概要
CSVのような単純な書式で記述されたファイルをParaviewで読み込むときに便利なTable to Structured Gridフィルタの使い方について簡単に説明します.
- 2019年2月6日 Whole Extentの説明を修正し,補足を追加.
使用環境
- Windows 10
- Paraview ver. 5.5.2-64bit
Paraview
Paraviewは,数値計算結果の可視化に用いるオープンソースソフトウェアです.多くの入力形式に対応し,非常に強力な可視化機能を備えています.よっぽどのこだわりがなければ,大抵の可視化はParaviewで完結できます.ただ,Paraviewは中々クセの強いソフトなので,使いこなすには慣れが必要です.
こういった多機能ソフトは「非常に簡単なことが簡単にできない」というのがお約束なのですが,Paraviewもその例に漏れません.
簡単に済ませたい簡単なこととは何でしょうか?それは,下図のような格子状に配置された点における物理量をサクッと表示することです.
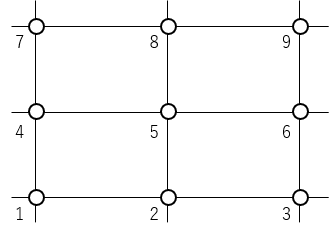
このような格子状に配置された点のデータは,配列の値を繰り返し処理で出力することで保存されます.
integer :: output
open(newunit=output, file = "velocity.txt")
do k = 1, Nz
do j = 1, Ny
do i = 1, Nx
write(output, '(6F)') dble(i-1)*dx, dble(j-1)*dy, dble(k-1)*dz, u(i,j,k), v(i,j,k), w(i,j,k)
end do
end do
end do
close(output)
Nx,Ny,Nzはそれぞれx,y,z方向の点数(1,2,3次元目の配列要素数),dx,dy,dzはそれぞれx,y,z方向の点の幅です.このような保存の仕方をすると,次のような単純な書式のファイルが得られます.
0.0 0.0 0.0 0.0 0.0 0.0
0.1 0.0 0.0 1.0 0.0 0.0
...
0.0 0.1 0.0 1.0 0.1 0.0
0.1 0.1 0.0 1.0 0.2 0.0
...
0.0 0.0 0.1 1.0 0.5 0.5
0.1 0.0 0.1 1.0 0.7 0.2
...
0.0 0.1 0.1 1.0 0.0 2.5
0.1 0.1 0.1 1.0 0.2 1.0
数値は適当ですが,ファイルの1,2,3列目に座標値,4,5,6列目に物理量の値が記述されてます.単純にスペースで区切っていますが,これをカンマで区切ればCSVファイル形式で出力されます.
都合上,これをCSVファイルとよびますが,区切りはスペースでもカンマでもかまいません.
VTKファイルフォーマット
こういったデータ構造の場合,Paraviewの基盤となっているVTK(Visualization Tool Kit)でファイルフォーマット1が定義されています.
- Structured Points (Image data)
- Rectilinear Grid
- Structured Grid
詳しくは言及しませんが,これらはファイル書式に関する記述が必要です.VTK側でもモジュールなどを提供していますが,そういった追加のモジュールを利用せず,CSV程度の書式をサクッと出力して可視化したいという要求は当然あるでしょう.そこで活躍するのが,本記事で紹介するTable to Structured Gridフィルタです.
Table to Structured Gridフィルタ
Table to Structured Gridフィルタの使い方を簡単に説明します.なお,Table to Structured Gridフィルタを使ってParaviewで処理できる形式に変換するには,少なくともx, y, z座標の情報が必要です.2次元シミュレーションなどでx, y座標の情報しかない場合でも,z座標に相当するところに0を書いておく必要があります2.
手順
Paraviewを起動する
インストールしたParaviewを起動してください.
CSVファイルを読み込む
CSVファイルをParaviewにドラッグアンドドロップするか,ParaviewのFile→Openでウィンドウを開き,そこからCSVファイルを選択してください.
入力したCSVファイルのプロパティを設定する
Pipeline Browserに読み込んだCSVファイルの名前が現れ,Browser下部でプロパティが設定できるようになります.
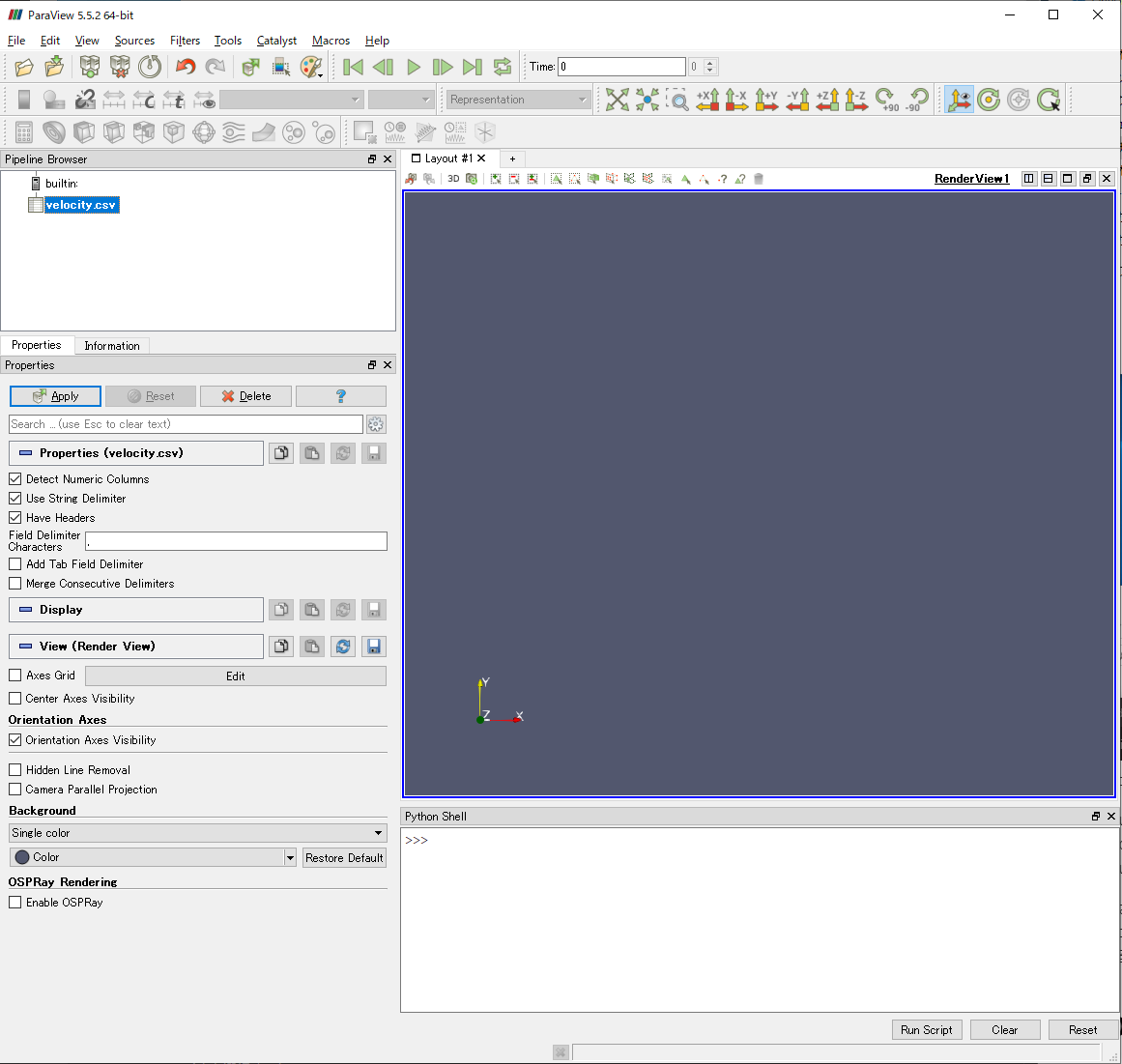
ここでは3個の設定を確認します.
Have Headers
読み込んだCSVファイルの1行目に各列の名称を記述していれば,チェックを付けたままにしておきます.2行目以降がデータと認識されます.
x y z u v w
0.0 0.0 0.0 0.0 0.0 0.0
0.1 0.0 0.0 1.0 0.0 0.0
...
0.0 0.1 0.0 1.0 0.1 0.0
0.1 0.1 0.0 1.0 0.2 0.0
...
0.0 0.0 0.1 1.0 0.5 0.5
0.1 0.0 0.1 1.0 0.7 0.2
...
0.0 0.1 0.1 1.0 0.0 2.5
0.1 0.1 0.1 1.0 0.2 1.0
特にそういう情報を記述していないのであれば,チェックを外します.
Field Delimiter Characters
列を区切る文字を指定します.CSVファイルではカンマが区切り文字ですが,スペースで各列を区切って出力している場合は,Field Delimiter Charactersのテキストボックスに入力されているカンマをスペースに置き換えます.
複数個のスペースで区切っていたとしても,入力するのは1文字だけでかまいません.
Merge Consecutive Delimiters
このプロパティは,列を複数個のスペースで区切っていたときに,そのスペースをまとめて区切りと認識させたいときにチェックを入れます.
複数個のスペースで区切ってるのにこのチェックを付けないと,余分なスペースも数値データとして認識されてしまいます.
