この記事は前回記事初心者がPythonでウェブスクレイピング(1)のソース改良版です。
bs4メソッドの使い方を変えて、Yahooニュースのヘッドラインニュース抽出時の最後に余計なものが出てしまうのを改善できたので、そのメモです。
※環境:MacOS Catalina Python3.7.3
Pythonでのウェブスクレイピング学習のロードマップ
(1)ローカルでとりあえず目的のブツのスクレイピングに成功する。 ←まだココ
(2)ローカルでスクレイピングした結果をGoogleスプレッドシートに連携する。
(3)ローカルでcron自動実行を行う。
(4)クラウドサーバー上での無料自動実行に挑戦する。(Google Compute Engine)
(5)クラウド上で、サーバーレスでの無料自動実行に挑戦する。(たぶんCloud Functions + Cloud Scheduler)
サンプルPGM(1)の機能
・requestsを利用してWEBサイトの情報をget
・BeautifulSoupでhtmlをパース
・文字列検索ができるreライブラリで特定の文字列を検索(ヘッドラインニュースの特定)
・bs4のメソッドのみでキレイにタイトルとリンクを抽出
・取得した結果リストからニュースタイトルとリンクを全てコンソールに表示
前回のサンプルソース
import requests
from bs4 import BeautifulSoup
import re
# requestsを利用してWEBサイトの情報をダウンロード
url = 'https://news.yahoo.co.jp/'
response = requests.get(url)
# print(response.text)
print('url: ',response.url)
print('status-code:',response.status_code) #HTTPステータスコード 大抵[200 OK]
print('headers[Content-Type]:',response.headers['Content-Type']) #headersは辞書なのでキー指定でcontent-type出力
print('encoding: ',response.encoding) #エンコーディング
# BeautifulSoup()に取得したWEBサイトの情報とパーサー"html.parser"を渡す
soup = BeautifulSoup(response.text, "html.parser")
# href属性の中で"news.yahoo.co.jp/pickup"が含まれているもののみ全て抽出
elems = soup.find_all(href = re.compile("news.yahoo.co.jp/pickup"))
# 抽出したニュースのタイトルとリンクをコンソール表示。
for elem in elems:
print(elem.contents[0])
print(elem.attrs['href'])
今回のサンプルソース
CSSセレクタで'topicsList'クラスをfind
'li'タグをfind_all
'a'タグをfind
import requests
from bs4 import BeautifulSoup
# requestsを利用してWEBサイトの情報をダウンロード
url = 'https://news.yahoo.co.jp/'
response = requests.get(url)
# BeautifulSoup()に取得したWEBサイトの情報とパーサー"html.parser"を渡す
soup = BeautifulSoup(response.text, "html.parser")
print('soup: ',type(soup))
topicsindex = soup.find('div', class_='topicsList')
# topicsindex = soup.find('div', attrs={'class': 'topicsList'})
print('topicsindex: ',type(topicsindex))
