内容
Amazon Bedrockのナレッジベースを使用したRAGシステムを構築します。
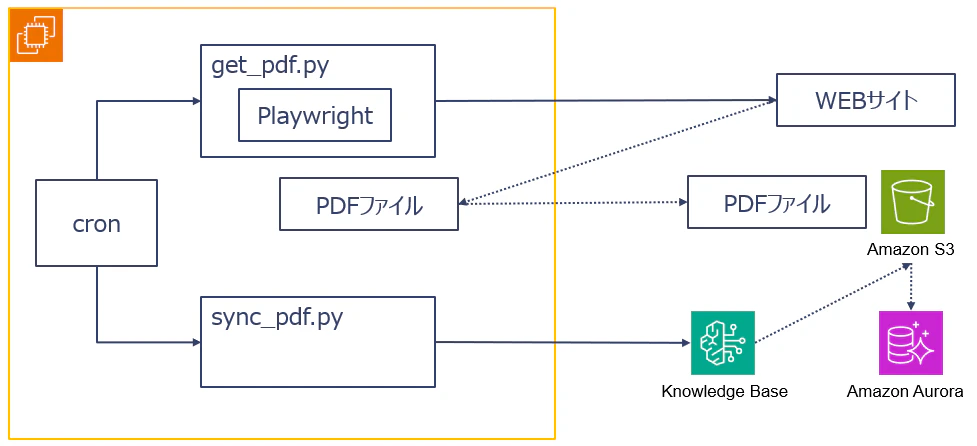
EC2サーバ上にget_pdf.pyというスクリプトを用意します。このスクリプトはPlaywrightを使用して、WEBページのデータをPDFとしてEC2サーバ内のディレクトリに保存後、S3バケットにアップロードを行います。またsync_pdf.pyというスクリプトを用意します。このスクリプトはS3に取得したPDFの情報をAuroraで構成したベクトルDBに同期します。なお2つのスクリプトはcronを使用して定期的に実行を行います。
前提条件
- EC2サーバはPrivarteLinkやNATゲートウェイを使用して、S3やBedrockのAPIにアクセス出来ること
- EC2サーバはイントラネット内またはインターネット上のWEBサーバにアクセス出来ること
- EC2サーバはS3やBedrockにアクセスするためのIAMロールの設定が完了していること
- Playwrightがインストール済みであること
PDFデータの取得
s3_bucket_nameにPDF保存先のS3バケット名を指定します。またlocal_dirにはPDFを保存するサーバ上のディレクトリを指定します。サーバ内のディレクトリにPDFファイル取得した後、S3にアップロードするといった動作を行います。
import asyncio
from playwright.async_api import async_playwright
import boto3
s3_client = boto3.client('s3')
s3_bucket_name = "********"
local_dir = "/***/***/doc"
PlaywrightはChromiumブラウザをバックグラウンドで起動して、該当のWEBページに移動した後、PDFファイルとして保存します。その後、s3_client.upload_fileを使用してS3にファイルをアップロードしています。
async def save_as_pdf(url, output_filename):
output_path = f"{local_dir}/{output_filename}"
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page()
await page.goto(url)
await page.pdf(path=output_path, format="A4")
await browser.close()
s3_client.upload_file(output_path, s3_bucket_name, output_filename)
情報を取得するWEBサイトのリストです。URLと保存するPDF名を指定します。
pdf_tasks = [
("https://xxx.xxx.co.jp/xxx01", "pdf01.pdf"),
("https://xxx.xxx.co.jp/xxx02", "pdf02.pdf"),
]
上記リストを使用してsave_as_pdfを呼び出します。処理完了後、S3バケットにPDFファイルが取得されます。
for url, output_filename in pdf_tasks:
asyncio.run(save_as_pdf(url, output_filename))
ベクトルDBへの同期
上記S3に取得したPDFのデータをベクトルDBに同期します。実行結果のログ保存ディレクトリをlog_dirに指定します。knowledgeBaseIdとdataSourceIdに対象のナレッジベースIDおよびデータソースIDを指定します。これらの設定内容を元にBedrockのAPIにアクセスして同期処理を行います。
import boto3
import json
from datetime import datetime
log_dir = "/***/***/log"
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
log_file = f"{log_dir}/ingestion_response_{timestamp}.log"
client = boto3.client('bedrock-agent', region_name="ap-northeast-1")
response = client.start_ingestion_job(
knowledgeBaseId='******',
dataSourceId='******'
)
下記は実行結果を受け取ってログを出力する処理の例です。
def convert_datetime(obj):
if isinstance(obj, datetime):
return obj.isoformat()
raise TypeError("Type not serializable")
with open(log_file, 'w') as f:
json.dump(response, f, indent=2, default=convert_datetime)
cronの設定
crontabを編集して、上記スクリプトの自動実行設定を追加します。下記は毎日20:00にgetpdf.pyを実行し、毎日20:10にsyncpdf.pyを実行する例です。
00 20 * * * python3 /root/getpdf.py
10 20 * * * python3 /root/syncpdf.py