ストラング先生の「線形代数イントロダクション」は説明が明確で読みやすく、書き方が平易でかつ図を活用して理解しやすいように書かれています。また、英語ですがビデオが用意されています。しかし、もともと難しい考え方については、やはり理解には時間を要します。また、先生は誰にでも分かるように平易に書いているので、学習のステップが多すぎて時間がかかるという批判もあります。2023年5月13日時点で、日本語に翻訳されているのは4版で、その後5版、6版と進化を遂げています。ストラング先生はその時代のニーズに合うように構成を少しずつ変えています。特に6章以降ではその変更がある程度あります。そして、版を重ねるごとに理解しやすくなっているように私には思えます。そこで、時間短縮して学びたい人のために、固有値、固有ベクトルについて見ていきたいと思います。4版、5版、6版の構成は以下の通りです。6章を勉強するだけでも楽に1年はかかるかもしれません。そこで、固有値、固有ベクトルについて最低限の知識を身につけたいと思います。そこで第6版の6.1をベースに説明していきたいと思います。多くの部分は原本の翻訳をDeepLを用いて行い、修正を加えたものです。また、Pythonのコードを付けています。
第4版:
6.1 固有値入門
6.2 行列の対角化
6.3 微分方程式への応用
6.4 対称行列
6.5 正定値行列
6.6 相似行列
6.7 特異値分解
第5版
6.1 固有値入門
6.2 行列の対角化
6.3 微分方程式への応用
6.4 対称行列
6.5 正定値行列
特異値分解は7章となり別立てになりました。また、相似行列は6.2で出てきます。
第6版
6.1 固有値入門
6.2 行列の対角化
6.3 対称正定値行列
6.4 複素数、ベクトル、行列
6.5 微分方程式への応用
6. 固有値と固有ベクトル
固有値と固有ベクトルは、正方行列のランクや列空間よりも深い、新しい情報を持っています。$A$を掛けても方向が変わらない固有ベクトル$x$を探すと、$Ax=\lambda x$で固有値$\lambda$となります。 $\lambda$を伸び縮み係数と呼ぶことができます。再び掛けると$A^2x=\lambda^2 x$が得られます。さらに続けると、$A^{100}x=\lambda^{100}x$となります。また、2つ以上の固有ベクトルを組み合わせることができます:

入力を固有ベクトルに分離すると、各固有ベクトルはそれぞれの道を進むだけです。
固有値は$A^nx=\lambda^nx$の成長因子なのです。すべての$|\lambda_i|<1$の場合、$A^n$は最終的にゼロに近づきます。$|\lambda_i|>1$ならば、$A^n$は最終的に成長します。もし$\lambda=1$であれば$A^nx$となります。
決して変化しません。これは定常状態です。国や会社や家庭といった経済にとっては、$\lambda$の大きさが重要なのです。
行列の性質は、$\lambda$と$x$に反映されます。対称行列$S$は、固有ベクトルが垂直で、その固有値がすべて実数です。線形代数の王道は、正の固有値を持つ対称行列です。この「正定値行列」は、エネルギー$f(x)=1/2x^TSx$のような関数の最小点を知らてくれます。
これは、微積分のテスト$d^2f/dx^2>0$で$f(x)$が最小になることを示す$n$次元の形です。
固有値と固有ベクトルにより、線形微分方程式 $du/dt=Au$ を解くことができます。解は、$u_n=\lambda^nx$の代わりに $u(t)=e^{\lambda t}x$-累乗の代わりに指数を用います。解全体は $u(t)=e^{At}u(0)$ となります。定数行列$A$を持つ線形微分方程式は、その固有ベクトルを使います。有名なフーリエ行列を含む複素行列のルールも固有値、固有ベクトルで説明できます。
6.1 固有値の導入:$Ax=\lambda x$
線形代数の最初の領域は、定常状態に対するもので $Ax=b$ の線形方程式についてです。第2の領域は変化についてのものです。微分方程式 $du/dt= Au$ では連続時間、$u_{k+1}=Au_k$ では時間ステップ $k=1,2,3, \cdots$ が登場することになります。これらの方程式は消去法では解けません。
$A$を掛けても方向が変わらない「固有ベクトル」$x$が欲しいのです。解ベクトル $u(t)$ や $u_k$ は、その固定ベクトル $x$ の方向に留まります。ということは、$x$が時間によって変化すると、それに掛ける数を探すことになります。つまり一次元の問題です。
良いモデルは、行列の冪 $A,A^2,A^3, \cdots$ から得られます。例えば、$A$の100乗($A^{100}$)が必要だとします。その列は固有ベクトル $x=(.6,.4)$ に非常に近いものになります:

