前置き
「機械学習」の解説をしますが、著者は専門的なバックグラウンドが未熟であるため、根拠が不十分であったり主観に基づく感想程度の記載があります。
本記事は参考程度とし信頼できる情報源については各自で調べてください。
機械学習とは
大量のサンプルを元にモデルを作成し、そのモデルを使用し未知のサンプルが何者であるか分類する行為そのもの、又はモデルを作成する過程を「機械学習」と言います。
「サンプル」、「モデル」、「分類」とは
平均体重を求め平均体重以上であれば肥満とする、といった話を想像してください、その場合「サンプル」、「モデル」、「分類」の単語は以下ような使い方をします。
-
サンプル(サンプリング工程)
個別に体重を聞いてまわる、アンケート用紙に体重を記載してもらう等して体重データを集めます、この体重データを 「サンプル」 と呼びます、収集する事を 「サンプリング」 と呼びます。 -
モデル(モデリング工程)
体重の平均値を求めます、平均値を 「モデル」 と呼びます。 -
分類(分類工程)
平均を超えるか平均以下かを判断する行為を 「分類」 と呼び、平均超えを「肥満」と決める事を 「ラベリング」 と呼びます
機械学習 とはサンプリングし、モデルを作成し、モデルを使用して分類を実行する工程全体を指します、モデル計算部分だけを「機械学習」と呼ぶ場合もあります
サンプリング、サンプル、モデル、ラベリング、分類、これらの単語は複雑さや目的が異なっていても機械学習で使用される汎用的な言葉です、あるタスクにおいてこれらの単語が具体的になにを指しているか想像できるようになると機械学習への理解が深まると思います。
「特徴化」について
