この記事は、Fujitsu extended Advent Calendar 2016の22日目の記事です。
なお、以下の掲載内容は所属企業・組織を代表するものではなく、すべて私自身の所見であることに留意してください。
きっかけ
新卒で入社して指定された資格(例.応用情報技術者試験)を最低1個は取得しなければならず、タイトルにあるJava SE 8 Programmer IIの合格によって取得できるOracle社認定資格のOracle Certified Java Programmer, Gold SE 8(以後、Goldと記述)、およびその1ランク下のJava SE 8 Programmer Iの合格によって取得できるOracle Certified Java Programmer, Silver SE 8(以後、Silverと記述)もそれらに含まれています。Oracle社認定のJava8系資格の概要はこのURLでも掲載されていますが、以下の表でも自分なりにまとめてみました。
| 名称 | 前提資格 | 資格取得の試験 | ターゲット |
|---|---|---|---|
| Java Programmer, Bronze SE 7/8 | なし | Java SE 7 / 8 Bronze | if文などの基礎文法からオブジェクト指向まで理解できる初学者向け。 |
| Java Programmer, Silver SE 8 | なし | Java SE 8 Programmer I | ポリモーフィズムやダウンキャストのようなクラス(インターフェース)間関係や、String、ArrayListクラス、Java8から出たラムダ式、日付/時刻APIの基本的な使い方などの標準メソッドの基本仕様を理解できている開発者向け。 |
| Java Programmer, Gold SE 8 | Java Programmer, Silver SE 8 | Java SE 8 Programmer II | Immutableオブジェクト、ジェネリクス、内部クラスなどの設計、Java I/O(NIO.2系含む)、Executorフレームワークなど、細部までの文法・設計が理解できる熟練者向け。 |
| 同上 | Java Programmer, Gold SE 7 | Upgrade to Java SE 8 Programmer | 同上 |
| 同上 | Java Programmer(SE 6以前) | Upgrade to Java SE 8 OCP ( Java SE 6 and all prior versions) | 同上 |
私は学生時代に簡単なAndroidアプリケーションの開発をJavaを使って独力で開発した経験があり、業務でもJavaを扱うことが多く、新人の早いうちに資格取得のノルマを達成しておこうと思ったので、Goldの前提資格であるSilverの取得を目指しました。その結果、今年の9月上旬に割とあっさりとSilverを合格してしまい自己研鑽としては物足りなかったので、より高度なJavaの文法知識を勉強したい&最近(Java8、Java9)のJavaインターフェース設計のトレンドを掴むべく、Silverより難易度の高いGoldの取得を目指そうと思いました。
出題内容
Oracle社公式URLにも出題に関する注意事項と共に記述されています。本コラムでは、その中に出てきたトピックの箇条書きを引用し、その説明を述べていこうと思います。Gold受験する人にとってはこんな感じで出題されるのか、受験しない人にとっては最近のJava公式APIってこんな感じになっているのか、と少しでも感じていただけたら幸いです。
なお、GoldはSilverを取得しないと取得できないので、当然ですが上記の表に記述されているようなSilverでの出題範囲はすべて理解できている前提で話を進めます。
Javaクラスの設計
- カプセル化を実装する
- アクセス修飾子やコンポジションを含む継承を実装する
- ポリモーフィズムを実装する
- オブジェクト・クラスの
hashCode、equalsおよびtoStringメソッドをオーバーライドする- シングルトン・クラスと不変クラスを作成および使用する
- 初期化ブロック、変数、メソッドおよびクラスでキーワード
staticを使用する- 抽象クラスおよびメソッドを使用するコードを作成する
- キーワード
finalを使用するコードを作成する- 静的な内部クラス、ローカル・クラス、ネストしたクラス、無名内部クラスなどの内部クラスを作成する
- メソッドやコンストラクタが列挙型内にあるものを含めて、列挙型を使用する。
- インタフェースを宣言、実装、拡張するコードを作成する。
@Override注釈を使用する- ラムダ式を作成および使用する
Silverと重複する範囲は多いですが、匿名クラスの作成はこの後に出てくる関数型インターフェース、ストリームAPIに強く関連するのでよく理解したほうがいいです。また、既存のクラスをImmutableクラスに設計するにはどうすればよいのか、のような問題が実際に出た記憶があります。さらに、列挙型(Enumクラス)でコンストラクタはprivate修飾子が付与しなければならないのに、実際にはpublicになっているので「○○行目でコンパイルエラー」を選ぶのが正解であるといった細かい箇所まで目を通さないと正解に気付かないような問題もありました。
Java8ではインターフェースにdefaultメソッドと具象staticメソッドが定義できるようになりました。なので、
interface A {
void foo();
}
interface B extends A {
@Override
default void foo() {}
}
interface C extends A {
@Override
default void foo() {}
}
class D implements B, C {}
のようなダイヤモンド継承ができてしまいます。当然class D implements B, C {}の行でコンパイルエラーになります。また、
interface E {
default void x(String s) {}
static void y(String s) {}
void z(String s);
}
のようなインターフェースの定義でも関数型インターフェースとなる(defaultメソッドや具象staticメソッドは無視される)ので、E e = s -> System.out.println(s);のようなラムダ式を記述することができます。実際の試験でも、この内容をベースとした問題が1題あったと思います。
ところで、Java7とJava8でローカルクラスと匿名クラスのコンパイル仕様が変化しています。
class Outer {
private static String a = "A";
public static void main(String[] args) {
Outer q = new Outer();
q.foo("B");
}
public static void foo(String b) { // Java8から変数bに暗黙的にfinal修飾子が付与
