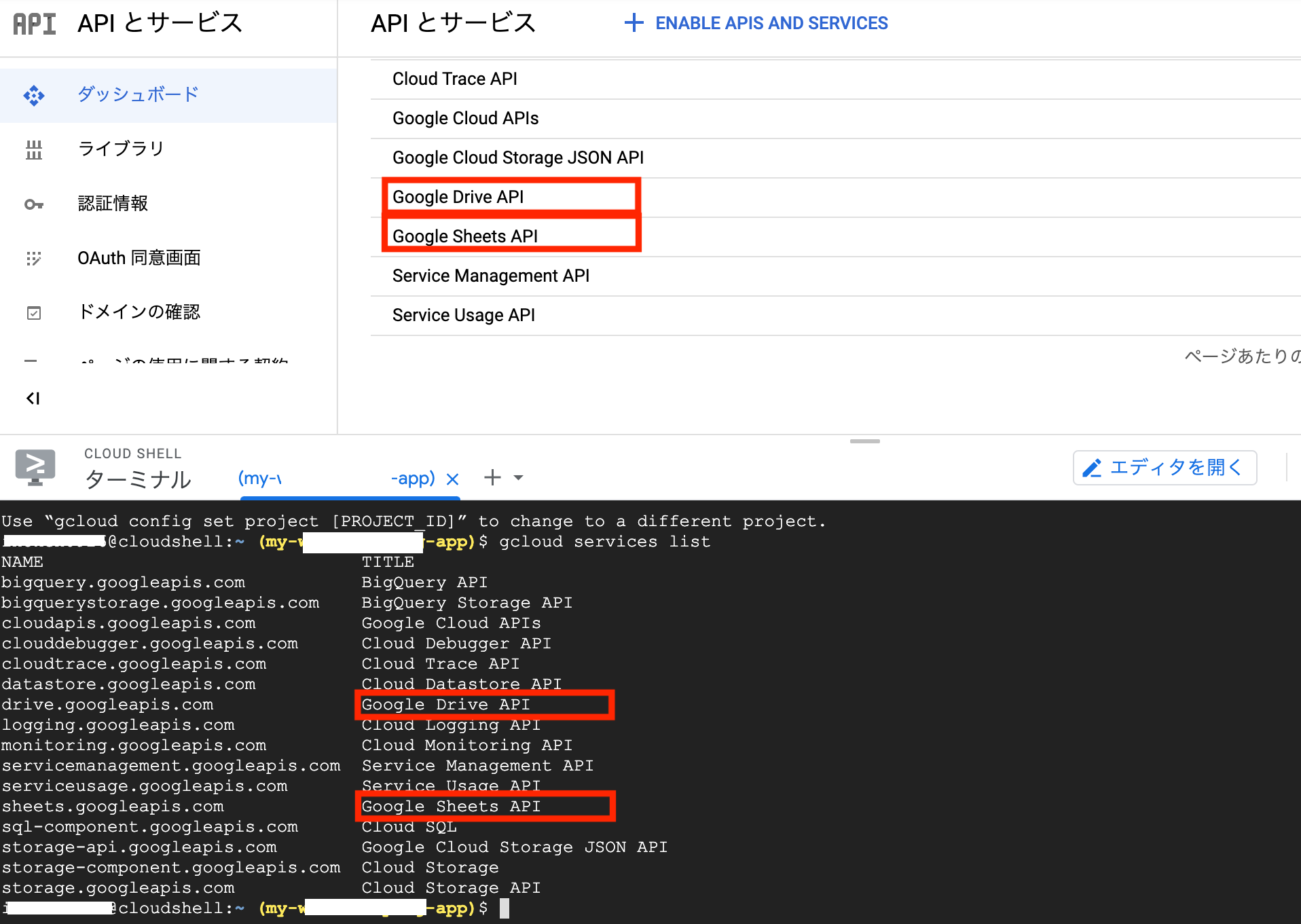
尚、Google Sheets APIは、100秒あたり500回の書き込み制限があります。
何もしなくても意外と動きはもっさりですが、loop書き込み時に一応sleepの設定はしましょう。

GCPコンソールでのサービスアカウント作成と秘密鍵(JSON形式)のダウンロード
APIとサービス > 認証情報 > 認証情報を作成 からサービスアカウントを作成。
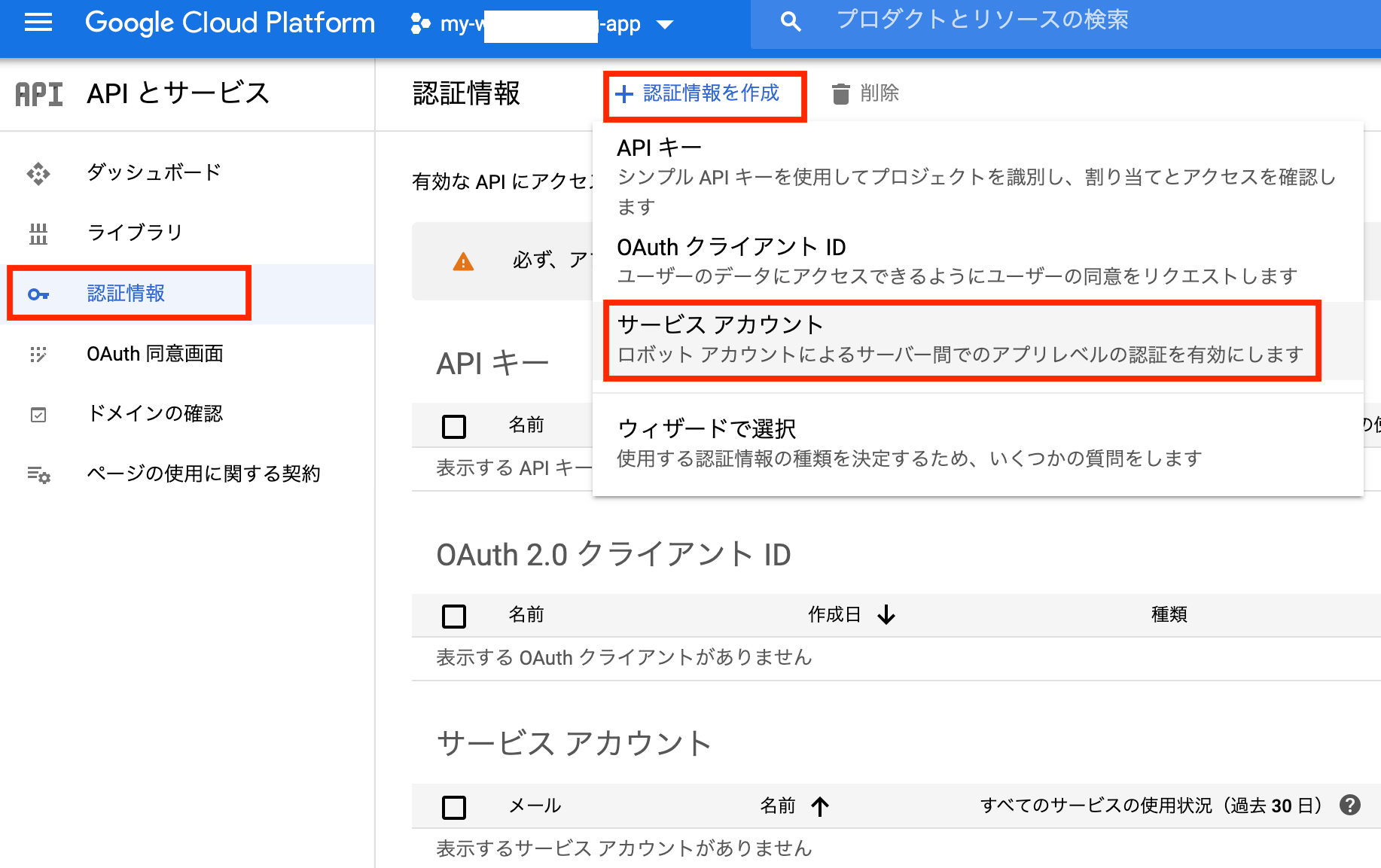
「サービスアカウント名」と「サービスアカウントの説明」を入力。
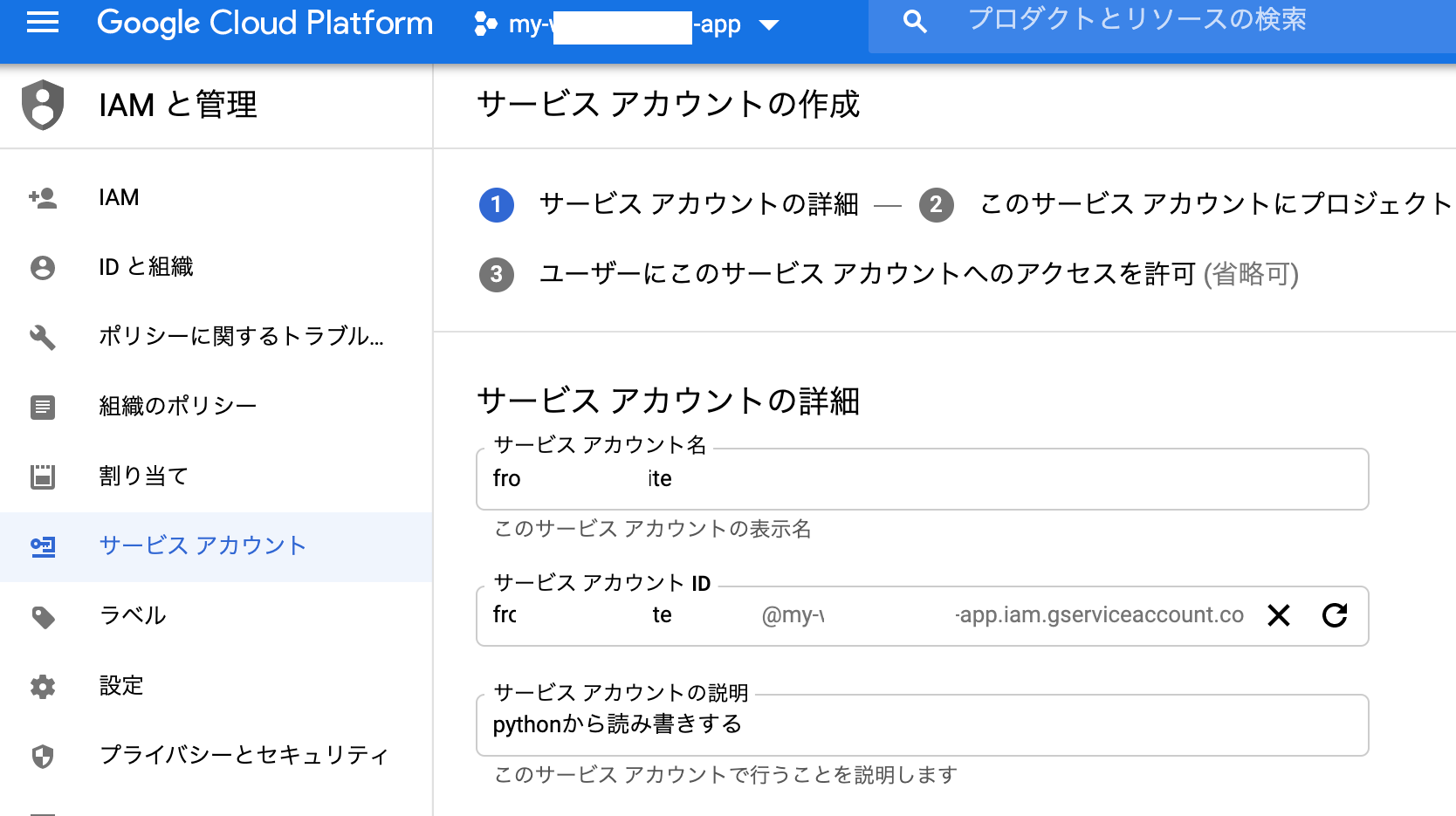
サービスアカウントの権限を設定します。
(赤枠の設定は、プロジェクトの全リソースにアクセスできる権限ですが、さらに限定する方法がわからないので、このまま。。。)
※追記:このサービスアカウントの目的はGoogleスプレッドシートへの書き込みのみ。Googleスプレッドシートへの書き込みはgspreadで認証するし、GCPリソースとは無関係。よってproject参照権限でいけるであろうとの考えのもと、参照権限のみで試したところ問題なく稼働しました。よって参照権限のみの方が安全と思われます。
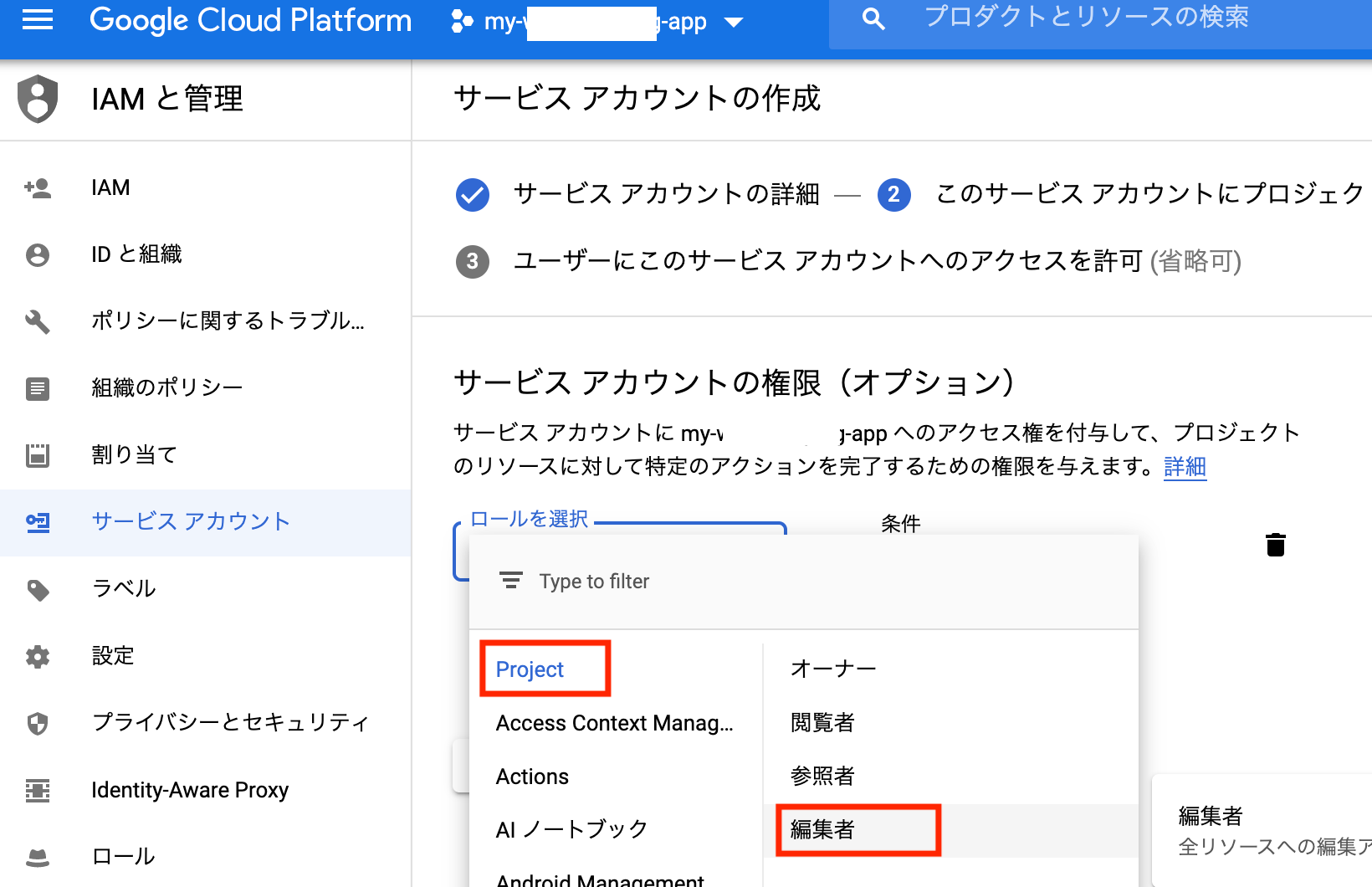
サービスアカウントの秘密鍵を作成。
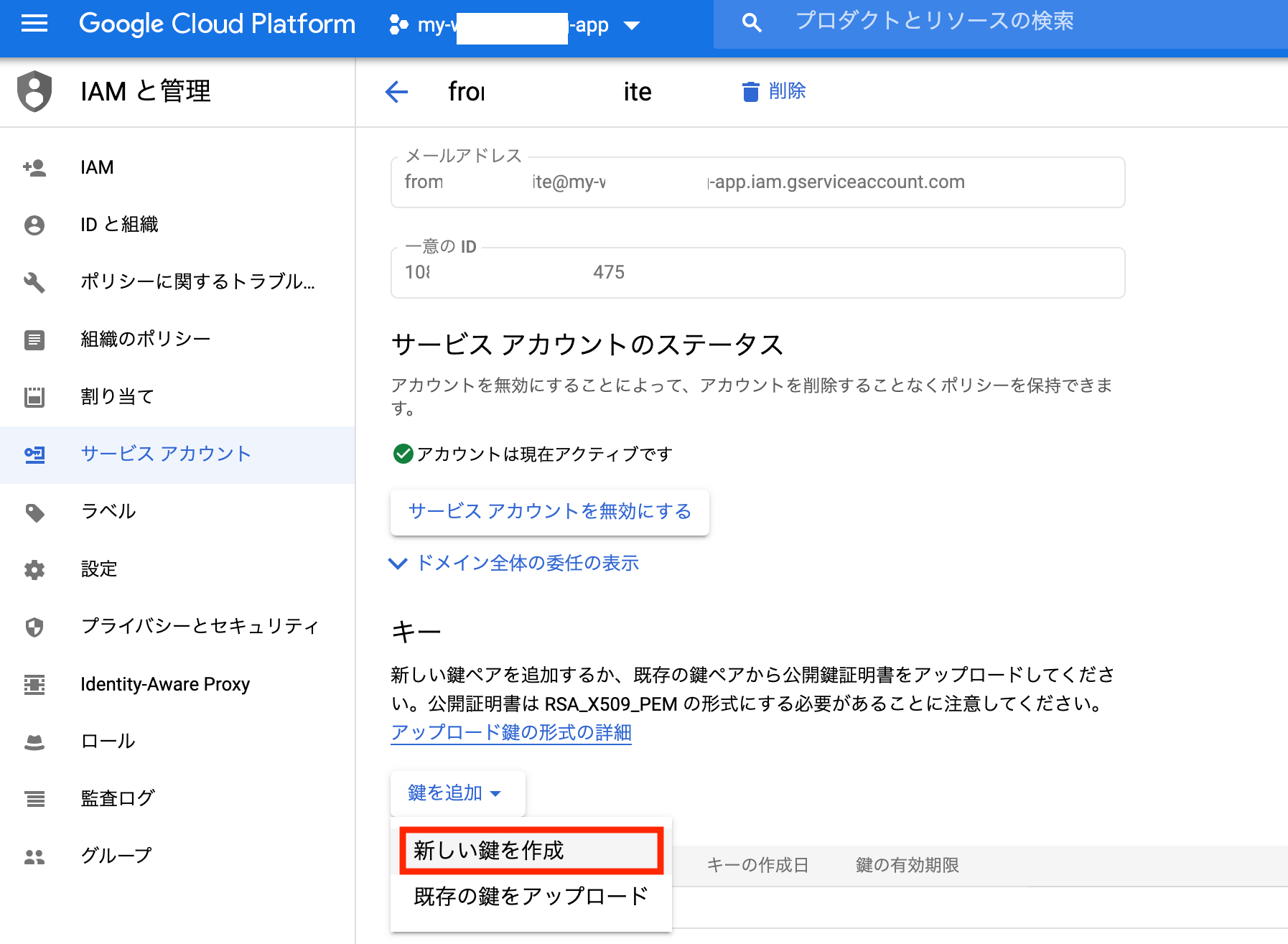
鍵のダウンロードファイルをJSON形式で作成。

ローカルにダウンロード。
ダウンロードしたファイルは、スクレイピング用のpyファイルと同じディレクトリに保存します。