$A^{100}$は、100個の行列を掛け合わせるのではなく、この$A$の固有値1と1/2を利用して求めます。固有値と固有ベクトルは、行列の核心部分を見るための新しい方法です。
import numpy as np
A=np.array([[0.8,0.3],
[0.2,0.7]])
A,A@A,A@A@A

AA=A
for i in range(100):
AA=AA@A
AA #Aは定常状態分布で、Aは確率遷移行列です。これはマルコフ連鎖の定常状態です。

固有値を説明するために、まず固有ベクトルを説明します。ほとんどすべてのベクトルは、$A$をかけると方向が変わります。ある例外的なベクトル$x$は、$Ax$と同じ方向にあります。それが「固有ベクトル」です。固有ベクトルに$A$を掛けると、ベクトル$Ax$は元の$x$の$\lambda$倍の数値になります。
基本方程式は$Ax=\lambda x$です。数$\lambda$は$A$の固有値です。
固有値は、特殊なベクトル$x$に$A$を掛けたときに、伸びるか縮むか反転するかということを表しています。$\lambda=2$ や $1/2$ や -1 が見つかるかもしれません。固有値は0かもしれません。その場合、$Ax=0x$は、この固有ベクトルが$A$の零空間にあることを意味します。
$A$が単位行列であれば、すべてのベクトルは$Ax=x$となります。すべてのベクトルは $I$ の固有ベクトルです。すべての固有値 "λ "は$\lambda=1$です。これは特別な状態です。ほとんどの2×2行列では、固有ベクトルの方向と固有値が2つあります。ここでは、$\det(A-\lambda I)=0$であることを示すことができます。
$x$と$\lambda$の計算方法について説明します。講義の早い段階で出てきます。2×2行列の行列式$ad-bc$があればことは足ります。例題1は、上に出てきた行列$A$の固有値$\lambda=1$と$\lambda=1/2$を$\det(A-\lambda I)=0$を使って求めています。(実際の固有値、固有ベクトルの求め方は4版日本語版p.304の「固有値の等式」を見てください。
例1
$\det(Aー\lambda I)$による重要な数は$A$の対角線上の0.8+0.7=1.5=3/2とAの行列式$(0.8・0.7-0.3・0.2)=0.5=1/2$です。

二次方程式を$(\lambda-1)$掛ける$(\lambda-1/2)$に因数分解して、二つの固有値$\lambda=1$と1/2を確認します。このことから、$A-I$と$A-1/2$(行列式が0)は可逆でないことがわかります。固有ベクトル$x_1$と$x_2$は$A-I$と$A-1/2$の零空間に存在します。
$(A-I)x_1=0$ は $Ax_1=x_1$ です。その第一固有ベクトルは $x_1=(0.6,0.4)$ です。
$(A-I)x_2=0$ は $Ax_2=1/2x_2$ です。その第二固有ベクトルは $x_2=(1,-1)$ です。

$Ax_1=x_1$ より、 $A^2x_1=Ax_1=x_1$ が得られます。$A$のあらゆる累乗は$A^nx_1=x_1$となります。$x_2$ に $A$ をかけると1/2が得られ、もう一度かけると $A^2x_2=(1/2)^2$と$x_2$の積となります。
# numpyで固有値、固有ベクトルを求めます。
eigenvalues, eigenvectors = np.linalg.eig(A)
# 結果の固有値は同じですが、固有ベクトルは(0.6,0.4),(1,-1)ではありません。
eigenvalues, eigenvectors