#### やり方(1)
# liで抜き出したあと、for文でaを抜き出しながら回す
topics = topicsindex.find_all('li')
# print(topics)
print('topics',type(topics))
# 抽出したニュースのタイトルとリンクをコンソール表示。
for topic in topics:
print(topic.find('a').contents[0])
print(topic.find('a').attrs['href'])
#### やり方(2)
# リスト内包表記でaタグまで抜き出したあと、for文で回す
headlines = [i.find('a') for i in topicsindex.find_all('li')]
print(headlines)
print(type(headlines))
# 抽出したニュースのタイトルとリンクをコンソール表示。
for headline in headlines:
print(headline.contents[0])
print(headline.attrs['href'])
今回はbs4の色んな抽出の仕方の勉強も兼ねて、
難しくてよくわからないYahoo!ニュースのhtmlもざっくり解析しながら、戦略を練ります。
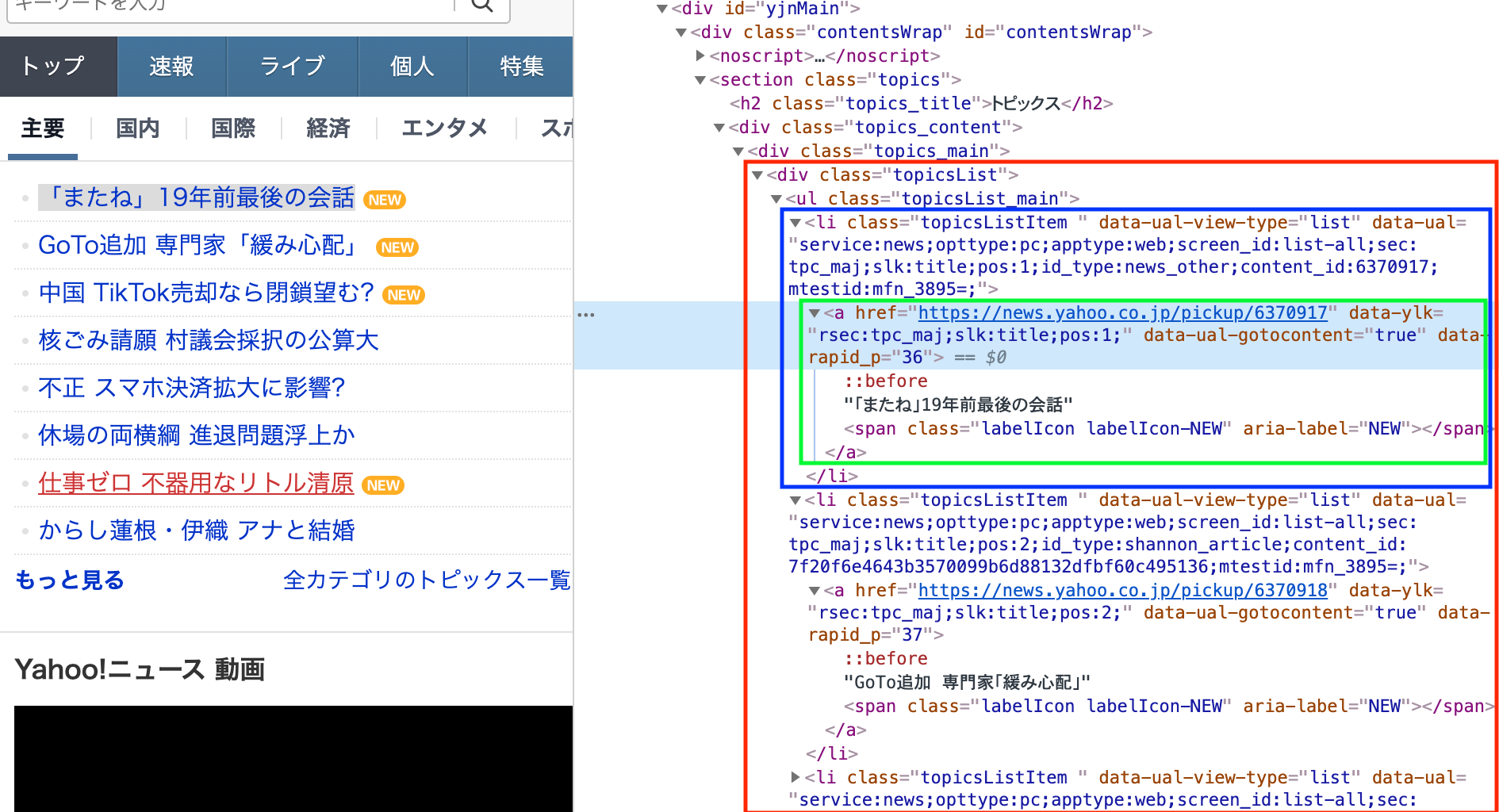
トップニュースのメイントピック達は、
・'topicsList'クラスで定義され、<赤枠>
・その中で'li'タグでニュースを連ねながら、<青枠>
・それぞれ'a'タグのhref属性でリンクが貼られている<緑枠>
構成なので、それらを順に引っこ抜いて行く作戦です。
soupしてfindしているあたりのコードは以下。
soup = BeautifulSoup(response.text, "html.parser")
topicsindex = soup.find('div', class_='topicsList')
topics = topicsindex.find_all('li')
for topic in topics:
print(topic.find('a').contents[0])
print(topic.find('a').attrs['href'])
その属性をプリントしたのが以下。
print('soup: ',type(soup))
print('topicsindex: ',type(topicsindex))
print('topics: ',type(topics))
print('topic: ',type(topic))
結果はこちら。
soup: <class 'bs4.BeautifulSoup'>
topicsindex: <class 'bs4.element.Tag'>
topics: <class 'bs4.element.ResultSet'>
topic: <class 'bs4.element.Tag'>
soupした状態は、'BeautifulSoup'オブジェクト、
CSSセレクタでclassをfindした状態は、'Tag'オブジェクト、
liタグをfind_allした状態は、(ドキュメントには見当たらないものの)'ResultSet'オブジェクト。
'ResultSet'はPythonのlist型になっていて、その個別の要素は、また'Tag'オブジェクトであることがわかります。
'topics'の各要素'topic'はTagオブジェクトなので、find等のメソッドを使うことが可能で、
contentsでtagに囲まれた文字列部分(つまりニュースタイトル)、
href属性も抜き出すことが可能です。
やり方(1)
liタグで抜き出したあと、for文でaタグを抜き出しながら回す
やり方(2)
リスト内包表記でaタグまで抜き出したあと、for文で回す
二つ試しましたが、両方同じ結果が出ます。
前回のような、写真つきのトピックが変な形で抜き出されることはなくなりました!