Googleドライブ上のスプレッドシートに対して(4)で作成のサービスアカウントのアクセス権を付与
Googleドライブから、スクレイピング用のスプレッドシートを作成して、共有ボタンをクリックします。
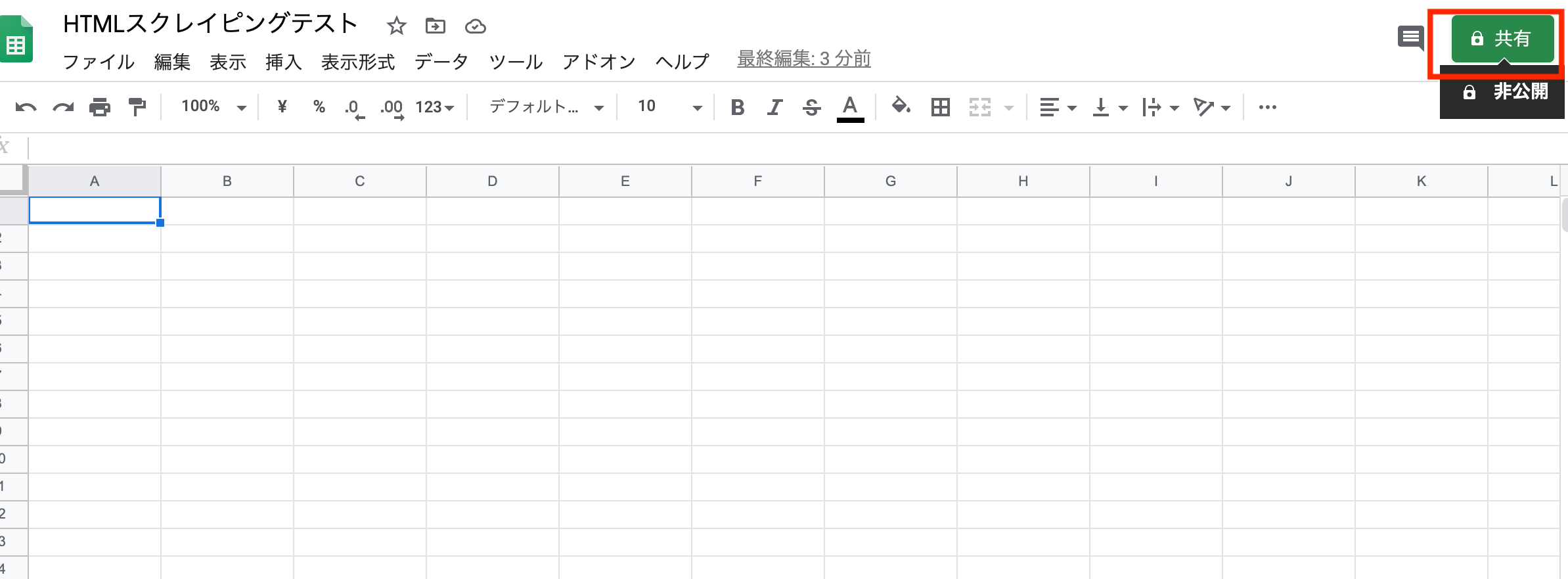
ダウンロードしたJSONファイルを開いて、"client_email"のメールアドレスを確認し、共有アカウントに、そのアドレスを設定します。

はい、ようやく準備完了です。
サンプルPGM
# PythonでYahoo!JAPANニュースのトップをスクレイピングしてGoogleスプレッドシートに展開する
# 参考サイト:https://hashikake.com/scraping-python
import requests
from bs4 import BeautifulSoup
import re
import gspread
from oauth2client.service_account import ServiceAccountCredentials
from datetime import datetime
import sys
from time import sleep
def get_gspread_book(secret_key, book_name):
scope = ['https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive']
#jsonファイルで認証情報設定
credentials = ServiceAccountCredentials.from_json_keyfile_name(secret_key, scope)
