Go で高速なコードを書くために使えるslice のベストプラクティスを、slice の仕組みを解説してから紹介します。
最適化の前提
本稿はコードの高速化を目的としています。そこで最適化にあたっての注意点を掲載します。
- 時期尚早な最適化は避けよう
- 最適化は、適切に計測しながら実施しよう
- 本稿の slice 高速化テクニックは、高速化するかケースバイケースのものも含まれます。計測しましょう。
方針
コードの高速化には、並列化やキャッシュなど様々なアプローチがあります。
しかし本稿ではアプローチを以下の3つに絞って、slice まわりのコードを高速化に関して解説していきます。
- メモリアロケートのサイズを減らす
- メモリアロケートする回数を減らす
- 不要なメモリコピーを減らす
slice の仕組み
The Go Blog の Go Slices: usage and internalsが詳しいです。
この章では、上記資料を端折って、sliceとarrayの関係、そして slice の lengthとcapacityについて解説します。これは次の章で解説するベストプラクティスの前提知識となります。すでにご存知のかたはこの章を読み飛ばして問題ありません。
sliceとarrayについて
さて、まずsliceとarrayの関係から解説します。arrayは固定長であることが特徴です。
var a [4]int
一方sliceは大きさを後から変更することができます。そしてsliceは内部にベースとなるarrayへのポインタを持っています。
このarrayのことを 基底配列と呼びます。
またsliceは、この基底配列のほかに、基底配列の容量 (capacity) と、実際にsliceの要素が何個存在するか(length)を持ちます。
図示するとかの通りです。

(source: Go Slices: usage and internals )
例えば、 make([]byte, 5) によって lengthが5, capacityが5のsliceを作ると、内部的には以下のようになります。
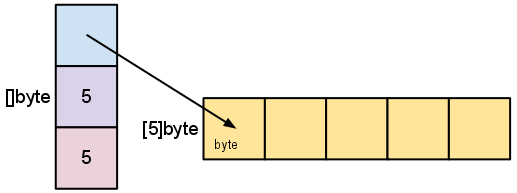
(source: Go Slices: usage and internals )
lengthとcapacityが紛らわしいのでここで一度整理しましょう。lengthは実際にユーザーが何個要素をsliceに詰めたかです。
capacityはより目に見えにくいものです。capacityとは、sliceが内部的に持っている基底配列の長さであり、つまり基底配列を変更しないかぎり、sliceのlengthの最大値はcapacityとなります。capacity(容量、最大収納量)という名前もこう考えるとわかりやすいのではないでしょうか。
sliceの拡張
slice は append によって要素を追加できます。
var s []int
s = append(s, 10)
このとき、基底配列の長さ、すなわちcapacityを超えてappendしようとしたらどうなるでしょうか。
arrayの長さは変更できないので、より長いarrayを新たにアロケートし、それを新しい基底配列として用いることになります。
さらに新しい基底配列となるarrayをアロケート後、古いarrayから新しい方へ内容をコピーすることになります。
裏でこのような振る舞いをしていることで、slice内部のcapacityを特に意識せずともappend関数を使うことができるのです。
さて、この新たな基底配列の長さはどの程度になるでしょうか。現在のruntimeの実装では、配列の大きさを倍としています。
倍々と大きくしていくことで、このsliceの拡張の処理が度々発生する事態を防いでいます。
以下にappend()の模式的コードを転載します。
func AppendByte(slice []byte, data ...byte) []byte {
m := len(slice)
n := m + len(data)
if n > cap(slice) { // if necessary, reallocate
// allocate double what's needed, for future growth.