# 計算された第一固有ベクトルを正規化して、全ての要素の和が1になるようにします。
index = np.argmax(eigenvalues == 1.0)
stationary_vector = eigenvectors[:, index]
print(stationary_vector,np.sum(stationary_vector))
stationary_vector /= np.sum(stationary_vector)
stationary_vector

x1=stationary_vector
#A@x1=x1になります。
A@x1

#計算された第二固有ベクトルを正規化します。
index = np.argmax(eigenvalues == 0.5)
x2_vector = eigenvectors[:, index]
adj=x2_vector[0]/1
x2_vector /=adj
x2_vector

x2=x2_vector
A@x2

$A$の固有ベクトルは$A^2$の固有ベクトルのままです。固有値$\lambda$は2乗されます。
このパターンが成功するのは、固有ベクトル $x_1,x_2$ がそれぞれの方向を変えないからです。$A^{100}$の固有値は$1^{100}=1$と$(1/2)^{100}=非常に小さい数$です。
$A$の固有ベクトルは、すべての$A^n$の固有ベクトルでもあります。すると、$A^nx=\lambda^nx$となります。
他のベクトルは方向を変えます。しかし、このようなベクトルでもすべて2つの固有ベクトル$x_1$と$x_2$の組み合わせで構成できます。$A$の1列目(0.8,0.2)は、(0.6,0.4)+(0.2,-0.2)と組み合わせられます。

各$x_i$に$\lambda_i$を掛けた$A^2$の1列目について:

各固有ベクトルは、$A$を掛けると、その固有値が掛けられます。どのステップでも$x_1$は$\lambda_1=1$なので変化しません。しかし、$x_2$は$\lambda_2=1/2$で99回乗算されます。
$A^{100}$の列1

これは$A^{100}$の1列目です。もともと.6000と書いていた数字は正確ではありませんでした。
小数点以下30桁では表示されない$(1/2)^{99}$の(.2)倍を省いてしまったのです。固有ベクトル $x_1$ は変化しない「定常状態」です($\lambda_1=1$ なので)。固有ベクトル$x_2$は、事実上消滅する「減衰モード」($\lambda_2=.5$)だからです。$A$のべき乗が大きいほど、その列はより定常状態に近づきます。
この特定の$A$をマルコフ行列と呼びます。その最大の固有値は$\lambda=1$です。その固有ベクトル $x_1=(0.6,0.4)$ が定常状態であり、$A^k$ のすべての列がこれに近づくことになります。付録8を参照。巨大なマルコフ行列は、Googleの超高速ウェブ検索で中心的な役割を担っています。
#どのようなベクトルも固有ベクトルの空間を張ることで得られる。
A.T[0],stationary_vector+x2_vector*0.2
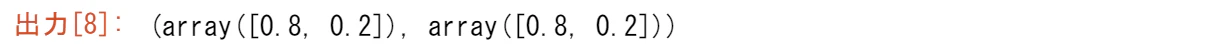
x1+0.2*0.5**99*x2

