今年は各地で災害が多く発生しました。私の地元でも大きな被害が発生していますが、昔から言われるように「災害は忘れたころにやって来る」ではなくて、最近では「いつでも災害は起きる」という心構えでいなければならないなと思っています。そして、最近の日本では鉄道でさえ通常時以外の備えが出来ていない、つまり「ここまでしっかり対策されているからそんなイレギュラーなことは起きない」前提で仕組みが作られてしまっています。しかし、現実的にはそうではなくてイレギュラーなことが発生すると「想定外でした!」。でも、実はちょっとした準備していれば回避できたことも多いはずです。例えば他社線との接続点に折り返し線を用意する、途中駅に上り下りの渡り線を用意したり引き上げ線を用意する、ダイヤは柔軟に変更可能にするなどすることで、乗り入れしている他社線の遠くの駅で起きたトラブルで自社線のダイヤが大きく乱れるなども防げたはずです。(この辺りはしっかり考えて作られている京成電鉄-都営浅草線-京浜急行は回復早いですよね)
コンピューターのディザスタ対策は
コンピューターの世界でこのようなイレギュラーケースに対してはどのようにしているでしょうか。オンプレミスの時代は簡単なデーターの定期的なバックアップ、サーバーのイメージバックアップ、別なところへのレプリケーション、復旧のために長い時間止めないために HA、全く止めないための FT、そしてその次はバックアップセンターなどいろいろありました。
1.データーを確保(保護)という視点・・・・バックアップ
以下は物理サーバー全盛の時代に行われていたサーバー側での様々な業務データーを保護する方法です。イレギュラー処理でデーターを破損してしまった場合やハードウエア障害でサーバーそのものの復旧が必要な場合などに使われる方法です。
- データーのバックアップ、はファイルを別の場所にコピーしたりデーターベースのデーターをエクスポートしたり、処理トランザクションを変更履歴として記録したりと様々は方法があります。
- サーバーのイメージバックアップは、物理サーバーのディスク自体をそのままダンプしてファイルとして保存するものです。
- レプリケーションは、ファイルやデーターベースなどを別のストレージ装置(またはサーバー)に定期的に同期して保管するもので、完全同期(Sync)と非同期(Async)があります。

2.業務を継続という視点・・・・高可用性
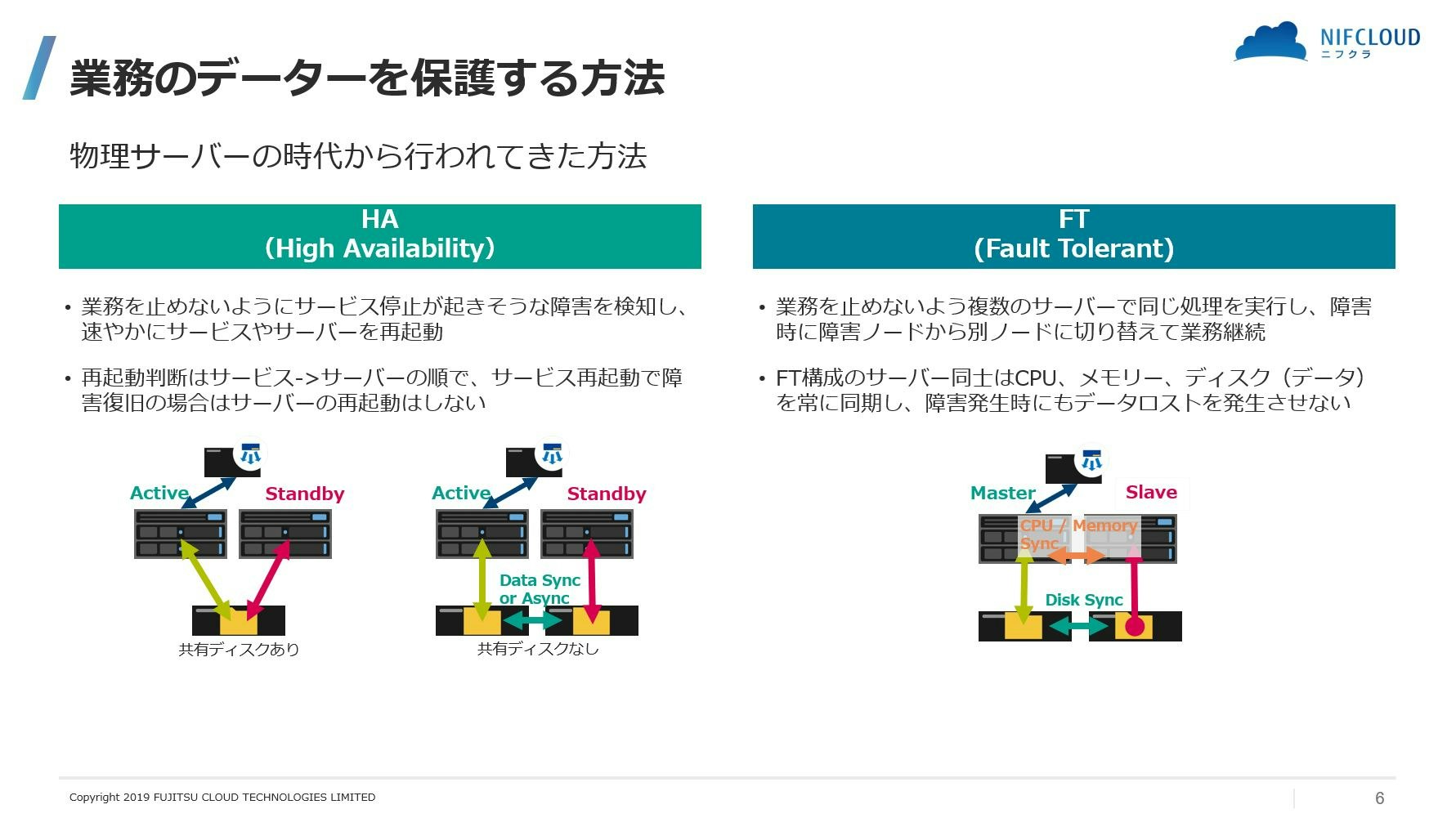
