Google Cloud Platform Advent Calendar 2017 11日目を担当する avvmoto です。よろしくお願いします。
この記事では、MySQL 等から Datastore にマイグレーションするときに必要となる、 Key 設計についての考慮点を解説します。
はじめに
GAE 等 GCP の強力な機能を用いるため、 MySQL 等 RDBMS から Datastore へマイグレーションしたくなる時があると思います。
Datastore には強力な機能が備わっていますが、独特の特徴があるので、それらを考慮して Key 設計する必要があります。
今回は、以下を実現することにします。
- マイグレート元のIDを引き継ぐ
- 新規 Entity の ID の発行には、Datastore 付属の automatically assigned ID を用いる
- つまり、アプリ開発者が ID の衝突を防ぐ仕組みを実装せずに済み、楽をします
- パフォーマンス悪化となる、ホットスポット問題を発生させない
これを実現するときの考慮点と、実現例をご紹介します。
Key 設計指針
Key の型・値
Key に用いられる型は二種類あります。 1
- int
- Cloud Datastore が自動でアサインするか、 Allocate した上でその範囲内の値を用いる
- string
- 利用者が任意のキーを指定する
今回はマイグレート元の ID を引き継ぐことを考えているため、 string の Key を用いることにします。
単純に int の ID を string に変換すると、つまり例えば元の ID が 1 だった場合に Key として string の "1" を用いる場合、いわゆるホットスポット 2 の問題が発生し、パフォーマンスに問題が出ます。
そのため、連番の int のID に対し、適度に分散されたstringが得られるような、何らかの1:1となり、しかも可逆な変換をした上で、それを Key として用いると良いでしょう。
この変換のアルゴリズムには、例えば Blowfish 3 4 などが利用できます。
既存のレコードをマイグレーションするときの Key このように設定できます。Datastore 移行後に新規に作成する Entity の Key については、次の章で説明します。
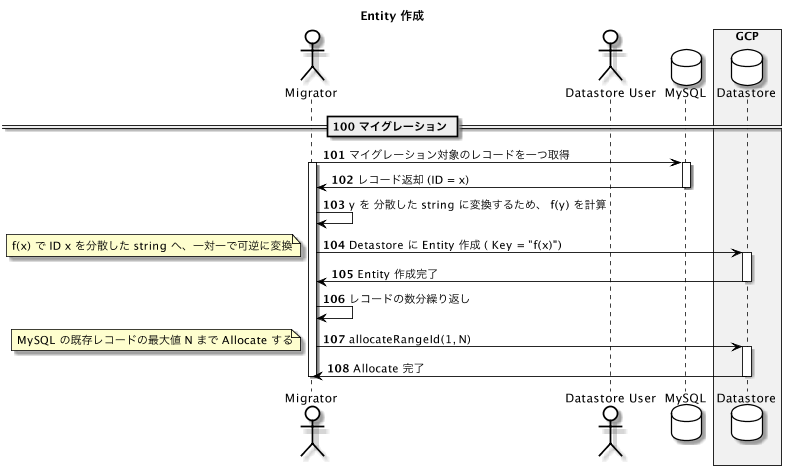
ID の Allocate
新規 Entity の作成
Key に string を用いた場合、既存の衝突しないことは自分で担保しないとなりません。1
int の Key を一つ AllocateID で Allocate し、それを Blowfish 等で変換した string を用いることで、既存レコードの ID と衝突しない string を得ることができます。
ただし、事前に以下のように、既存レコードの ID を Allocate しておく必要があります。
なお、今回の例だとEntity の Key には string を用いていますが、int の Key を Allocate することに特に問題はないようです。
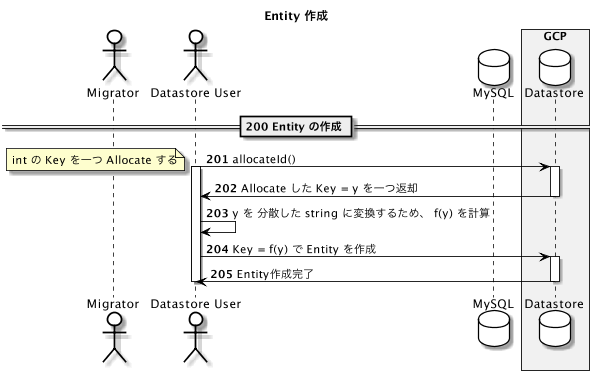
既存レコード ID の Allocate
既存レコードの ID が連番で採番されていて、最大値は N であるとします。この場合、 Datastore の自動アサインで、 1 ~ N の範囲が用いられないように、事前にその範囲を Allocate しておく必要があります。
この Allocate は、必ず新規 Entity を作成する前に行いましょう。
この Allocate には allocateIdRange 5 を用いましょう。
なお上記ドキュメントには、 [DatastoreService.KeyRangeState] (https://cloud.google.com/appengine/docs/standard/java/javadoc/com/google/appengine/api/datastore/DatastoreService.KeyRangeState) に応じて、Allocate しても他の Entity を上書きする場合があると書いてあります。
しかし新規の(つまりまだ Entity の作成されていない) Kind に対して、初回の allocateRangeId() で Allocate した領域に対しては、上書きされる事はありません。詳しくは補足:KeyRangeState をご覧ください。
Enity Group の場合
Enity Group の場合は注意が必要です。子となる Entity の Key は、親 Entity の Key を含めたものとなります。 そのため、親 Entity 毎に、子となる Kind で ID の Allocate が必要となります。
まとめ
MySQL 等から Datastore へマイグレーションするときの考慮点や、設計例をご紹介しました。
実際に Key を設計するときは、今回の考慮点以外にもビジネスロジックから Strong Consistency や ユニーク制約が必要になり、より多くの考慮点が発生すると思います。
そのため、ケースバイケースで Key 設計をすることになると思います。
あやまりや不正確な点がありましたら、ご教授のほどよろしくお願いします。
補足:KeyRangeState
allocateIdRange によると、
writing entities with manually assigned keys in this range may overwrite existing entities (or new entities written by a separate request) depending on the DatastoreService.KeyRangeState returned.
