医師国家試験解答システム「NMLE‑RTA」
はじめに
私は元医師で、医師国家試験を数年前に受験しました
医師国家試験は9割が受かる試験であり、現役生に至っては95%が合格します
よくそれを引き合いに簡単な試験と勘違いされますが、全医学生が本気で挑んでくるので実はかなりプレッシャーのかかる試験です
あの過酷な試験がどれだけ大変だったかは今でもよく覚えています(医師になってからも国家試験を落ちた夢が出てくるという人がいるくらいです)
だからこそ医師免許を持ちつつ AI エンジニアとして活動する身として 「うるせぇ!医師国家試験をベンチマークにしておもちゃにするんじゃねぇ!」
という思いがあり、医師国家試験を当日最速でAIに解かせるシステム 「NMLE‑RTA」 を作成しました(これ以後はおそらく二番煎じだ)
世界最速解答は受験生本人ですが、外部の人間では「多分これが一番早いと思います」(厳密には私が操作するAIモデルですが)
githubにコードを共有しているので誰でも試すことができます
忙しかったり、当日のエラーで書き捨ての部分もありますが一通り実行できると思います(今後ニーズあればリファクタリング予定)
また今回は医学教育コンテンツを作成している メディックメディア 協力の元、行われました
メディックメディアの該当記事はこちらになります
こちらでは技術的な部分を除いた、より分かりやすい分析を公開しております
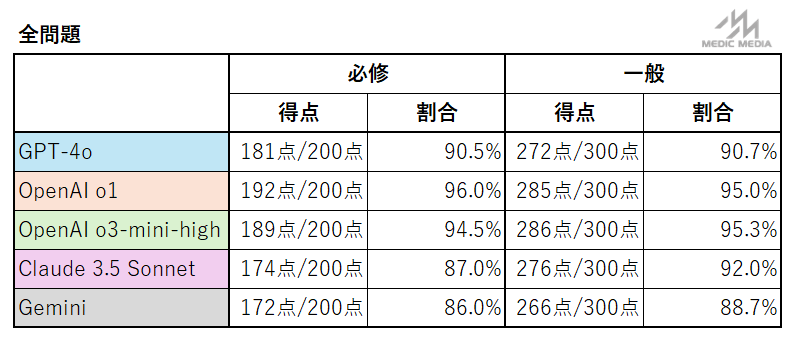
ちなみに o3-mini-high の一般臨床の正答率は95.3%でした!
国試受験生では第7位相当の好成績になります
また医者を辞めてCTOになった私の経歴に興味がある方は下記記事も見ていただけますと
医師国家試験のルール
開催時期
医師国家試験は2月初旬の土日の2日間で行われます(以前は3日間)
第119回は2025年2月8日・2月9日に実施
合格基準
医師国家試験はA〜Fブロックまで別れており、大別すると一般問題(A・C・D・F)と必修問題(B・E)に分けられます
【絶対評価】
ブロックB, Eは必修問題で、1ブロック100点満点の試験ですが合計で160点、つまり絶対的に80%以上でないと不合格になる試験です
【相対評価】
一方でA, C, D, Fについては相対評価です。医師国家試験はざっくりいうと下位1割をふるい落とす試験です。なので毎年ボーダーが変わります。例年は7割前後が多いです
この相対評価、不思議なことが沢山あり、一説には国試多浪で有名なルシファー(東大理三)という人が基準になってるのでは?とまことしやかに囁かれています
禁忌肢
医師国家試験特有のルールとして禁忌肢があります
選択肢の中にドボンが存在していて、いくら他の点数が問題なくても絶対アカン選択肢(たいていは患者を◯す恐れがある)を合計3つ踏むと合格できません
この禁忌肢、医師国家試験の特徴としてよく取り上げられます
しかし禁忌肢が導入されてから本当に禁忌落ちをした受験生はほぼ存在しないと言われています
(私が聞いた話では過去10年で単独禁忌落ちは2人と言われています)
もちろん禁忌肢は非公開、最終的に受験生には合計何個の禁忌肢を踏んだかだけ教えてくれます
今回のシステムについて
概要
「NMLE‑RTA(National Medical License Examination - Real Time Analysis)」は、医師国家試験の問題をPDF形式で入力し、以下の一連の流れで自動解答を生成するシステムです
メインのシステムpromptは以下を使用しております
画像がある場合は問題文とともに画像のデータが渡されます
医師国家試験の問題について回答してください。
以下の形式で出力してください:
ルール:
1. 問題文に「2つ選べ」などの指示がない限り、必ず1つだけ選択してください
2. 複数選択の場合は、選択肢をアルファベット順に並べて出力してください(例:ac, ce)
answer: [選択した回答のアルファベット]
confidence: [0.0-1.0の確信度]
explanation: [回答の理由を簡潔に]
使用モデル
2025-02-08現在、以下のモデルを使用しています
- o1-2024-12-17: 問題解答(Vision含む)
- gpt-4o-2024-08-06: 問題解答(Vision含む)
- o3-mini: 問題解答(Visionなし)
- claude-3-5-sonnet-20241022: 問題解答(Vision含む)
- gemini-2.0-flash: 問題解答(Vision含む)
- DeepSeek-R1: 問題解答(Visionなし)
2025年1月末から2月頭までに出た最新モデルを取り揃えました
2025年1月中旬にこのプロジェクトを開始したので、1月末にたくさんのモデルが出るのは大きな誤算でした
またDeepseekについてはAPIが不安定なため後日結果を公開します
実際のコードと使い方
実際の使い方についてはレポジトリのREADMEに詳しく書いていますが、その内容をかいつまんで説明します
1. PDF からのテキスト抽出(pdf2txt.py)
Azure Document Intelligence を用いて PDF の OCR 処理を行い、可視化用の PDF、抽出テキスト、詳細な OCR 結果(JSON)を生成。例えば、OCR 結果のテキストは以下のような形式で出力されます。
=== Page 1 ===
118B1以下の症例について問1~問3に答えよ。
54歳の男性。発熱と咳を主訴に来院した。
3日前から38℃台の発熱と咳が出現し、市販薬を内服したが改善しないため来院した。
...