String c = "C"; // Java8から変数cに暗黙的にfinal修飾子が付与
Inner inner = new Inner(){
@Override
public void bar(String d) {
System.out.println(a + b + c + d);
}
};
//b = "BB";
//c = "CC";
inner.bar("D");
}
interface Inner {
public void bar(String d);
}
}
バージョン1.7のコンパイラーでコンパイルすると、ローカル変数bとcをfinal宣言しなければならない旨のコンパイルエラーになるのですが、バージョン1.8ではコンパイルが通ってしまいます。これは、Java8からコンパイル時にローカル変数bとcに暗黙的にfinal修飾子を付与する仕様になったからであり、その背景としては後述するラムダ式を導入されたことによって、匿名クラスを関数として渡しているかのように自然に見せたかったからだと私は思います。ただし、ローカル変数bとcはfinal修飾子が暗黙的に付与されているのでb = "BB"とc = "CC"のコメントアウトを外すのはNGです。javacのバージョンが1.7でも1.8でもコンパイルエラーになります。ちなみに、上記ソースコードをコンパイルし実行するとABCDと出力されます。
ジェネリクス、コレクション
- ジェネリクスクラスを作成および使用する
ArrayList、TreeSet、TreeMapおよびArrayDequeオブジェクトを作成および使用するjava.util.Comparatorおよびjava.lang.Comparableインタフェースを使用する
Javaでは配列は共変ですが、ジェネリクスは不変であることを絡めた問題が出た記憶があります。つまり、
Number[] array = new Integer[3];
はコンパイルが通りますが、
ArrayList<Number> list = new ArrayList<Integer>(3);
はコンパイルエラーとなります。
ワイルドカード、境界ワイルドカードも1題出ていました。例えば、
ArrayList<?> list = new ArrayList<Integer>();
はコンパイルが通りますが、
ArrayList<Integer> list = new ArrayList<?>();
ArrayList<?> list = new ArrayList<?>();
はどちらの行ともコンパイルエラーになります。というのも、=の右辺はワイルドカードを用いてはいけないからです。また、
ArrayList<? extends Number> list = new ArrayList<Integer>();
はコンパイルが通りますし、もっと言えば
List<? super Integer> list = new ArrayList<Number>();
もコンパイルが通ります。
java.lang.Comparable、java.util.Comparatorインターフェースのそれぞれの仕様はしっかり理解しておいた方がいいです。その関連として、java.util.TreeMapインスタンスに追加するキーのクラスはjava.lang.Comparableインターフェースをimplementsしなければならないのですが、もしimplementsしていないと実行時にlava.lang.ClassCastExceptionがスローされます(コンパイルエラーではないので注意)。
そう言えば、Deque関連は1題も出題されませんでした。ただの気まぐれかも。
ラムダ組込み関数型インタフェース
Predicate、Consumer、Function、Supplierなど、java.util.functionパッケージに含まれている組込みインタフェースを使用する- プリミティブ型を扱う関数型インタフェースを使用する
- 2つの引数を扱う関数型インタフェースを使用する
- 'UnaryOperator'インタフェースを使用するコードを作成する
後述するストリームAPIに必要な記述だということもあり、それに次いで2番目に出題数が多かった分野だったと思います。個人的に四天王と名づけている以下の4つのインターフェース名と、それぞれの抽象メソッド名は絶対覚えておきましょう。最低これら4つ覚えておけば、BiConsumer<T, U>のようなBiが付くインターフェースや、プリミティブ型(int、long、double、booleanの4つ)に特化したDoublePredicateやLongToDoubleFunctionのようなインターフェースをいちいち覚えなくても応用が効きます。
| インターフェース名 | 抽象メソッド名 | 備考 |
|---|---|---|
Function<T, R> |
R apply(T t) |
四天王の1つ |
Consumer<T> |
void accept(T t) |
四天王の1つ |
Supplier<T> |
T get() |
四天王の1つ |
Predicate<T> |
boolean test(T t) |
四天王の1つ、コイツだけSilverでも出題される |
BiFunction<T, U, R> |
R apply(T t, U u) |
- |
UnaryOperator<T> |
T apply(T t) |
Function<T, T>のサブインターフェース |
BinaryOperator<T> |
T apply(T t1, T t2) |
BiFunction<T, T, T>のサブインターフェース |
IntFunction<R> |
R apply(int value) |
- |
ToDoubleFunction<T> |
double applyAsDouble(T t) |
double apply(T t)ではない |
IntToDoubleFunction |
double applyAsDouble(int value) |
double apply(T t)ではない |
IntConsumer<T> |
void accept(int value) |
- |
IntSupplier<T> |
int getAsInt() |
int get()ではない |
IntPredicate<T> |
boolean test(int value) |
- |
※java.util.functionパッケージに定義されてある関数型インターフェースは、上記の表以外にも公式API集にすべて載っています。 |
これらの知識より大事なことは、関数型インターフェースからラムダ式(または後述するメソッド参照)を連想できるようになれることは当然ですが、逆にラムダ式からどの関数型インターフェースを使ったのか連想できるようになれることです。例えばSupplier<String>インターフェースだったらvoid型からString型を返せばよいので、
Supplier<String> a = () -> "HelloWorld!"
のようなラムダ式を定義できるようになること、また
b = s -> s.concat("World!")