射影行列$P$の場合、列空間は自分自身に射影されます($Px=x$)。$P$の零空間は0に射影されます($Px=0x$)。$P$の固有値は$\lambda=1$と$\lambda=0$です。
例2:
射影行列
P=\left[\begin{array}{c c} 0.5 & 0.5\\ 0.5 & 0.5\end{array} \right]は固有値\lambda=1と\lambda=0
を持ちます。
その固有ベクトルは $x_1=(1,1)$ と $x_2=(1,-1)$ です。そして、$Px_1=x_1$(定常状態)、$Px_2=0$(零空間)となります。この例は、マルコフ行列と非可逆行列($\lambda=0$の行列)です。最も重要なのは、対称行列であることです。そのため、固有ベクトルが直交しています。
- マルコフ行列.$P$の各列の和は1になり、$\lambda=1$が固有値となります。
- $P$は非可逆行列です。$\lambda=0$は固有値です。
P=P^Tは対称行列です。直交する固有ベクトル
\left(\begin{array}{l} 1\\ 1\end{array} \right)と\left(\begin{array}{l} 1\\ -1\end{array} \right)があります。
射影行列の固有値は0と1だけです。$\lambda=0$ (つまり$Px=0x$)の固有ベクトルは零空間を埋めます。零空間は0に射影されます。列空間は自分自身に射影されます。射影によって、列空間は維持され、零空間はなくなります:
各部分の射影
v=\left[\begin{array}{l} 1\\ -1\end{array} \right]+\left[\begin{array}{l} 2\\ 2\end{array} \right]=\left[\begin{array}{l} 3\\ 1\end{array} \right]
は
Pv=\left[\begin{array}{l} 0\\ 0\end{array} \right]+\left[\begin{array}{l} 2\\ 2\end{array} \right]
に射影されます。
射影行列の固有値には$\lambda=0$と1があります。置換行列の固有値はすべて$|\lambda|=1$です。次の行列$E$は鏡映行列であり、同時に置換行列です。また、$E$は特殊な固有値を持っています。
#固有ベクトルは、伸び縮みするので、表現方法はいろいろある。1,-1,0で表現すると
P=np.array([[0.5,0.5],
[0.5,0.5]])
eigenvalues, eigenvectors = np.linalg.eig(P)
print(eigenvalues, eigenvectors)
index = np.argmax(eigenvalues == 1.0)
x1_vector = eigenvectors[:, index]
x1_vector /= np.sum(x1_vector[0])
print('stationary',x1_vector)
index = 1
x2_vector = eigenvectors[:, index]
x2_vector /= np.sum(x2_vector[0])
x2_vector

#vを(1,-1)と(2,2)に分解する理由を理解すには説明不足で、この部分は行間が長い。
#(1,-1)はゼロ空間に射影する固有ベクトル、(1,1)は列空間に射影する固有ベクトル
#(2,2)は(1,1)の線形結合である。この部分は「列空間は維持され、ゼロ空間はなくなります。」
#の部分と直接関係している。
x1=x1_vector
x2=x2_vector
#Pv=Px1^T+px2^T
v=x1_vector*2+x2_vector
print('Px1=',P@x1)
print('Px2=',P@x2)
print('v=',v)
print('Pv=',P@v)
#Pvはvを射影すると列空間の直線上の一点になることを示している。

例3:
交換行列(\text{exchange matrix) } E=\left[\begin{array}{c c} 0 & 1\\ 1 & 0 \end{array} \right]は固有値1と-1を持ちます。
固有ベクトル$(1,1)$は、$E$によって変化しません。第2固有ベクトルは$(1,-1)$です。その符号は $E$で反転します。負の要素を持たない行列でも、負の固有値を持つことができます!$E$の固有ベクトルは$P$と同じで、$E=2PーI$だからです。

