はじめに
この記事はDatabricks Advent Calendar 2024シリーズ1の19日目の記事です。
Databricks Appsとは
Databricks Appsは、Databricks上でデータアプリケーションを開発、実行、共有できる機能です。Databricks上で動作するため、追加のインフラストラクチャを構築することなく、データアプリケーションの開発や共有が可能です。
類似の機能としてSnowflakeのStreamlit in Snowflakeがありますが、Databricks AppsではStreamlitの他にもDash、Flask、Gradio、Shinyといったさまざまなフレームワークを利用してアプリケーションを開発できます。
パブリックプレビュー
2024年12月時点ではプレビュー版のため利用可能なリージョンが限られています。
Databricks Appsを利用可能なリージョンについては公式ドキュメントをご参照ください。
データアプリの作成
新規からアプリを選択します
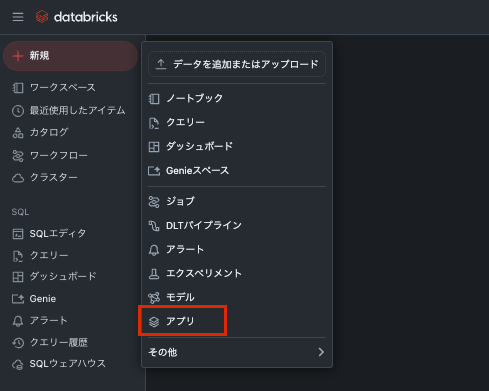
Databricks Appsではテンプレートを使ってのアプリ作成も可能です。
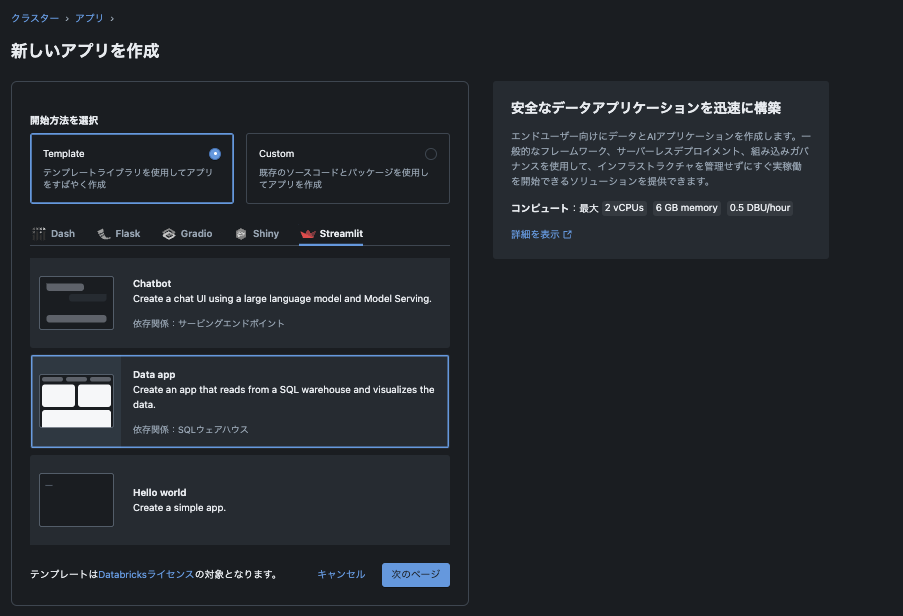
テンプレートを使用する場合は、使用するフレームワークと作成するアプリの種類を選択します。
今回はフレームワークにStreamlit、アプリはData appを選択します。
Data appではSQLウェアハウスが必要なため、アプリ名と使用するSQLウェアハウスを選択します。
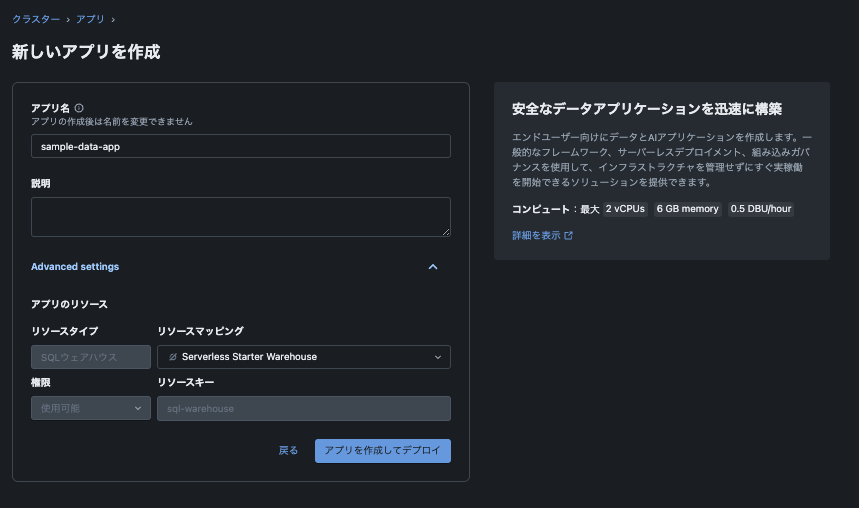
[アプリを作成してデプロイ]をクリックするとデプロイが始まります。
デプロイが完了すると画面の表示が実行中に切り替わります。
実行中のリンクをクリックするとアプリが別タブで起動します。
