この記事は 『Supership Advent Calendar 2016』 2日目の記事です。今は 2016/12/07(水)です。
はじめに
この記事では、 Amazon Aurora (MySQL 互換) のレプリケーションに関連する機能をまとめています。ざっと下記の内容についてまとめています。この情報は 2016/12/02(金) の情報です。
- Amazon RDS for MySQL と Amazon Aurora のレプリケーション機能の違い
- レプリカラグについて
- Aurora でレプリケーションを構成するときに注意するべきこと
- レプリカが1台以上ないと SLA が保証されない
- エンドポイントが複数ある
- 読み込みエンドポイント
- 昇格階層(プライオリティティア)
今後 Aurora の機能追加に伴い、ドキュメントの内容が実情に合わなくなる場合もあると思いますので、ご注意ください。
Amazon Aurora とは
Amazon Aurora は、2014年の AWS re:Invent で発表された AWS 上の MySQL 互換のフルマネージドデータベースサービスです。その後、パブリックプレビューや正式公開、東京リージョンでの利用開始などを経て、「AWS サービスの中で最も成長が早い」(クラウド Watch)サービスともされています。そして、ついに 2016年の re:Invent では PostgreSQL 互換エンジンが発表されました。(Publickey)
PostgreSQL 互換エンジンは現在プレビュー中なので、私は残念ながらまだ試せていないのですが、非常に期待をしている人も多いのでないでしょうか?
なんといっても、 Aurora の魅力は、ほぼ MySQL と同じ、と言えるくらいの互換性と、開発者が手をわずらわすことなく手軽にスケールアップ・スケールアウトすることができるアーキテクチャです。これは、現在の Aurora (MySQL互換) と変わらず PostgreSQL 互換エンジンにも提供されるのではないでしょうか?
この記事では、 MySQL 互換の Aurora を使用した経験をもとに、 Aurora のスケールアウトの手段として提供されているレプリケーション機能と注意点についてわかやすくまとめてみたいと思います。
Amazon Aurora (MySQL 互換) と Amazon RDS for MySQL について
Amazon RDS for MySQL(以下 RDS(MySQL) とします)と Amazon Aurora (MySQL互換 同 Aurora(MySQL))は、ともに AWS 上の Amazon RDS (Relational Database Service) 上で展開されているフルマネージドデータベースサービスです。
RDS(MySQL)、Aurora(MySQL) ともに、自社サーバーや、 Amazon EC2 上で MySQL を使用するときと比べると、利用できる構成や調整できるパラメーターなどに制限はあるものの、 OS などの管理の手間を省けることから、非常に省力化が可能なサービスとなっています。
特に Aurora(MySQL) では、クラウドに最適化されたアーキテクチャにより、 RDS(MySQL) やいわゆる商用データベースエンジンに比べても遜色のないパフォーマンス、 64TB まで自動拡張される共有分散ストレージや、障害時の自動復旧が短時間なこと、 RDS(MySQL) に比べて非常に低いレイテンシで読み出し専用のレプリケーションインスタンスを15台まで作成可能なことなどから、非常に広い範囲で採用されているとされています。
Amazon RDS for MySQL と Amazon Aurora のレプリケーション機能の違い
RDS(MySQL) と Aurora(MySQL) は、それぞれ読み出し専用のリードレプリカという機能を提供しています。この機能は Aurora でも使用できるのですが、その実装方法に一部違いがあります。