のラムダ式を見て、変数bの変数型はFunction<String, String>またはUnaryOperator<String>であると連想できればよいです。そして、関数型インターフェースを実際に適用するためにどのように抽象メソッドを使えばいいのか連想できることも大事です。先ほどの例でラムダ式を使ってHelloWorld!の文字列をString型の変数strに代入したかったら、String str = a.get();やString str = b.apply("Hello");と記述すればよいです。
さらに上記の知識を応用した
DoubleFunction<BiConsumer<Integer, Double>> func = x -> (y, z) -> System.out.println(x / z + y);
のような入れ子のラムダ式もありました。もし5.0 / 2.0 + 3 = 5.5の計算結果を出力する場合は、func.apply(5.0).accept(3, 2.0);と記述します。
JavaストリームAPI
- ストリームのインタフェースとパイプラインについて説明する
- ラムダ式を使用してコレクションをフィルタリングする
- ストリームとともにメソッド参照を使用する
- 基本バージョンの
map()メソッドを含むpeek()およびmap()メソッドを使用してオブジェクトからデータを抽出するfindFirst、findAny、anyMatch、allMatch、noneMatchなどの検索メソッドを使用してデータを検索するOptionalクラスを使用する- ストリームのデータ・メソッドと計算メソッドを使用するコードを作成する
- ストリームAPIを使用してコレクションをソートする
collect()メソッドを使用してコレクションに結果を保存する。Collectorsクラスを使用してデータをグループ化/パーティション化するflatMap()メソッドを使用する
Java8の目玉機能というのもあり出題数が非常に多く、実際に約5割の問題がストリームAPIに絡んでいたと思います。上記の箇条書きで書いたすべてのコラムが大事だと思います。
ストリームはStream<T>インターフェースや、そのプリミティブ型に特化したIntStreamインターフェースなどを使用し、以下の流れで動作します。
- 配列、コレクションの各要素などから、複数要素を保持できるストリームを生成する(保持する値を直接指定することも可能)
- ストリームが保持した値に対し、マッピング、フィルタリング、デバッグなど途中で何らかの編集を行う(=中間操作)
- ストリームが保持した値から、何らかの結果を返す(=終端操作)
ただし、以下の注意点があることを留意して下さい。この内容も実際の試験と絡めて覚えておくべきです。
- 中間操作はストリームからストリームを生成するので、何度も実行できる
- 終端操作は1回しか実行できず、終端操作を行ったストリームは再度終端操作を行うことができない(=コンパイルエラーになる)
- 終端操作の記述を忘れてもコンパイルエラーにはならないが、設定した中間操作は何も実行されない
ストリームAPIは、1〜3の動作をなんと1行でコーディングできちゃうことが最大の利点で、それによるコードの可読性向上、早急なバグ発見への期待があります。例えば、後述するJava7から追加されたNIO.2を利用して、カレントディレクトリから兄弟と子のファイル/ディレクトリをすべて出力させるJavaコードを書きたいとします。このとき、javacのバージョンが1.7では以下のようにFileVisitorインターフェースの4つの抽象メソッドをオーバーライドして、長い行数をコードする必要がありました。
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.FileVisitOption;
import java.nio.file.FileVisitResult;
import java.nio.file.FileVisitor;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.BasicFileAttributes;
class Search7 {
public static void main(String[] srgs) {
try {
Files.walkFileTree(
Paths.get("./"),
new FileVisitor<Path>() {
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) {
System.out.println(dir);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) {
System.out.println(file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) {
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) {
return FileVisitResult.CONTINUE;
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
}
一方、バージョンが1.8では以下のように非常に短い行数で済みます。
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
class Search8 {
public static void main(String[] srgs) {
try {
Files.walk(Paths.get("./")).forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
}
}
なお、Java8でのコードにあるSystem.out::printlnはJava8から追加された表記でメソッド参照と呼びます。この表記はラムダ式の(Path path) -> System.out.println(path)と同じ意味を持ち、ラムダ式よりもさらに短く表記で記述できます。実際の試験では関数型インターフェースと絡めて結構出題されていたので注意が必要です。例えば
ToDoubleFunction<String> ds = str -> Double.parseDouble(str);
は、以下のように書き換えることができます。
ToDoublefunction<String> = Double::parseDouble;
ラムダ式の記述から、どのようにメソッド参照を記述するのか、またその逆のメカニズムをしっかり頭の中でイメージできればよいです。
さてストリームAPIの説明に戻りますが、試験対策として先ほどの1〜3に応じて説明していきます。まずは以下のストリームAPIを用いたコードを見て下さい。
Stream<String> stream1 = Arrays.asList("a", "bb", "ccc", "dddd").stream(); // ストリームの生成
Stream<Integer> stream2 = stream1.map(str -> str.length()); // 中間操作その1
Stream<Integer> stream3 = stream2.filter(num -> num > 1); // 中間操作その2
Optional<Integer> result = stream3.max((num1, num2) -> num1 - num2); // 終端操作
result.ifPresent(max -> System.out.println(max));
1行目のストリームの生成関数は、Java8で新たにCollection<T>インターフェースでdefaultメソッドとして追加されたstream()によって、型パラメータTでのストリームのインスタンスstream1を生成しています。Arrays.asList()メソッドはCollection<T>インターフェースのサブインターフェースであるList<T>インターフェースを返すので、このメソッドを用いたストリームの生成が非常に多く出題されていました。
