StableDiffusionは初めての成功した脳の基本構造と動作のシミュレーションである事を理解し、今後の可能性を考えてみる
こちらで内容面に関して少しご紹介をいただきました!!ありがたや🤩
あと、実際に脳とLatent潜在変数、に関する論文を書かれた方が出てきましたね。
脳とこのLDMの関係、潜在変数とクオリアの関係は今後よりクローズアップされていくと思います🤔😊
こんな記事も発見。これって脳(視床)構造の優位性を示している気がするぞ。また別記事で書こうかな・・・?
StableDiffusionと言う脅威のAI
まずお断りとして。生成系AIも色々あるけど、ここでは特に内部構造もソースも公開されてるStableDiffusionの話。特にLDMと呼ばれる構造についてだよ。
StableDiffusion、Qiitaやってる人達は皆さん遊んでると思うけど、最近もすごいよね。StableDiffusionもV2.1になったり、各種の専用に学習したデータセットが数え切れないほどあったりなので、なんと言うか、最初の公開の瞬間から試してた身としては、まだ1年も経っていないのに、もうその差が圧倒的になってることにも驚愕する。
実際にここ2~3日の間に自分で試してるうちに出てきたものをいくつか貼ってみよう。StableDiffusionは2.1だったり1.5だったり、BasilとかAnything4.5とか色んなデータセットを使ってみてる。GPUは比較的非力な自宅マシンのRTX3060だ。
これは去年の8月の公開時に最初に作った何枚かのうち一枚w

そして下記が今のもの!(半年経ってないよ!)






もういくらでも出てくるし・・・シュワちゃん、ちゃんとプロンプトの「smile」に反応して笑ってるし🥰
もはや自分で描けるかどうか、なんてレベルは完全に超えてるし、写真も写真だよね、としか言いようがない。しかも十分にかわいい・・・これがまさに仮想の人間??むー・・・
しかも昔は、いい絵が出るのは10分の1とかだったりもしてて、後は壊れた手と目が3つとか普通だったのに🤤今はまだ多少難はあっても、細かく見ても半分ぐらいは壊れていない(手にも破綻がない)し、3割ぐらいはもう神絵に近いんじゃない?みたいになってきてる。写真としても違和感が全く仕事してない。
これだけの恐ろしいポテンシャルで、なおかつまだまだ改善していて、GPUのメモリも初期から見たらかなり少なくなってるし、最近はTensorRTにするとまだ速度5倍ぐらいになるとか言ってるし、今後まだどんな発展があるのかという状態だ。ここまで来ればどこかが専用ハードにしてしまうのも時間の問題だろう。秒間何十枚の神絵生成も可能になり、
リアルタイム神絵メタバース
とか、10年経てば誰でも使えるレベルで実現してるかもしれない。というか、当然Metaはそのつもりだろうw 自分も先立つもの100億あれば喜んでIC設計から作りますw
つまり神絵専用マシンがもう全人類が手に入っているようなものだ。凄まじい。chatGPTなどと合わせて、生成系のAIに世界中の企業がありったけの投資をぶち込むのも当然だよね。
で、この StableDiffusion、なんでこんなに上手くいったのか。パッと公開されてるソースとか見ても結構複雑なネットワーク構造なので、なんだろうなあ、と思っている人もいるだろう。自分も中を確認してみてるけど、そうしたら、これはまさに脳のエミュレータとしても構造がまさにこうあるべき、になっている事が分かる。自分はこういうの作ったらいいかな、と思ってたアーキテクチャにかなりそのまま、その意味では理想に近い構成なんだよね。で、それが一番上手くいってる。脳の構造に近いものが本当に上手くいく、というあたりもある意味すごい話だ。自然と生物のすごさを感じさせる。
前からも書いては来たけど、ここではその構造を実際に詳細に確認していき、今までの話や、意識の仮説の話、そして素粒子論と宇宙論とも!あくまでざっくりだけど繋げてみようかと思ってる。
どういうネットワークなのか
まずはここをよく確認しよう。今までと同じで、自分で何かいてももう情報は出てるし、まとまってるから参考は以下のようなビデオを見てもらえるといいと思う。実際に説明のために画像等も利用させてもらうよ。
こういうのもYoutubeとかでも、煽ったりよくわからない説明と後は「触ってみた」「ひたすらエロ絵を作る!!」だけしている人たちが日本人大杉問題・・・この映像自体は日本語翻訳すれば日本語でわかるよ。
で、全体構成はこんな感じだ。上記映像にあるしまあもちろんもともと公開情報。
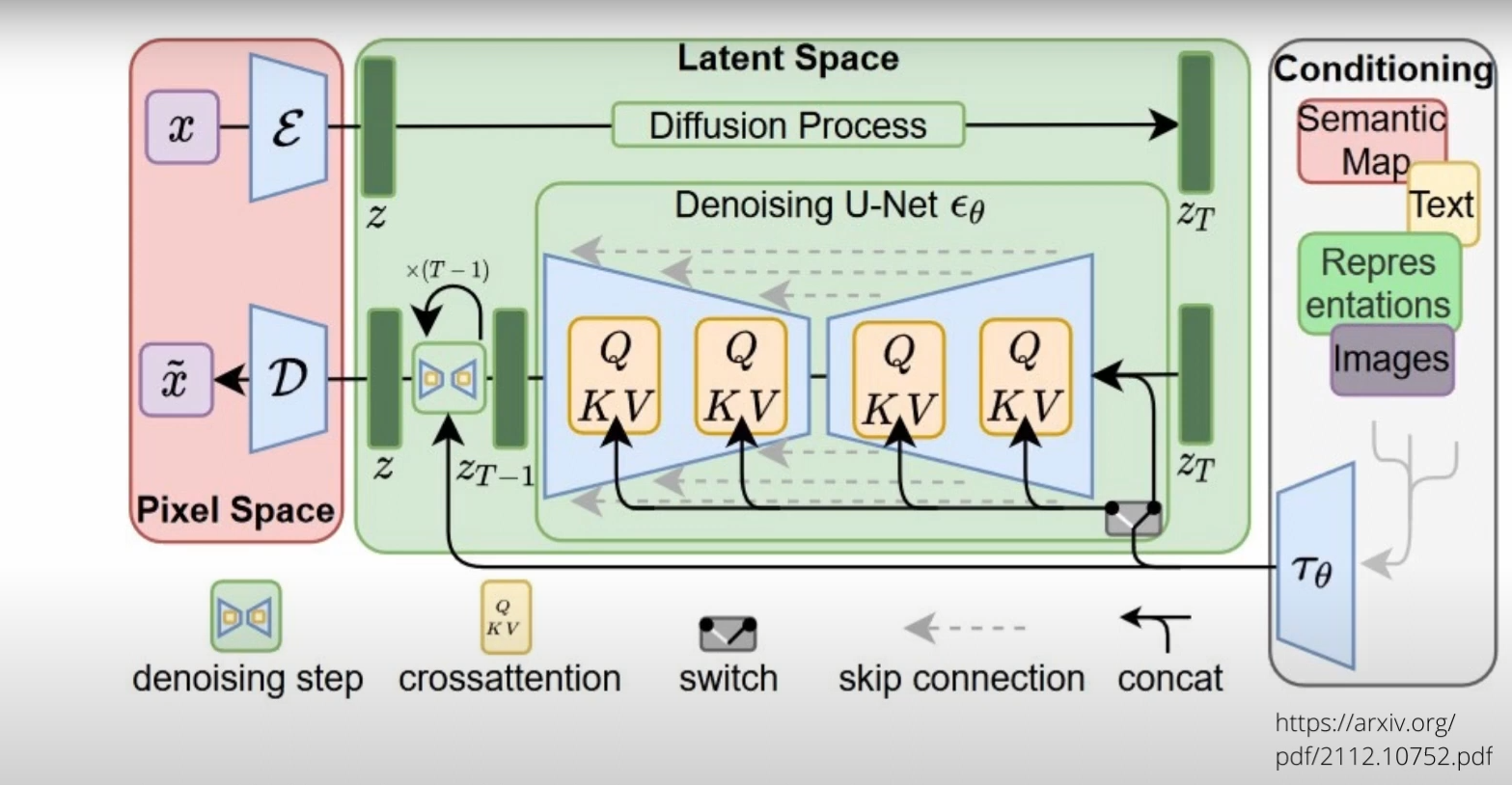
これが!!脳の!!シミュレーション!!??