読み込まれたデータの確認
これらの設定を確認してからApplyボタンを押すと,ParaviewのRenderView(描画ウィンドウ)にSpreadSheetView 1と名付けられた表が現れます.
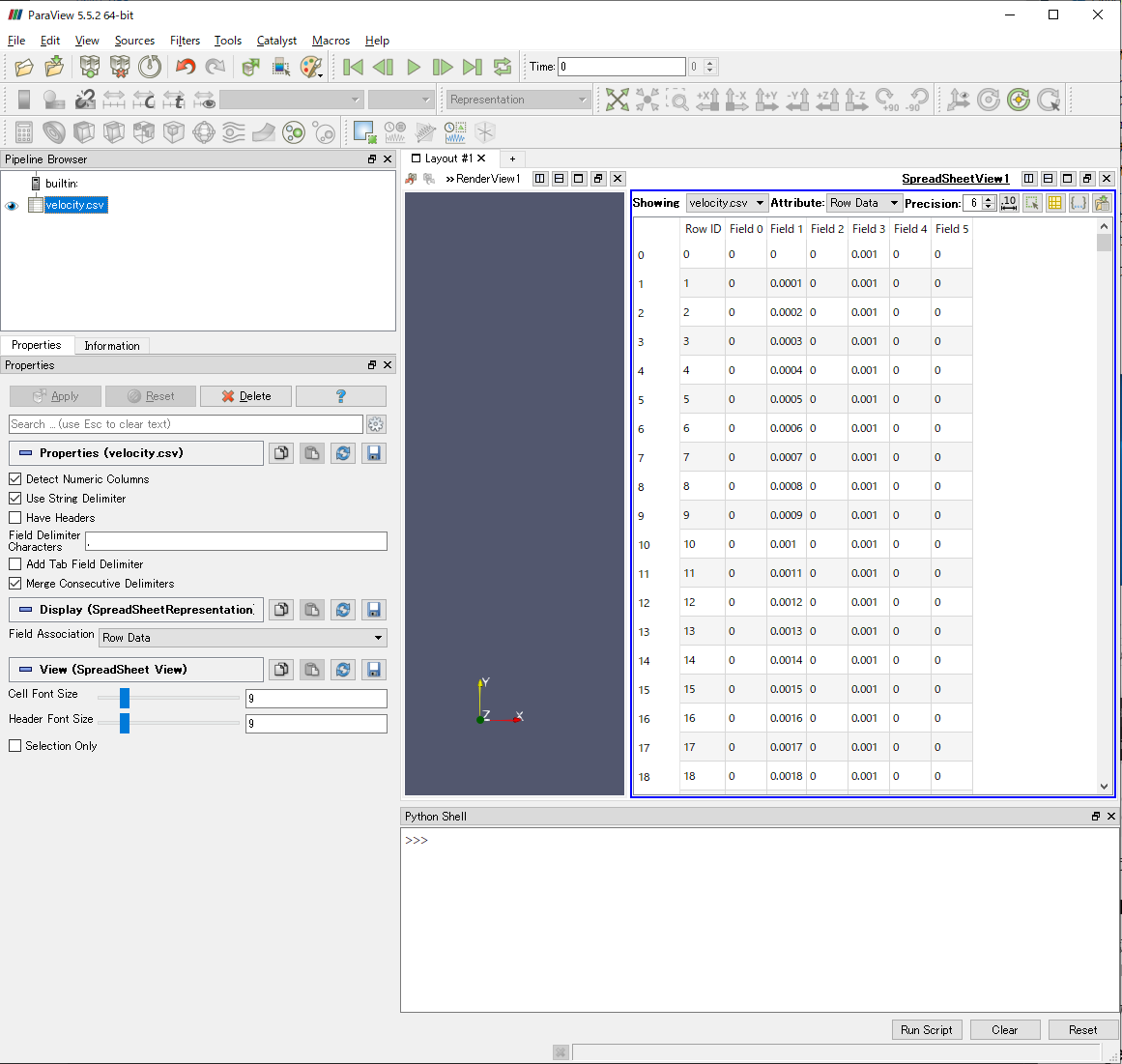
最上段は各列に付けられた名前です.ファイルの1行目に各列の名称を記述していれば,Field 0,Field 1・・・となっている箇所が任意の名称になります.なお,最左列のRow IDはParaviewが勝手に付けたデータの番号なので,気にしないでください.
これでデータを読み込めたのですが,このデータのままではParaviewで可視化することができません.そこでTable to Structured Gridフィルタの出番です.
Table to Structured Gridフィルタの適用
私の環境では,SpreadSheetViewを表示したままフィルタを適用すると,RenderViewに結果が表示されません.そのため,フィルタ適用前にSpreadSheetViewを閉じます.
Table to Structured Gridフィルタは,Filter→Alphabeticalから選びます.Alphabeticalには全てのフィルタがアルファベット順に表示されるので,画面を埋め尽くすほど多くのフィルタが現れます.
Table to Structured Gridフィルタを適用すると,Pipeline Browserにフィルタのプロパティが表示されます.ここに,可視化データへ変換する時の設定を入力します.
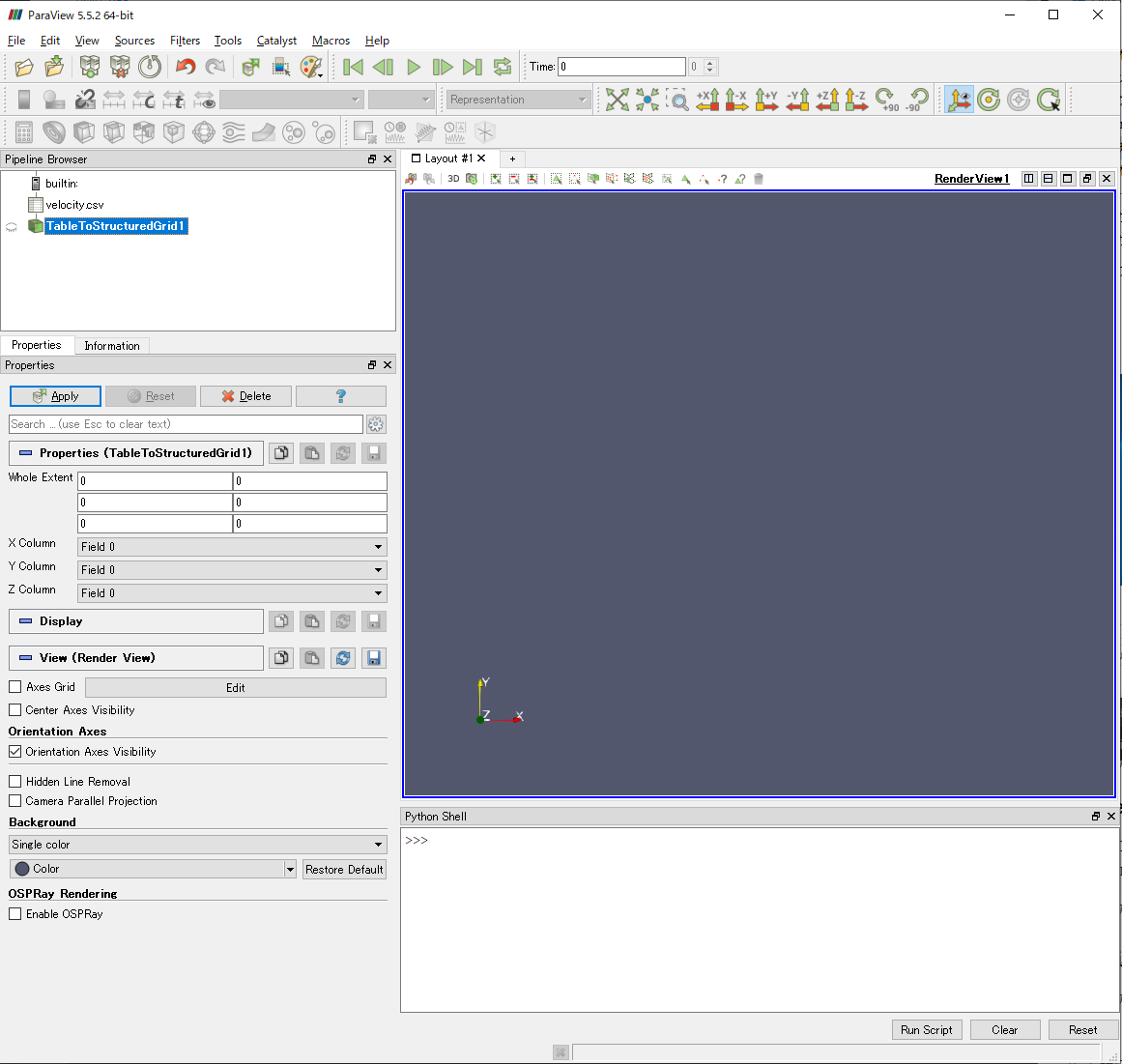
ここでは,大きく分けて2個の設定を確認します.