2行目の中間操作map()には、stream1で保持されている各String型の4つの要素に対し、Stringクラスのlength()を呼び出すようラムダ式で指定しています。その結果、4つのString型の要素はlength()の戻り値であるint型のラッパークラスであるInteger型に変換されます。よって、map()によって生成されたstream2で保持している値は1, 2, 3, 4になります。なお、ジェネリクスにはintのようなプリミティブ型は記述できません(コンパイルエラーになります)。
また、3行目の2回目の中間操作filter()では、stream2で保持している値1, 2, 3, 4に対しフィルタリングをかけて、保持する値の数を少なくしています。フィルタリングの指定もラムダ式を使用し、この例の場合は値が1より大きい要素だけ保持して残りは破棄するように指定しています。よって、stream3で保持している値は2, 3, 4です。
最後に終端操作max()ですが、これはstream3で保持している値である2と3と4のうち最大値を返しています。ただし、最大値を求める際に最大であることの定義をmax()の引数に指定しなければなりません。この引数はjava.util.Comparator<T>型であり、その抽象メソッドであるint compare(T num1, T num2)を表すラムダ式(num1, num2) -> num1 - num2を指定しています。この指定により自然順序による最大値を求めるので、4を返す流れになります。なお、このように2、3、4すべての要素を終端操作によって用いることが確定済である操作をリダクション操作と呼びます。
しかし上記例を見ると、max()はOptional<T>型のインスタンスresultを返しています。Optional<T>クラスはストリームの終端操作の結果を格納してくれるコンテナクラスであり、終端操作の結果がnullであってもOptional<T>インスタンスはnullを格納でき、そのときOptional<T>インスタンス自身はnullにはならないことが最大の特徴です。上記例で最後の行にOptional<T>クラスのifPresent(Consumer<? super T> consumer)を呼び出しており、null以外の値を格納している場合は引数で指定されるconsumerのラムダ式が実行され、nullが格納している場合は何もしない仕様になっています。これより、実行時にjava.lang.NullPointerExceptionがスローされるリスクを無くしている設計が読み取れるのではないかと思います。以上より、resultには4が格納されているので、Consumer<Integer>型のラムダ式max -> System.out.println(max)のmaxに4がそのまま適用されて、4と出力されます。
なお、上記例を1つの文で書き、メソッド参照をすべて適用すると以下のような記述になります(当然、実行結果は同じです)。
Optional<Integer> result =
Arrays.asList("a", "bb", "ccc", "dddd").stream() // ストリームの生成
.map(String::length) // 中間操作その1
.filter(num -> num > 1) // 中間操作その2
.max((num1, num2) -> num1 - num2); // 終端操作
result.ifPresent(System.out::println);
上記以外にも、ストリームの生成メソッド、中間操作を行うメソッド、終端操作を行うメソッドはたくさんあります。これ以上は記事を書くのが面倒なので割愛しますが、ストリームAPIに強くなりたいなら公式API集を参考にしてみてください。実際の試験では、一番上に書かれた10個の箇条書きのうち、10個すべてが出題されていた気がします。
例外、アサーション
- try-catchおよび
throw文を使用するcatch、multi-catchおよびfinally句を使用する- try-with-resources文とともにAutocloseリソースを使用する
- カスタムな例外と自動クローズ可能なリソースを作成する
- アサーションを使用して不変量をテストする
try-with-resourceはJava7から追加された便利な機能ですが、SE8 Gold試験でも後述するJDBCと絡めて結構出題されていました。このとき、オーバライドされたclose()メソッドやcatch句の実行されるタイミングで注意が必要です。
class Main {
static class X implements AutoCloseable {
X() {
System.out.println("X : Constructor");
}
@Override
public void close() {
System.out.println("X : close()");
}
}
static class Y implements AutoCloseable {
Y() {
System.out.println("Y : Constructor");
}
@Override
public void close() {
System.out.println("Y : close()");
}
}
public static void main(String[] args) {
try (X x = new X();
Y y = new Y()) {
throw new Exception("Exception");
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
System.out.println("finally");
}
}
}
上記ソースファイルをコンパイルし、実行すると
X : Constructor
Y : Constructor
Y : close()
X : close()
Exception
finally
と出力されます。変数yは変数xより後で定義したのにも関わらず、close()メソッドではそれらの逆順に呼ばれるというtry-with-resourceの仕様を知らないと引っかかりやすいです。また、今までのtry句→catch句→finally句の実行順序に引きづられしまい、Y : close()の前にExceptionが出力されると勘違いしやすいです。上記の結果ごと覚えておけば引っかけや勘違いを防ぐことができます。
さらに、スーパークラスでthrows Exceptionやthrows RuntimeExceptionと定義されているメソッドをオーバーライドするとき、サブクラスでのメソッドはどのようにthrows指定すればよいのかに関する問題が1題出題されてありました。
意外にも、アサーション関連の問題は2題も出題されていました。assertキーワードの構文を覚えるだけなので、しっかり得点源にしたい分野です。
日付/時刻API(Java SE8)
LocalDate、LocalTime、LocalDateTime、Instant、PeriodおよびDurationを使用して日付と時刻を単一オブジェクトに結合するなど、日付に基づくイベントと時刻に基づくイベントを作成および管理する- 複数のタイムゾーン間で日付と時刻を操作する。日付と時刻の値の書式設定など、夏時間による変更を管理する
Instant、Period、DurationおよびTemporalUnitを使用して、日付に基づくイベントと時刻に基づくイベントを定義、作成および管理する
Java8で新しく実装されたストリームAPIとは別のAPIですが、あまり出題されていなかったと思います。ゾーン情報を含むZonedDateTime、Instantクラス、日付/時間のフォーマット、夏時間に関する問題は1題も見なかったような気が…