行列が$I$だけ変化したとき、それぞれの$\lambda$は1だけ変化します。固有ベクトル自体に変化はありません。
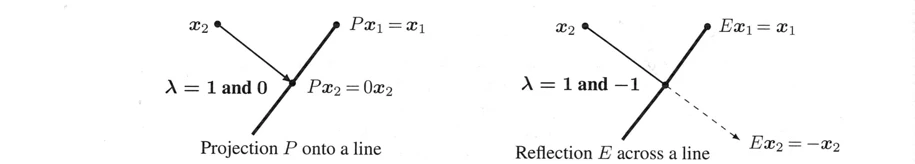
図6.2: 射影行列 $P$ の固有値は 1 と 0 です。交換行列$E$の固有値は$\lambda=1$と$\lambda=-1$です。典型的な$x$は方向を変えますが、固有ベクトル$Ax=\lambda x$は$x$を通る線上にとどまります。
次の節に関しては
固有値の等式:$\det(A-\lambda I)=0$
行列式とトレース(4版良い知らせと悪い知らせ)
虚数の固有値
ABとA+Bの固有値(4版p.324 ABとA+Bの固有値)
4版(日本語版)と同じなのでそちらを見てください。
おまけ
よく$x\in \mathbb{R}^n$という表記を見ます。これは$x$が$n$次元の次数空間にいること表しています。しかし、この意味がよくわかりません。そこで乱数を使って疑似的に体験してみます。つぎにPythonのfloatでは15桁の精度ですのでそこまで合わせるのは大変なので、近似計算しています。
$Ax=b$の列空間を$b$とします。xxは一様乱数です。それに第一固有値を満たす固有ベクトルを条件にして得られる第一固有ベクトルを探します。$(A-I\lambda)x=0$なので、$A-I\lambda=0$. 第一固有ベクトルは右肩上がりの直線になります。第一固有ベクトルはx1=(0.87,0.55)でもいいし、(0.6,0.4)でもOKでした。解は零空間にあり、第一固有ベクトルが特解だからです。伸び縮みするベクトルです。この伸び縮みするベクトルは一般に言われる固有値の伸縮率という意味とは別です。今回の例では固有値を1にしてありますが、これが2であれば、固有ベクトルはすべて2倍されるという意味です。
fig = plt.figure(figsize = (3, 3))
xx=np.random.rand(10000,2)*2-1
A=np.array([[0.8,0.3],
[0.2,0.7]])
b=[]
b2=[]
for x1,x2 in zip(np.transpose(xx)[0],np.transpose(xx)[1]):
b0=(A@np.array([x1,x2]))[0]
b1=(A@np.array([x1,x2]))[1]
b.append([b0,b1])
lamda=1
if np.floor(b0*1000)==np.floor(x1*lamda*1000)\
and np.floor(b1*1000)==np.floor(x2*lamda*1000):
b2.append([b0,b1])
b=np.array(b)
b2=np.array(b2)
plt.scatter(b[:,0],b[:,1])
plt.scatter(b2[:,0],b2[:,1])

第二固有ベクトルも直線になりますが、第一固有ベクトルに直交しています。
b=[]
b2=[]
for x1,x2 in zip(np.transpose(xx)[0],np.transpose(xx)[1]):
b0=(A@np.array([x1,x2]))[0]
b1=(A@np.array([x1,x2]))[1]
b.append([b0,b1])
lamda=0.5
if np.floor(b0*1000)==np.floor(x1*lamda*1000) \
and np.floor(b1*1000)==np.floor(x2*lamda*1000):
b2.append([b0,b1])
b=np.array(b)
b2=np.array(b2)
fig = plt.figure(figsize = (3, 3))
plt.scatter(b[:,0],b[:,1])
plt.scatter(b2[:,0],b2[:,1])
plt.show()

実は
if np.floor(b0*1000)==np.floor(x1*lamda*1000)\
and np.floor(b1*1000)==np.floor(x2*lamda*1000):
b2.append([b0,b1])
この部分は近似計算をしています。正確に=のものを探すことは至難の業で、百万個の乱数を発生しても見つからないでしょう。固有値、固有ベクトルはそれほどまれな事象を表現しているのです。
ですから主成分分析で次元圧縮しても元のデータを復元できるのはすごいことなんです。
20230719 15424
固有ベクトルは特解だと書きましたが、これはストラング線形代数イントロダクションのp.169にある「階数rによる線型方程式の4つの可能性」を見てください。
- 一つの解を持つ
- 無限個の解を持つ
- 0はたは一つの解を持つ
- 0または無限個の解をもつ
に分けられます。固有ベクトルは無限個の解を持つに相当します。連立方程式は変数と式の数が同じであれば通常解けますが、この数が足りないと一位の解はありません。そこでその際にも解が得られる時があり、その特殊な場合の1つが固有値、固有ベクトルの問題です。
連立方程式を例に変数の数と式の数で関係を理解しておくと便利です。ちなみに式の数が変数の数よりも多い場合も問題です。その際の解の求め方の1つが最小二乗法です。
ーーーーーーーーーーーーーーーーーーーーーーーー
Python3ではじめるシステムトレード【第2版】環境構築と売買戦略

「画像をクリックしていただくとpanrollingのホームページから書籍を購入していただけます。