障害が発生すると実際には業務の停止を伴います。しかしバックアップから戻しているのでは業務停止時間が長くなってしまいます。そのため業務停止を出来る限り短くする仕組みが必要になってきます。これが高可用性(High availability:HA)です。
HA の場合はサービスまたはサーバーの再起動があるのでダウンタイムが発生します。
そのため、障害発生時にも業務のダウンタイムを発生させないように一つの処理に対して複数のサーバーを同時並行的に動かすことで、サーバーに障害が発生した時でも正常なサーバーに切り替えることでダウンタイム無しに業務を継続できる仕組みもあり、こちらは FT (Fault-Tolerant)と呼ばれます。この2つを理解していなくて混同している人を時々見かけますが、下記表のような違いを押さえておくとよいでしょう。
| 項目 | HA | FT |
|---|---|---|
| ダウンタイム | あり | なし |
| データ欠落 | キャッシュデーターや書き込み中のデータは欠落の恐れあり | 欠落なし |
| CPU 内容同期 | なし | あり |
| メモリー内容同期 | なし | あり |
| ディスク構成 | 共有ディスクまたはレプリケーション | サーバーごと同時書き込み |
| データ同期方法 | 共有ディスクは 排他制御だけなので同期なし。レプリケーション構成は Sync または Async による同期 | マスターに書き込み時に同時にスレーブにも書き込み |
構成イメージは以下の通りで、FT は物理サーバーの時代はサーバーのメモリーや CPU の情報も同期していました。
3.拠点がダウンしても業務の継続(BCP)という視点・・・・ディザスタリカバリー構成
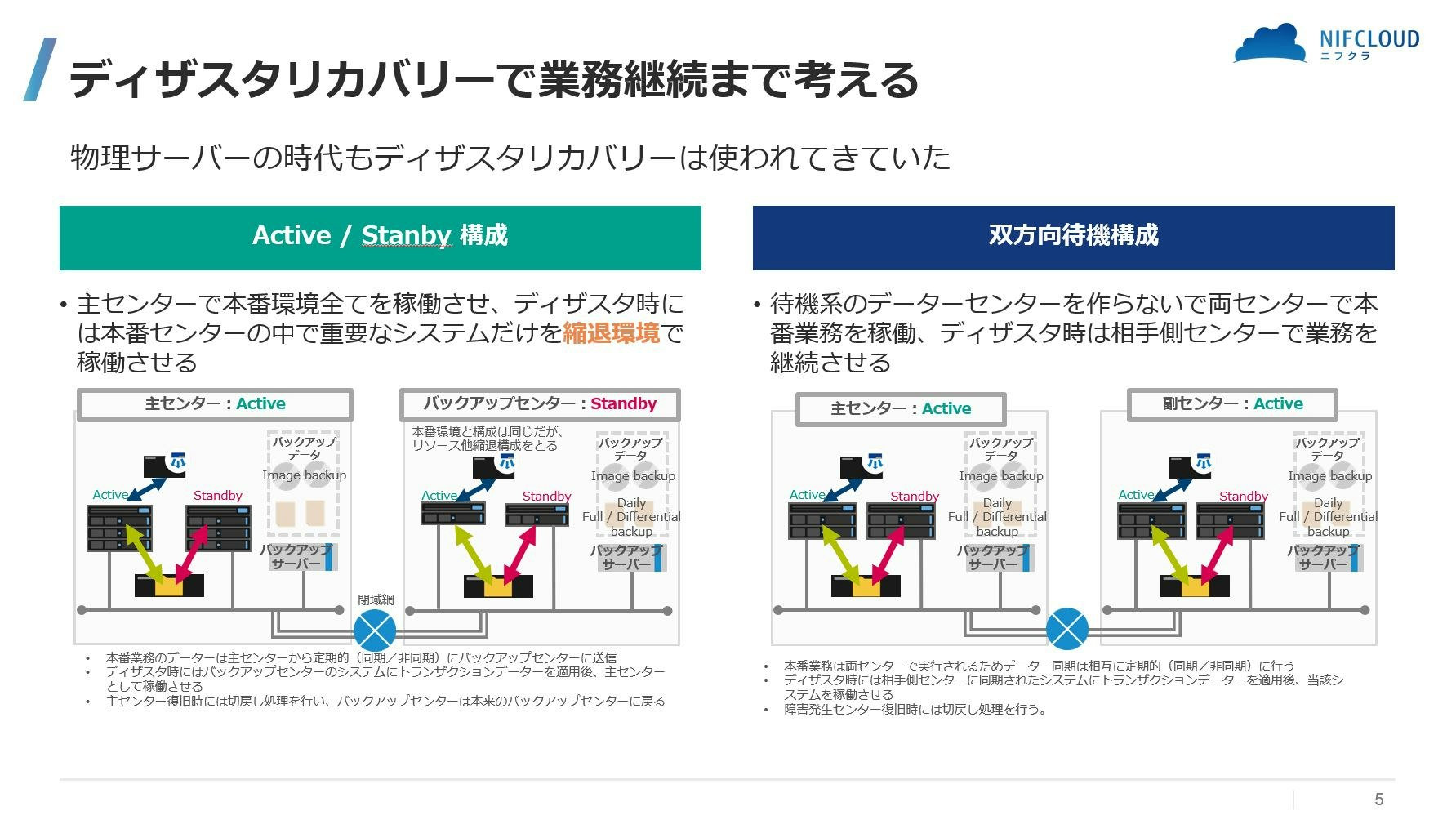
ここまでは単一拠点内の話でしたが、例えば昨今の自然災害などでサーバーのある拠点が使えなくなることが考えられます。そうなると業務は完全に停止してしまい事業への損害も大きくなってしまいます。そのため、可能な限り早期に業務再開できるようにする必要があり、事業継続計画(BCP)として最近では考えられるようになってきました。この場合、単一拠点だけで対策を考えることは出来ず複数拠点で同じような環境を作ることになります。この構成も大きく分けて2つあります。
-
Active / Standby 構成
