データ分析をとにかくやりたい
データ分析をやりたい。
これまでJavascriptやPHPなどWeb開発の言語を学んできた中で、
最も楽しかった言語がPythonであり、Pandasの授業だ。
『データ分析のキャリアは文系で未経験だと難しい。』
そう言われても、とにかくやってみたかった。
データの前処理やグラフ化はなんとなくできたので、機械学習をひとまず触ってみる。
扱うデータは年齢、性別、人種、職業、学歴、国籍、経験年数、給与が入っているデータ。
給与の大小はこのようなものにどれくらい相関があるのかを知りたくなった。
(おそらく経験年数、年齢が相関としては大きいのではないかと考えている。結果がたのしみ。)
①必要そうなライブラリを読み込んでおく
今回は下記が使えそうなので、先に下記を読み込む。
役割はこんな感じ。

Pandas:表でデータの中身を見やすく処理する担当
Numpy:難しい計算する担当
LabelEncoder(scikitlearn.preprocessing):文字列をカテゴリー変数として数値に変換する担当
②データの中身を確認する
どんなカラムがあるのか、データはどれくらいあるのか。
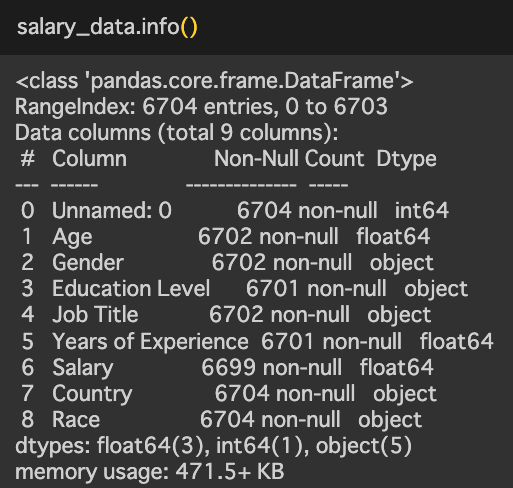
欠損値はどのカラムにどれくらいあるのか。
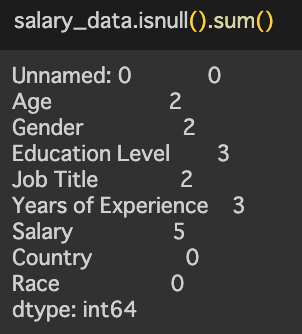
③欠損値の処理
今回は欠損値が少なかったので、欠損値がある行を全て削除することにする。
dropna()で削除。
その後、isnull().sum()で挙動を確認する。

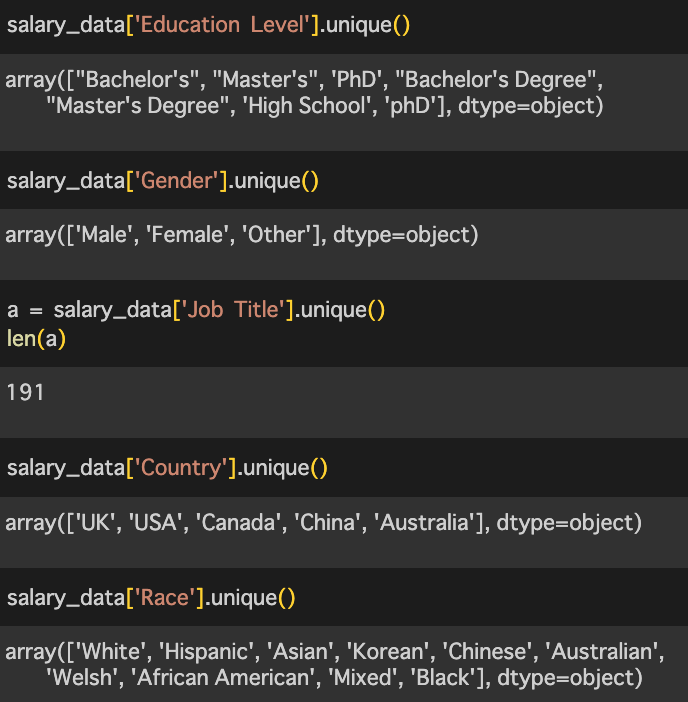
④各カラムのunique値を確認
数字(量的変数)はきりがないので、今回は文字列の固有値を確認する。
特にデータの種類が多そうなJob_titleについては量を見てみる。
(変数名はおおめに見てほしい。)
⑤文字列をカテゴリー変数に変換する。
値が適当に割り振られるので、データの扱い方としてあんまりよくなさそうだが他の量的変数で特徴量は満足できそうなので、
LabelEncoderで数字の割当をコンピューターにおまかせする。