しかしSilverでもそうでしたが、LocalXXX系クラスはImmutableクラスであることを利用した引っ掛け問題がGoldでも出題されていました。
他にはPeriodは日付、Durationは時間の間隔であることや、時刻のISO 8601表記くらいを覚えておけばよい気がするので、Gold取得だけが目的だったらSilverの知識+α程度で十分だと思います。
なお、昔のjava.utilパッケージにあるDateクラスやCalendarクラスは1題も出題されていませんでした。SE 8に追加された方の日付/時刻APIが主流になっていくにつれ、いずれ@deprecatedになってしまうのでしょうか。
Java I/O、NIO.2
- コンソールに対してデータの読取り/書込みを行う
java.ioパッケージのBufferedReader、BufferedWriter、File、FileReader、FileWriter、FileInputStream、FileOutputStream、ObjectOutputStream、ObjectInputStreamおよびPrintWriterを使用するPathインタフェースを使用してファイルおよびディレクトリ・パスを操作する- NIO.2とともにストリームAPIを使用する
メソッドの仕様を知らなきゃ解けない問題だらけなのにも関わらず、試験での出題数は案外それなりにあります。当時私が最も苦手とする分野でしたので、ここは公式API集を見ながら実際に手を動かしてテストサンプルを実装しながら理解するのがベストです。Java7で追加されたNIO.2より昔から存在していた入出力ストリーム(Java8で追加されたストリームAPIとは全くの別物であることに注意)よりNIO.2の方が出題数は多かったと思います。
まずは前者の入出力ストリームですが、与えられたファイルに対してBufferedReaderインスタンスを生成した時、ファイルに書かれてある文字列からread()、readLine()、mark()、reset()、skip()を用いてどのように出力されるのかの問題が実際にありました。ここで、read()とreadLine()との違いを以下の表に簡単にまとめます。
| メソッド名 | 読み込み単位 | 戻り値の型 | ファイル終端時 |
|---|---|---|---|
read() |
1文字 |
int(通常、char型に明示的キャストして1文字にする) |
-1を返す |
readLine() |
1行 |
String(改行コードは自動判別し、戻り値に含まない) |
nullを返す |
ここで、BufferedReaderはReaderインターフェースをimplementsし、そのインターフェースでmark()やreset()など宣言していますが、Readerの実装クラスすべてがオペレーションをサポートしているとは限りません。サポート外のReader実装クラスでこれらを実行すると、実行時にjava.io.IOExceptionがスローされてしまいます。このサポート状態はmarkSupported()の戻り値(boolean型)で判別できます。BufferReader以外の入出力ストリームの出題状況は記憶にありませんが、少なくともjava.io.SerializableインターフェースとObjectOutputStreamは出題されていなかったと思います。また、コンソール入出力関係はInputStream型のSystem.in変数や、OutputStream型のSystem.out変数を使えばよいのですが、Java6から追加されたjava.io.Consoleクラスを使う手もあります。このクラスのポイントは、以下の2つだと思います。
-
Consoleインスタンスはnewを用いて初期化できず、System.console()の戻り値を代入して初期化する - コンソールから1行分読み込む
readline()はString型を返すのに対し、コンソール上は非表示にして1行分読み込むreadPassword()はchar[]型を返す
残ったNIO.2の方がむしろ大事なのではないでしょうか。NIO.2はjava.nioに続くパッケージに格納されており、入出力ストリームでは実現できないようなファイル/ディレクトリ情報を操作できる機能を実装しています。実際の試験ではそれらを操作するstaticメソッドのみが用意されているFilesクラスのcopy(Path from, Path to, CopyOption... option)、move(Path from, Path to, CopyOption... option)が1題ずつ出題され、それらの第3引数以降に可変長引数としてオプションを指定できるLinkOption.NOFOLLOW_LINKSやStandardCopyOption.REPLACE_EXISTINGなどの実行結果などにも注意が必要です。また、ファイル内のすべての文章を1行単位で読み込みできるメソッドとしてreadAllLines(Path path)とlines(Path path)があります。以下の表で、それぞれの違いを簡単にまとめます。
| メソッド名 | 戻り値の型 | 導入されたバージョン |
|---|---|---|
static readAllLines(Path path) throws IOException |
List<String> |
Java7 |
static lines(Path path) throws IOException |
Stream<String> |
Java8 |
ところで、これらFilesクラスのメソッド群の引数にPathインターフェースが指定されています。このPathインターフェースだけに関しても2〜3題出題されていました。Pathインターフェースには当然コンストラクタは存在せず、以下の2通りからインスタンスが生成することができます。
- ファクトリクラスである
Pathsクラスのget(String first, String... more)メソッドを使用する(こっちだけ覚えれば十分) -
FileSystemインターフェースの実装クラスでgetPath(String first, String... more)メソッドを使用する
Pathインターフェースの引数に指定する絶対/相対パスは、ルートディレクトリが0番目を表さず、ルートディレクトリ直近のディレクトリ/ファイルを表すことに注意して下さい。例えば
Path path = Paths.get("/usr/bin/java");
System.out.println(path.getName(0));
System.out.println(path.subpath(1, 3));
を実行すると、以下の出力結果になります。
usr
bin/java
他にも、相対パスと絶対パスでのPathオブジェクトに対して、resolve()、normalize()を実行したときの動きの違いなどは注意するべきです。
Javaの同時並行性
RunnableとCallableを使用してワーカー・スレッドを作成する。ExecutorServiceを使用してタスクを同時に実行する- スレッド化の潜在的な問題であるデッドロック、スタベーション、ライブロックおよび競合状態を識別する
- キーワード
synchronizedとjava.util.concurrent.atomicパッケージを使用してスレッドの実行順序を制御するCyclicBarrierやCopyOnWriteArrayListなど、java.util.concurrentのコレクションとクラスを使用する- 並列Fork/Joinフレームワークを使用する
- リダクション、分解、マージ・プロセス、パイプライン、パフォーマンスなど、並列ストリームを使用する
まずは、ThreadクラスやRunnableインターフェースを用いたスレッドを用いた並列処理の基本の使い方や、排他処理、同期処理の基本の使い方から身につけてましょう。排他処理にはsynchronized修飾子をメソッドやブロックに指定し、同期処理にはjava.util.concurrent.CyclicBarrierなどを利用すればよいのです。なおRunnableインターフェースは1つの抽象メソッドであるrun()を持つ関数型インターフェースなので、ラムダ式の代入が可能です。