なんだかわかんない・・・かな?説明は本当にしてると長くなりすぎるし、上のビデオでも勉強できると思うので、ここでは要点に絞るよ。
基本動作
本当はあまり説明しないつもりだったけど、さわりだけ乗せとくね。退屈なら下に飛ばしてください。
このStable DiffusionのLDM(Latent Diffusion Model=潜在変数拡散モデル)はもともと以下のような動作をしてる。
まずは、いろんな絵をノイズをだんだん加えてわかんない絵にしていく。拡散過程。【Forward Diffusion Process】と呼ばれる。
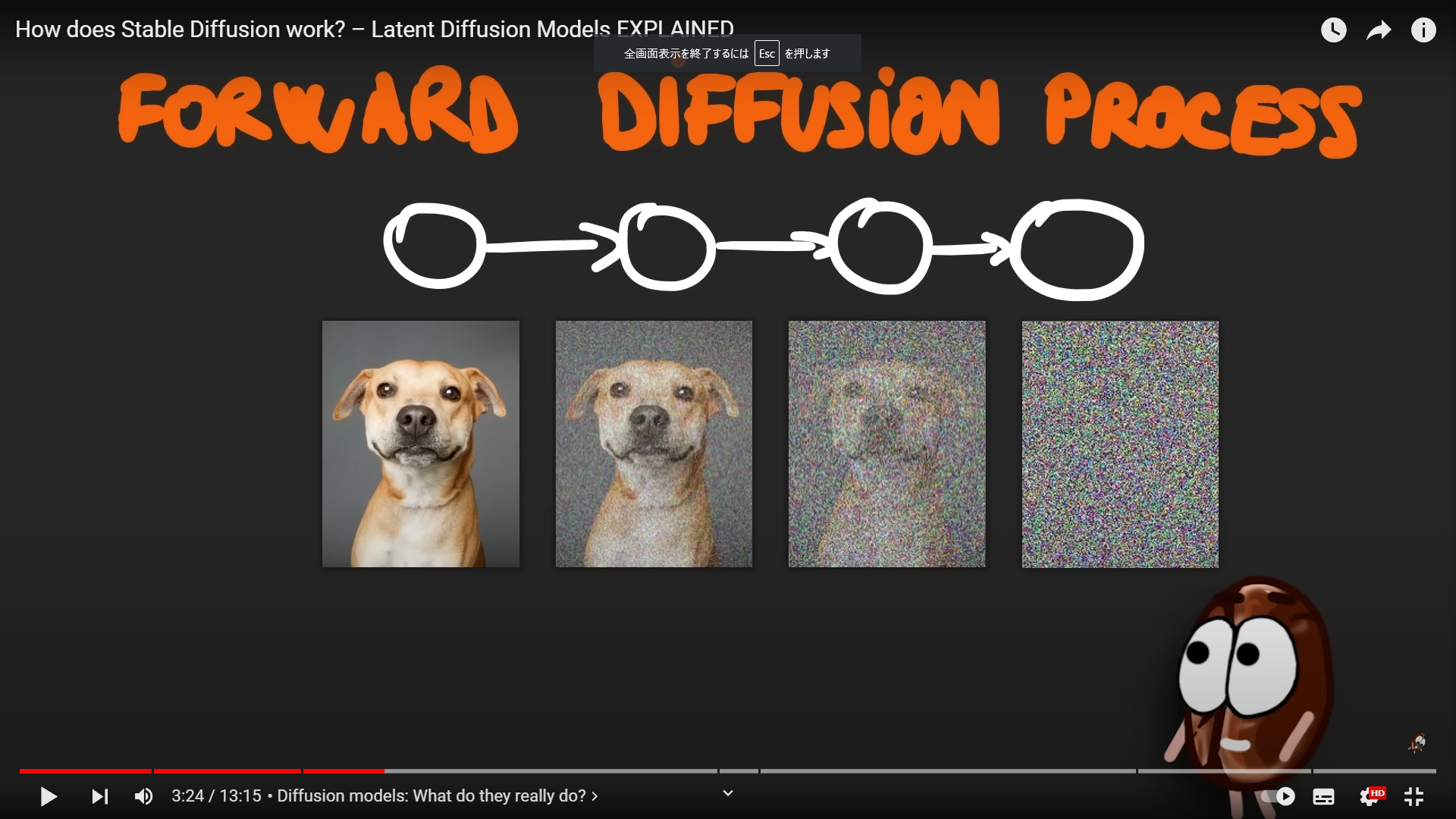
【拡散過程(Forward Diffusion Process)】
で、このニューラルネットは基本的には、ノイズを与えられたら、元の絵を類推して描けるようにしていく。これが逆拡散過程【Backward Diffusion Process】だ。

【逆拡散過程(Backword Diffusion Process)】
これを学習でやれるようになったネットワークは、どんなノイズからでもなんか絵をでっちあげられるwようになる。それがこの拡散モデルの基礎だよ。これはまあノイズ除去の仕組みなんだよ。でも何出てくるかわからないし、何か意味のあるものを書いてよ、と言っても、なんか色とか見てきれいに塗るだけだから、ノイズ除去とか、解像度を高めるための超解像処理にしか実際にあまり使えない。まあそれはそれで役には立つけど1からまともな絵は書いてくれないよね。
でもLDM(Latent Diffusion Model)と呼ばれるこのStable Diffusionのネットワークはこれとはいろんな場所で違っていて、それが、まさにこのネットワークを脳の動作と構造に近づけ、神絵を量産可能になってきた部分、まさに秘密の構造、いわば神の構造だ。以下それを説明するよ。
LDMの構造と動作
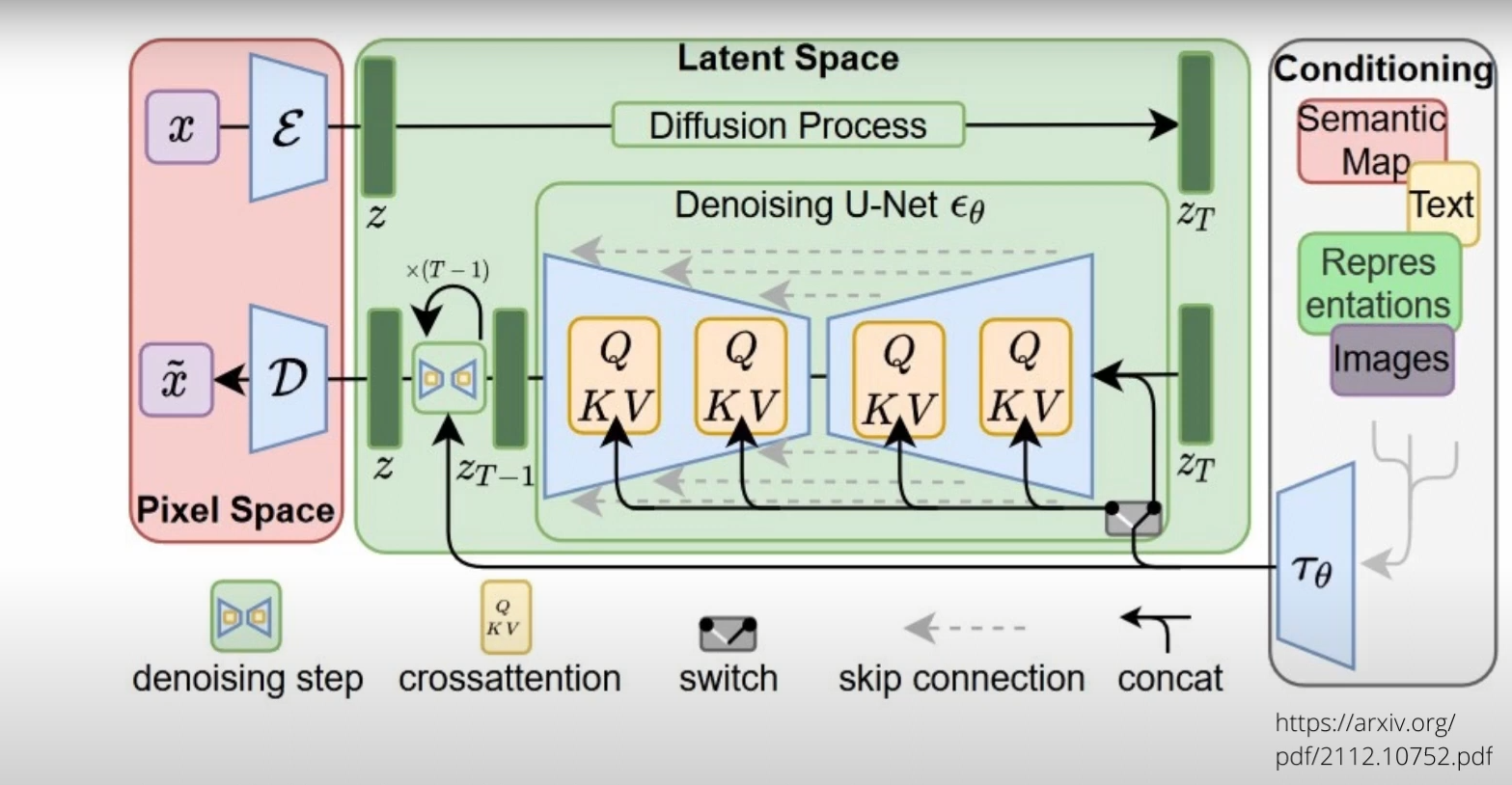
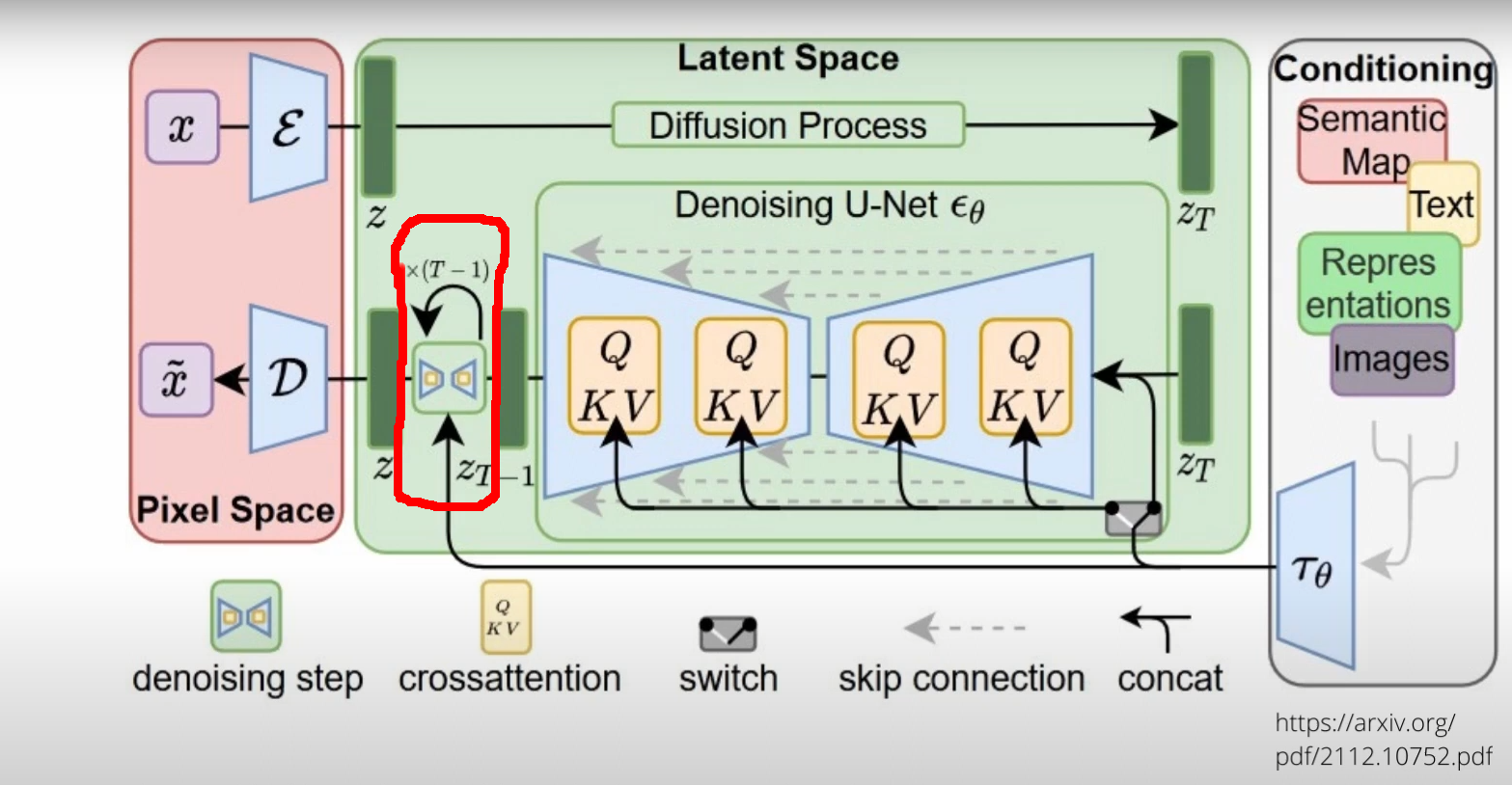