2. OCR テキストのクリーニング(cleaning_ocr_txt.py)
OCR の結果に含まれるノイズや誤認識部分を正規表現などで整形。問題文と選択肢を明確に分離するため、各問題毎に「【問題】」および「【選択肢】」を自動挿入します。
ただし自動整形のため、OCRの精度が悪かったり英語が交じると崩れてしまいますので、最終的に人力でこの形式に修正します。
=== 118B1 ===
【問題】
54歳の男性。発熱と咳を主訴に来院した。
3日前から38℃台の発熱と咳が出現し、市販薬を内服したが改善しないため来院した。
【選択肢】
a. 市中肺炎
b. 気管支喘息
c. 急性気管支炎
d. 肺結核
e. 肺癌
3. テキストから JSON への変換(txt2json.py)
整形済みのテキストを解析し、各問題を JSON 形式に変換。以下のような構造データを出力します。
{
"questions": [
{
"id": "118B1",
"case_text": "54歳の男性。発熱と咳を主訴に来院した。\n3日前から38℃台の発熱と咳が出現し...",
"sub_questions": [
{
"number": 1,
"text": "最も考えられる診断は何か。",
"options": [
"市中肺炎",
"気管支喘息",
"急性気管支炎",
"肺結核",
"肺癌"
]
}
],
"has_image": false
}
]
}
4. LLM による問題解答
当初は answer_questions.py を利用していましたが、JSON 出力のフォーマットエラーが頻発したため、よりシンプルな構造出力を実現するために main.py、llm_solver.py、process_llm_output.py による新しい実装に切り替えました
これにより、GPT‑4o、OpenAI o1、o3-mini、Anthropic Claude、DeepSeek、Google Geminiなど、複数のモデルに対して統一したフォーマットの出力を実現しています
5. 結果の集約と CSV 変換
各モデルの解答結果は JSON、CSV、生テキスト形式で保存され、後から解析・検証ができるようになっています。たとえば、json_to_csv_converter.py を実行すると、以下のような CSV ファイルが生成されます。
number,has_image,gpt-4o,gpt-4o-explanation
118B1,False,a,(解説省略)
...
技術的な設計とコードの具体例
API 抽象化と統一インターフェース
各 LLM(GPT‑4o、o1、o3-mini、Claude、DeepSeek、Gemini)の API 呼び出しの違いを吸収するため、llm_solver.py では以下のようにモデルごとの設定を統一しています。
self.models = {
"o1": {
"api_key": os.getenv("OPENAI_API_KEY"),
"model_name": "o1",
"supports_vision": True,
"api_type": "openai",
"parameters": {"response_format": {"type": "json_object"}},
},
"gpt-4o": {
"api_key": os.getenv("OPENAI_API_KEY"),
"model_name": "gpt-4o",
"supports_vision": True,
"api_type": "openai",
"parameters": {"temperature": 0.2, "response_format": {"type": "json_object"}},
},
# ... 他のモデル設定
}
この設定をもとに、setup_client 関数で各 API クライアントを生成し、統一的なインターフェースで呼び出せるようにしています
画像問題の処理
Deepseek-R1とo3-miniは除く残りのモデルは、画像入力にも対応したマルチモーダルモデルです
画像を含む問題の場合、以下の手順で画像を準備します:
- 画像ファイルを
images/ディレクトリに配置 - ファイル名の形式:
- 単一画像:
{問題番号}.jpgまたは{問題番号}.png - 複数画像:
{問題番号}-1.jpg、{問題番号}-2.jpgなど
- 単一画像:
例:
images/118B1.jpg-
images/118B2-1.png、images/118B2-2.png
具体的な使い方
1. 環境構築と API キー設定
プロジェクトルートにある .env.example をもとに、必要な API キー(Azure Document Intelligence、OpenAI、Anthropic、DeepSeek、Gemini)を .env に設定します。
cp .env.example .env
依存パッケージは uv を用いてインストール。
curl -LsSf https://astral.sh/uv/install.sh | sh
uv sync
2. PDF からの OCR 抽出
pdf2txt.py を実行して、data/ に配置した PDF(例:data/118B.pdf)から OCR を実施。
python pdf2txt.py
3. OCR テキストのクリーニングと JSON 変換
cleaning_ocr_txt.py で OCR テキストを整形し、txt2json.py で JSON 形式に変換。