Executatorフレームワークは2題くらい出題されていたと思いますが、知らないと動きが分からないと思います。Execuratorフレームワークは、インスタンス生成時に複数のスレッドを一度に生成して、スレッドを使用するまで貯めておくスレッドプールの概念を導入しています。また、各スレッドの実行のスケジューリング機能を実装し、スレッドの再利用性に優れたパフォーマンスを発揮します。試験対策としては、ExecutorServiceの立ち振舞いを理解する必要があります。ExecutorServiceの使用例として、以下のコードを見てください。
Runnable r = new Runnable() {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("Runnable : " + i);
}
}
};
Callable<Integer> c = new Callable<Integer>() {
@Override
public Integer call() {
int i = 0;
for (; i < 5; i++) {
System.out.println("Callable : " + i);
}
return i;
}
};
ExecutorService es = null;
try {
es = Executors.newFixedThreadPool(3);
es.execute(r);
Future<?> f1 = es.submit(r);
Future<Integer> f2 = es.submit(c);
System.out.println(f1.get() + " : " + f2.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
es.shutdown();
}
Executors.newFixedThreadPool(3)によって、固定数3個のスレッドを持つスレッドプールを表すExecutorServiceインスタンスesを生成します。このインスタンスに、あらかじめ定義したRunnableのタスクをexecute()によって3個のうち1個のスレッドを用いて実行します。また、タスクはRunnableインターフェースではなくCallable<T>インターフェースも使えることが可能であり、違いは以下の表の通りになります。
| 関数型インターフェース名 | 抽象メソッド | 戻り値の型 | checked例外スロー可否 |
|---|---|---|---|
java.lang.Runnable |
run() |
必ずvoidにする |
不可能 |
java.util.concurrent.Callable |
call() |
型パラメータTで指定 |
throws指定により可能 |
このとき、スレッド実行関数は以下の4パターンのどれかになります。
| メソッド名 | 戻り値の型 | タスク実行後にFutureが格納する値 |
|---|---|---|
execute(Runnable task) |
void |
- |
submit(Runnable task) |
Future<?> |
null |
submit(Runnable task, T t) |
Future<T> |
t |
submit(Callable<T> task) |
Future<T> |
Callable<T>のT call()で返す値 |
Future<T>はタスク実行結果を表すインターフェースであり、get()によってタスクが完了するまでスレッドが待機し、完了したらT型の結果をそのまま返す仕組みを覚えておけばよいです。以上より、System.out.println(f1.get() + " : " + f2.get());の行で
null : 5
と出力されます。最後にshutdown()を実行してesをシャットダウンし、新たにタスクを受け付けないようにします。もしshutdown()メソッドを呼び出さないと、すべてのスレッドの処理が終わってもプログラムが終了しないまま、ずっと待機し続けてしまいます。以上のような一連の動作を覚えておくだけイメージが湧いてくるのではないかと思います。
java.util.concurrentパッケージにはCyclicBarrier以外にも、スレッドセーフなList、Map、Set、Queueインターフェースが実装されています。例えば、以下のコードを見て下さい。
List<Integer> list = new ArrayList<>(Arrays.asList(0, 1, 2, 3, 4));
new Thread(){
@Override
public void run() {
for (Integer num : list) {
System.out.println("Thread : " + num);
}
}
}.start();
for (Integer num : list) {
System.out.println("Remove : " + num);
list.remove(num);
}
一見この実行のたびに結果が変わりそうですが、実際には必ず例外java.util.ConcurrentModificationExceptionがスローされてしまいます。
Exception in thread "Thread-0" Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:901)
at java.util.ArrayList$Itr.next(ArrayList.java:851)
at Main.main(Main.java:18)
java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:901)
at java.util.ArrayList$Itr.next(ArrayList.java:851)
at Main$1.run(Main.java:12)
Javaの拡張for文ではコレクションに実装されているイテレータ(=Iteratorインターフェース)が呼び出されるのですが、そのイテレータによる反復処理中にArrayListなどのスレッドセーフではないコレクションの要素を追加/削除すると例外java.util.ConcurrentModificationExceptionがスローされる仕様になっているからです。これは実際に実装してみてハマらないと分からない辛さの1つではないかと個人的に思っています。この回避手段として
List<Integer> list = new ArrayList<>(Arrays.asList(0, 1, 2, 3, 4));
の行を、以下のようにスレッドセーフなjava.util.concurrent.CopyOnWriteArrayListクラスに置き換えてあげればよいです。
List<Integer> list = new CopyOnWriteArrayList<>(Arrays.asList(0, 1, 2, 3, 4));
CopyOnWriteArrayList以外にも多くのスレッドセーフなコレクションが用意されていますが、ひとまずjava.util.concurrentパッケージに用意されているクラスのサマリーにざっと目を通して、どのコレクションがスレッドセーフなのか否かを判別できるだけでよいと思います。
なお、アトミック、Fork/Joinフレームワークからそれぞれ1題ずつ出題されていた事は覚えています。アトミック(=分割不可能な一連の操作)は、intなどのプリミティブ型にsynchronized修飾子のような排他処理を行うメソッドが定義されているAtomicIntegerクラスが出題されました。Fork/Joinフレームワークは全体的なコード記述方法を大まかに理解するだけで十分です。
JDBCによるデータベース・アプリケーション