Whole Extent
1次元的に並んだデータに対して,x,y,z方向のデータの個数を指定する項目です.不親切にテキストボックスが2 × 3個並んでいますが,1,2,3行目がそれぞれx,y,z方向に対応しています1,2,3番目に変化する次元のデータ個数を表しています.左側は基本的に0でよく,右側に各方向のデータの個数-1を入力してください.C言語系統の言語になじみの深い人は,配列の各次元の要素数だと認識すればわかりやすいかも知れません.
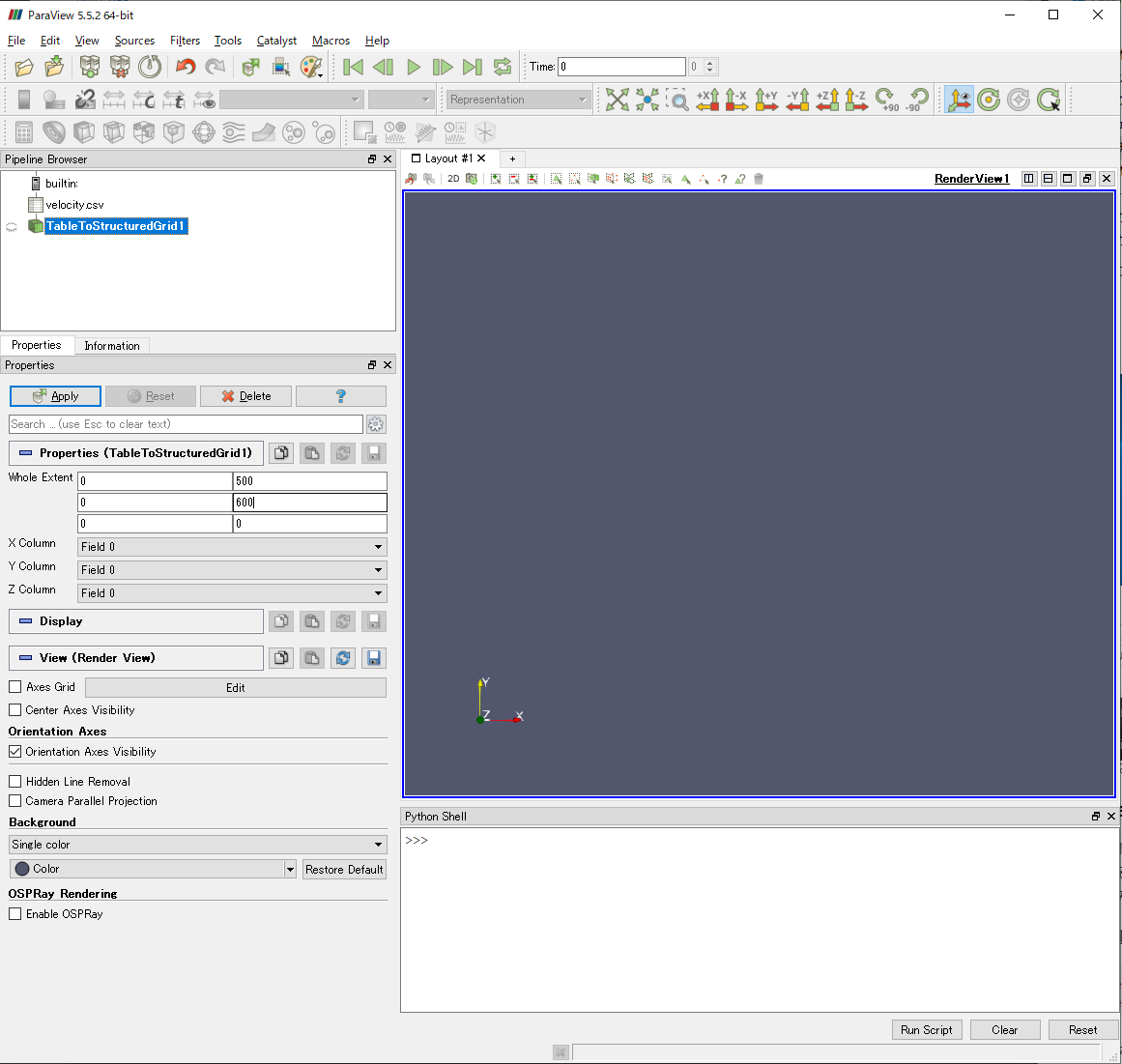
この記事で用いているCSVファイルを出力したプログラムでは,x,y方向の個数が以下のように定義されています.
integer,parameter :: Nx = 501
integer,parameter :: Ny = 601
そのため,x,y方向はそれぞれ501個,601個のデータがあります.2次元なので,z方向のデータは1個だけです.こういう場合は,
| 0 | 500 |
| 0 | 600 |
| 0 | 0 |
と入力してください.0から500までの501個,0から600までの601個,0から0までの1個のデータが各方向に存在しているという意味です.
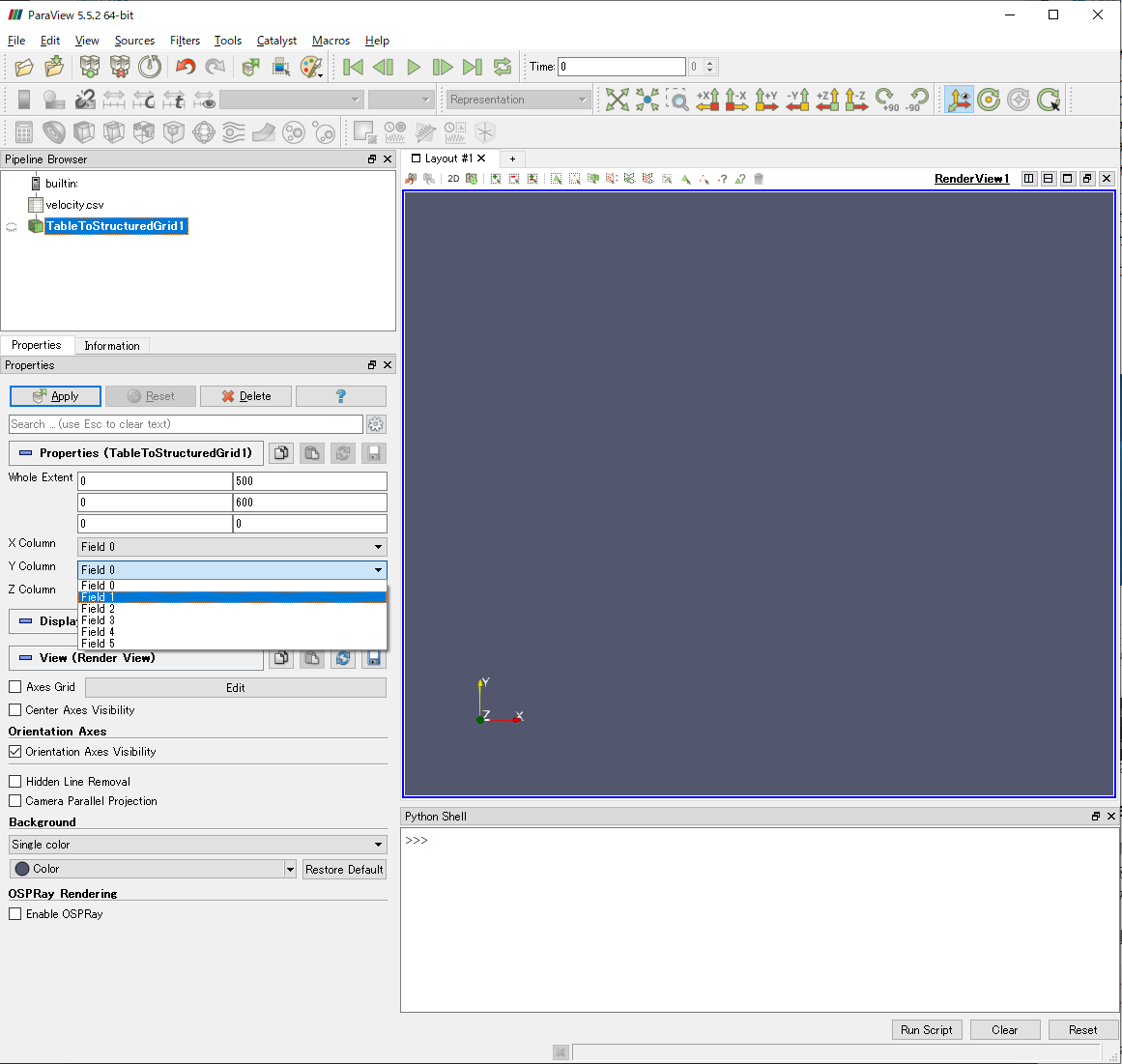
X Column, Y Column, Z Column
ここでは,各方向のデータがSpreadSheetViewのどの列に対応しているのかを,プルダウンメニューから割り当てます.このとき,Headerとして各列の名称を記述していれば,Headerで名付けた名前が現れます.
| X Column | Field 0 |
| Y Column | Field 1 |
| Z Column | Field 2 |
各Columnと列データ,それらの個数(Whole Extent)がきちんと対応していないと,思った通りの表示にはなりません.