前述の工程解説には誤りがあり、サンプリング工程とモデリング工程の間に本来は「特徴化」という工程が存在します、概要を知る上で話が複雑になるため省略しました。
本来の工程は 「サンプリング」→「特徴化」→「モデリング」→「分類」 となります。
例え話の「サンプル」に「身長」もあったと仮定します。
できるだけ正確に「肥満」を分類したいので、 身長÷体重 で比率を算出してから比率平均を計算し、 比率以下であれば「肥満」とする という計算にします。
この特徴採用により単純な体重平均より正確に肥満が分類できるようになりました。
既存の数値に 「分類に有利な加工を加える」 事を 「特徴化」 と呼びます。
特徴化には以下のような物があります、多種多様すぎて書ききれませんのでほんの一部だけ書きます
- 365日のデータを月毎に集計し1年12個の変数に圧縮する
- 音声をフーリエ変換後に周波数でヒストグラム化する
- log関数を適用する
- 2乗関数、3乗関数を適用する
目的に対して特徴が際立つように変数を加工する、計算を減らせるよう変数の数を減らす等の工夫する工程を 「特徴化」 と呼びます。
機械学習の種類
「教師無し学習」 と 「教師有り学習」 の2種類があります。
教師無し学習
あるN個のクラスタのデータを含む多数のサンプル郡があったとする
クラスタを形成する集団を自動的に検出し、0~N のインデックスに分類できるモデルを作成する
作成された「モデル」を使用して未知のサンプルXがどのクラスタに所属するか分類する
ただし、クラスタ数Nは任意に指定する必要がある、サンプル郡がどの程度のクラスタに分かれるかを事前に知っている必要がある、又は可能な範囲で総当たりをし適切なクラスタ数を判断する必要がある