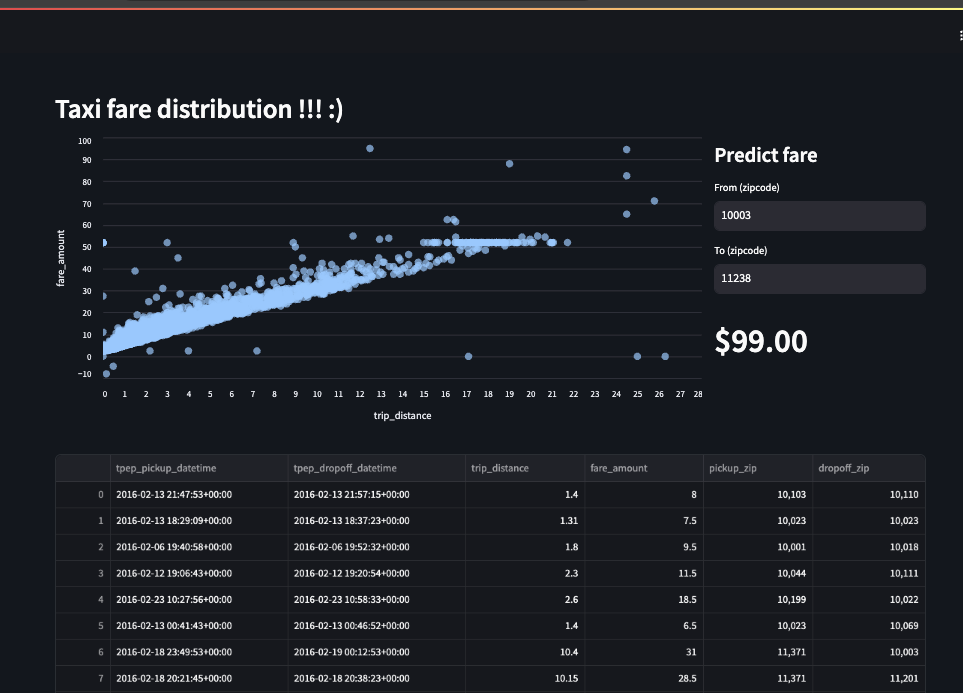
テンプレートとして提供されているのは、タクシーの乗り場と行き先の郵便番号を指定することで料金を予測するアプリケーションのようです。
Databricks上のテーブルの読み込み
次にコードを修正して、Databricks上に格納されたテーブルにアクセスします。
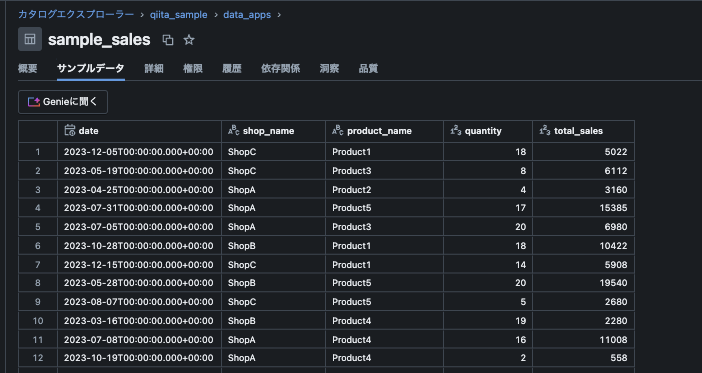
下記の店舗の売り上げに関するダミーデータを使用し、時系列での売り上げの推移を確認します。
デプロイメントのソースのリンクをクリックするとデプロイされているアプリのソースコードを確認することができます。
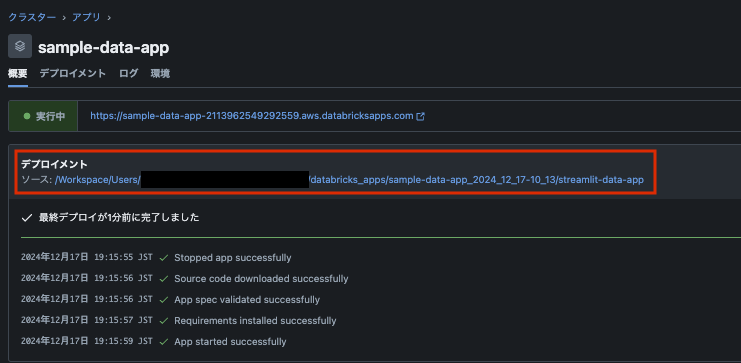
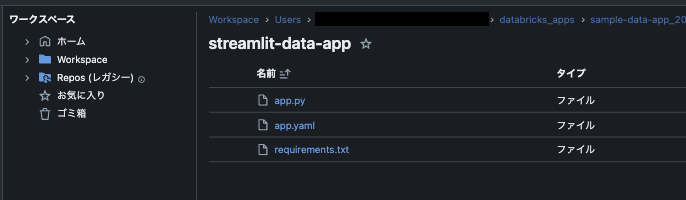
app.pyを確認するとgetData()関数でDatabricks上のテーブルからデータを取得しているようです。このクエリを先ほどの売り上げテーブルからデータを取得するクエリに変更します。
import os
from databricks import sql
from databricks.sdk.core import Config
import streamlit as st
import pandas as pd
# Ensure environment variable is set correctly
assert os.getenv('DATABRICKS_WAREHOUSE_ID'), "DATABRICKS_WAREHOUSE_ID must be set in app.yaml."
def sqlQuery(query: str) -> pd.DataFrame:
cfg = Config() # Pull environment variables for auth
with sql.connect(
server_hostname=cfg.host,