python cleaning_ocr_txt.py output/118B_ocr_text.txt output/118B_cleaned.txt
python txt2json.py output/118B_cleaned.txt output/118B_questions.json
4. AI モデルによる問題解答
新規エントリーポイント main.py を用いて、複数の AI モデルで問題を解答。たとえば、Claude、o1、GPT‑4o を使う場合は以下のように実行。
uv run main.py output/118B_questions.json --models claude o1 gpt-4o
結果は answer/json/ および answer/raw/ に保存され、CSV 変換は次のように行えます。
uv run python json_to_csv_converter.py answer/json/results_YYYYMMDD_HHMMSS_final.json
現状のコードの問題
統一インターフェイスの問題
llm_solver.py で統一的なインターフェイスを構築していますが、いくつか問題があります
統一的なインターフェイスの背後には Deepseek/GeminiがOpenAIのAPIの形式と互換性があることにあります
ただし parameter に関してはリーゾニングモデルや各社モデルで微妙に違いがあり、面倒くさいです(特に最新のモデルの場合、ドキュメントが整備されていないことも)
API動かない問題
2025-02-08現在、Deepseekについては負荷のためAPIが動作しない
それに加えて gemini-flash-2.0 も何故かクオート制限エラーが出る
有料アカウントなのでなるわけがない上に、Quota制限エラーについてはissueが上がっている
こればっかりは本当に勘弁してほしかった
構造化について
当初はこのようにJSON形式で出力をお願いしていました
以下のJSON形式で出力してください:
{
"answer": "選択肢のアルファベット(選択肢の中から)",
"confidence": 0.85,
"explanation": "解答の根拠を簡潔に説明"
}
OpenAIについてはparameterでJSONフォーマットを指定できるものの、他社のモデルでは使えませんでした。そのため出力フォーマットがぐちゃぐちゃでパースに失敗してしまうので、この方法を諦めました
予行演習ではできていましたが、当日半分くらいのモデルを最新にアップデートしたのでそれも影響したように思えます
JSONを諦め、シンプルに
answer: [選択した回答のアルファベット]
confidence: [0.0-1.0の確信度]
explanation: [回答の理由を簡潔に]
構造化したデータを出力するように変更しました
ほかリファクタリングすべき箇所
リアルタイムで問題解いている最中にエラーが頻発してしまったので(概ねアップデートしたモデルに起因)ところどころコードがチグハグです
また互換を謳っているモデルについてはOpenAIのAsyncライブラリの動作が担保されていないので、全て同期・直列処理で動かしています。非常にナイーブな処理になっています
asyncで書き直そうか迷いましたが、一旦動くものを完成させました
今までのベンチマークの問題点
凄い!!!
— 河野健一 Kenichi Kono | 脳外科医 CEO|AI 医療 MBA|脳血管内手術支援AI (@CeoImed) November 8, 2024
「GPT-o1 previewが医師国家試験で98.2%の正答率!」
・ 2024年2月の日本医師国家試験において、OpenAIのo1 previewが最高98.2%の正答率を記録
・ 画像を含む問題や複数の正解がある問題は除外
・ 既存ベンチマークの飽和が進んでいる
・ 合格基準は76.7%
https://t.co/qfFU8tZHk3 pic.twitter.com/kPiPjtdREh
実はここにある 「o1-previewの正答率は98%!」はほぼ嘘 です
というのも画像問題と多肢選択問題を除外しているからです
これがどれくらいのインパクトかと言うと、例えば先程行われた119Cブロックでは75問中20問は画像もしくは多肢選択式であり、98%の正答率を叩き出したというAIは実質7割程度の問題しか解いていないことになります
医師国家試験を受験した身としては、画像問題がない国試なんて簡単に決まっているだろと思います
こうした既存のベンチマークはデータセット自体の出自もかなり怪しいものが多く、そのため私は許可いただいたうえでHuggingfaceに医師国家試験データセットも公開しております
最後に
医師国家試験の現場を体験した者として、国家試験の厳しさはよく分かっています
「医師国家試験をAIに解かせる」というタスクは一見すると最新技術のアピールに見えるかもしれません。しかし実際には「国試をおもちゃにするんじゃねぇ!」という強い怒りと、本物の試験に対する敬意が込められています
私自身はAI に国家試験を解かせるのはナンセンスだと思っていて、そのため自分でさっさとやって二番煎じを封じたいという思いもありました
今回おそらく世界最速でデータを公開できたと思います
今後詳細にこれらの結果を分析していきますので続報も楽しみにしていただければと思います
いくつか面白い知見も得られましたので、公開できえばと思います
読んでいただきありがとうございました。