後付で人間がクラスタが何者であるかラベル付けを行い、そのモデルを使いクラスタ分類を行うことで結果だけ見れば教師有り学習と同等の振る舞いをする
図は2つのクラスタを持つサンプル
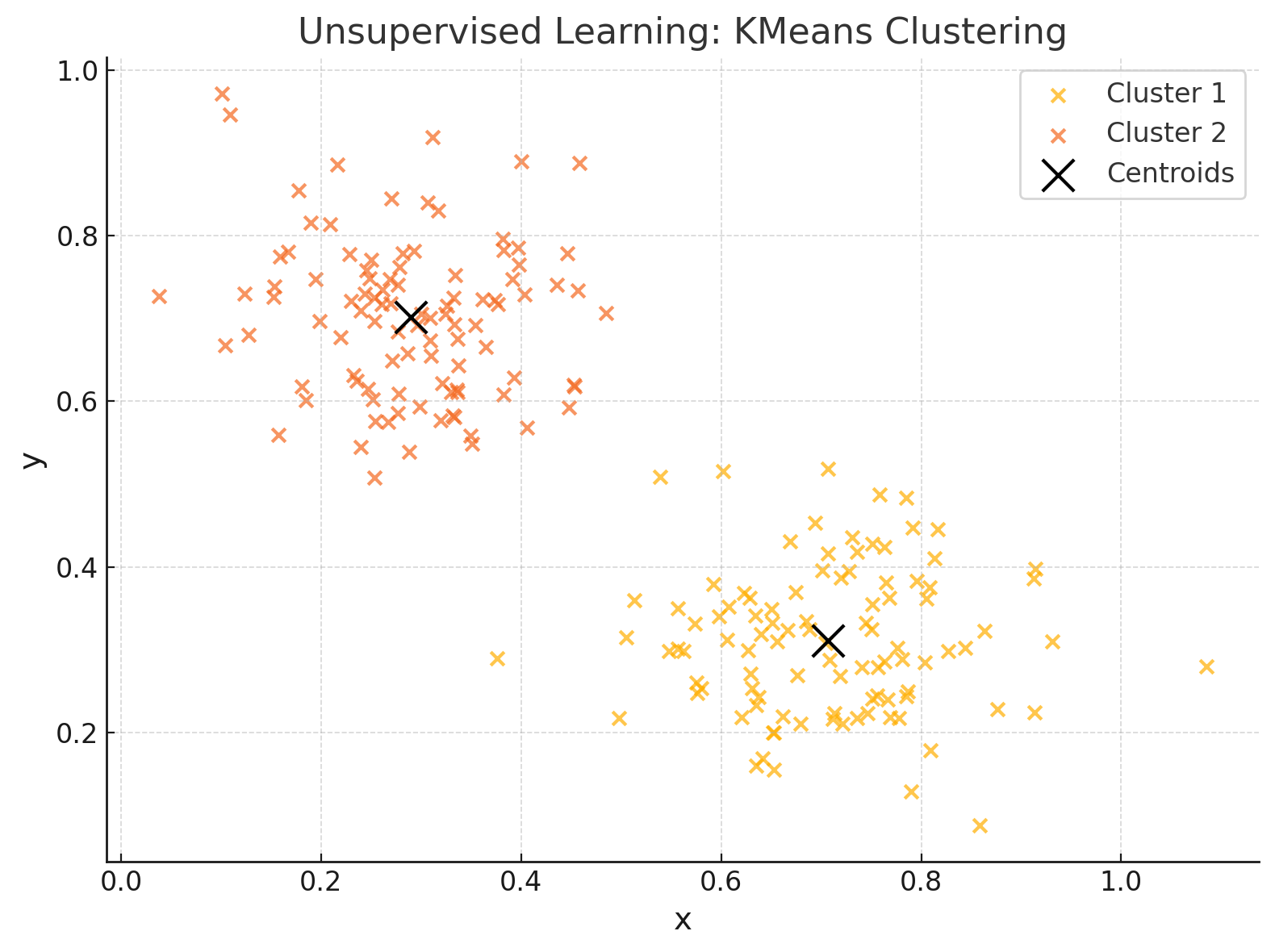
実際の教師無し学習の動作例(KMEANS)
- ランダムに各クラスタの仮の中心値を決定する
- サンプルのクラスタ毎平均値(クラスタ中心)を求める
- 中心値から再度クラスタリングを行う
- 2,3を誤差が少なくなるまで繰り返したら計算終了
ランダムに初期値を決める

再度クラスタリングを行う
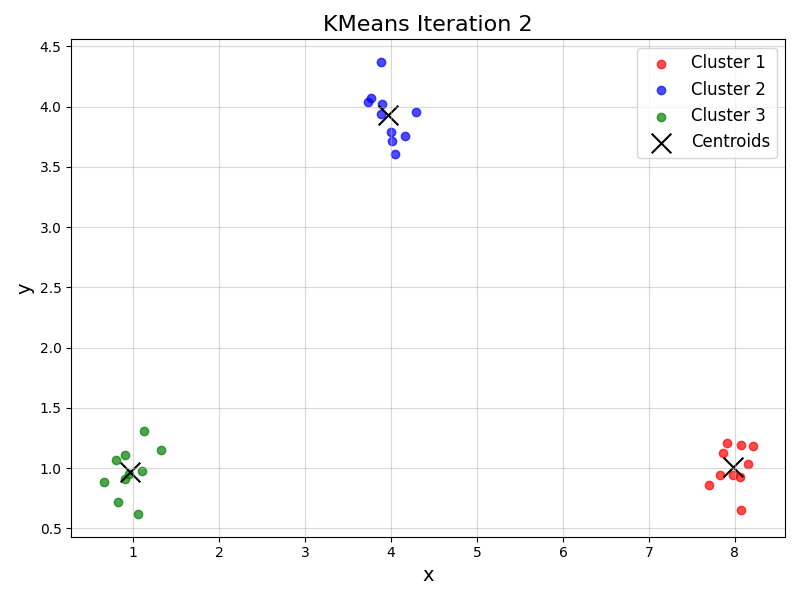
再度クラスタリングを行う、中心値のズレが収束したので終了する

教師有り学習
ある2クラスタのデータを含む多数のサンプルがあったとする
クラスタのどちらかをポジティブラベルと定義しポジティブ、非ポジティブ(ネガティブ)を判断できるモデルを作成する
作成された「モデル」を使用して未知のサンプルXがどのクラスタに所属するか分類する
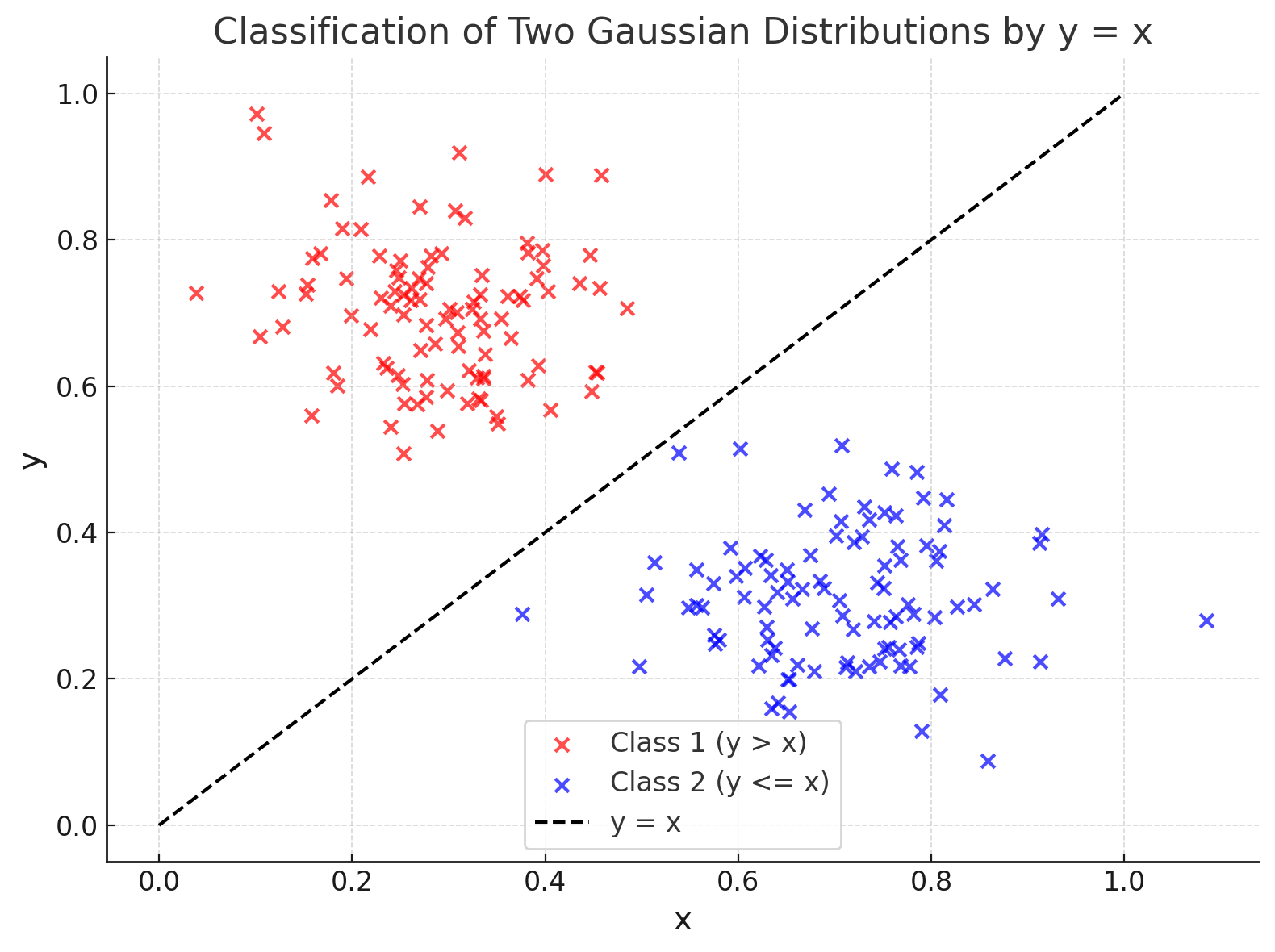
サンプルを2分する決定境界線(決定境界面)を求めてその線(面)の計算式(係数)を「モデル」として出力し機械学習を終了し、新たなサンプルXをそのモデルに適用し分類器として使用します
ロジックによっては2分類だけでなく多値分類にも対応できる、その際はポジティブ、ネガティブではなく0~Nの整数で正解ラベルを定義する
実際の教師有り学習の動作例(SVM、Linear)
- 適当な偏り(重み)を加えた直線(曲線)を引く