まずは左のピンクの箱( Pixel Space )からの左上から処理が始まる。ここでは最初は空の大画像がある。(img2imgの時にはその元になる画像)それをまずεの所で小さい画像にエンコードする。これで画像サイズを小さくして内部での処理量をぐっと減らすAE(オートエンコーダ)を通るんだけど、普通のとちょっと違うのはこれは「VAE(Variational Auto-Encoder)」である事だ。これは何かといえば、ここからただ単に絵を小さくするのではなく、その「潜在変数(Latent)」を抽出しながら情報量を削減する。この時に要は絵そのものでなく、「絵に入ってる概念」を抽出するんだよね。目が大きいとか小さいとか、何かは学習に寄るけど、とにかくいろいろな概念として情報を圧縮してる計算をしている。これがまずこのLDM(Latent Diffusion Model)の非常に重要な部分だ。
このVAEは下の図のように、画像からLatentを取り出して、それをまた元に戻す、という学習をさせられるよ。まあ絵から概念を読み取って、その概念から絵を描き戻す、というプロセスを何回も学習させるんだね。人間でいえば、絵をみながら、単に真似をするというよりは、分析をしながらその本質を見極めて同じような絵を描ける、という事を学習することに似ている。VAEだからこそ、単なる真似にはならないで、概念を扱いながら絵をまねる、という事が可能になるんだね。
【VAEの学習 - 絵を分析(Latentに変換)して書き戻す学習をしているね】
そしてその後、ノイズを徐々に加えて、この場合には初期値の空白画像をノイズまみれにしていく。ここが、「(Forward) Diffusion Process」だ。
ここでZtというノイズ画像がまず得られる。ただこのノイズは、概念が詰まったノイズになる。いわばアイデアが無限にランダムに詰まった箱になっている、事になる。
そして「概念の塊」になったデータを右のうすい灰色の所( Conditionning )、で得られている情報も使って変化させていくよ!!これは文章や画像から得られた結果、つまりこれも概念=Latentだよ。意味を抽出して、それを使うという事。絵そのものではないんだよ。
そして、その概念を。まさに真ん中の箱、「 Denoising U-Net 」の所で、今ある概念と、「混ぜ合わせる」。このまぜまぜは基本的にはU-netにTransforrmerのヘッドを付けたようなものになっている。
U-Netはもともとの基本形は以下のものだ。(情報の流れは上の図と逆になってるから注意)
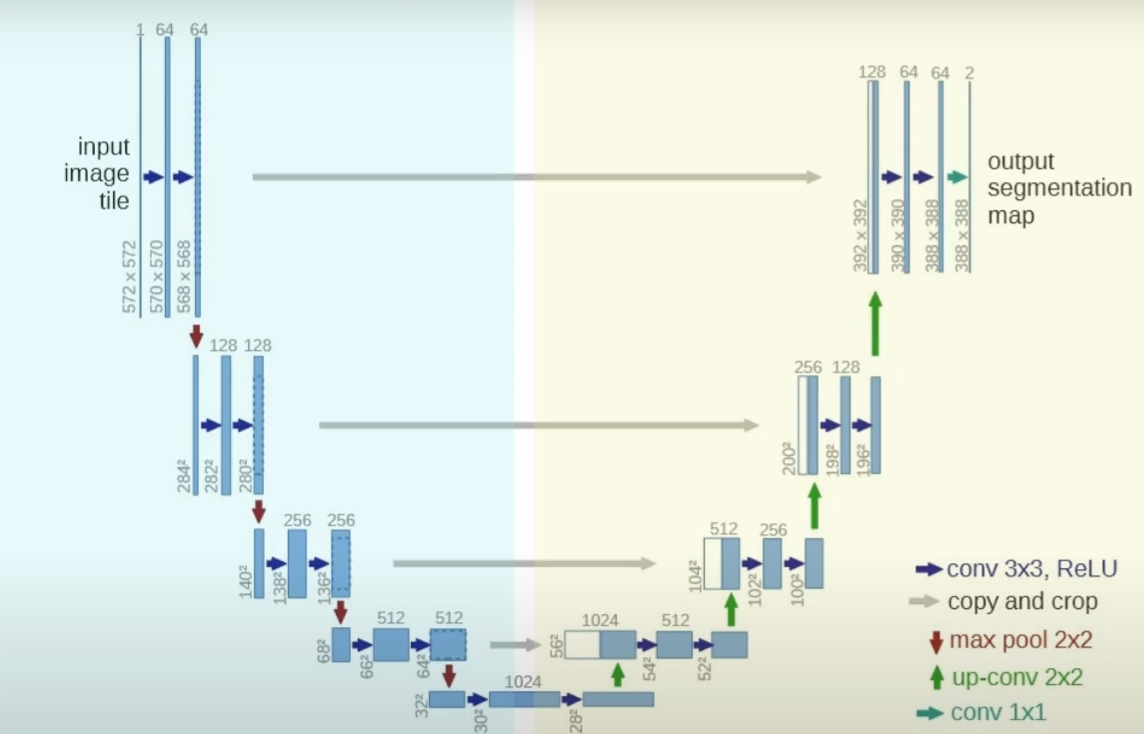