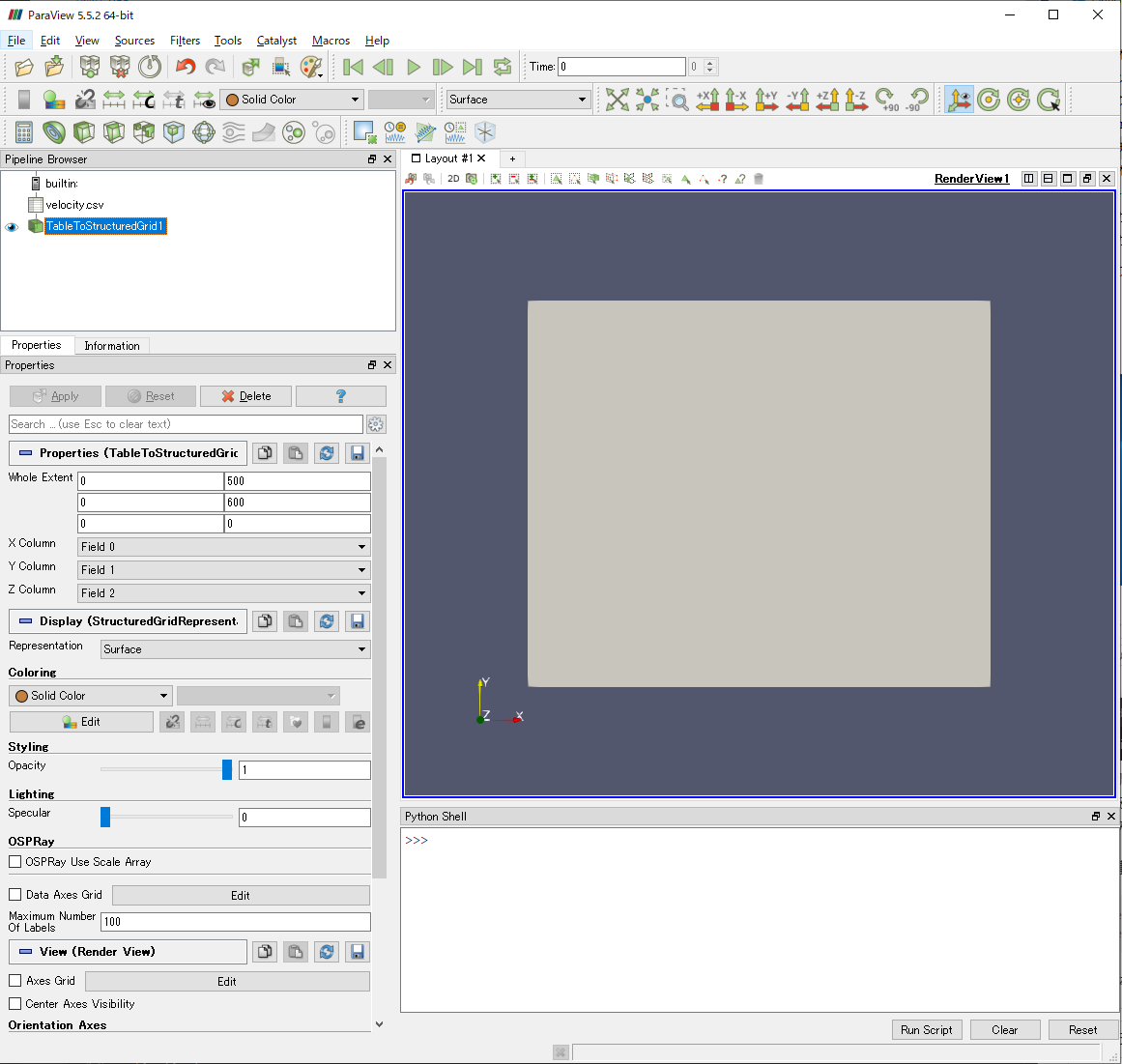
設定が終われば,Applyボタンを押して設定を完了します.
RenderViewに灰色の四角が表示されれば成功です
可視化
Paraviewで可視化できる形式に変換されたので,あとはParaviewを使って可視化を行います.
例えば,Coloringを変更すれば,各物理量を確認することができます.
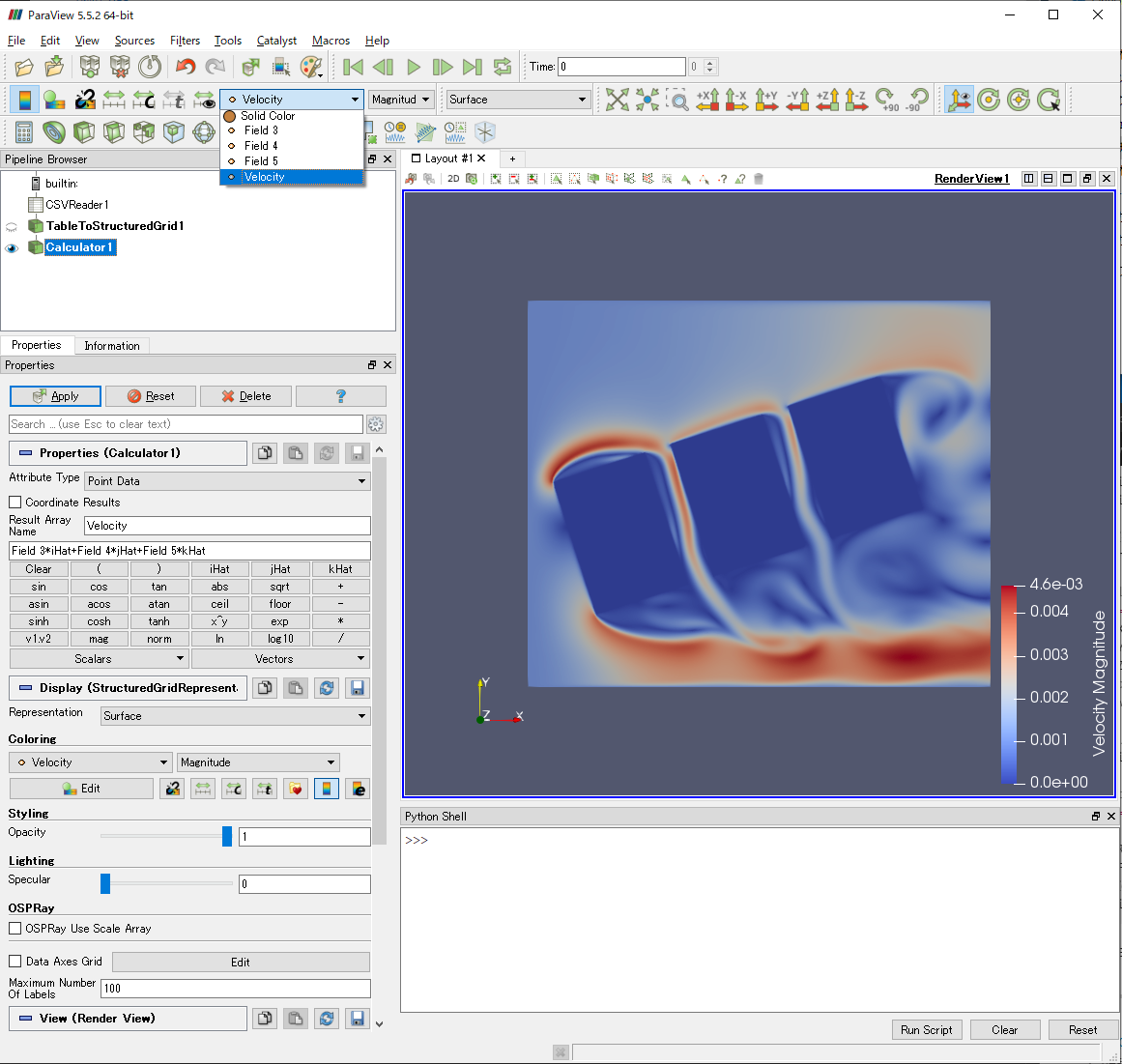
読み込まれたデータは,Field 3,Field 4,Field 5と名付けられていることが確認できます.