gc = gspread.authorize(credentials) #認証情報を使用してGoogleAPIにログイン
book = gc.open(book_name) #ファイル名を指定してGoogleスプレッドシートを開く
return book #開いたGoogleスプレッドシートを戻り値に指定
# requestsを利用してWEBサイトの情報をダウンロード
url = 'https://news.yahoo.co.jp/'
response = requests.get(url)
# BeautifulSoup()に取得したWEBサイトの情報とパーサー"html.parser"を渡す
soup = BeautifulSoup(response.text, "html.parser")
# href属性の中で"news.yahoo.co.jp/pickup"が含まれているもののみ全て抽出
elems = soup.find_all(href = re.compile("news.yahoo.co.jp/pickup"),limit=8)
# jsonファイルとbook名でspreadsheetをopenする
secret_key = '/Users/●●●/git-repository/env2/my-web-●●●.json'
book_name = 'HTMLスクレイピングテスト'
sheet_name = 'シート1'
sheet = get_gspread_book(secret_key, book_name).worksheet(sheet_name)
# spreadsheetの最終行を取得
values1 = sheet.col_values(1) #列の情報をまとめてlistに取得
lastrow1 = len(values1) #listの長さ=行数
# soup結果listをspreadsheetに反映する
# 写真付きの最後の1要素はエラーとなるのでエラ〜ハンドリングを行う
for elem in elems:
lastrow1 += 1
try:
sheet.update_acell('B' + str(lastrow1), elem.contents[0])
except:
print('エラーが発生しました')
print(elem.attrs['href'])
else:
datetimestr = datetime.now().strftime("%Y/%m/%d %H:%M:%S")
sheet.update_acell('A' + str(lastrow1), datetimestr)
sheet.update_acell('B' + str(lastrow1), elem.contents[0])
sheet.update_acell('C' + str(lastrow1), elem.attrs['href'])
sleep(2)
print(datetimestr,'スクレイピングを終了しました。')
import
gspread:Google SpreadSheetsを扱うためのライブラリ
oauth2client:主にGoogle API関連のリソースとのやりとりを行うためのライブラリ
pip install gspread
pip install oauth2client
実装のポイント
APIの認証
関数"get_gspread_book"として定義
上で説明したscopeとcredensialsを設定し、APIを認証してスプレッドシートをopenして、スプレッドシートインスタンスを返す関数。