複数のデーターセンターで業務を稼働させる主センターと主センターが使えなくなった時に稼働させるバックアップセンターとを明確に分けて運用する構成です。この構成ではバックアップセンターは主センターと同じ構成の環境を持ちつつ常に待機状態にしておくため、バックアップセンターのサーバーやストレージは主センターのものより低い性能を用意することも多くあります。その場合は、実際切り替えが発生した時は主センターの中で重要な業務システムを優先してバックアップセンターで稼働させ、それ以外は優先度をつけて稼働させるかバックアップはあるが稼働をさせないなどして、事業継続に必要なシステム(サービス)だけを動かすなどの運用をします。 -
Active / Active 構成
バックアップセンターを持つということは、それだけ常に稼働していない資産に対してもお金を払い続けることになり無駄が出ます。そのため、複数のデーターセンターを利用する場合それぞれのデーターセンターに業務システムを分散していずれかのデーターセンターが主センターでいずれかのデーターセンターがバックアップになるという構成で、通常業務の時はデーターセンターのリソースを有効活用するという構成です。
この場合、いずれかのデーターセンターがダウンした場合、そのデーターセンターで動いている業務はそのデーターセンターのバックアップセンターで稼働させることになりますが、この時重要な業務を稼働させる場合リソースが不足することが懸念されるときは、バックアップセンターの優先度の低い業務システムのサービスを停止して優先度の高い業務システムを稼働させるなどの設計が必要で、物理サーバーの時代はそのような設計と実装もとても重要でした。
これらデーターセンター規模でのディザスタリカバリーでは、データーの整合性の確認も重要になってきます。そのため実際にはデーターの書き込み履歴(トランザクションデーター:変更履歴データー)も同時に保管し相手先に同期するのが通常です。そうすることで、業務停止が発生した時点までのデーターが保護されるとともに変更履歴をその復旧したデーターの環境に適用することで、欠落データーを最小限にすることが可能になります。
仮想化したらどう変わる
昔物理から仮想に移るときによく言われていたこと。「仮想化プラットホームである vSphere では vSphere HA があるから大丈夫です!!」と言って、物理サーバーでは HA 構成にしていたのに仮想化したら HA 構成をやめてしまったという話をよく聞きました。今では流石にそういうことを言ってくる SIer は無いと思いますが、もしいたらこのページ(仮想化環境で HA クラスタを構成する際の考慮点)を参考にどうして不要になるかを聞いてみてください。物理から仮想になったとしても、データー視点での保護という点は変わらないです。
