スクレイピングにハマっている無職です。
今回はスクレイピングをしてそこから読み取ったデータをCSVファイルでいい感じに表示させていきたいと思います
今回やりたいこと
ここから本の題名を検索して、本のシリーズの題名、著者、出版日、Urlを抜き出してCSVファイルに移すと言うものをやっていきたいと思います。
今回の完成の動画はこちらです。
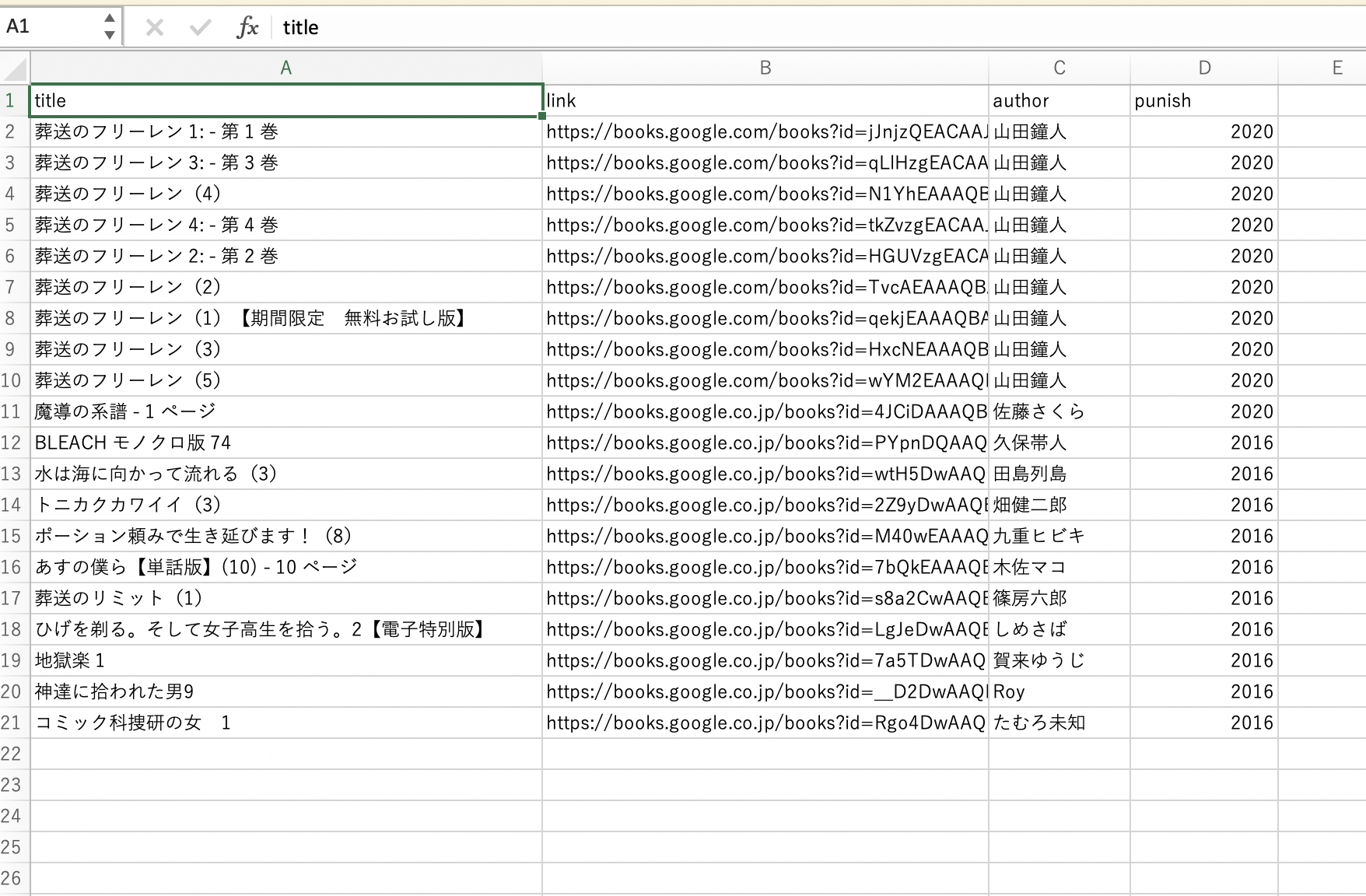
完成したCSVファイル
参考にした記事
今回のプログラムファイル
import chromedriver_binary
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options # オプションを使うために必要
import csv
option = Options() # オプションを用意
option.add_argument('--incognito') # シークレットモードの設定を付与
driver = webdriver.Chrome(options=option) # Chromeを準備(optionでシークレットモードにしている)
driver.get('https://books.google.co.jp')
time.sleep(2)
search_box = driver.find_element_by_name("q")
search_box.send_keys('葬送のフリーレン')
search_box.submit()
time.sleep(2)
i = 1 # ループ番号、ページ番号を定義
i_max = 2 # 最大何ページまで分析するかを定義
title_list = [] # タイトルを格納する空リストを用意
link_list = [] # URLを格納する空リストを用意
author_list = []
punish_list = []
while i <= i_max:
# タイトルとリンクはclass="r"に入っている
class_group = driver.find_elements_by_class_name('Yr5TG')
# タイトルとリンクを抽出しリストに追加するforループ
for elem in class_group:
title_list.append(elem.find_element_by_class_name('LC20lb').text) #タイトル(class="LC20lb")
link_list.append(elem.find_element_by_tag_name('a').get_attribute('href')) #リンク(aタグのhref属性)
author_list.append(elem.find_element_by_class_name('fl').text)
punish_list.append(driver.find_element_by_xpath("//div[@class='N96wpd']/span").text)
# 「次へ」は1つしかないが、あえてelementsで複数検索。空のリストであれば最終ページの意味になる。
if driver.find_elements_by_id('pnnext') == []:
i = i_max + 1
else:
# 次ページのURLはid="pnnext"のhref属性
next_page = driver.find_element_by_id('pnnext').get_attribute('href')
driver.get(next_page) # 次ページへ遷移する
i = i + 1 # iを更新
time.sleep(1.5)
#画像のリンクをクリック
# element.click()
time.sleep(2)
driver.quit()
test = []
#listを入れ替えて二次元配列にする(見にくい版)
for i in range(len(title_list)):
test2 = []
test2.append(title_list[i])
test2.append(link_list[i])
test2.append(author_list[i])
test2.append(punish_list[i])
test.append(test2)
@StrawBerryMoon さんがより、みやすく、わかりやすいコードを教えてくださいました!
#listを入れ替えて二次元配列にする
for i in range(len(title_list)):
test.append([title_list[i], link_list[i], author_list[i], punish_list[i]])
rowtitle =["title","link","author","punish"]
#csvファイルを書き込む utf_8_sigをつけることでエクセルで読子でも文字化けしない
with open('sample_writer_row.csv', 'w',encoding='utf_8_sig') as f:
writer = csv.writer(f)
writer.writerow(rowtitle)
writer.writerows(test)
これでいい感じにスクレイピングしていい感じにCSVファイルを整えて出力できます。
楽しいスクレイピングライフを!