※この関数はまにゃpyさんのサイト
https://hashikake.com/scraping-python
を存分に参考にさせていただきました。
関数内で使われている、スプレッドシートインスタンスのopenのメソッドですが、3種類あります。
今回はシート名でopenを使います。
open(title)
例:gc.open('My fancy spreadsheet')
open_by_key(key)
例:gc.open_by_key('0BmgG6nO_6dprdS1MN3d3MkdPa142WFRrdnRRUWl1UFE')
open_by_url(url)
例:gc.open_by_url('https://docs.google.com/spreadsheet/ccc?key=0Bm...FE&hl')
def get_gspread_book(secret_key, book_name):
scope = ['https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive']
#jsonファイルで認証情報設定
credentials = ServiceAccountCredentials.from_json_keyfile_name(secret_key, scope)
gc = gspread.authorize(credentials) #認証情報を使用してGoogleAPIにログイン
book = gc.open(book_name) #ファイル名を指定してGoogleスプレッドシートを開く
return book #開いたGoogleスプレッドシートを戻り値に指定
get_gspread_book関数に引数を渡す部分
# jsonファイルとbook名でspreadsheetをopenする
secret_key = '/Users/●●●/git-repository/env2/my-web-●●●.json'
book_name = 'HTMLスクレイピングテスト'
sheet_name = 'シート1'
sheet = get_gspread_book(secret_key, book_name).worksheet(sheet_name)
soup関連
soupするところまでは、原則前回と一緒ですが、
find_allメソッドにはlimit引数が設定できるので、9番目の写真付きの奴のエラーを回避しました。その9番目データのエラー回避のためエラーハンドリングロジックを入れてたのですが、不要になりましたが、せっかくなので残しています。
# href属性の中で"news.yahoo.co.jp/pickup"が含まれているもののみ全て抽出
elems = soup.find_all(href = re.compile("news.yahoo.co.jp/pickup"),limit=8)
gspreadでスプレッドシートに書き込む行の取得
APIリファレンスに従い、col_valuesメソッドでスプレッドシートに書かれている最終行を取得します。col_valuesメソッドは指定したcolmunをlist型オブジェクトに格納するので、そのlistの数を数えることで最終行を取得します。(間に空行がいるとズレると思います。)
col_values(col, value_render_option='FORMATTED_VALUE')
Returns a list of all values in column col.