【U-Netの構造(基本形)】
この構造は、Uの真ん中の下の方に行く毎に、データをどんどんと「圧縮」する事で動作する。これによって、重要でない情報を減らし( ないし融合して )、重要な情報だけが残る。その上でまた、それを広げていく。VAEもそうなんだけど、このU-Netも情報を「小さくまとめて」「その後で広げる」という動作をしていることに注意したい。(U-Netは元の情報も上で並列で通している所がAEとは異なるけど)これが非常に重要な話になる。とんでもなく重要な話だよ。
その中でまずは、映像で紹介されてるけど、実際にはノイズ除去を行うより、 元のノイズの方を!類推する処理をして それを使って元絵をノイズなしに近づけていく。この処理はこんな感じ。
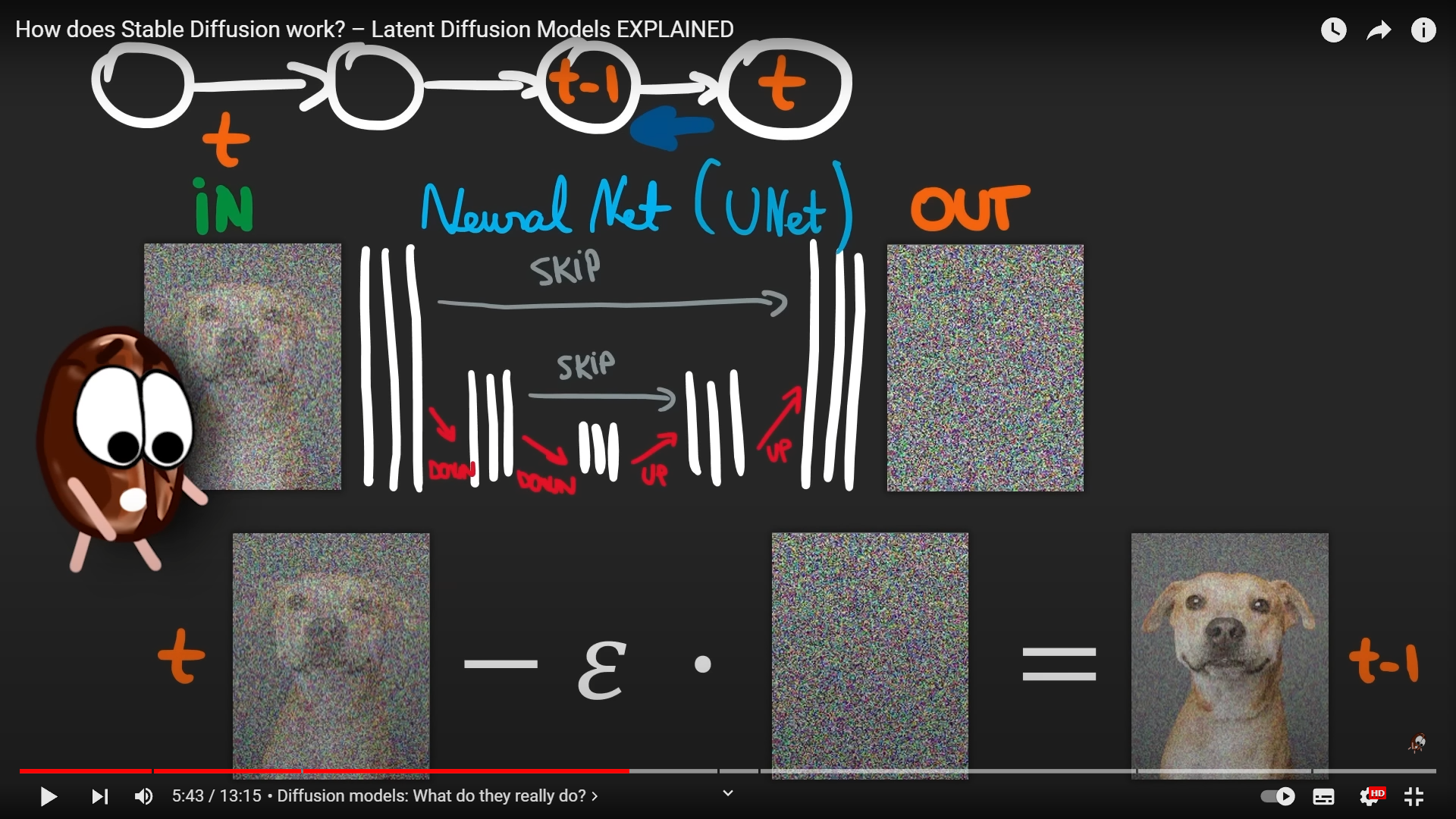
【LDMのU-Netの逆拡散プロセスの動作】
そしてこの圧縮と展開を行っているまさに最中に、この「Denoising U-Net」では、テキストや絵から得られた概念情報、潜在変数(Latent)をこの中に(Q,K,Vの所でそれぞれ)「混ぜて」行っている!!下の図の左下の[Transformer]から、多数の線がこのU-Netに入っているのがわかるだろう。
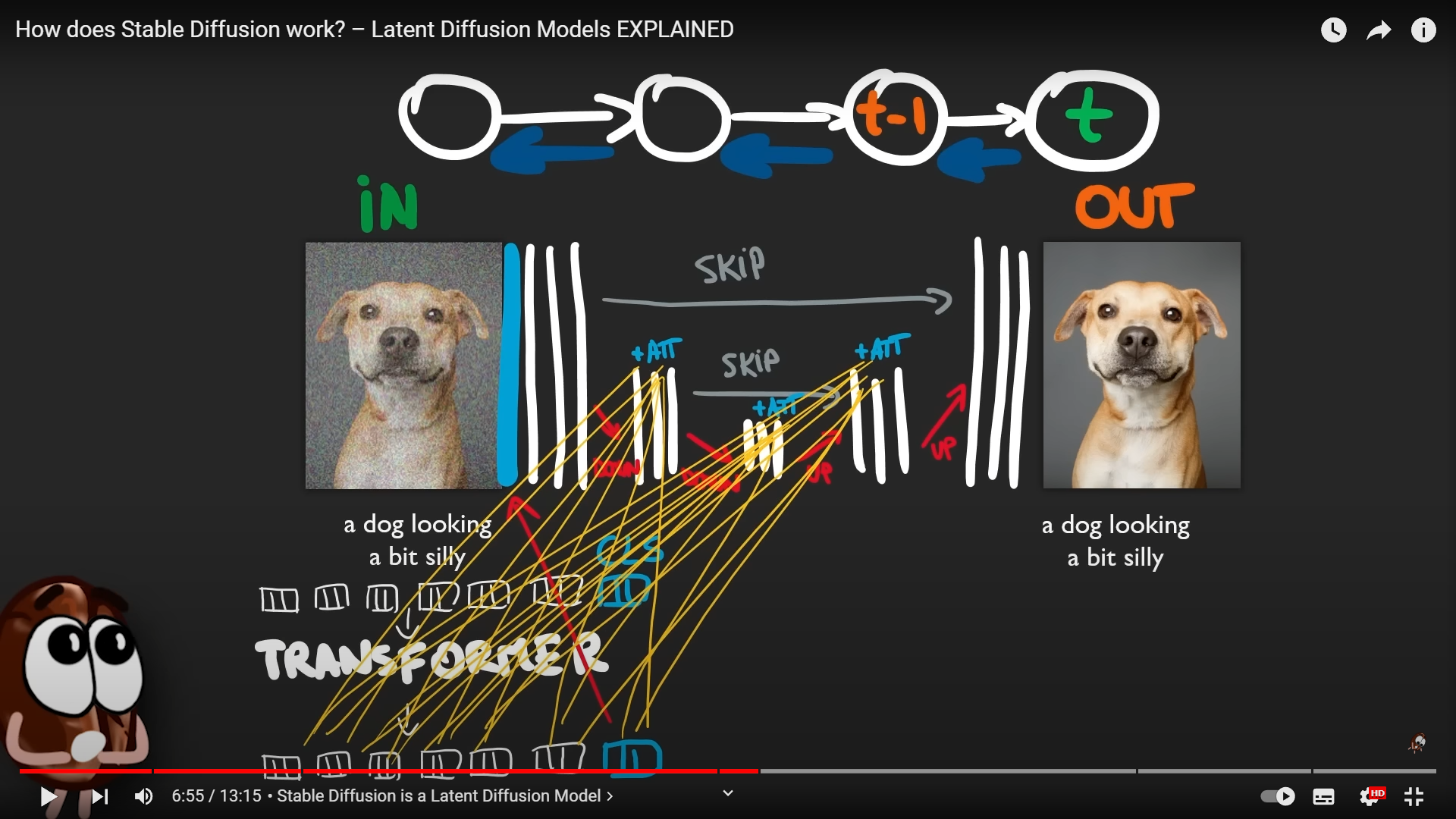
【概念の注入プロセス】
これによって、元あった絵の概念は、混ぜられた文字や絵の概念に影響を受けて、変化していく!!!そして影響を受けた概念は、少しだけ明確な絵になって行く。繰り返しのSTEP数はまさにこれを何回繰り返すかという事だよ。
【デノイズの繰り返し。まさにあのSTEP数がDenoising U-Netを何回通るかを示している】
そして、概念の入った小さな絵の元は変化する。ノイズだらけの概念は、少しだけ整った概念の集合体になって行く。
最後にVAEのデコーダを通ってLatentの集合は大きな画像になる。これが出来上がった絵になる。
Stable Diffusionを使ってる人たちは、 STEP数を上げないとテキストが反映されにくいので詳細度をますならSTEP数は多めに という事を知ってるだろう。
これがまさにこのLatent SpaceにSTEP毎に概念を混ぜている、からそうなるんだよね。
