pythonで多項式フィッティングを実装
偏微分を用いたフィッティング
必要なライブラリのインポートと初期設定
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
sns.set_style(whitegrid)
テストデータの作成
def create_test_data(func, low=0, high=1, size=10, sigma=0.25):
x = np.random.uniform(low, high, size)
t = func(x) + np.random.normal(scale=sigma, size=size)
return x, t
func=lambda x:np.sin(2*np.pi*x)
x, y=create_test_data(func)
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(x,y)
sx=np.arange(0,1,0.01)
ax.plot(sx, func(sx))
plt.show()
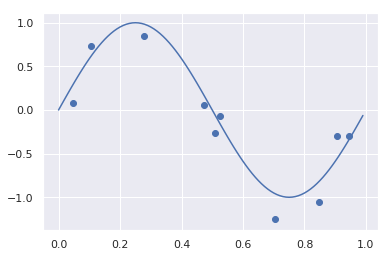
適当な感じにsin curveに乱数足した感じになっています。
fitting
前回の記事で書いたように
\begin{align}
\boldsymbol{T} &= A\boldsymbol{w}\\
\boldsymbol{T} &= \bigl(A+diag(\lambda)\bigr)\boldsymbol{w}\\
\\
\\
T_i&=\sum_{n=1}^{N}t_nx_n^iとすると\\
\boldsymbol{T}&=(T_1,T_2,...T_M)^T\\
\\
&Aはa_{ij}を成分とするM\times M行列\\
a_{ij}&=\sum_{n=1}^{N}x_n^{i+j}
\end{align}
を満たす行列AとベクトルTを求めて重みベクトルwを算出することでフィッティングを行います。
fittingを行うクラスPolynomialFittingを作成します。
次元数Mと正規化項λを初期値として利用して、fitで重みベクトルを算出し、predictで予測結果を算出します。
predictの内部はnp.dotを使えばうまく書けそうです。全体的にコードが汚いのでその辺精進したいですね。
class PolynomialFitting(object):
def __init__(self, M, l=-18):
#次元、正規化項のlambdaを設定
self.M=M
self.l=np.exp(l)
self.penalty=np.diag(np.array([self.l for i in range(M)]))
def fit(self, x, t):
#A,Tを計算
self.A=np.array([[sum([x[k]**(i+j) for k in range(len(x))]) for j in range(self.M)] for i in range(self.M)])
self.normalize_A=np.array([[sum([x[k]**(i+j) for k in range(len(x))]) for j in range(self.M)] for i in range(self.M)])+self.penalty
self.T=np.array([sum([t[j]*x[j]**i for j in range(len(x))]) for i in range(self.M)])
self.w=np.dot(np.linalg.inv(self.A),self.T)
self.normalize_w=np.dot(np.linalg.inv(self.normalize_A),self.T)
def predict(self):
#予測を実行
lx=np.arange(0,1,0.01)
ly=np.array([np.sum(np.array([self.w[i]*llx**i for i in range(self.M)])) for llx in lx])
nly=np.array([np.sum(np.array([self.normalize_w[i]*llx**i for i in range(self.M)])) for llx in lx])
return ly, nly
ということで予測を実行します。
データ数が10なので過学習が起きるであろうM=10で予測を行なってみます。
M=10
polynomial_fitting=PolynomialFitting(M)
polynomial_fitting.fit(x,y)
ly, nly=polynomial_fitting.predict()
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(x,y)
sx=np.arange(0,1,0.01)
ax.plot(sx, func(sx),label='sin curve')
ax.plot(sx,ly,label='not normalized')
ax.plot(sx,nly,label='normalized')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_ylim(-1.5,1.5)
plt.legend()
plt.show()
実行結果

そこそこフィットしてますね。あと正規化すると過学習も確かに抑えられているようです。すごい!
次はデータ数を増やしてみます。Mはそのままで。
n=100

n=500

データ数を増やすと綺麗にフィットしていくことがわかります。
次は最尤推定で多項式フィッティングを行なってみようかと思います。