運用は大事!設計時は想定していてもしっかり運用できていないとダメ
ここまでしっかりバックアップや冗長構成をとりディザスタリカバリー構成をしていても、いざことが起きた時にうまく復旧できないということをよく耳にします。これ、実は運用に問題があることは殆どです。つまり、最初に環境をデザインしてその時はしっかり切り替わることをテストして OK を出しているのですが、システムは運用が始まるといろいろと変更点が出てきます。例えば設計時に想定していないくらいにデータ量が増えたとか、ネットワークのトラフィックが多いとか、ストレージの IOPS が足りていないとか、インフラ設計の根幹にかかわるようなことも出てくることがあります。そしてそのように環境負荷は変わっているのにインフラ運用自体は前のままだと、データー量が多くてバックアップに失敗する、ネットワークトラフィックが多いのでレプリケーションに失敗する、ストレージの IOPS が足りなくて処理に遅延が発生するなど問題が出てきたりするのですが、運用を自動化していてこれらの事象が起きた場合に、ログに書き出されているけれど業務的には稼働しているのと「いざ」というときのバックアップや冗長構成をとりディザスタリカバリー構成だから、業務に影響なければ今すぐ対処しなくても良いよねとあと送りしてしまったりすることもあるかもしれません。特に自分たちで環境の世話をしているのではなくどこか協力会社に丸投げとかデーターセンターのオペレーターに丸投げで、バックアップや冗長構成をとりディザスタリカバリー構成の所のアラートが上がっても通常業務じゃなければ自分たちの所には週でしかレポートが上がらない、そしてそれに対して指示しないと何もやらないとかになっていると最悪です。そのように「いざ」というときにリカバリーできない状態にならないよう、システムを変更したらリカバリのテストをかならず行う。そして運用も変化をしたら常に運用も見直して必要なら変える、運用時に問題が出たら「とりあえず運用で逃げよう」ではなくて、問題が出ないように運用を見直すなど、「変わったことに対して常に対応し、いざというときに備える」ということ、しっかり対応してクリアすることが大切です。
災害は忘れたころにやって来る・・・・・・・・そしてちゃんと対策を考えていないと被害は大きくなる。気を付けましょう。
文責:imaisato