はじめに
Amazon Auroraのことばかり言っていますが、 GCPでも2016/08/23にGoogle Cloud SQLのSecond Generation がGAとなり、ようやくGCPでもマネージドなMySQLが使い物になるようになってきたのではないでしょうか?
Googleの記事(前出)やAWSのマネジメントコンソールを見ていると、お互い相手を意識していることがありありと分かったりするのですが、Amazon RDS for MySQL(以下RDS(MySQL)とします)とAmazon Aurora(同Aurora)の間だけではなく、Google Cloud SQL(Second Generation)(同GCS) もレプリケーションで使える構成がかなり違います。
もちろん、RDS(MySQL)とGCPは旧来のMySQLをクラウドに乗せているのに対し、Auroraは分散共有ストレージを持っているという違いはありますし、そもそもAWSとGCPのアーキテクチャや課金体系などもかなり違います。しかし、そのような部分はかなり解説もされているようですので、ここではレプリケーションだけに焦点を絞って解説をしようと思います。
レプリケーションについて
レプリケーションにもいろいろありますが、ここでは上記3つのサービスで使えるレプリケーションに焦点を絞ります。
3者に共通するのは、レプリケーションをしたときに、レプリカ機で利用できるのはいずれも読み出しのみである、という点です。ただし、RDS(MySQL)は特定の構成でレプリカ機を読み出し用に利用できません。
RDS(MySQL)のレプリケーション
RDS(MySQL)では
- Multi-AZ
- Read Replica
という2つのレプリケーションが利用できます。しかし、この2つの目的は大きく違い、Multi-AZ構成はHA構成のため、Read Replicaは冗長化も兼ねた読み出しのために用意されています。
Multi-AZ
Multi−AZ構成は、簡単に示すと図1のようになります。
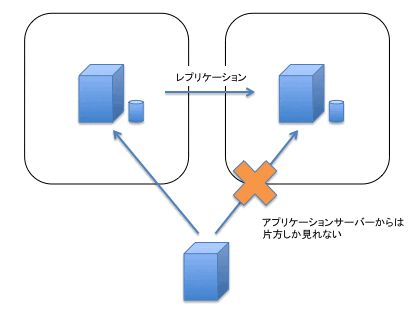
図1: Multi-AZ構成
このとき、2台は地理的に分かれたデータセンター(Availability Zone)に配置されます。アクティブ/スタンバイ構成となり、スタンバイ機は通常は利用できませんが、フェイルオーバーのときにはコネクション切断後、エンドポイント(サーバーに割り振られているホスト名)が自動で付け替えられ、再接続できます(図2)。
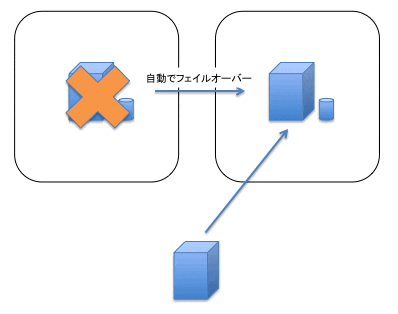
図2: RDS(MySQL)のMulti-AZ構成時のフェイルオーバー
また、この構成のときの同期方式は「同期物理レプリケーション」とされていますので、アクティブ機からスタンバイ機は常に同期していると思っていいでしょう。
Read Replica
これに対して、Read Replicaは図3のように読み出しのみに使える「非同期レプリケーション」構成です。
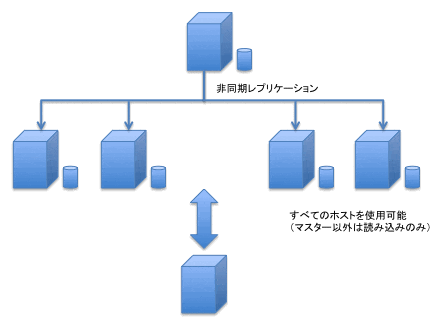
図3: RDS(MySQL)のRead Replica
この時、マスターとスレーブの間では書き込みの遅延が起こりえます。AWSではこれをReplica Lagと呼んでいます。普段は数百ミリ秒の遅延があるのですが、重い書き込みを行うと数十秒を超えReplica Lagが発生することもあります。
また、Read ReplicaはHA構成ではないため、自動的にフェイルオーバーは行われません(図4)。