newSlice := make([]byte, (n+1)*2)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:n]
copy(slice[m:n], data)
return slice
}
(source: Go Slices: usage and internals )
実際に runtime のgrowslice関数のコードをみると、上記が同等であると確認できます。
https://github.com/golang/go/blob/db16de920370892b0241d3fa0617dddff2417a4d/src/runtime/slice.go#L188
さて、appendの処理をまとめましょう。
- 現在の基底配列の2倍の長さのarrayをアロケートする
- 現在の基底配列の内容を、新しいarrayにコピーする
- sliceの基底配列を新しいarrayに切り替える
という処理になります。
以下のようにsliceをcapacityを指定せず作成すると、arrayの長さが1,2,4,8,16,32・・・となるsliceの成長が発生すること言えます。
var s []int
for i:=0; i<20; i++ {
s = append(s, 10)
}
複数回のallocateのコスト、そしてメモリコピーのコストが発生していますね。そして長さが20のarrayで十分なはずが、32の長さで確保されています。
slice ベストプラクティス
length や capacity を指定して slice を作成する
事前に slice がどれぐらいの length を必要とするか検討が付く場合、capacityを明示してsliceを作成しましょう。
s1 := make([]int, length) // capacity = length
s2 := make([]int, length, capacity)
事前に基底配列が十分な長さを持っていることで、sliceにappend()で要素追加しても、基底配列の拡張が発生しなくなります。その結果メモリアロケートやメモリコピーが発生せず、高速化につながるでしょう。
事前に指定するcapacityは必ずしも正確でなくてもよいです。例えば、もし仮にsliceの長さとして必要になる範囲が100~300だったとしましょう。この場合、もしsliceのcapacityに100を指定して作成していた場合、100より多く要素をappendすると、基底配列の拡張が発生します。ただし、capacityを0で作成していた場合よりも、トータルで発生する基底配列の拡張の回数は減り、パフォーマンスに優れるでしょう。
またこの場合、もし多めにcapacityに300を指定して作成していた場合、要素数が少ないと、すでにアロケートした領域の一部が無駄になります。ただ基底配列の拡張は発生しないのです。実行環境のメモリに余裕があり、かつメモリアロケートやコピーのコストを避けたい場合は、多めにcapacityを生成しておくほうがパフォーマンスに優れるでしょう。
後述の sync.Pool を用いてsliceを使い回す場合、sliceの長さに振れ幅があるとしたら、どうでどこかで上に触れるときが発生するので、考えられる上限の値をcapacityに指定して作成するのが良いです。
[]*T ではなく []Tを使う
あるサイズの大きいstruct BigStruct のsliceを作成することを考えます。
この場合、[]*BigStruct と[]BigStructのどちらを利用するかで、パフォーマンスに差が現れるでしょうか?
s1 := make([]*BigStruct, 0, 1e5)
ここでs1はBigStructのpointerが多数アロケートされているに過ぎず、BigStruct自体はまだ一つもアロケートされていないことに注意しましょう。もしここでs1に要素を以下のようにappendする場合、for文中で毎回BigStructがallocateされます。
s1 := make([]*BigStruct, 0, 1e5)
for i:=0; i<1e5; i++ {
s1 = append(s1, &BigStruct{})
}
メモリアロケートされるサイズが同じであったとしても、メモリアロケートの回数が多いとパフォーマンスが悪化します。
メモリアロケートが一度で済むよう、[]BigStruct型を用いましょう。
s2 := make([]BigStruct, 1e5)
for i:=0; i<1e5; i++ {
InitBigStruct(&s2[i], i) // すでにallocate済みの s2[i] を初期化する
}
このように[]BigStructを利用すれば、上記for文中でメモリアロケートはなくなります。
for 文では index を用いて要素にアクセスする
あるサイズの大きいstructのslice []BigStruct の各要素に、for文でアクセスすることを考えます。
s := make([]BigStruct, 3)
for i, b:= range s {
doSomething(i, b)
}
ここでfor文中で毎回、s[i]から、 iteration variables であるbへメモリコピがー発生していることに注意しましょう。
もしこのメモリコピーを防ぎたいのであれば、以下のようにします。
s := make([]BigStruct, 3)
for i := range s {
doSomething(i, s[i]) // i は int. BigStructではない
}
このように、for文で1番目のindex iteration variablesを利用して sliceのindexを指定してアクセスすることで、最初の例であったiteration variablesへのメモリコピーが発生しなくなりました。
ただこの2つには差があります。最初の例では、for文中で、 bを書き換えても、slice sの要素は書き換わりませんでした。最後の例では、for文中でs[i]を書き換えたら、当然for文から抜けたあともその結果が影響します。その点ご留意ください。