簡単に言うと、 MySQL ではマスターでバイナリログを出力し、そこからスレーブにレプリケーションしているのに対して(図1a)、 Aurora では全てのマスターとスレーブでストレージを共有していて、マスターがバックエンドに書き込みをすると、それが自動的にスレーブにも共有される仕組みになっています(図1b)。
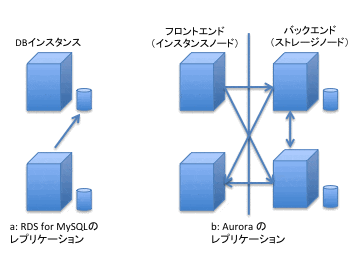
図1: RDS(MySQL) と Aurora のレプリケーションの違い
このため、 RDS(MySQL) に比べて、 Aurora ではレプリケーションをしてもマスターとなるインスタンスへの負荷が低く、また、マスターからスレーブにデータを複製するタイムラグ(レプリカラグ)も非常に低く抑えられるとしています。
レプリカラグについて
RDS(MySQL) に限らず、データベースサーバーのレプリケーションをして、そのデータがレプリケーション先から読み出し可能になるまでにはある程度以上のレイテンシが発生します。このレイテンシを RDS(MySQL) と Aurora(MySQL) ではレプリカラグと呼んでいます。
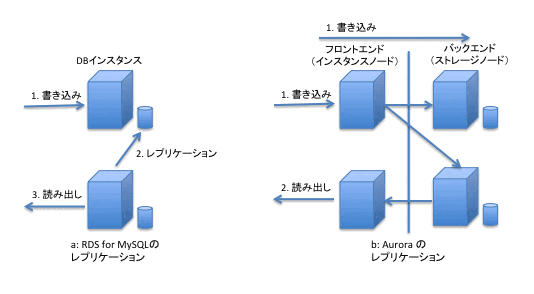
図2: RDS(MySQL)でのレプリカ読み出しと Aurora(MySQL) のレプリカ読み出し
従来、 RDS(MySQL) では、先に述べたようにバイナリログから他のサーバーへのデータコピーとサーバー内での反映作業を行う必要がありました(図2a)。通常動作時には、レプリカラグはおおむね数百ミリ秒に収まることが大半です。しかし、マスターとなるサーバーに負荷がかかったときには、その負荷自体とデータ量が大量になること、その反映作業を行うことから、レプリカラグが数秒 〜 数百秒まで拡大してしまうこともあり、大量のデータを処理するのに向いているとは言えませんでした。
しかし、 Aurora(MySQL) では、ストレージがバックエンドで共有され、マスターとなるストレージが各ストレージに書き込むほか、各ストレージ間でもデータの整合性を取る処理が行われるため、そのレプリカラグはおおむね数百ミリ秒以下に収まるとされています(図2b)。また、実際に利用している中でレプリカラグが数百ミリ〜数秒を超えたことは今のところありません。
Aurora でレプリケーションを構成するときに注意するべきこと
レプリカが1台以上ないと SLA が保証されない
RDS(MySQL) では、 SLA は Multi-AZ 構成、つまり、 AWS の複数のアベイラビリティゾーンにまたがってアクティブ/スタンバイ構成を採った時に保証されるものとなっていました。
Aurora(MySQL) では、スタンバイ機を用意する代わりに、リードレプリカを利用することができます。つまり、 Aurora(MySQL) を利用する場合、 RDS(MySQL) と同じ2台構成が標準ですが、2台目をリードレプリカとして使用することができます。
しかし、次節で述べる通り、 Aurora(MySQL) でリードレプリカを利用する際には、アプリケーションの構成上気をつける必要がある点があります。
エンドポイントが複数ある
RDS(MySQL) では、 Multi-AZ 構成を採ることで、一時的なコネクションロストはあるものの、基本的には同じホストを参照していれば問題ありませんでした。
また、リードレプリカについても、 Multi−AZ 構成で、コストは倍になってしまうものの、アプリケーション側では同じホストを参照することで対応することができました。
Aurora(MySQL) では、 Multi-AZ 構成の代わりに、2台目のインスタンスをリードレプリカとして使用することができます。
しかし、この構成は、特にリードレプリカを想定しているアーキテクチャでアプリケーションを構築している場合に注意が必要です。
Aurora では、各インスタンスを指す URL (インスタンスエンドポイント)と、常にマスターを指す URL (クラスターエンドポイント)、そして、リードレプリカに対して負荷分散を行いながらアクセス可能な URL (リーダーエンドポイント)がそれぞれ異なります。
そのため、最低限、クラスターエンドポイントとリーダーエンドポイントを使用して、読み書き可能、読み込みのみ可能なエンドポイントを区別する必要があります。