Driver、Connection、StatementおよびResultSetインタフェースと、プロバイダの実装に対するこれらの関係など、JDBC APIの中核を構成するインタフェースについて説明する- JDBC URLなど、
DriverManagerクラスを使用してデータベースに接続するために必要なコンポーネントを識別する- ステートメントの作成、結果セットの取得、結果の反復、結果セット/ステートメント/接続の適切なクローズを含め、問合せを発行しデータベースから結果を読み込む
JDBCは主に以下の2つの観点の理解度が問われます。
- JDBC APIとJDBCドライバの2つが、それぞれどんな役割を担っているのか
- JDBC APIを用いてどのようにデータベースへ接続し、SQL文を用いて操作できるのか
実際の試験では後者のJDBC APIの使い方に関する問題だけ4題ほど出題された記憶がありますが、前者の知識も複数選択問題として出題される可能性があるので、システムの動きを把握するべきだと思います。今後、本記事では後者のみ説明を述べます。
JDBC APIの使い方は以下の順序によって、データベースを接続/操作できるコーディングの基本の流れから把握することが一番大事です。
-
DriverManager.getConnection()によって生成されるConnectionインターフェースを実装したオブジェクト - 1.の
Connection.createStatement()によって生成されるStatementインターフェースを実装したオブジェクト - 2.の
Statement.executeQuery()によって生成されるResultSetインターフェースを実装したオブジェクト
これら3つのオブジェクトは、すべてtry-with-resourceを適用してclose()を実行できます。なので、クローズ済みの各オブジェクトに対して何らかのメソッドを実行するとSQLExceptionがスローされることに注意して下さい。例えば、ある与えられたprivate static finalなString型のJDBCに接続できるURLを表す変数URLに対して
try (Connection cn = DriverManager.getConnection(URL);
Statement st = cn.createStatement()) {
ResultSet rs1 = st.executeQuery("SELECT id FROM shop");
ResultSet rs2 = st.executeQuery("SELECT name FROM shop");
if (rs1.next()) {
System.out.println(rs1.getInt(1));
}
if (rs2.next()) {
System.out.println(rs2.getString(1));
}
} catch (SQLException e) {
e.pribntStackTrace();
}
のようにStatement型の変数stを使い回すと、rs2が生成された地点でrs1がクローズされていまいます。よって、rs1.next()でSQLExceptionがスローされます。
なお、ResultSetは何気に行/列のインデックスが0ではなく、1から始まることに注意です。よってResultSet型の変数rsに対し、rs.getString(0)などはコンパイルは通りますが、実行時にSQLExceptionがスローされます。ただし、rs.absolute(0)はコンパイルエラーにも実行時にSQLExceptionがスローされません。rs.absolute(0)を実行すると、rsの1番目の行の前にある空行へ移動するからです(ちなみに、このメソッドはboolean型を返し、正常に移動できた結果としてのtrueを返します)。
この他にも以下のような内容が問われ、両方とも1題ずつ出題されていました。
-
Statement.execeteQuery()以外のSQL文実行方法 -
ResultSetインターフェースを拡張したSQL文を使わないレコード操作の方法
ローカライズ
- アプリケーションをローカライズするメリットについて説明する
Localeオブジェクトを使用してロケールを読み取り設定するpropertiesファイルの作成と読取りを行う- 各ロケールについてリソース・バンドルを作成し、アプリケーションでリソース・バンドルをロードする
特定の地域を表すLocaleインスタンスの初期化には、以下の2通りの方法があります。
-
Localeクラスのコンストラクタを用いる方法(引数に国、言語、バリアントを任意で指定可能) -
Locale.USやLocale.ENGLISHのようなLocale型のstatic変数を代入する方法
最近のjavaの標準APIではnewを使わない設計が多くなっているのにも関わらず、Java8で新規追加されたLocaleクラスはコンストラクタを用いて初期化できる珍しい設計をしています。上記ののLocale変数の初期化方法が実際に出題されていました。なお、LocaleクラスのstaticなネストクラスであるLocale.Builderクラスによって初期化もできますが、後述する模擬問題や実際の試験にはそれを用いた初期化は無かったと思います。
Java8では新規に追加されていないのですが、特定の地域ごとに言語、数値、通過の情報などの情報を一元管理するリソースバンドルを表すResourceBundle抽象クラスが標準APIに存在します。Java標準APIでは、リソースバンドルを実現する上記情報を記述する方法として、以下の2つが以前から存在していました。
- 独自のクラスに
ResourceBundleのサブクラスであるListResourceBundle抽象クラスを継承し、その抽象メソッドであるpublic Object[][] getcontents()をオーバライドして、そのメソッド内の定義に情報を記述する方法 - 拡張子が
propertiesのファイルに情報を記述する方法
実際の試験では上記2つの設計方法のうち後者のみが出題された記憶があるのですが、それを利用したリソースバンドルの使用方法についても問われていました。本記事では両方とも例として挙げてみたいと思います。まず前者ですが、以下のようなリソースを表すクラスを記述します。
package com.gold.eight.java;
import java.util.ListResourceBundle;
public class Test_ja_JP extends ListResourceBundle {
@Override
protected Object[][] getContents() {
String[][] contents = {
{"capital", "Tokyo"},
{"currency", "yen"},
{"language", "Japanese"}
};
return contents;
}
}
戻り値がObject[][]なのにString[][]を返している理由は、ジェネリクスにも書いてあるようにJavaの配列は共変だからであることを思い出して下さい。String[][]の中に入れ子として存在するString[]にはjava.util.Map<String, String>のごとく、0番目の要素にキー値、1番目の要素にはキー値に対応する値を入力します。ここで、クラス名がTest_ja_JPとなっていますが、Testを基底名といい、それにアンダーバーで続けてロケール情報の言語コード、国コードを記述しています。
では、このリソースを以下のようにリソースバンドルとして利用してみます。
package com.gold.eight.java;
import java.util.Locale;
import java.util.ResourceBundle;
public class Main {
public static void main(String[] args) {
ResourceBundle rb = ResourceBundle.getBundle("com.gold.eight.java.Test", Locale.JAPAN);
