内容
Amazon Bedrockのナレッジベースで構築したRAGシステムの回答精度を向上させるため、クエリ分解の検証を行います。
イメージ
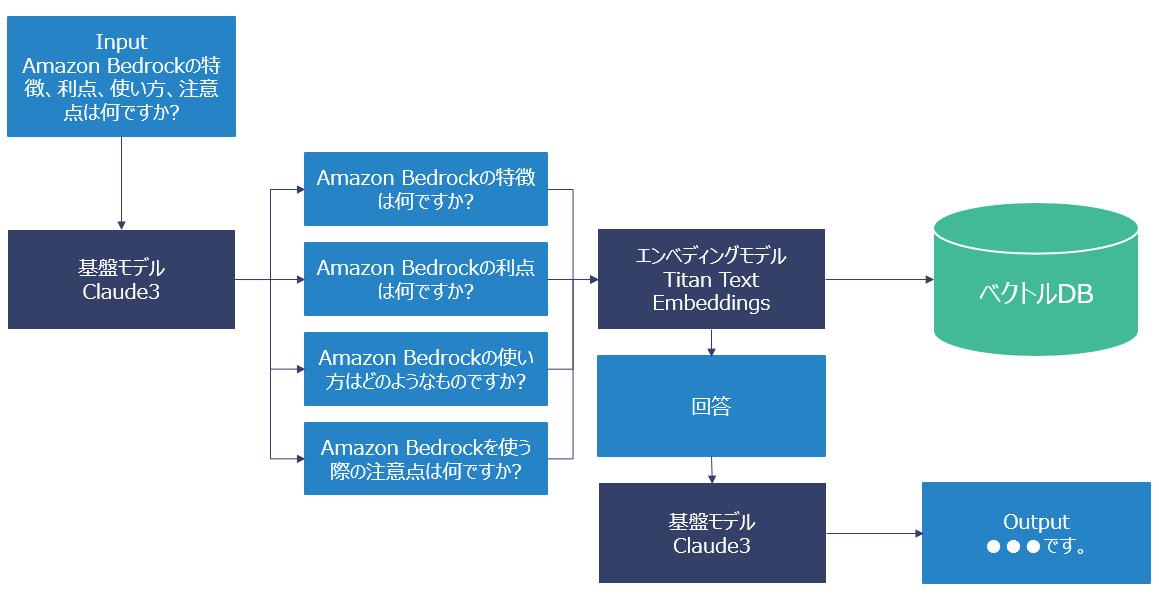
イメージは下記のようになります。ユーザがプロンプトから「Amazon Bedrockの特徴と利点と使い方と注意点」といった質問をします。こういった色々な情報が入った複雑なクエリを事前に「Amazon Bedrockの特徴」や「Amazon Bedrockの利点」といったサブクエリに分割してくれる機能です。分割後の複数のクエリがベクトル変換後、ベクトルDBに問合せを行い、回答を作成します。最終的な回答はClaude3などの基盤モデルで作成後、ユーザへの応答を行います。
設定
RetrieveAndGenerateAPIでクエリ分解の設定を行います。以下はテスト用プログラムの全文です。
import boto3
import json
REGION = "ap-northeast-1"
MODEL_ARN = "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0"
MODEL_ARN_RERANK = "arn:aws:bedrock:ap-northeast-1::foundation-model/amazon.rerank-v1:0"
KNOWLEDGEBASE_ID = '******'
bedrock_agent = boto3.client("bedrock-agent-runtime", region_name=REGION)
user_question = "Amazon Bedrockの特徴と利点と使い方と注意点"
context_prompt = f"""
以下はユーザーからの質問です:
<question>
{user_question}
</question>
"""
# retrieve_and_generate_stream 呼び出し
response = bedrock_agent.retrieve_and_generate_stream(
input={"text": context_prompt},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"orchestrationConfiguration": {
"queryTransformationConfiguration": {
"type": "QUERY_DECOMPOSITION"
}
},
"knowledgeBaseId": KNOWLEDGEBASE_ID,
"modelArn": MODEL_ARN,
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"rerankingConfiguration": {
"bedrockRerankingConfiguration": {
"metadataConfiguration": {
"selectionMode": "ALL",
},
"modelConfiguration": {
"modelArn": MODEL_ARN_RERANK
},
},
"type": "BEDROCK_RERANKING_MODEL"
}
}
}
}
}
)
stream = response.get("stream")
raw_events = []
if stream:
for event in stream:
raw_events.append(event)
print(json.dumps(raw_events, indent=2, ensure_ascii=False))
設定箇所は下記になります。
"orchestrationConfiguration": {
"queryTransformationConfiguration": {
"type": "QUERY_DECOMPOSITION"
}
}
queryTransformationConfiguration
プロンプトを分割して複数のソースを取得するには、変換タイプをQUERY_DECOMPOSITIONに設定します。
確認
CloudWatch Logsから実行フローを確認してみます。(ログは一部抜粋箇所のみ記載)
「Amazon Bedrockの特徴と利点と使い方と注意点」という質問をしています。
まず最初にクエリを分割する処理が入りました。下記システムプロンプトの日本語訳はあなたはクエリ生成エージェントです。会話履歴(オプション)とユーザーの質問に基づいて、最適なクエリを決定するのがあなたの仕事です。となります。
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"anthropic_version": "bedrock-2023-05-31",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "\n以下はユーザーからの質問です:\n\n<question>\nAmazon Bedrockの特徴と利点と使い方と注意点\n</question>\n"
}
]
}
],
"system": "You are a query generation agent. Given the conversation history (optional) and a user question, your task is to determine the optimal queries.以下省略",
その後、下記4つのサブクエリが作成された後、クエリのベクトル化が実行されました。
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"inputText": "Amazon Bedrockの利点は何ですか?",
"dimensions": 1024,
"embeddingTypes": [
"float"
]
},
"inputTokenCount": 12
}
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"inputText": "Amazon Bedrockの使い方はどのようなものですか?",
"dimensions": 1024,
"embeddingTypes": [
"float"
]
},
"inputTokenCount": 19
}
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"inputText": "Amazon Bedrockを使う際の注意点は何ですか?",
"dimensions": 1024,
"embeddingTypes": [
"float"
]
},
"inputTokenCount": 17
}
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"inputText": "Amazon Bedrockの特徴は何ですか?",
"dimensions": 1024,
"embeddingTypes": [
"float"
]
},
"inputTokenCount": 13
}