ここが一番恐ろしい所だ。このStable DiffusionのLDM(Latent Diffusion Model)は絵そのものでなく、概念を含めて整理して描いていく。つまりこのネットワークは 意味と概念 を扱い、それを使って絵を描いていく、んだ!!
これはまるで、自分たちが文字や例の絵を見せられながら、自分たちの絵の考えを何もない所(=ノイズの塊)から、コンセプトを練って、ラフを書き、それを細かく修正しながら細部を書き込み、完成絵にしていく、というプロセス、まさにその通りの流れになっている!!そしてこの流れは、処理というだけでなく、認識結果がクオリアとして「意識」に上り、そしてその内容をもとに我々が何をするかを決めている、というその定性的な関係とも完全に一致している事に気づくだろうか?
つまりこの構成は実際に我々が、そして神絵師の人たちがやっているプロセスを実際に、処理系として実現しているのだ、という事が明確になる。
脳の構造とのとんでもないレベルの類似性!?
て、機能的には同じような事をやっているからこそ、まさに同じようなものが得られているのだな、という事はわかると思う。だけどそれだけじゃね。実際の脳とは構造も全然違うだろ?簡単な話じゃないだろ!!と思うかもしれない。しかし実際には、このStable Dfffusionを形作るLDMの構造は、脳の構造のまさにコピーともいえる構造を持っている。それを下に示そう。
元記事は下記で見れます。
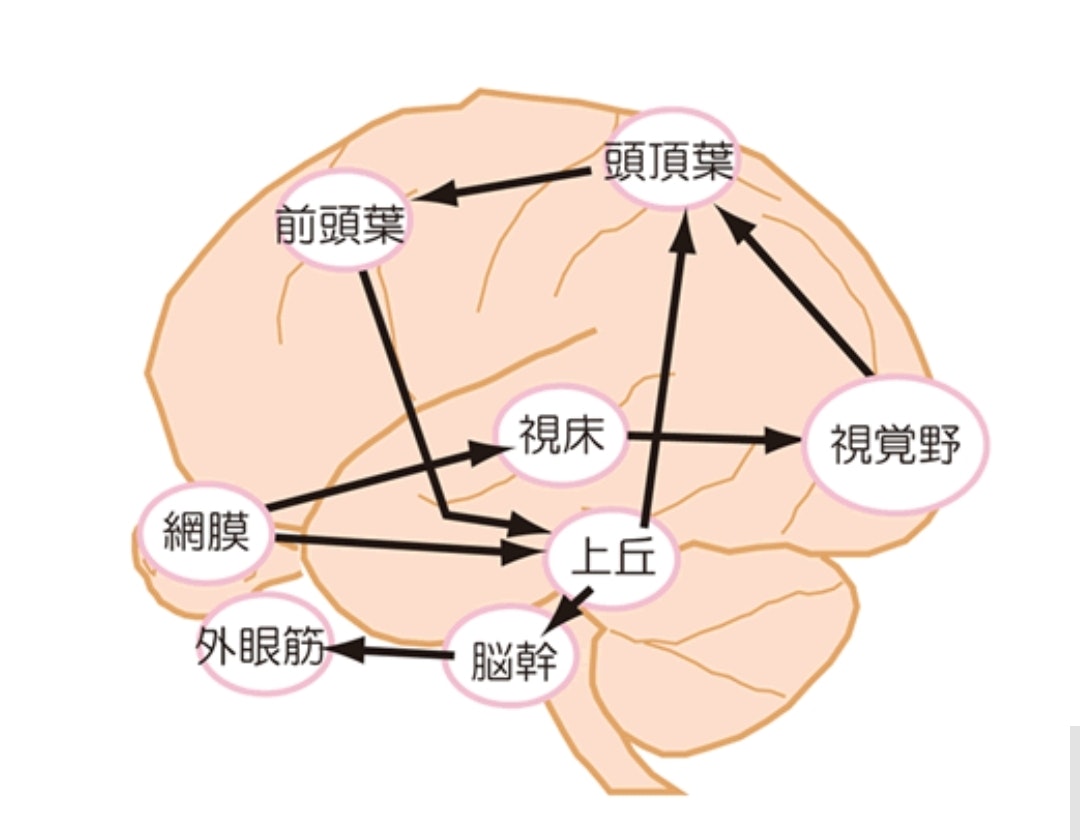
これは前に書いた脳の簡単な構造と視覚に関する神経の接続だけ示したものだ。そして、以下のように、視覚が「意識」に登るためには以下のような経路の違いで差が出てくる。
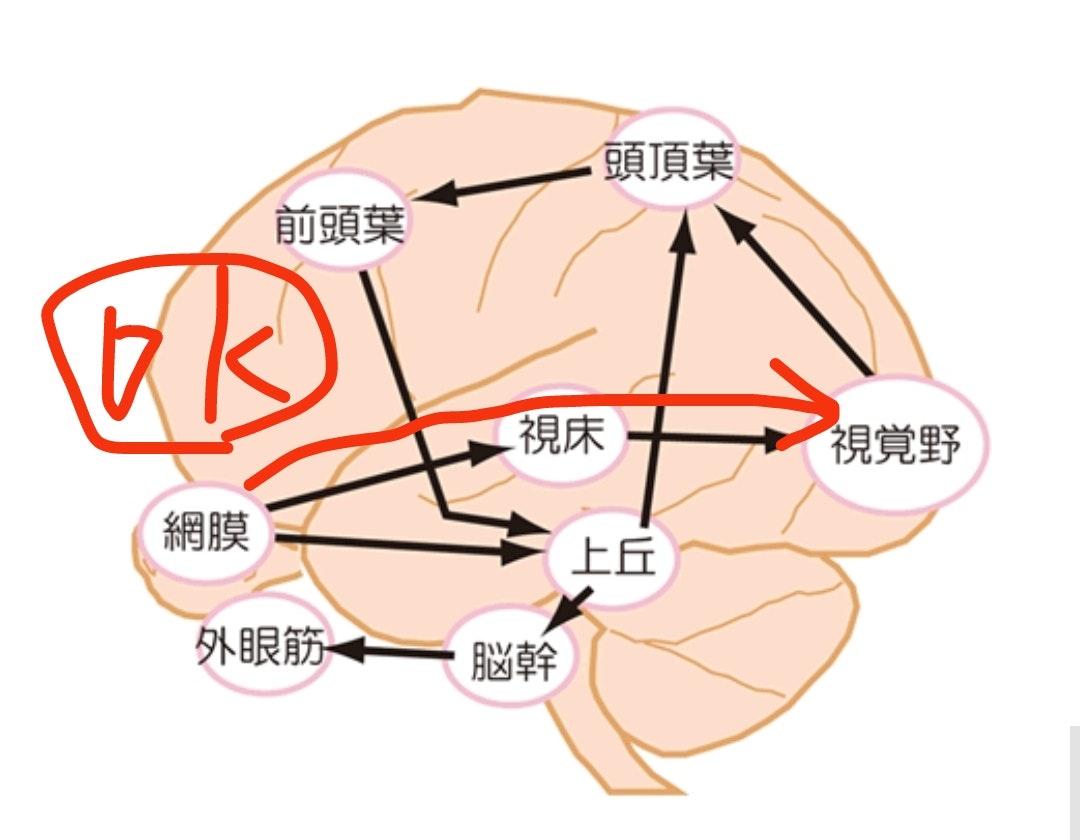
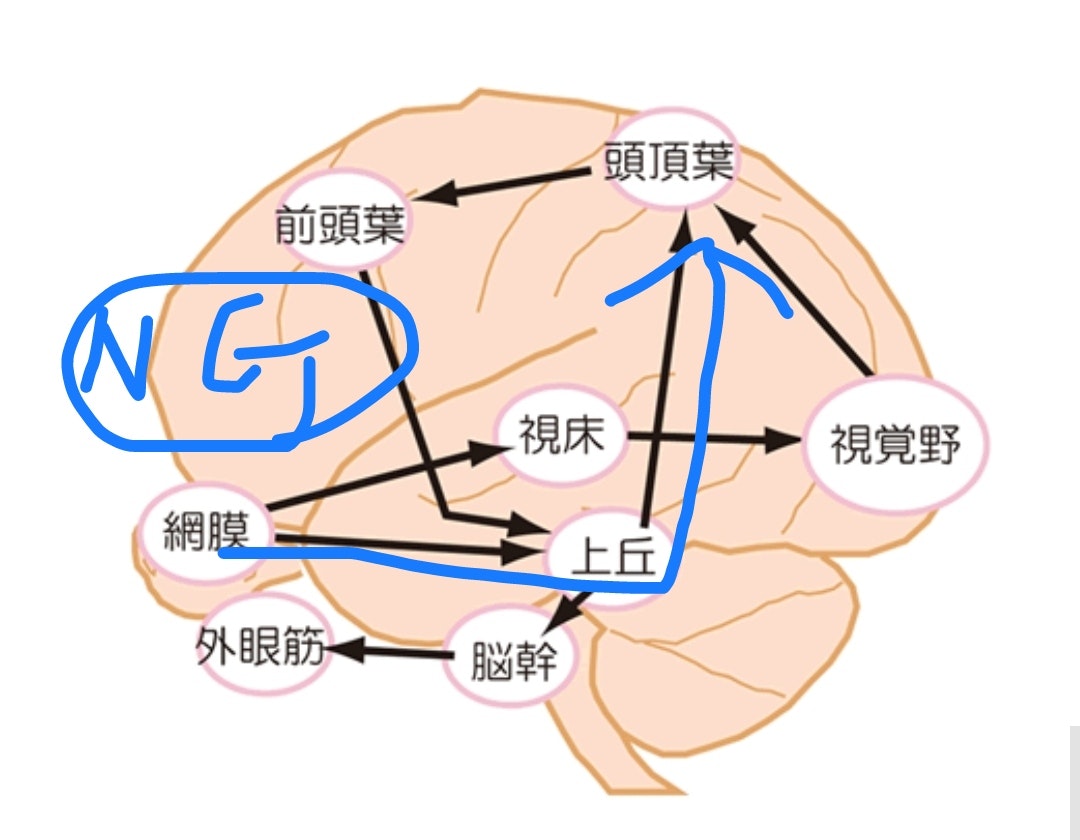
OKと書いてるのは【視覚意識が発生している】、そしてNGは【視覚意識が発生していない。いわば盲視の状態】だよ。盲視の状態でも人は高確率で見えてない物体の方向を当てることができる。意識がなくても人間は認識も動作もできる、というダイレクトな例だよ。
これが視覚意識の発生には視床と大脳視覚野が必要であるという事を強く類推させてるわけだけど、この構造のどこがどこに当たるのか、それを考えてみる。