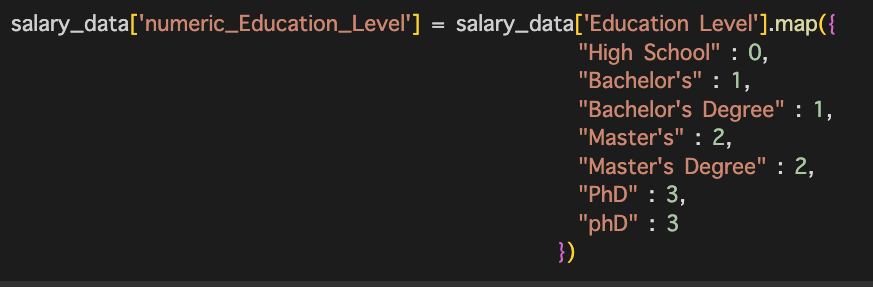
「値に被りがあった」&「一応アカデミック度は比例する」ので最終学歴だけ自分で指定したくなった。
map()で数値を格納する。
いざ、機械学習
モデルのロジックがわからないので、ChatGPTから給与の大小を機械学習するなら、
線形回帰が良さそうとのことで、それを採用する。
(触ってみたら、今後はモデルも勉強したくなった。)
scikitlearnのLinearRegressionをインポートする。

線形回帰はy = ax + bみたいなもののようで、Xを説明変数、yを目的変数というようだ。
ちなみに大文字小文字の違いは機械学習界隈での慣習らしい。
今回は説明変数を、年齢、性別、業務経験、国、人種、最終学歴とする。
目的変数はもちろん給与だ。
量的変数:年齢、業務経験、最終学歴
質的変数:性別、国、人種
(最終学歴は質的の可能性もあるが、今回のデータは学士、修士や博士号、高卒とあったので
数字として大小は作れそうなので、量的変数とする。)
⑥機械学習の結果
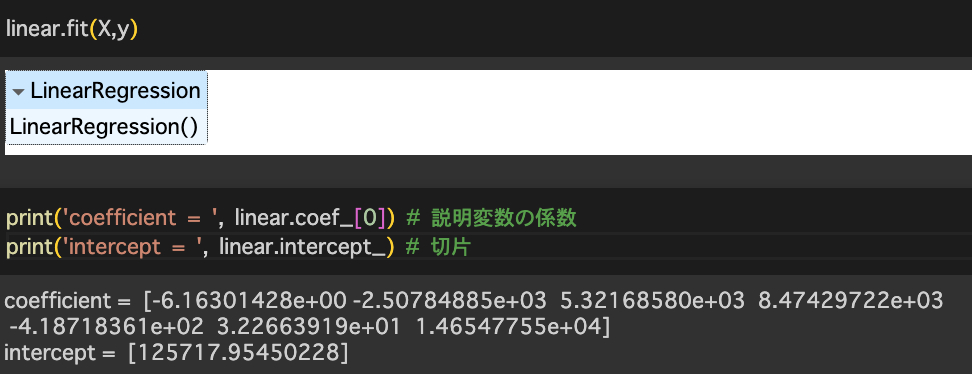
coefficientが係数で絶対値が大きければ目的変数に大きな影響を与えるようだ。
その前提で紐解くと
年収の上下に影響を与える要素ランキングは下記となる。
①業務経験
②性別
③国(カテゴリー変数なので今は意味を持たない。)
④人種(カテゴリー変数なので今は意味を持たない。)
⑤年齢
⑥学歴
ん〜、まぁそれっぽい答えが出てきた。
対象国が欧米だったため、年齢より性別が強く影響している可能性があるかもと思った。
まとめ
実際に触ってみて、楽しさは感じた。
だが出来上がったモデルの検証や分析ロジック、データの前処理もまだまだ勉強不足だと思った。
特に機械学習を使うなら、「このデータはどういう分析手法が合っているのか」を
判断する能力はマストだと思った。
色々触っていけそうで楽しみだ。