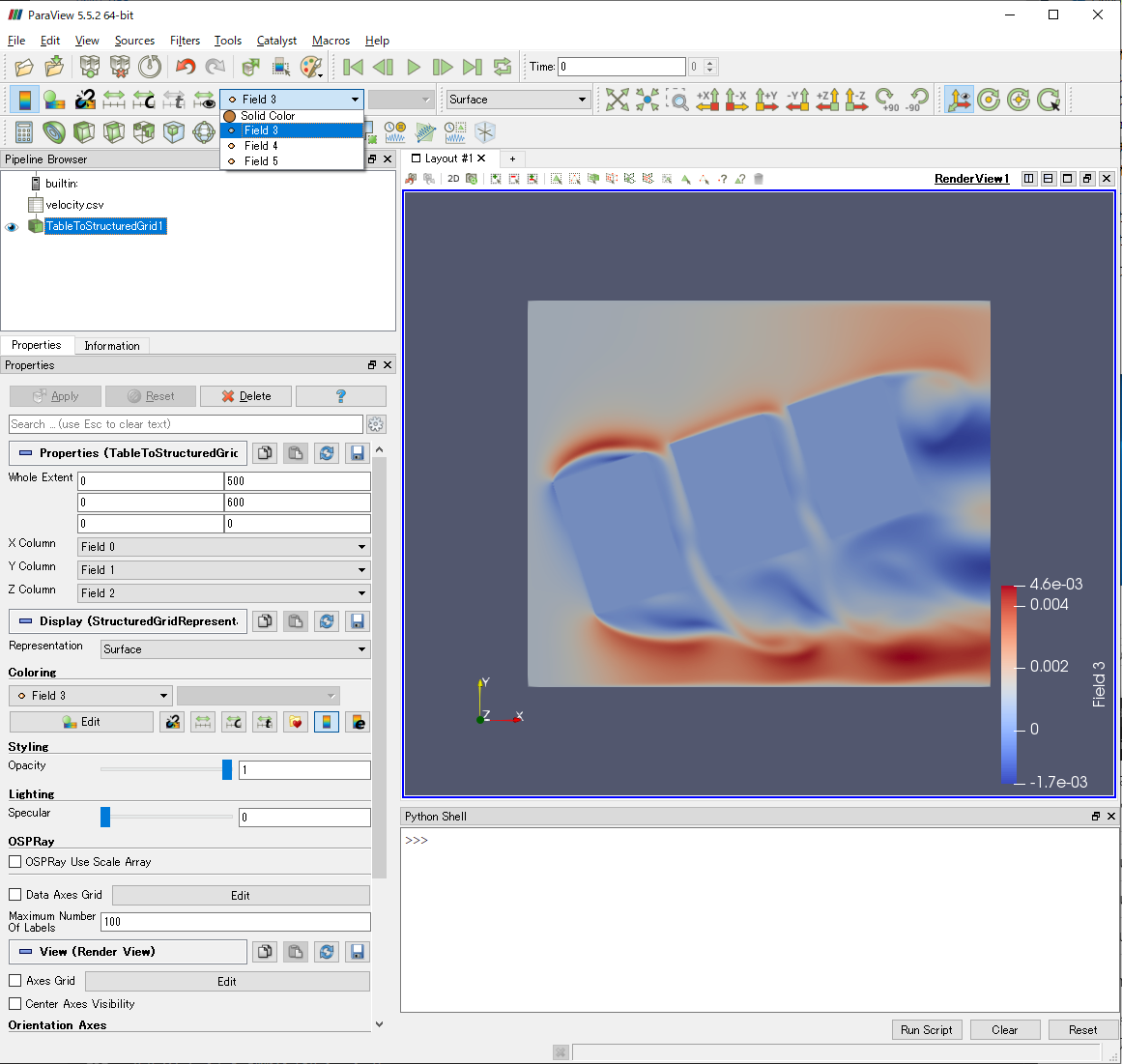
ただし,こうやって読み込んだデータ(Field 3,Field 4,Field 5)は,ベクトルの成分とは認識されないため,速度ベクトルを描画する際に1次元方向のデータしか利用できません.
試みにGlyphで速度ベクトルを描いてみましたが,ベクトルとして認識されないので,Field 3(x方向成分のデータ)しか用いることができません.
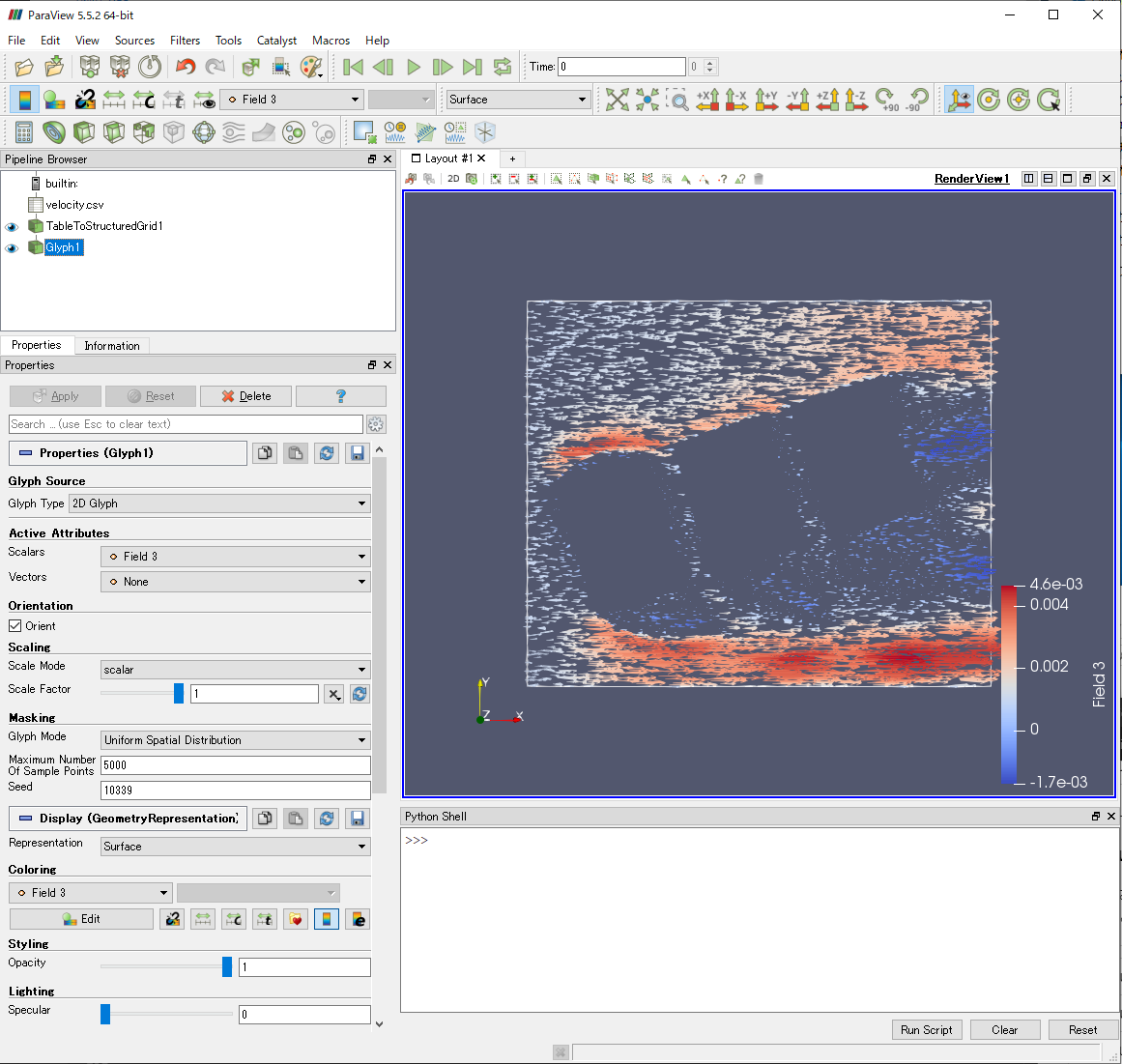
読み込んだデータのベクトル化
各成分のデータをまとめてベクトルとして認識させることは,Table to Structured Gridフィルタではできないので,フィルタ適用後のデータに,さらにCalculatorフィルタを適用します.Calculatorフィルタを使うと,複数のデータからベクトルを作ることができます.
Filer→Alphabetical→Calculatorを選択します.
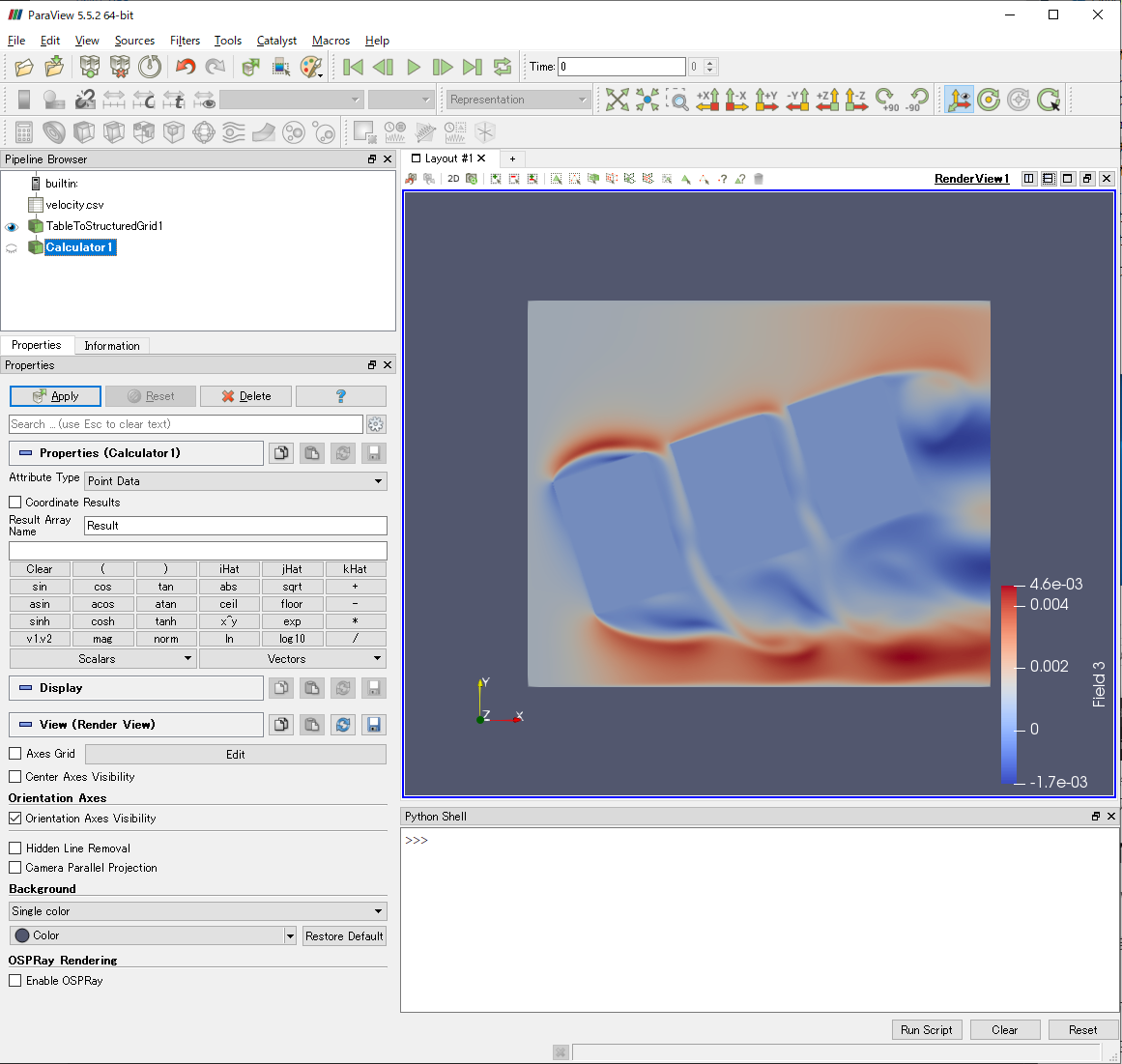
Calculatorフィルタでは,2個の設定を行います.