脳は前も言ったけど、元々生まれたてでは大脳はほとんど白紙の未学習エリアだ。視覚野さえほとんど作られていない。だから赤ちゃんは生まれたてでは「明るさと僅かなぼやっとした視覚しか持ってないと考えられているし、実際の反応からもそれは十分にそう思える。」
その時には要は人間は「視床でほぼ生きている」だからそこに情報は全て入っている。しかし、明らかに視床の情報処理能力は超えている。なので大脳が作られる(学習で機能するようになっていく)。大脳は上の図のどこに当たるか、と言えば、画像を認識している場所であり、そこから必要なLatentを取り出す作業をしている。つまりはそれは右側の箱だ。ここには、テキストの概念や、有り得るなら、音声からの概念認識、つまりは、「聴覚野」も入ってくるだろう。
そして、真ん中の「Latent Space」はそれから考えればまさに「視床」に当たる。このLatent Space自体が概念しか扱わないのは、このネットワークの成立の仮定を知っていれば(上記の動画でも紹介されてる)、つまり、フラットな画像を扱うのは情報処理的に厳しすぎるから、概念の形にまとめてそれを処理する、となっている事が分かる。つまりは元々は、 視床でも、お絵かきAIでも!!処理がオーバーフローするので 概念だけを扱うようにしたのだし、それによって必然的に扱う情報は生の情報というより、「概念」だけを扱うことになり、それが何と 「抽象化」された概念、クオリアに相当する概念情報を必然的に発生させた という事だ!
そして得られた情報は再びVAEのデコーダとして大きな情報量に戻される。ここも、まさに大脳の絵を細かく書く部分であり、細かい指先のコントロールをする、大脳に当たることになる。
図に示すとこんな感じだ。
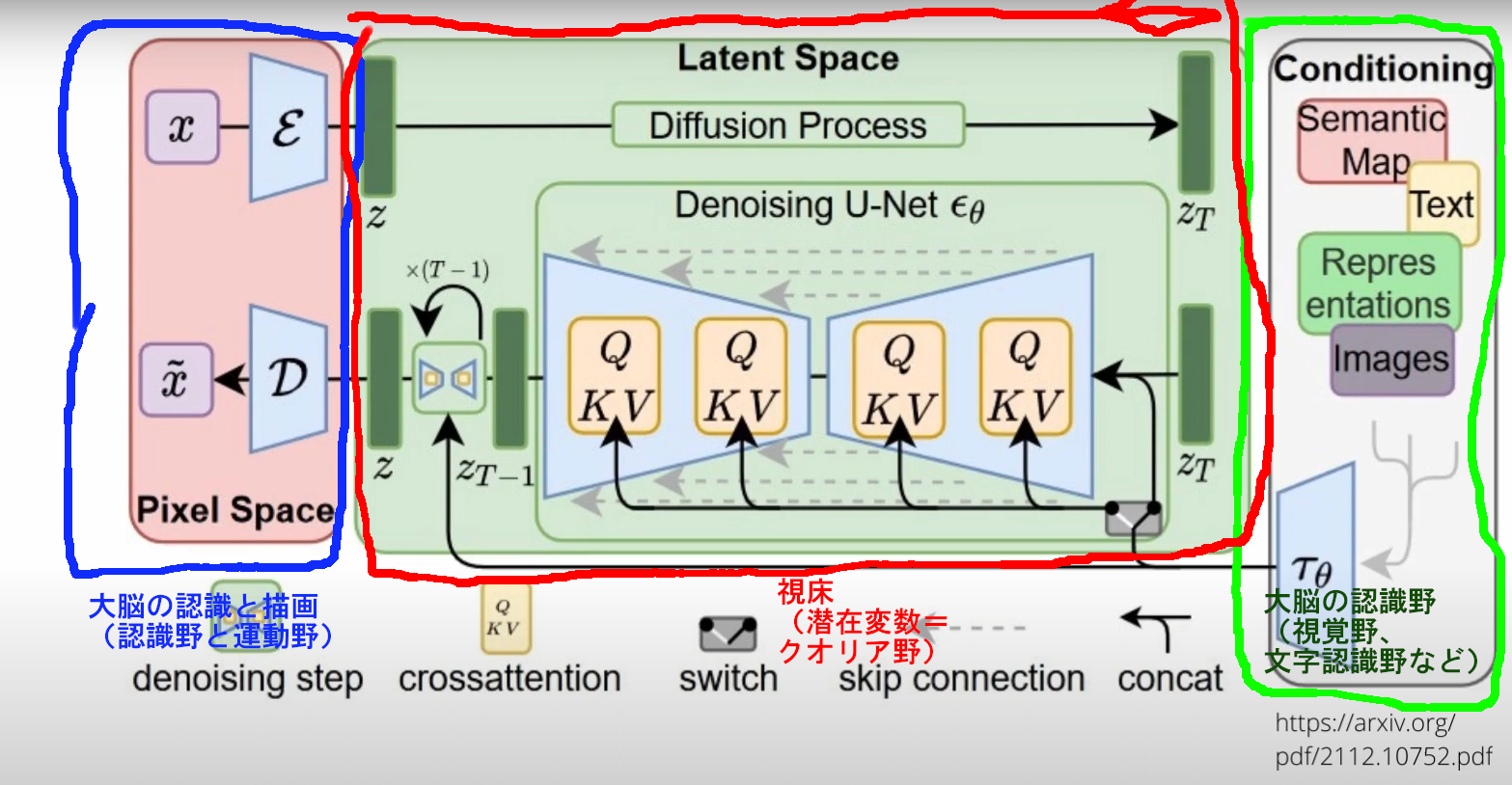
【Stable DiffusionのLDMモデルと脳の対比】
つまり、このLDMのモデルは、視床と大脳の繋がりと、その処理を「構造そのまま」実現している、ということになっている。
視床も、このLatent Spaceも、まさに小さくて処理量が間に合わないからこそ、概念だけの演算を行う処理装置に特化し、概念を得たり、作った概念を実現する部分はより広大なネットワークである大脳に任せている、その構造は産まれてからの学習でスキルを高めていく。視床の動作も発振を繰り返している、と前に述べたし、それは実験としての事実なんだけど。これはまさに、
LDMのDenoisingのSTEPの繰り返し、に相当している処理だyo!!
