TL;DR
PyTorchを使った転移学習を行ってみます。使用するデータセットはPyTorchのチュートリアルで使われている蟻と蜂のデータセットを使います。ここからダウンロードできます。直接ダウンロード始めるので気をつけてください。
それぞれ120枚ずつ画像が存在し、validationに75枚の画像を使用します。ImageNetなどでpre-trainされたResNet18を使用することでこの少ないデータセットでも比較的高い精度を出すことができます。
Google Colaboratory内でデータセットの準備
GPUを使って学習を進めたいので、Google Colabを使用します。
まず、Google Driveの/content/drive/My Drive内にdataディレクトリを作成します。
この中に先にダウンロードしておいたデータセットをアップロードし、My Driveでマウントをします。また、必要なライブラリをimportします。\
そういえば、plt.ion()でインタラクティブに表示させられるようになるんですね。初めて知りました。
from google.colab import drive
drive.mount('/content/drive/')
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
plt.ion()
os.chdir('/count/drive/My Drive/')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# cuda:0
カレントディレクトリの確認とディレクトリ構成の確認します。
!pwd
# /content/drive/My Drive
!tree ./data -d
./data
└── hymenoptera_data
├── train
│ ├── ants
│ └── bees
└── val
├── ants
└── bees
datasetの作成
trainとvalidationのdata_transformsをtorchvision.transforms.Composeクラスを使って作成します。
trainではdata augumentationをランダムリサイズクロップとランダムフリップを行うことにします。
また、pretrainedのモデルを使用するためにmean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]に正規化します。
次にtorchvison.datasets.ImageFolderクラスを使ってtransformされたデータセットimage_datasetsを作成します。image_datasetsとtorch.utils.data.DataLoaderクラスを使ってロードされるごとにbatch sizeが4でデータのシャッフルが行われるdataloadersを作成します。また、それぞれのデータセットのサイズとラベルを作成しておきます。
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
image_datasetsの中身を確認してみます。内部にはデータセットのサイズや場所、行われるtransformの処理などが書かれています。
また、辞書と同様にkeyを指定することができ、valueに対してclassesを使うことで内部のラベルを表示することができます。
print('-'*10, 'image_datasets','-'*10,'\n', image_datasets)
print()
print('-'*10,'train dataset','-'*10,'\n', image_datasets['train'])
print()
print('-'*10,'label','-'*10,'\n', image_datasets['train'].classes)
# 出力
---------- image_datasets ----------
{'train': Dataset ImageFolder
Number of datapoints: 244
Root Location: data/hymenoptera_data/train
Transforms (if any): Compose(
RandomResizedCrop(size=(224, 224), scale=(0.08, 1.0), ratio=(0.75, 1.3333), interpolation=PIL.Image.BILINEAR)
RandomHorizontalFlip(p=0.5)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
Target Transforms (if any): None, 'val': Dataset ImageFolder
Number of datapoints: 153
Root Location: data/hymenoptera_data/val
Transforms (if any): Compose(
Resize(size=256, interpolation=PIL.Image.BILINEAR)
CenterCrop(size=(224, 224))
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
Target Transforms (if any): None}
---------- train dataset ----------
Dataset ImageFolder
Number of datapoints: 244
Root Location: data/hymenoptera_data/train
Transforms (if any): Compose(
RandomResizedCrop(size=(224, 224), scale=(0.08, 1.0), ratio=(0.75, 1.3333), interpolation=PIL.Image.BILINEAR)
RandomHorizontalFlip(p=0.5)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
Target Transforms (if any): None
---------- label ----------
['ants', 'bees']
訓練データの表示
Tensorをnumpy arrayに変換し、maplotlibを使って表示します。Tensorの形状をimshowで表示できるように変換して表示します。
表示の際には、4枚分の画像を連結するtorchvision.utils.make_gridを使用します。
next(iter(dataloaders['train']))でdataloadersから出力された4枚の画像のTensorとラベルを取得しています。
def imshow(inp, title=None):
"imshow for Tensor"
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
inputs, classes = next(iter(dataloaders['train']))
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
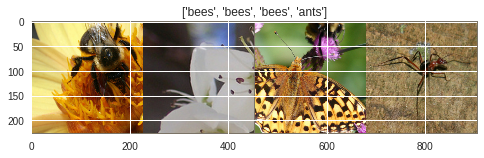
実際にData Augumentationが行われていることがわかります。実行するたびに毎回違う写真が表示されます。
モデル、損失関数、ハイパーパラメータの定義
モデルとしてpre-trainedなResNet18を使用し、出力次元を2次元にして二値分類を行います。損失関数として交差クロスエントロピー誤差、最適化法としてMomentumSGDを使用します。(転移学習を行う時はAdamより良いらしい)
また、torch.optim.lr_scheduler.StepLRを使用して7 stepごとにlrを1/10します。
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