Result Array Name
作成したベクトルの名前をここで設定します.標準でよければResultという名前になりますが,ここではせっかくなのでVelocityと名付けました.
計算式
Resutl Array Nameの直下に細長いテキストボックスがあります.ここに以下のように式を入力します.
Field 3*iHat+Field 4*jHat+Field 5*kHat
iHat, jHat, kHatはベクトルの成分を作るための機能で,各軸方向の単位ベクトルを意味していると捉えてください.
Field 3,Field 4,Field 5については,列の名称を設定している場合にはそれぞれ置き換えてください.Scalarsとかかればプルダウンメニューからも選択できます.iHatや*については,ボタンを押して入力しても全く問題ありません.

Applyボタンを押すと,新たにVelocityという名前のデータが作成されます.
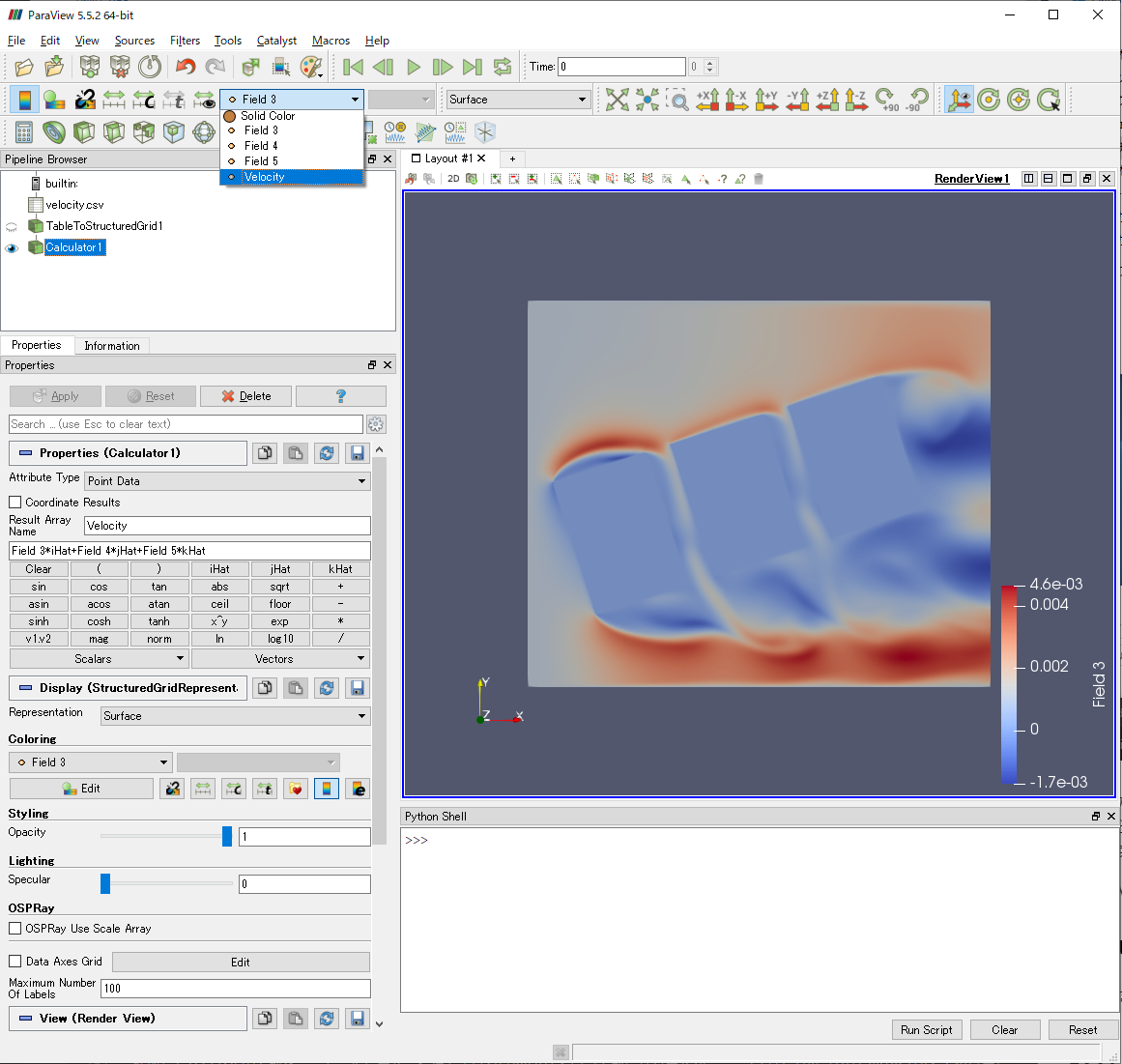
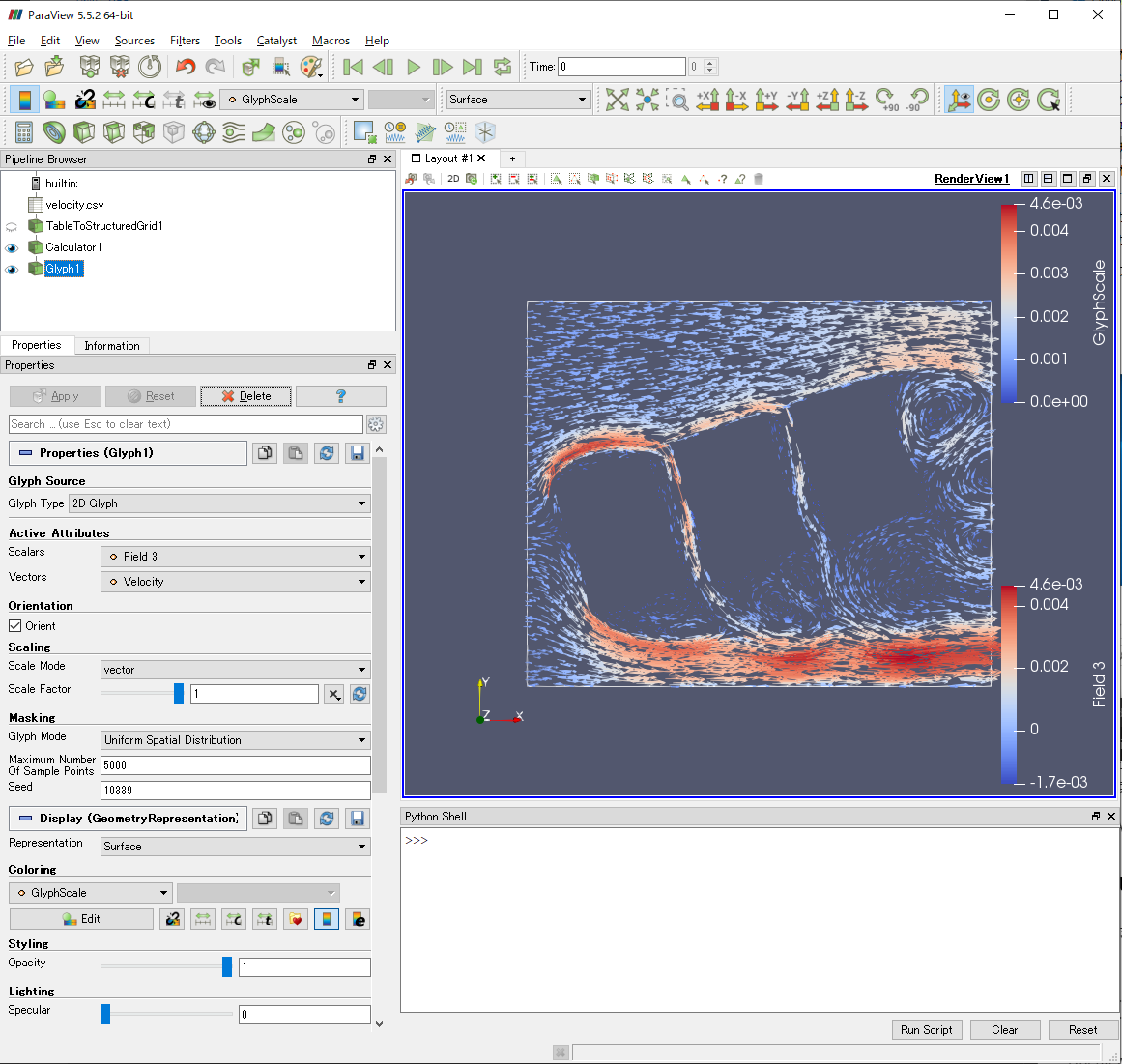
先ほどと同様に,Glyphで速度ベクトルを描きました.NoneとなっていたVectorsのオプションにVelocityがあることで,各方向の速度が認識され,角柱後流の渦が可視化されました.