そしてStableDiffusionやってる人なら知ってると思うけど、この中のVAE(の重み)を取り替えて得意な絵のジャンルに合わせたりする。これはまさに細かい絵の細部を描く部分を「取り替えて」良い絵を描くことに相当している、という事だ。絵柄を変える時には何回も練習が必要になる。これは人間がVAE部分を変えるにはいわゆる「手癖」を変えないといけなくて大変に苦労する、ことにまさに同じという事だ。
(LDMモデルは一瞬でこれが入れ替えられるけどね!!)
一方でLatent Spaceの重みを取替えるということは、まさに中に入ってる人の、記憶、触れてきた絵の概念自体を取替えて違う絵をかけるようにする、事になる。これは何か指示が来た時の絵の発想の部分を取り換えていることになるね。
人生は一度しかないけど、LDMモデルは中の人ごと取り換え、手癖の大脳も取り換えて、違う絵を描けるんだね。なるほどだね!!!
どうだろう。こう考えると、このLDMが何か、そして何をやってるか、どこを変えればどうなるか、とても明確に見えてくるし、それがまさに我々の脳を構造も動作も含めて同じような処理をしている事が分かるだろう!!
つまりは、これはもうある意味では人工の「脳」であり、実際に動作しているという事だよ。ビジネスの話だけ盛り上がってるが、このLDMの構造が実際に動く状態で公開され、みなが改良できる状態になった、という事は、人類史上でのここ数十年で(いや人類史上??)最大のイベント、なのは間違いがないんだ。そして、この構造の中での
潜在変数Latentはまさに意識の中の「クオリア」だ
両眼視覚野闘争で、両眼の大脳の処理は見えない。それはこの結果がまとめられた後の「概念」として視床にフィードバックされているからだ、と考えれば全く問題なく説明ができる。右側の大脳内部の認識計算は、Latent Spaceには見えていない。だから!両眼視野闘争での絵の入れ替えが起こるんだよね。
このモデル、この概念、まさにすべてがクリアになっていて、今のところは矛盾点が見えないという事だ。
汎用人工知能=AGIはある意味ではもう実現している!
つまりは。
もうある意味での脳が人工的に構造も機能も「実現し」、そのために、神絵をガンガンと「創作」できるようになった、と考えられる。LatentSpaceは脳が視床を使っているのと同じで汎用の概念=クオリアの演算回路だ。まさにLDMはAGI(Artificial General Intelligence=汎用人工知能)の基本設計であり、既に実現され、多大なる可能性を人類に示している!!
もちろん今のLDMは絵を描けるだけ、だ。しかし、Latentを扱うLatent Space自体は実際には概念なら何でも飲み込める、汎用のまさに潜在空間、クオリアどうしが演算されるスペースだ。これもまさに自分たちの意識構造がそういうものだ、という事がよく知る人ほど理解できると思う。だから、後はこれを「拡張していく」事でそれが汎用の人工知能、まさにAGIとして機能する事がわかるだろう。
chatGPTはそれからいうと、今の状況はまさに「巨大すぎる大脳」だけだ。ある意味での恐ろしい有能さと、何かが決定的に抜けている感のある受け答え、それはまさに、このLatent Spaceを明示的に持っていない、ある程度自発的にその構造が内部に出来てる可能性は十分あっても、構造的にはフラットすぎるのだ。だから、自分はGPTは今後、LDMと同様で、Latent Spaceと今のGPT部分とが融合されていくことで、本来の脳と同じような意識的なふるまいを明確に始めることになるだろう。と考えている。
(ちょうど、GoogleがchatGPT対抗の「Bard」出してきたね。たった80億パラメータだけど、chatGPTよりまともだ、と主張してるらしい。そうGPT3は構造の最適化のないものだ。設計的には厳しいはずだと思う。アーキテクチャの改変が今後いっそう進むと思う)
みんなそんなこと思ってました??StableDiffusionと脳構造の関連。考えれば考えるほど、これは人類史での大きな大きな事件、であることがわかってくるはずだよ。
この構成と素粒子論と宇宙論、意識構造との類似
そして実はね。この構造だけど。もう一度ここで、Stable Diffusion(=LDM)の構造を下に書くよ。
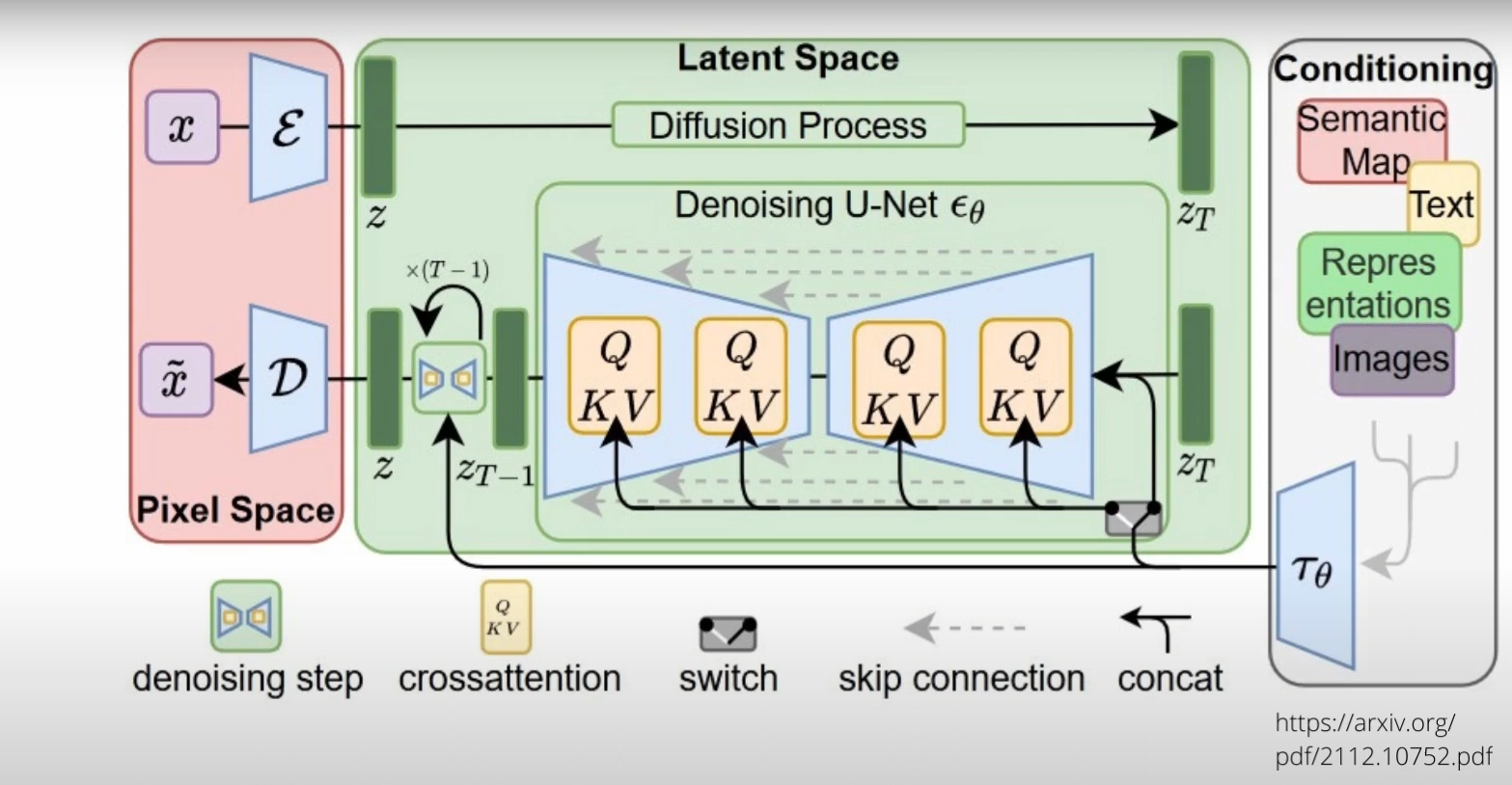
この構造は上で少し触れたんだけど、