http_path=f"/sql/1.0/warehouses/{os.getenv('DATABRICKS_WAREHOUSE_ID')}",
credentials_provider=lambda: cfg.authenticate
) as connection:
with connection.cursor() as cursor:
cursor.execute(query)
return cursor.fetchall_arrow().to_pandas()
st.set_page_config(layout="wide")
@st.cache_data(ttl=30) # only re-query if it's been 30 seconds
def getData():
# This example query depends on the nyctaxi data set in Unity Catalog, see https://docs.databricks.com/en/discover/databricks-datasets.html for details
- return sqlQuery("select * from samples.nyctaxi.trips limit 5000")
+ return sqlQuery("select * from select * from qiita_sample.data_apps.sample_sales")
data = getData()
st.header("Taxi fare distribution !!! :)")
col1, col2 = st.columns([3, 1])
with col1:
st.scatter_chart(data=data, height=400, width=700, y="fare_amount", x="trip_distance")
with col2:
st.subheader("Predict fare")
pickup = st.text_input("From (zipcode)", value="10003")
dropoff = st.text_input("To (zipcode)", value="11238")
d = data[(data['pickup_zip'] == int(pickup)) & (data['dropoff_zip'] == int(dropoff))]
st.write(f"# **${d['fare_amount'].mean() if len(d) > 0 else 99:.2f}**")
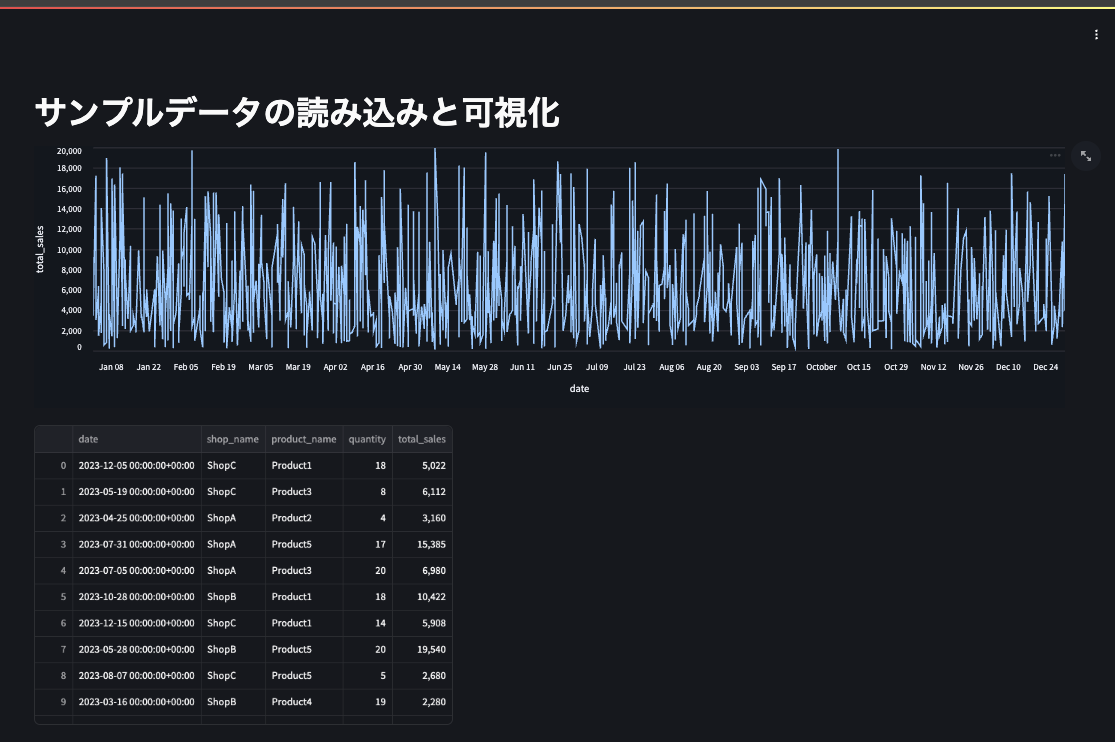
さらにst.header()以降の記述も以下の売り上げテーブルの可視化を行うコードに修正します。
st.title('サンプルデータの読み込みと可視化')
st.line_chart(
data=data,
x='date',
y='total_sales'
)
st.dataframe(data)
コードの修正が完了したら、先ほどのアプリの画面に戻り、右上の[デプロイ]をクリックします。
デプロイ完了後、アプリを開き直すと更新されていることが確認できます。
ローカル環境での開発とデプロイ
Databricks AppsではDatabricks上で作成したアプリをローカルで編集し、デプロイすることも可能です。
Databricks CLI
ローカルで開発、デプロイを行うためにはPython環境およびDatabricks CLIのインストールが必要です。
https://docs.databricks.com/ja/dev-tools/cli/install.html
以下のコマンドでローカル環境にアプリのソースコードをコピーします。
$ databricks workspace export-dir <your_data_app_srouce_path> .