Pythonスクリプト
Paraviewは,これらの一連の流れをすべてPythonスクリプトで実行できます.
Pythonスクリプトは,Python Shellから実行します.View→Python Shellを選択すると,Python Shellが起動します.
1行ずつ実行してもよいのですが,Run Scriptボタンから既存のPythonスクリプトを実行することができます.
どのような命令を書けばよいのかは,はっきり言ってサッパリわかりません.Tools→Start Traceで一連の作業をPythonスクリプトとして記録できるので,記録したファイルから必要なさそうな記述を削除し,最低限の処理だけ残します.
記録したスクリプトで冗長な命令を削除していくと,以下のようなスクリプトができあがりました.Pythonに関連するモジュール以外は通常のPython(2系ですが)と同じなので,繰り返しを書いてファイルを次々に読み込むといったことも,配列にファイル名を並べて一気に複数のファイルを読むこともできます.
from paraview.simple import *
paraview.simple._DisableFirstRenderCameraReset()
# 区切りに関係なくCSVファイルとしてファイルを読み込み
velocity = CSVReader(FileName=['ここに読み込みたいファイルをフルパスで記述する'])
# ヘッダや区切り文字の設定
velocity.HaveHeaders = 0
velocity.MergeConsecutiveDelimiters = 1
# 設定を適用
renderView1 = FindViewOrCreate('RenderView1', viewtype='RenderView')
# Table To Structured Gridフィルタの設定
grid = TableToStructuredGrid(Input=velocity)
grid.XColumn = 'Field 0'
grid.YColumn = 'Field 1'
grid.ZColumn = 'Field 2'
# Properties modified on grid
grid.WholeExtent = [0, 500, 0, 600, 0, 0]
# フィルタの適用
gridDisplay = Show(grid, renderView1)
# Calculatorフィルタの設定
calc = Calculator(Input=grid)
calc.ResultArrayName = 'Velocity'
calc.Function = 'Field 3*iHat+Field 4*jHat+Field 5*kHat'
# 設定の適用と結果の表示
calcDisplay = Show(calc, renderView1)
Pipeline Browserの表示が若干変化していますが,正しくデータが読めているようです.
まとめ
CSVファイルをParaviewで読み込むときに便利なTable to Structured Gridフィルタの使い方について簡単に説明しました.
スカラ量については,他にも解説が存在していますが,ベクトルにする方法までは書かれていなかったので,Calculatorフィルタについても言及しました.
さすがにドラッグアンドドロップで可視化とまではいきませんでしたが,Pythonスクリプトも合わせればそれなりに手軽に表示できるのではないかと思います.
補足 Whole Extentに入力する数字
Whole Extentにおいて,
1,2,3行目が1,2,3番目に変化する次元のデータ個数を表しています.
と述べました.これを適当なプログラムで確認してみます.
x, y, z方向にそれぞれ31, 21, 11点の値を設け,出力時のカウンタを最外からk-j-i, i-j-kと入れ替えてファイルを出力し,Paraviewで読み込んでみます.
program main
implicit none
integer,parameter :: Nx = 31
integer,parameter :: Ny = 21
integer,parameter :: Nz = 11
real(8),parameter :: Lx = 1d0
real(8),parameter :: Ly = 1d0
real(8),parameter :: Lz = 1d0
real(8),parameter :: dx = Lx/dble(Nx-1)
real(8),parameter :: dy = Ly/dble(Ny-1)
real(8),parameter :: dz = Lz/dble(Nz-1)
integer :: i,j,k
integer :: output
real(8) :: u(Nx,Ny,Nz)
real(8) :: v(Nx,Ny,Nz)
real(8) :: z(Nx,Ny,Nz)
do k = 1,Nz
do j = 1,Ny
do i = 1,Nx
u(i,j,k) = (k-1)*(Nx*Ny) + (j-1)*Nx + i
end do
end do
end do
open(newunit = output, file = "kji.txt")
!k-j-iループ
do k = 1,Nz
do j = 1,Ny
do i = 1,Nx
write(output,'(4F)') (i-1)*dx, (j-1)*dy, (k-1)*dz, u(i,j,k)
end do
end do
end do
close(output)
open(newunit = output, file = "ijk.txt")
!i-j-kループ
do i = 1,Nx
do j = 1,Ny
do k = 1,Nz
write(output,'(4F)') (i-1)*dx, (j-1)*dy, (k-1)*dz, u(i,j,k)
end do
end do
end do
close(output)
end program main
k-j-iループ
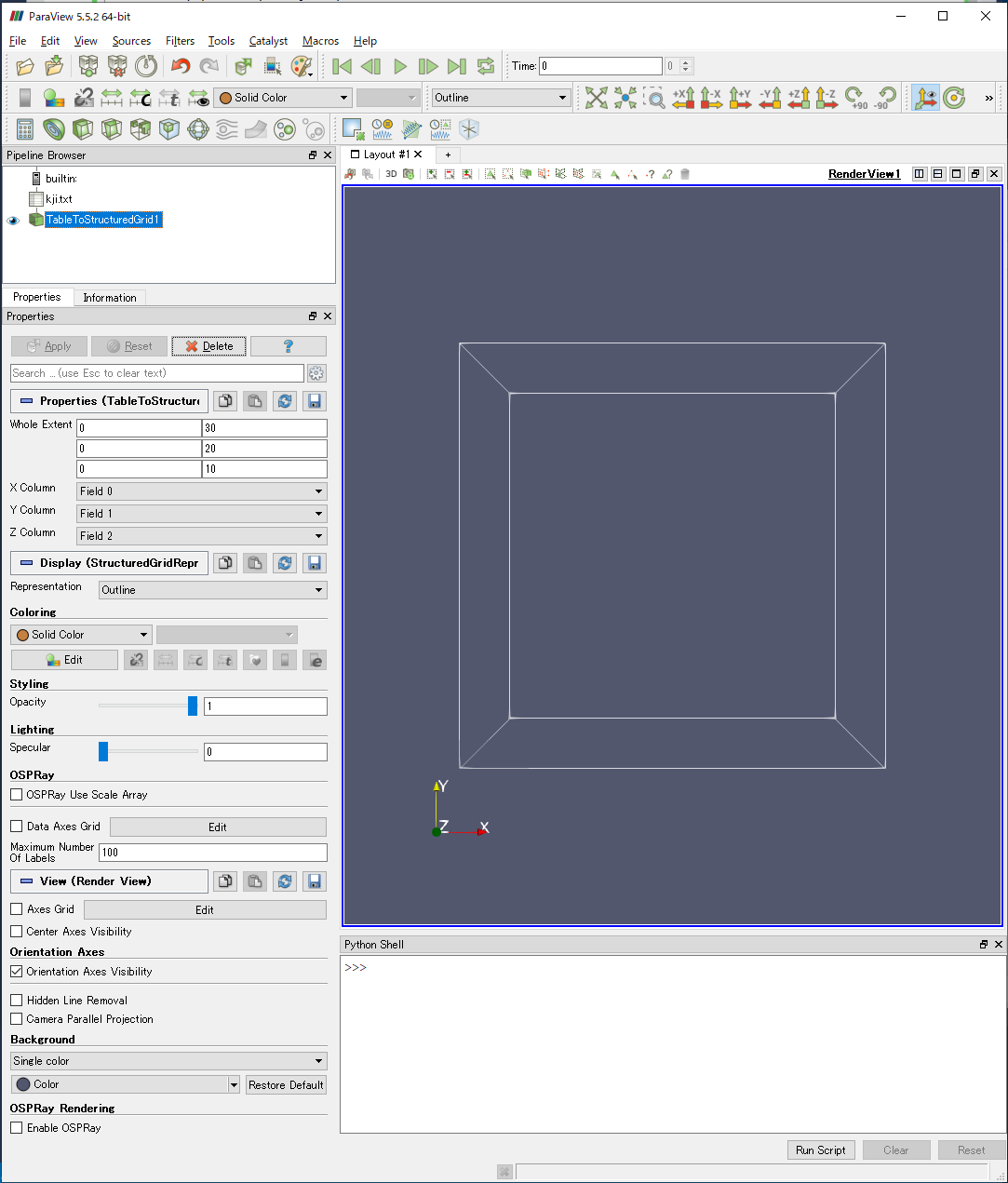
k-j-iループはiが3重ループの一番内側にあるため,出力されたファイルでは,座標はi,j,kすなわちx, y, z座標値の順に変化します.