length を延長し allocate 済みの領域を使う
slice[]BigStructに、要素をappendしていくことを考えます。
s := make([]BigStruct, l, c)
for i:=0; i<E; i++ {
s = append(s, BigStruct{BigData(i)}) // 毎回 BigStruct{} を新規にアロケートしている
}
この例だと、for文のループ中に毎回 BigStruct{} を新規にアロケートしていていますね。これを回避する策があります。
slicesでは、s[0], s[1], ... , s[len(s)-1] の領域は要素が入っていて利用されています。
ただs[len(s):cap(s)] の領域は、メモリアロケートはされているものの、要素は利用されていません。このメモリアロケート済みだが利用されていない BigStructを利用しましょう。

この領域を利用するには、slice のlengthの延長をしてから、延長した領域に書き込みます。
s := make([]BigStruct, l, c)
for i:=0; i<E; i++ {
if len(s)+1 < cap(s) { // 書き込みたい場所がcapacityの範囲内
s=s[:len(s)+1] // sliceのlengthを一つ延長
s[len(s)].Data = BigData(i) //延長された領域に書き込み
}
}
ここでsliceの延長 s=s[:len(s)+1]について、これが何をしているか解説します。
そのためには、普段何気なく使っている Slice expressions a[low:high]の詳細な挙動を理解する必要があります。
a[low:high]について、a がsliceの場合1、以下の挙動をします。
- 新しいsliceを作る。
-
low:highは、aの要素のうち、どこが新しいsliceに含まれるかのインデックスとなる。 -
low、highが取れる範囲は、0≦low≦high≦cap(a)
ここで3.に注目してみてください。範囲として取れるindexの上限はlen(a)ではなく、cap(a)なのです。
Index expressions a[i] においては、 i の上限がlen(a)-1と、lengthが参照されるのとは異なり、capacityが参照されるのです。
a[low:high]において、highに len(s)≦high≦cap(a)となる値を指定することで、sliceaのlengthを延長することができます。
なお、slice expressionsについて、
- 新しいsliceと
aは基底配列を共有2する。 つまりメモリアロケートは発生しない。
という特徴もあるため、sliceのlengthの延長のコストはメモリアロケートの発生しない、安いものだと言えます。
さて、話を「sliceのlengthを延長し、そこに書き込む例」に戻します(以下に再掲)。この例だと、最初に渡された s のcapacity以上には要素を追加できていないです。
s := make([]BigStruct, l, c)
for i:=0; i<E; i++ {
if len(s)+1 < cap(s) {
s=s[:len(s)+1] // slice の延長
s[len(s)].Data = BigData(i) //延長された領域に書き込み
}
}
capacity を超えて要素を追加したい場合は、appendによって基底配列を拡張してもらうよう修正しましょう。appendは基底配列のlengthを倍にしてくれるので、また追加できるようになります。またもし事前に追加したい要素の数がわかっていれば、 slice s を初回に作るときにcapacityを設定できるので、そもそも基底配列の拡張の発生を防ぐことができます。
s := make([]BigStruct, l, c)
for i:=0; i<E; i++ {
if len(s)+1 < cap(s) {
s=s[:len(s)+1] // slice の延長
s[len(s)].Data = BigData(i) //延長された領域に書き込み
} else if cap(s) < len(s)+1 {
s = append(s, BigStruct{BigData(i)}) // capacityを超えてしまったので、appendによって拡張
}
}
以上、sliceのlength を延長することで、allocate 済みの領域を使う方法をご紹介しました。これを用いることで、繰り返しappendが発生する場合に、メモリアロケートの回数をへらすことができます。
sync.Pool で使い回す
例えば Web サーバーでのレスポンスの生成といったようなタスクだと、同じ型のsliceを何度もリクエストのたびに作り、レスポンスを返し終わると不要となるケースがあります。
このような場合は、一度作ったsliceを使い終わったあと、別の処理で使い回すとメモリアロケートの回数と量を低減することができます。
この用途に便利なのが sync.Pool です。
使い方の詳細は以下の記事が参考になります。
まとめ
高速化の原則を紹介し、それを実現する slice のベストプラクティスを slice の仕組みを解説しながら紹介しました。
ただし時期尚早な最適化は避けましょう。そして最適化はするときは、適切に計測しながら実施しましょう。
本稿のテクニックも、採用するべきかケースバイケースのものもあります。
-
aがarrayまたはstringの場合にもslice expressionsを用いることができるが、インデックスの範囲や作成されるものが異なります。詳細はこちらを参照してください。https://golang.org/ref/spec#Slice_expressions ↩ -
もし
aがnilだった場合は、新しいsliceもnilとなります。詳細はこちらを参照してください。https://golang.org/ref/spec#Slice_expressions ↩