さらに、リーダーエンドポイントは2016年9月に追加された機能のため、それ以前に Aurora(MySQL) を利用しているユーザーは、クラスターエンドポイントとインスタンスエンドポイントをアプリケーション側で区別する必要がありました。
クラスターエンドポイントが指しているインスタンスがダウンした場合、 CNAME の切り替えによって、クラスターエンドポイントのフェイルオーバーが行われます。
インスタンスエンドポイントを使用している場合は、このような場合に備えてアプリケーションを構築する必要があります。
| エンドポイント名 | 役割 | ホストに対して固定かどうか |
|---|---|---|
| インスタンスエンドポイント | それぞれのホスト | 固定 |
| クラスターエンドポイント | 常に書き込みをするホスト(ライターインスタンス)を指す | 可変 |
| 読み込みエンドポイント | 読み込みホスト(リーダーインスタンス)のどれか | 可変 |
また、インスタンスエンドポイント、クラスターエンドポイント、読み込みエンドポイントとも、接続先のインスタンスが再起動などで接続が失われると、それぞれのエンドポイントに対して再度再接続をし直して処理を続行する必要があります。
読み込みエンドポイント
前項で触れたとおり、現在 Aurora(MySQL) には3種類のエンドポイントがあります。その一つである読み込みエンドポイント(リーダーエンドポイントとも呼ばれます)は比較的新しく、2016年9月に導入された機能です。
クラスターエンドポイント、読み込みエンドポイントは全て特定のインスタンスのホスト名に対する CNAME として提供されます。クラスターエンドポイントはある時点での特定のインスタンスを指しますが、読み込みエンドポイントは特定のインスタンスではなく、リードレプリカのうちどれかのホストを返します。
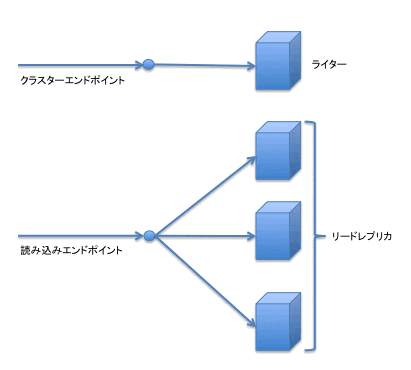
図3: クラスターエンドポイントと読み込みエンドポイント
読み込みエンドポイントを利用することで、複数のアプリケーションサーバーからの負荷をリードレプリカに振り分けることができます。ただし、それぞれのインスタンスの負荷を見ているわけではないようです。
また、クエリレベルで負荷分散をする必要があるときは、アプリケーション側で行う必要があると AWS のドキュメントにも明示されています。
昇格階層(プライオリティティア)
Aurora は1台の書き込みインスタンスと、その他のリードレプリカで構成されています。 RDS(MySQL) とは異なり、 Multi-AZ 構成はリードレプリカを用いて構成されるので、特定のホストをフェイルオーバー先として選択することができません。
そのときに利用可能なのが昇格階層(プライオリティティア)です。インスタンスそれぞれに tier-0 (最高) 〜 tier-15 (最低)までの昇格階層が設定でき、書き込みインスタンスが何らかの理由で停止したときには優先度が高い階層を設定しているインスタンスにフェイルオーバーするという機能です。
この機能では1階層に複数のインスタンスを設定することができるので、インスタンスサイズが高い順に優先度を設定したり、機能別に優先度を設定することができます。
また、同一の階層に複数のインスタンスが設定してある場合は、インスタンスサイズが大きい方が優先されます。優先度とインスタンスサイズが同じ場合、どのインスタンスにフェイルオーバーが行われるかは制御できません。
まとめ
駆け足で Aurora(MySQL) のレプリケーション機能を見てきました。 Aurora(MySQL) はそこまで新しいサービスとはいえない方ではあるのですが、随時たくさんの機能追加がなされているので、ここに書かれていることもすぐに古くなってしまうのだと思います。
その際に Aurora(MySQL) を利用している人が、同じような記事を書いてくれるよう、 Aurora ユーザーが増えることを願っています。
それと、更新リクエストも随時お待ちしています (-;