ドコモ口座 偽HPで情報入手か
https://news.yahoo.co.jp/pickup/6370962
退陣へ 決める政治言葉躍れど
https://news.yahoo.co.jp/pickup/6370953
箱根で車衝突し炎上 2人死亡
https://news.yahoo.co.jp/pickup/6370970
古墳では?HPの測量図で気づく
https://news.yahoo.co.jp/pickup/6370965
胎児に脳の病気 選んだ中絶
https://news.yahoo.co.jp/pickup/6370957
郊外に金属くずの山次々 なぜ
https://news.yahoo.co.jp/pickup/6370958
藤井2冠に壁 豊島竜王に5連敗
https://news.yahoo.co.jp/pickup/6370961
17歳「新・最年少棋士」誕生
https://news.yahoo.co.jp/pickup/6370964
ちなみに、やり方(2)で予めaタグまで抜き出した奴は、普通の'List型'オブジェクトで、
chromeの要素検証で見ると何やら解りませんが、
ここまで抜き出すと、初心者にも優しい単純な形であることがわかります。
<class 'list'>
[<a data-ual-gotocontent="true" data-ylk="rsec:tpc_maj;slk:title;pos:1;" href="https://news.yahoo.co.jp/pickup/6370962">ドコモ口座 偽HPで情報入手か</a>,
<a data-ual-gotocontent="true" data-ylk="rsec:tpc_maj;slk:title;pos:2;" href="https://news.yahoo.co.jp/pickup/6370953">退陣へ 決める政治言葉躍れど<span aria-label="NEW" class="labelIcon labelIcon-NEW"></span></a>,
<a data-ual-gotocontent="true" data-ylk="rsec:tpc_maj;slk:title;pos:3;" href="https://news.yahoo.co.jp/pickup/6370970">箱根で車衝突し炎上 2人死亡<span aria-label="NEW" class="labelIcon labelIcon-NEW"></span></a>,
<a data-ual-gotocontent="true" data-ylk="rsec:tpc_maj;slk:title;pos:4;" href="https://news.yahoo.co.jp/pickup/6370965">古墳では?HPの測量図で気づく</a>,
<a data-ual-gotocontent="true" data-ylk="rsec:tpc_maj;slk:title;pos:5;" href="https://news.yahoo.co.jp/pickup/6370957">胎児に脳の病気 選んだ中絶<span aria-label="NEW" class="labelIcon labelIcon-NEW"></span></a>,
<a data-ual-gotocontent="true" data-ylk="rsec:tpc_maj;slk:title;pos:6;" href="https://news.yahoo.co.jp/pickup/6370958">郊外に金属くずの山次々 なぜ<span aria-label="NEW" class="labelIcon labelIcon-NEW"></span></a>,
<a data-ual-gotocontent="true" data-ylk="rsec:tpc_maj;slk:title;pos:7;" href="https://news.yahoo.co.jp/pickup/6370961">藤井2冠に壁 豊島竜王に5連敗</a>,
<a data-ual-gotocontent="true" data-ylk="rsec:tpc_maj;slk:title;pos:8;" href="https://news.yahoo.co.jp/pickup/6370964">17歳「新・最年少棋士」誕生</a>]
あとがき
今回は公式ドキュメントを眺めながら、いろいろ挑戦しました。
公式ドキュメントを根幹に据えながら、先人達のサイトをありがたく拝見して参考にするのが王道。
https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (英語:2020/9/13現在 Beautiful Soup version 4.9.1)
http://kondou.com/BS4/ (日本語:2020/9/13現在 Beautiful Soup version 4.2.0)