Empty cells in this list will be rendered as None.
# spreadsheetの最終行を取得
values1 = sheet.col_values(1) #列の情報をまとめてlistに取得
lastrow1 = len(values1) #listの長さ=行数
スプレッドシートに展開する部分
まず、標準の datetimeライブラリをimportして、
現在の時間を取得し、日付フォーマットを整えます。
Documentation » Python 標準ライブラリ » データ型 »
| 指定子 | 意味 |
|---|---|
| %Y | 西暦 (4桁) の 10 進表記を表します。 |
| %m | 0埋めした10進数で表記した月。 |
| %d | 0埋めした10進数で表記した月中の日にち。 |
| %H | 0埋めした10進数で表記した時 (24時間表記)。 |
| %M | 0埋めした10進数で表記した分。 |
| %S | 0埋めした10進数で表記した秒。 |
また、写真つき等のゴミ記事をひっかけた時のために、エラーハンドリングを行っています。(soupのrimit引数でエラー回避したため不要となりましたが。)
日付をA列、記事タイトルをB列、記事リンクをC列に、
最終行に+1しながらupdate_acellメソッドでスプレッドシートを更新していきます。
update_acell(label, value)
Updates the value of a cell.
Parameters:
label (str) – Cell label in A1 notation.
value – New value.