情報を圧縮し、Latent Spaceに渡し、そこでLatentをうりゃうりゃ混ぜ合わせて、その結果をまた間を補完しながら大きくして精緻な結果を得る
という構造なんだよね。つまり情報は一度どんどん圧縮され、情報量は減っていき、そしてその中で最適化を行う、という処理になっている。
これは実は、前にも書いていた、この宇宙のAdS/CFT対応における、AdS、つまり反ド・ジッター空間の構造そのものになっている。またこれは素粒子物理学における「疎視化」であり、「繰り込み」と同様の処理であることもすぐ分かる人もいるだろう。すべて情報量の削減処理なんだよね。そしてその処理は「テンソルネットワーク」で行われる。まさにAIでも脳構造でも、そして量子もつれの系でも、同じ処理が行われている。

この絵の端の模様が真ん中に行くにしたがって減っていく。これがまさに空間の細分化の減少=情報の圧縮を意味している、訳だ。
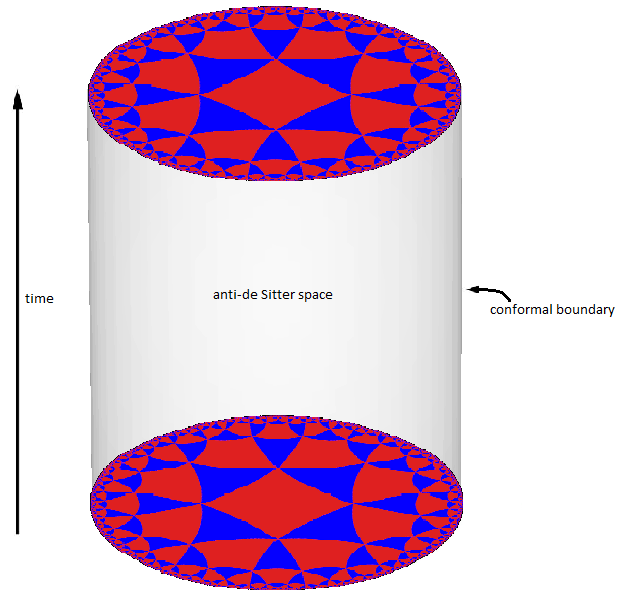
つまりこのLDMの基本構造は、今までのすべて見てきた人たちは分かると思うけど、かなり強い意味、要は 物理的に同じ という意味で
「脳と同じ」「量子の世界と同じ」「量子コンピュータと同じ」「宇宙と同じ」「単細胞生物と同じ」であり、量子もつれ、を起こす部分が実際に時空構造に情報空間を作るから、意識ができるんだろう、と考えることができる。
意識の構造仮説に関しては細かくはこちら見ていただければと。
こちらは概略図だよ。
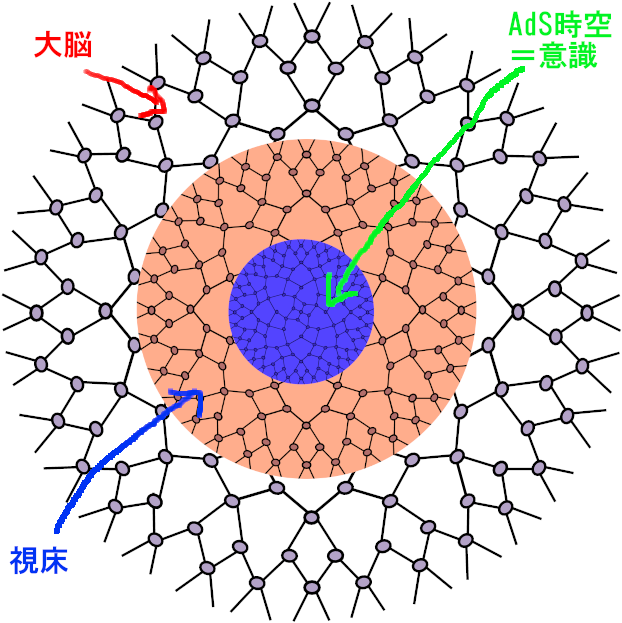
【前にも書いた大脳と視床・意識の構造仮説の図】
上記の図で視床の中の構造が真ん中に行くほど疎になっていることがわかるだろう。これがLDMのU-Netであり、AdS空間に相当するんだね。時空のAdS構造で実際に最終的にLatent、そしてクオリアが攪拌されて意識を形成している、と考えられる訳だ。
ただし、このStableDiffusionのLDM自体は前から書いてるけど、あくまで「シミュレーション」であり、物理実体がない。だから生命や脳とはここが決定的に違う。意識的にふるまったとして、意識を反映させるための実在する情報空間はない。要は、時空構造と同じような「 量子もつれ 」を発生しない。すべては計算処理の中の数値。つまり意識はできない。つまりはこの人工脳の最初のモデルであり成功例のAI神絵師のStable Diffusionには意識はないよねw今後も発生しないだろう。
皆さん良かったかな??w
でも量子コンピュータとAIが統合して量子もつれを使いだしたら??AI神絵師にも意識できそうだね。
究極の統一理論と存在の生成の可能性
という事で、またStableDiffusionという人工神絵師、というか、構造を見れば 人工脳 に近いもの、をめぐって書いてきたけど。そして生命も宇宙も素粒子もある意味では同じ構造であり、だからこそこの宇宙の一員なんだろう、って話でもあるんだけど。これが真理だとすれば我々はもう神の領域にいよいよ近づいていて、世界の創造、そして「存在」の創造を考えられる時期はもうすぐだという事だと思われる。
LDMの構造は結構実装の話だし、ソースもちゃんと公開されてるわけなので、別に怪しい話ではちっともないんだけど、ここで広がる量子もつれや脳と意識や宇宙とのつながりの原理というか仮説を今の人達が受け入れるかどうか、それは数百年後かもしれないし、数日かもしれないけど、自分としてはいろんな所がつながって見えてて、結構楽しい世界になってる。今回もあっさり書くつもりが何回も書き足す羽目にw
でも同じことを考えている人は、たぶんもう世界には何人もいるだろうと考えている。少なくてもかなり近い事を言ってる人たちはもともとのペンローズなど含めて多数いる。自分はもう少し進めて考えてるだけだし、証明まではなかなかできないだろう。あと自分が考えていることは最低でも1000人はもういる、というのはよく言われるし、ある意味ではすべて今の物理や実験結果や定性議論のどこかには載っていて、突拍子もない所はあまり含んでもいない。まあ妄想と言われても別にいいけど、言う人たちはちゃんと考えて理性的に反論してくれたらいいかなとは思ってるし、こういう発想の面白さを理解してくれる人が日本でも出てきてくれたらいいな、と思ってるよ!
あとこれ見て一緒にAGI作ろう!って人いたら連絡ください(本気)