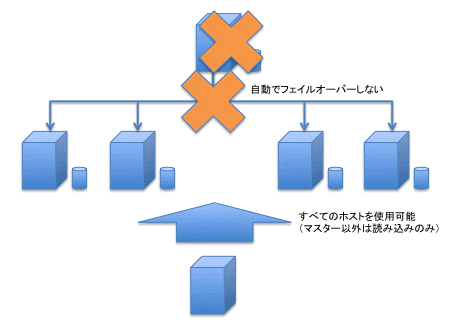
図4: RDS(MySQL)のRead Replicaのフェイルオーバー
ただし、手動でどれかのスレーブを選んでマスターに昇格させる、という機能はあります。この場合、アプリケーションの設定を書き換える必要もあります。
Multi-AZ + Read Replica
さらに、RDS(MySQL)では、Multi-AZ + Read Replica構成を採ることができます。この場合、マスターと全てのRead Replicaに使用できないスタンバイ機が用意できます(図5)。
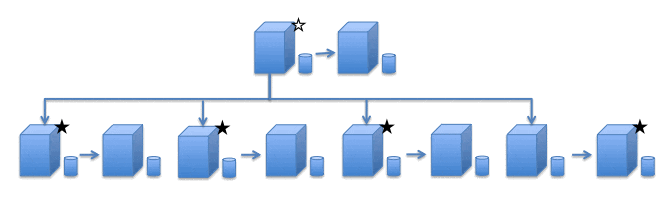
図5: Multi-AZ + Read Replica
この構成では、図5の☆が読み書き可能、★が読み込みのみ可能です。壮大な構成ですが、これもなしではないでしょう。。。
Auroraのレプリケーション
この問題をかなり解消しているのがAuroraのレプリケーションです。Auroraはもともとバックエンドのストレージを共有しているので、異なるAvailability Zoneにまたがってマスターとリードレプリカを用意しておけば、書き込みと読み込みに利用できる他、フェイルオーバーも自動で行われます(図6)。
また、ストレージを共有しているため、Replica Lagもだいたい数百ミリ秒に収まる範囲です。
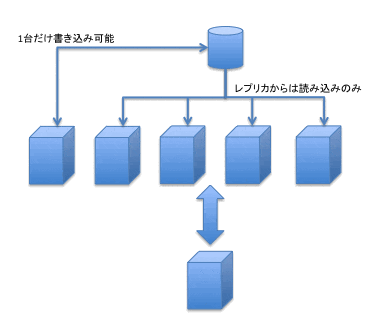
ここで一つ注意が必要なのは、設定や操作によって、Auroraインスタンスの存在するAvailability Zoneが1つにまとまってしまわないようにすることです。1つにまとまってしまうと、インスタンスレベルの障害ではフェイルオーバーできますが、Availability Zoneレベルのフェイルオーバーには多少の時間が必要となってしまうと思われます。(今のところそのような事態には遭遇していません。)
ちなみに、実オペレーション上では、Replica Lagが数百ミリ秒に収まるというのはとても大きいです(個人の感想です)。
GCSのレプリケーション
さて、それでは、GCSのレプリケーションを見てみましょう。ここではFirst Generationは考慮から外しています。
GCSのレプリケーションは、図7の通り、RDS(MySQL)を進化させたような形です。
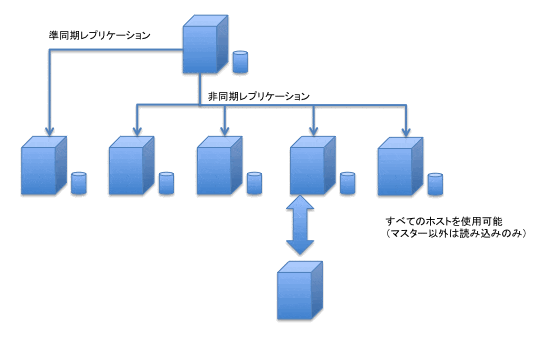
GCSでは、フェイルオーバーレプリカという名前で、マスターと準同期レプリケーション(データ到着の応答は待つが、その後の処理は待たない)を行うスレーブを作ることができ、このスレーブにはフェイルオーバーが短時間で行われます。
また、それ以外のホストは非同期レプリケーションにはなりますが、読み込みには使用できます。
私はGCSでの検証を行えていないのですが、フェイルオーバーレプリカでは数百ミリ秒以下、それ以外のレプリカでも通常数百ミリ秒以下のレプリカ遅延で使用できるのではないでしょうか?
まとめ
駆け足でAmazon RDS for MySQL、Amazon Aurora、Google Cloud SQL(Second Generation)で使えるレプリケーション方式をまとめてみました。MySQL互換という同じ枠の中ですが、かなり違いがあるのが分かっていただけたと思います。
Cloud選定の際には、こんなところも面白いなと思っていただけるといいなと思っています。