- その線の y > x(又はy <= x) のクラスタに正解が含まれている割合を計算する
- 1,2を繰り返し正解が含まれる割合が高いところで計算を終了する
適当な線を引く

分類状況を見て線の係数を変更する

分類状況を見て線の係数を変更する

分類状況を見て線の係数を変更する、収束又は指定のイテレーション回数に到達したので計算終了

以上、機械学習の説明でした。
オマケ:「AI」 と 「機械学習」という言葉の意味
たまに「AI」≒「機械学習」という認識の記事を見ますが異なる言葉だと思っています、著者が思う「AI」と「機械学習」について書きます。
「AI」という言葉は自動的になにかやってくれる物の総称といった感じで時代により指す物が異なっているように感じます、例えば1990年以前であるとか、その時代に工場で流れてくる商品の重量や反射光を解析して不良品を弾く仕組みがあったとして、それはその時代では「AI」と呼ばれていたかもしれませんが、2020年以降にそのような仕組みがあっても「自動化」と呼ばれるだけだと思います
その時代最新の自動化処理が概ね「AI」と呼ばれているかなという認識です、狭い範囲を特定して指し示す単語では無いと思います
「機械学習」という言葉は統計モデルを使用してなにかを分類する行為やそのための集計作業等を「機械学習」と呼んでおり、「AI」より意味を捉えやすい単語だと思います
TODO
機械学習を全く知らない人に機械学習を伝えたくて書いたのですが、読み返すと分かりづらい部分多いので改善していきたいと思います
後、具体的な文章、音声、画像等についての工程もどこかで解説していきたいと思います。
以上です。