そのため,Whole ExtentおよびColumnをそれぞれ次のように設定しなければなりません.
| 0 | 30 |
| 0 | 20 |
| 0 | 10 |
| X Column | Field 0 |
| Y Column | Field 1 |
| Z Column | Field 2 |
この設定でTable to Structured Gridを適用すると,RenderViewに立方体が表示され,正しく読み込まれていることがわかります.
i-j-kループ
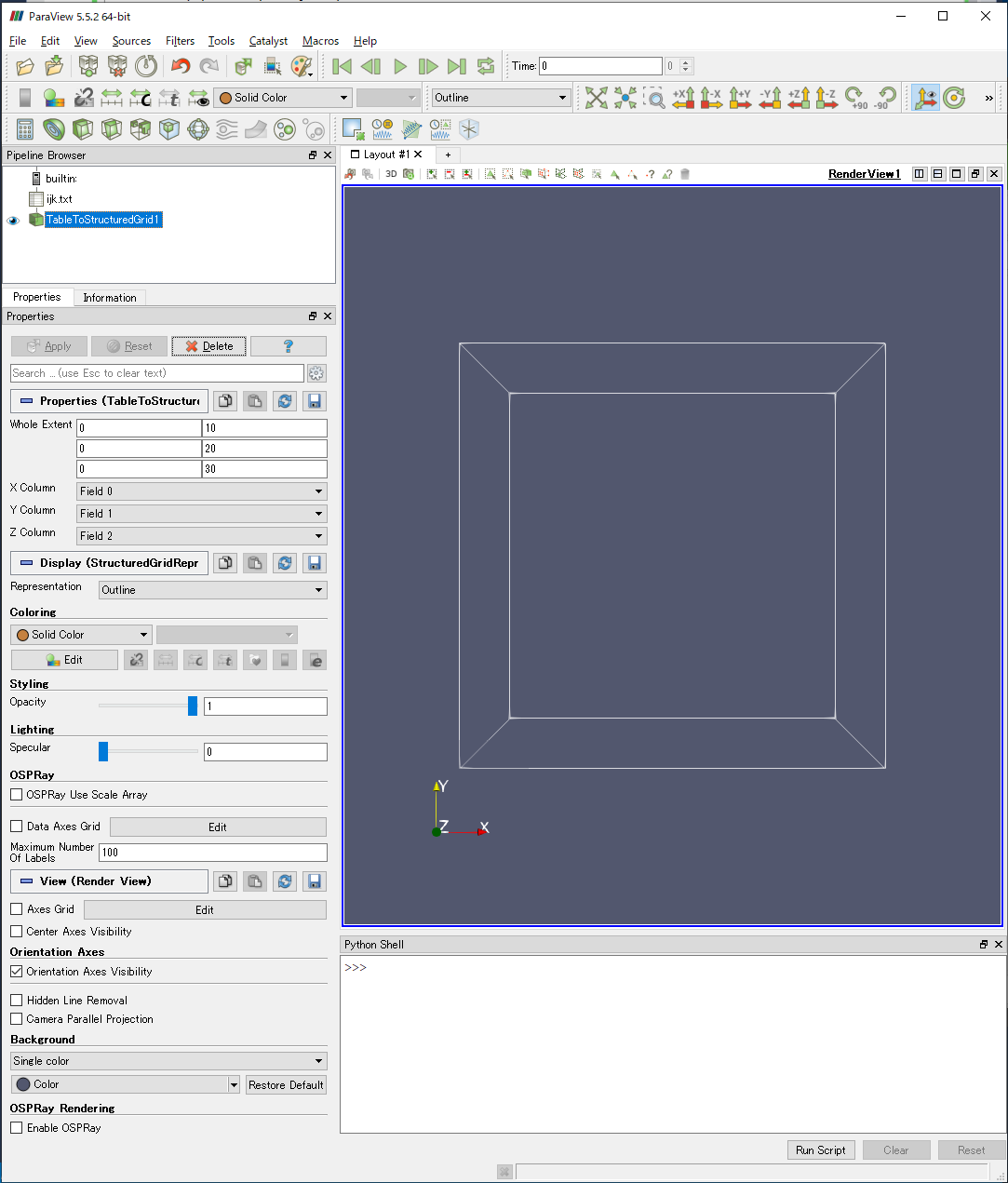
i-j-kループはkが3重ループの一番内側にあるため,出力されたファイルでは,座標はk,j,iすなわちz, y, x座標値の順に変化するので,ColumnとFieldを一致させる場合,Whole Extentの値は以下のようにします.
| 0 | 10 |
| 0 | 20 |
| 0 | 30 |
RenderViewに立方体が表示され,正しく読み込まれていることが分かります.
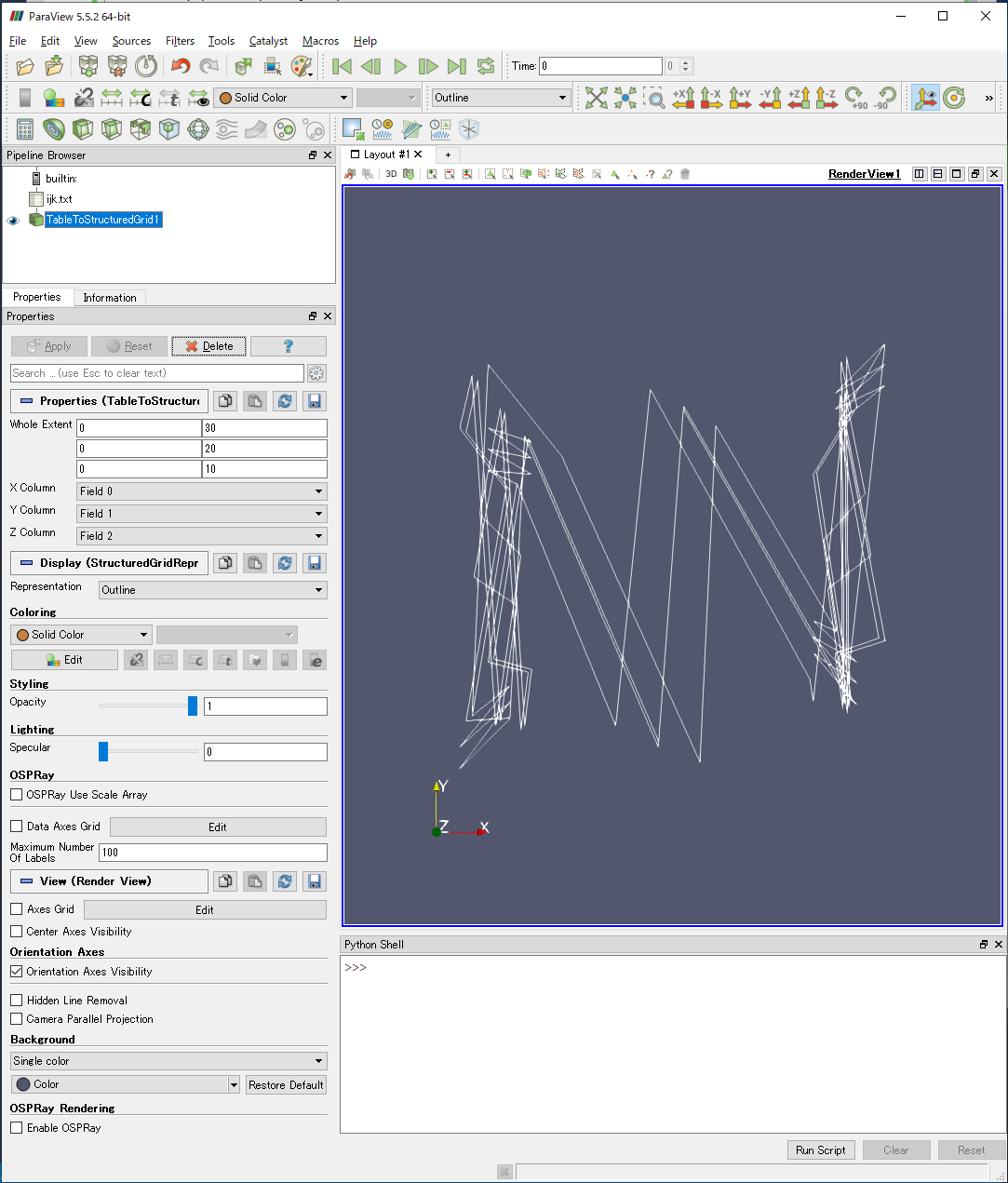
i-j-kループで出力したときに,k-j-iループで出力した時の値をWhole Extentに入力すると,RenderViewにぐちゃぐちゃの折れ線が表示され,正しく読み込まれていないことがわかります.
-
https://vtk.org/wp-content/uploads/2015/04/file-formats.pdf ↩
-
所詮はCSV形式なので,Excel等の表計算ソフトに放り込んで1列追加すればよいのですが,ファイルが複数あると手間がかかります. ↩