Example:
worksheet.update_acell('A1', '42')
for elem in elems:
lastrow1 += 1
try:
sheet.update_acell('B' + str(lastrow1), elem.contents[0])
except:
print('エラーが発生しました')
print(elem.attrs['href'])
else:
datetimestr = datetime.now().strftime("%Y/%m/%d %H:%M:%S")
sheet.update_acell('A' + str(lastrow1), datetimestr)
sheet.update_acell('B' + str(lastrow1), elem.contents[0])
sheet.update_acell('C' + str(lastrow1), elem.attrs['href'])
sleep(2)
pip list は以下のようになりました。
(env2) ●●@●●● env2 % pip list
Package Version
-------------------- ---------
beautifulsoup4 4.9.1
cachetools 4.1.1
certifi 2020.6.20
chardet 3.0.4
google-auth 1.21.0
google-auth-oauthlib 0.4.1
gspread 3.6.0
httplib2 0.18.1
idna 2.10
oauth2client 4.1.3
oauthlib 3.1.0
pip 20.2.1
pyasn1 0.4.8
pyasn1-modules 0.2.8
requests 2.24.0
requests-oauthlib 1.3.0
rsa 4.6
setuptools 49.2.1
six 1.15.0
soupsieve 2.0.1
urllib3 1.25.10
wheel 0.34.2
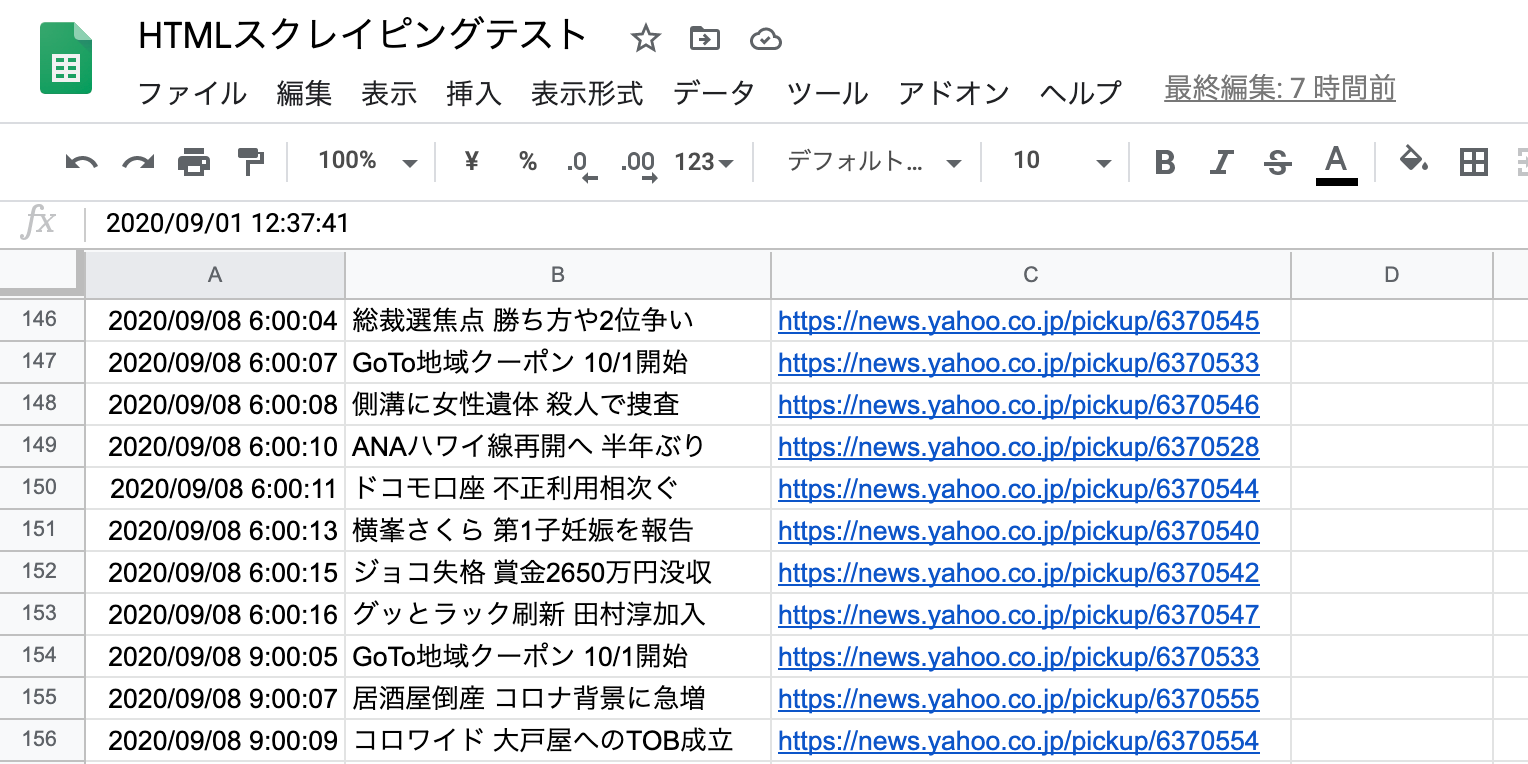
そして、無事キレイにスプレッドシートに連携されました。成功です。
参考サイト