少し、model_ftの内部を表示してみます。ResNet18の構造で、最後のfc層のout_featuresが1000から2になっていることがわかります。
今回とは関係ないですけど、DropoutじゃなくてAvePoolingが使われてるんですね。
for x in list(model_ft.children()):
print(x, '\n')
# 出力
Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
ReLU(inplace)
MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
AdaptiveAvgPool2d(output_size=(1, 1))
Linear(in_features=512, out_features=2, bias=True) #⇦ここ
訓練
epoch内部でそれぞれのrunごとにlossとaccuracyを算出してepoch全体での平均のlossとaccuracyを表示します。また、訓練内でもっともvalidationのaccuracyがよい重みを保存しておき、その重みを返します。trainのときはmodel.train(), validationやtestのときはmodel.eval()を使うと良いようです。
ChainerのTrainerとかKerasのfitみたいな感じで抽象化されてないのが印象的でした。内部構造知らなかったけどこんなのだったのか。
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
#tensor(max, max_indices)なのでpredは0,1のラベル
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
# training
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
# 結果
Epoch 0/24
----------
train Loss: 0.7234 Acc: 0.6393
val Loss: 0.2526 Acc: 0.9085
Epoch 1/24
----------
train Loss: 0.4869 Acc: 0.8197
val Loss: 0.3383 Acc: 0.8889
Epoch 2/24
----------
train Loss: 0.3276 Acc: 0.8566
val Loss: 0.2369 Acc: 0.9085
Epoch 3/24
----------
train Loss: 0.5924 Acc: 0.7869
val Loss: 0.5277 Acc: 0.8758
Epoch 4/24
----------
train Loss: 0.5988 Acc: 0.7828
val Loss: 0.2489 Acc: 0.9281
Epoch 5/24
----------
train Loss: 0.6662 Acc: 0.7254
val Loss: 0.3093 Acc: 0.8627
Epoch 6/24
----------
train Loss: 0.3032 Acc: 0.8811
val Loss: 0.2465 Acc: 0.9150
Epoch 7/24
----------
train Loss: 0.3520 Acc: 0.8484
val Loss: 0.2225 Acc: 0.9412
Epoch 8/24
----------
train Loss: 0.3038 Acc: 0.8852
val Loss: 0.2239 Acc: 0.9346
Epoch 9/24
----------
train Loss: 0.2872 Acc: 0.8893
val Loss: 0.2418 Acc: 0.9216
Epoch 10/24
----------
train Loss: 0.3253 Acc: 0.8525
val Loss: 0.2461 Acc: 0.9085
Epoch 11/24
----------
train Loss: 0.3024 Acc: 0.8607
val Loss: 0.2695 Acc: 0.9150
Epoch 12/24
----------
train Loss: 0.2161 Acc: 0.9139
val Loss: 0.2258 Acc: 0.9412
Epoch 13/24
----------
train Loss: 0.3032 Acc: 0.8730
val Loss: 0.2255 Acc: 0.9412
Epoch 14/24
----------
train Loss: 0.2812 Acc: 0.8730
val Loss: 0.2493 Acc: 0.9216
Epoch 15/24
----------
train Loss: 0.3901 Acc: 0.8279
val Loss: 0.2229 Acc: 0.9281
Epoch 16/24
----------
train Loss: 0.2845 Acc: 0.8648
val Loss: 0.2298 Acc: 0.9281
Epoch 17/24
----------
train Loss: 0.3170 Acc: 0.8443
val Loss: 0.2546 Acc: 0.9150
Epoch 18/24
----------
train Loss: 0.1837 Acc: 0.9262
val Loss: 0.2278 Acc: 0.9412
Epoch 19/24
----------
train Loss: 0.3121 Acc: 0.8811
val Loss: 0.2450 Acc: 0.9281
Epoch 20/24
----------
train Loss: 0.2862 Acc: 0.8811
val Loss: 0.2319 Acc: 0.9346
Epoch 21/24
----------
train Loss: 0.2897 Acc: 0.8852
val Loss: 0.2426 Acc: 0.9150
Epoch 22/24
----------
train Loss: 0.2668 Acc: 0.8934
val Loss: 0.2326 Acc: 0.9346
Epoch 23/24
----------
train Loss: 0.2813 Acc: 0.8852
val Loss: 0.2235 Acc: 0.9346
Epoch 24/24
----------
train Loss: 0.3278 Acc: 0.8648
val Loss: 0.2472 Acc: 0.9150
Training complete in 2m 50s
Best val Acc: 0.941176
訓練結果
accuracyが0.94とか出てますね。転移学習は本当にすごいです。
実際にどのような予測が行われるのかみてみます。
Validationデータの表示
def tensor_to_np(inp):
"imshow for Tensor"
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
return inp
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = fig.add_subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {} label: {}'
.format(class_names[preds[j]], class_names[labels[j]]))
ax.imshow(tensor_to_np(inputs.cpu().data[j]))
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
visualize_model(model_ft)
出力結果

だいたい正解しているようです。転移学習に成功しました!
目で見てもいまいちわからないです。
結論
実際はResNetのfcだけ学習とかのほうが早いし精度も出そうな感じですが、一応転移学習をすることができました。次はDCGANでも実装してみようと思っています。