とあります。つまり allocateIdRange で取得した ID を手動で明示的に Key に指定して Entity を作成すると、 [DatastoreService.KeyRangeState] (https://cloud.google.com/appengine/docs/standard/java/javadoc/com/google/appengine/api/datastore/DatastoreService.KeyRangeState) によっては、既存の Entity を上書きする場合があります。
[DatastoreService.KeyRangeState] (https://cloud.google.com/appengine/docs/standard/java/javadoc/com/google/appengine/api/datastore/DatastoreService.KeyRangeState) を見てみましょう。
| KeyRangeState | 訳 |
|---|---|
| COLLISION | 衝突 |
| CONTENTION | 競合 |
| EMPTY | 空 |
COLLISION はわかりやすいです。
Indicates that entities with keys inside the given KeyRange already exist and writing to this range will overwrite those entities.
つまり、 Allocate した KeyRange の中に、既に Entity が存在している状態を指します。
Empty は、
Indicates the given KeyRange is empty and the datastore's automatic ID allocator will not assign keys in this range to new entities.
つまり、 Allocate した KeyRange の中に、Entity が存在しない状態です。
CONTENTION はややこしいです。
Indicates the given KeyRange is empty but the datastore's automatic ID allocator may assign new entities keys in this range.
つまり、Allocate した KeyRange の中に Entities は存在しないものの、自動 ID アロケーターがその範囲内に新しい Entity の Key を Allcoate する場合がある状態です。
この状態は、内部実装的に、 Key の Allocate 済みの範囲を、領域として保存していないことに由来します。6 7
つまり、その値以下は自動アロケーターが発番に用いないという最大値を持っているのです。仮にこの値を「Allocate済みの最大値」 と呼びましょう。
KeyRange を指定して allocateIdRange() で Allocate するということは、対象の Kind の「Allocate済みの最大値」 を KeyRange の最大値に設定することである、と言い換えることができます。
さて、 CONTENTION についてです。 Allocate しようとした KeyRange の中に、「Allocate済みの最大値」がある場合もありえます。
この状態が CONTENTION となります。
最終的な結論として、今回気にしていたEntity の無い空の Kind への allocateIdRange() についていえば、 任意の 1 ~ N の allocateIdRange() が成功し、自動 ID アロケーターは以後この範囲を発番に用いない、といえます。
参考資料
- https://ja.wikipedia.org/wiki/Blowfish
- https://cloud.google.com/datastore/docs/best-practices?hl=ja#keys
- https://cloud.google.com/datastore/docs/concepts/entities#assigning_identifiers
- https://cloud.google.com/appengine/docs/standard/java/javadoc/com/google/appengine/api/datastore/DatastoreService#allocateIdRange-com.google.appengine.api.datastore.KeyRange-
- https://cloud.google.com/appengine/docs/standard/java/javadoc/com/google/appengine/api/datastore/DatastoreService.KeyRangeState
脚注
-
https://cloud.google.com/datastore/docs/concepts/entities#assigning_identifiers ↩ ↩2
-
https://cloud.google.com/datastore/docs/best-practices?hl=ja#keys ↩
-
仮に golang を用いる場合、 Bigint は他言語に比べて遅いと言われますが、 Blowfish は Bigint を用いない点も適切です。 ↩
-
なお golang にはこれの相当物は、今のところありません。 https://github.com/golang/appengine/issues/97 ↩
-
この仕様を表現しているドキュメントは見つかりませんでしたが、私が Google Cloud Platform Support に問い合わせた結果、そうだということでした。なお公開されていない仕様なので、将来的に変更される可能性があります。しかし仮に将来仕様が変わったとしても、既に Allocate 済みの領域は、ずっと Allocate 済み扱いされることを期待していいと思います。 ↩
-
このあたりの仕様は、 Datastore のクライアントライブラリーが、裏側の Datastore API へ送っている リクエストパラメーター からも察することができます。 ↩