System.out.println(rb.getString("capital"));
System.out.println(rb.getString("currency"));
System.out.println(rb.getString("language"));
}
}
以上2つのjavaファイルをコンパイルし、実行すると以下のように出力されます。
Tokyo
yen
Japanese
ResourceBundle rb = ResourceBundle.getBundle("com.gold.eight.java.Test", Locale.JAPAN);の行で先ほどのリソースを読み込みます。このとき、getBundle()の第1引数には文字列で「パッケージ名.基底名」と書かないといけません。また、第2引数は任意でLocaleインスタンスを指定できるので、先ほどの言語コードと国コードに対応するLocale.JAPANを書いています。リソースに書かれた情報を読み込む時にはResourcebundleインスタンスのgetString()を使って、引数にキー値の文字列を指定していますが、もし存在しないキー値を指定するとjava.util.MissingResourceExceptionがスローされます。
また、後者のpropertiesファイルを作る方法は、Test_ja_JP.javaの代わりに以下のフォーマットで記述するだけでよいです。
capital=Tokyo
currency=yen
language=Japanese
ここでもファイル名が基底名にアンダーバーで続けてロケール情報の言語コード、国コードを記述しています。リソースバンドルとして利用したい場合は先ほどのMain.javaと同様です。
勉強記録
勉強を開始してからGoldを取得するまでにどんな感じに過ごしてきたのか、覚えている範囲で書いていきます。
2016/9/10〜
Silverを取得するも自己研鑽には物足りなく感じ、その翌日にGoldの取得を決意しました。
2016/9/17〜
Amazonでポチっていたオラクル認定資格教科書 Javaプログラマ Gold SE 8(通称、紫本)が届いたので勉強を開始しました。

問題集というより教科書みたいな位置づけですので、不定期ながらも週3,4日のペースでちまちまと読み進めていました。2016/10月中旬〜下旬には2周目を読み始めていたと思います。
初見のクラスやメソッドなどにはアンダーラインを引き、時には実際に公式API集を見ながら独力で実装して、理解を深めていました。
2016/10/23〜
紫本の2周目を読んでいる最中に、Silverの時にお世話になった問題集のGold版である徹底攻略 Java SE 8 Gold 問題集[1Z0-809]対応(通称、黒本)が発売された情報を知り、早速Amazonでポチりました。

Silverの黒本は解説も丁寧であり、章末の模擬問題からそっくりの問題が実際の試験に出題されていたりしました。なので、紫本を2周読んで理解してから解こうと決心しました。実際に1ページ目を開いたのは11月上旬〜中旬だったと思います。
※黒本のレビューが書いてある外部記事がほとんど無いので、この機を借りて書いてみます。章末以外は、上記カテゴリーごとの確認問題みたいなもので難易度は低めですが、知識の習得・確認として用いる分には十分であると思います。章末には模擬試験が1回分あるが、Silverの時と同様に模擬試験にあった問題と同じか、それに似た問題が実際に試験で出題されていたので、何回も繰り返す事をオススメします。Silverと同様に各問題に対する解説は非常に充実しているので、正直試験に受かるだけであったら黒本と公式API集の2つで十分だと思います。
2016/11/23
紫本は2周以上読み黒本も半分くらい目を通したので、そろそろ試験を申し込もうと決心しました。目標では11月中のGold取得でしたが、11月中に受験できるテストセンターが近くに1つも存在せず、やむを得ず12/3に申込みました。
2016/12/3
試験日。実際に受けてみたら、紫本や黒本で予め想定していた難易度よりも簡単に感じました。残り約1時間のタイミングでレビュー含めすべて解き終わり、答案を送信したと思います。その後すぐにCertViewから結果が送信され、合格したことが分かりました。
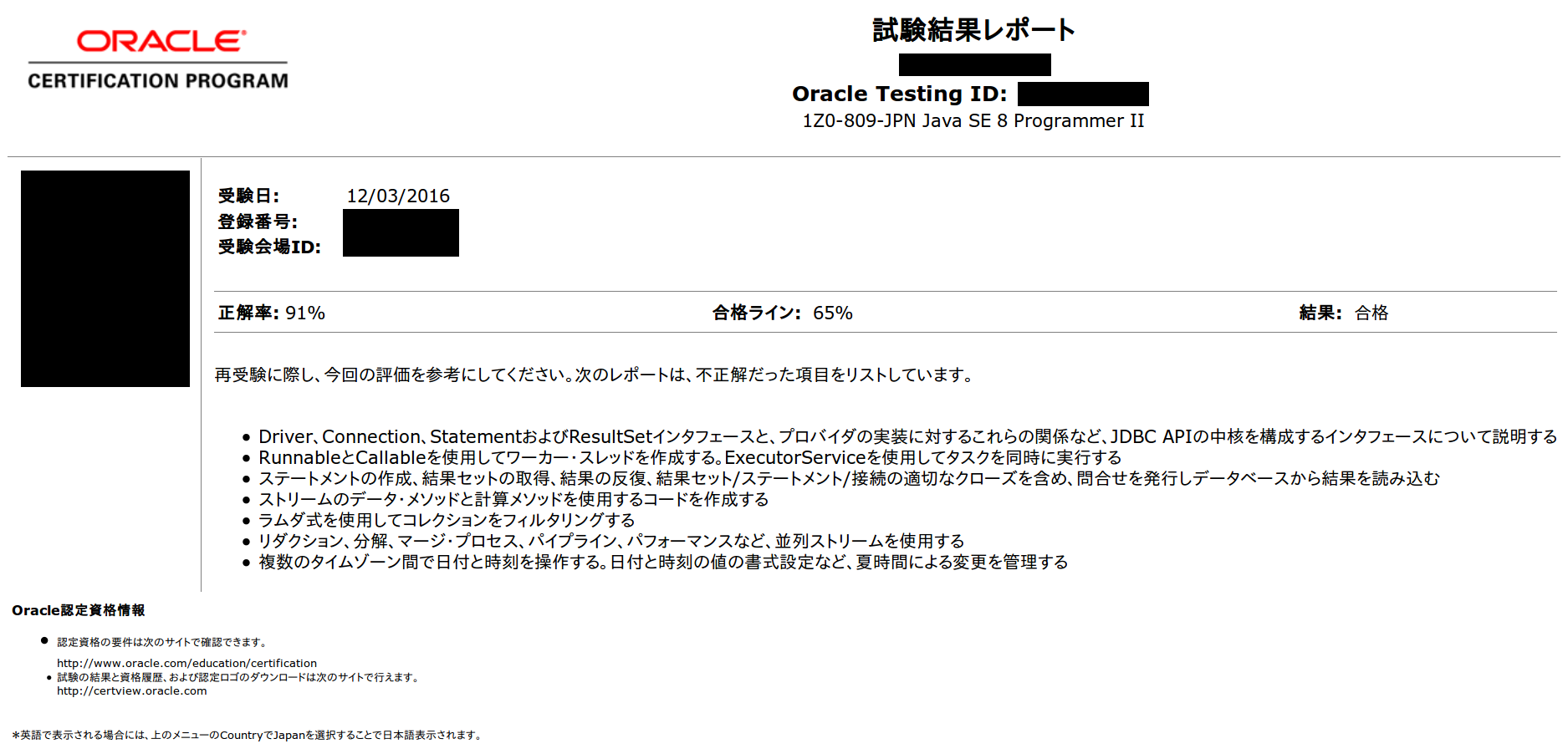
所感
最後に、合格に至るまで&合格してからの気づきでも書いていきます。
やはり、一番の気づきは最近の公式API設計になるにつれて実行時に例外をスローさせるのではなく、なるべくコンパイルエラーにさせるような、設計の歴史の流れが何となくわかったことでしょうか。例えば、リソースバンドルの概念が出てきたのはジェネリクスの出てきた時代(Java5)より昔なので、ListResourceBundleの抽象メソッドであるgetContents()の戻り値の型はObject[][]になってしまっています。なので
@Override
protected Object[][] getContents() {
Object[][] contents = {
{"A", "1"},
{"B", 2},
{"C", 3.0}
};
return contents;
}
のような、いかにもjava.lang.ClassCastExceptionを起こしてくれと言っているかのような怖いコードがコンパイルできちゃいます。その後追加されたジェネリクスの導入より、コンパイル時に型を静的に決められる箇所は決めてしまってjava.lang.ClassCastExceptionをスローされるリスクを減らそうとする設計の流れが何となくわかってきます(まぁinstanceofを使ってキャストしてもいいんですけど…)。さらに最近ですと、かの悪名高きで有名なjava.lang.NullPointerExceptionを極力減らそうとしたOptimal<T>型もJava8で追加されています。これによって開発工程での早期バグ発見などが期待でき、稼働中のシステムがダウンするようなリスクが少なくなります。
また、Consoleクラス、LocalDateTimeクラスなどのコンストラクタをprivate指定にして隠蔽したり、Pathインターフェース、ExecuratorServiceインターフェースなど抽象クラスやインターフェースはnewを使ってインスタンスをできないことを利用して、なるべくコンストラクタを使わせない設計も最近増えています。というのも、設計者が意図しないようなextends/implementsによって定義変更されたクラス、メソッドを使われることを阻止しているためです。誤った定義変更のメソッドを実行することによって、メソッド実行の順番誤りによる例外が常にスローされてしまうようではAPIの設計者もAPI利用者も困りますからね。
それにしても、ベンダー資格は資格取得に要する費用が新人から見ると高いものがほとんどです。Gold受験時には割引チケットを適用しましたが、まともに受験料を払うとSilverで26,600円、さらにGoldでも26,600円の合計53,200円要してしまいます。まぁ、世の中にはこれよりはるかに高額な受験料の資格もあるらしいですが。。ところで、2017年3月にJava9がリリースされるようですが、Java8と同様にJava9のBronze、Silver、Goldの資格が登場するんでしょうかね?もしそうだとしたら、Upgrade to Java SE 9 Programmerの合格によってJava9のGoldが取得できると思いますが、受験料26,600円をいちいち払っていると運用費も必要になってきます。それでも、今後とも資格マニアにならない程度にJavaの最新動向を追い続けてみたいです。とは言っても、Upgrade to Java SE 9 Programmerがあったら、やっぱりJava9の目玉機能であるProject Jigsawの問題が一番多いのでしょうか。jshellとか、そもそも問題が作れなさそうだし。
拙い記事でしたが、最後まで閲覧していただきありがとうございました。