ローカル環境にファイルがコピーされました。

以下のコマンドを実行すると、ローカルでの編集内容がリアルタイムにDatabricksへ同期されます。
$ databricks sync --watch . <your_data_app_srouce_path>
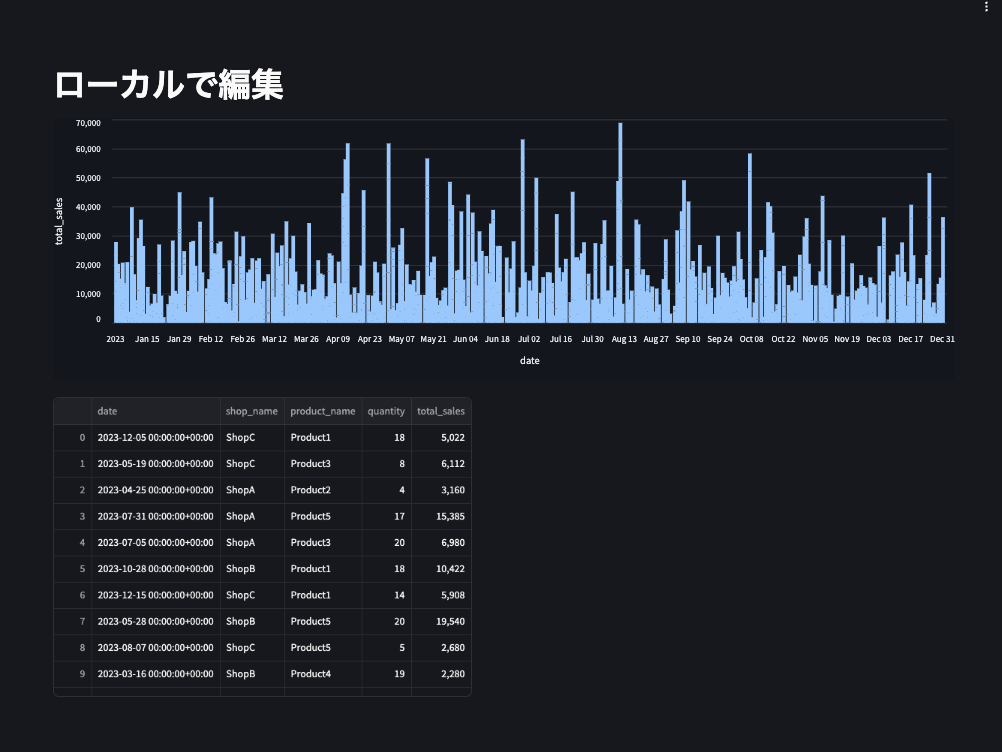
データアプリのタイトルとグラフの種類を折れ線グラフから棒グラフに変更します。
-st.title('サンプルデータの読み込みと可視化')
-st.line_char(
+st.title('ローカルで編集')
+st.bar_chart(
data=data,
x='date',
y='total_sales'
)
st.dataframe(data)
修正が完了したら以下のコマンドでDatabricksアプリへのデプロイを行います。
$ databricks apps deploy <app_name> --source-code-path <your_data_app_srouce_path>
Databricksでアプリを確認するとローカルでの変更が反映されていることが確認できました。
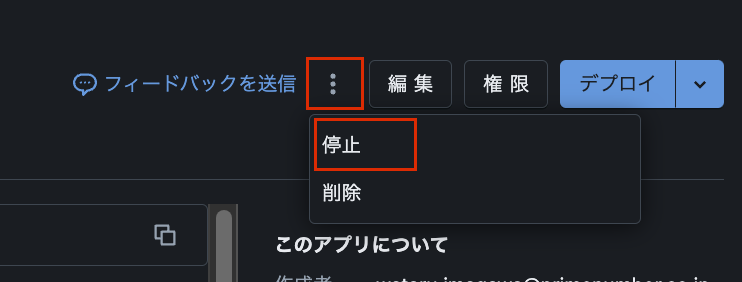
アプリの停止
最後に、アプリは起動したままだと課金されるため、不要なアプリは停止 or 削除しておきましょう。画面右上の3点リーダーから操作可能です。