はじめに
この論文は、モデルが公開され、幅広く使われている VGG16 の論文。
よく、Fine tuning されて使われているモデルです。(参考)
以下、機械学習を絶賛勉強中なので、正直よく分からないで、本記事を書いています。訂正、指摘、疑問、質問等あれば、どしどしお願いします。
3行でまとめると
- 畳み込みネットワークを、16~19層にすることで、劇的に認識精度が上がった
- 畳み込みフィルタを先行論文より小さい、3x3 とした。これにより、深くてもパラメータ数の増加を抑え、より良い精度が得られた
- 入力時のクリッピングを複数のスケールにすることで、精度向上が見られた。
Abstract
- 本研究では、畳み込みネットワークの深さが大規模画像認識設定の精度に及ぼす影響を調べる
- 主な評価内容は、非常に小さい(3×3)畳み込みフィルタを備えたアーキテクチャを使用して深さの深いネットワークを評価すること
- 16-19層にする事で、劇的に改善した
- ImageNet Challenge 2014で1位と2位になった
- また他のデータセットでも有効である事を示した
- 2つの最も優れたConvNetモデルを公開した
2 CONVNET CONFIGURATIONS
2.1 ARCHITECTURE
- トレーニング中に、ConvNetsへの入力は固定サイズの224×224のRGB画像
- 前処理は、トレーニングセットで計算された平均RGB値を各ピクセルから減算する
- 3×3 の受容野を有する畳み込み層スタックを用いる
- 一部の構成では、1×1畳み込みフィルタも使用する。これは、入力チャネルの線形変換(非線形性の後に実施)と見ることができる
- 畳み込みStrideは1ピクセルに固定されている
- 畳み込み層入力の空間パディングは、畳み込み後に空間解像度が保存されるようなものである必要が有り、すなわち、3×3畳み込み層では1ピクセルである
- 5つのmax-poolingレイヤーがある
- 畳み込みレイヤのスタックの後には、3つの完全接続(Fully Connected)レイヤが続く
- 最後の層はsoft-max層
- 活性化関数はReLUを用いる
表1:ConvNetの設定
A〜Eでネットワークが深くなる
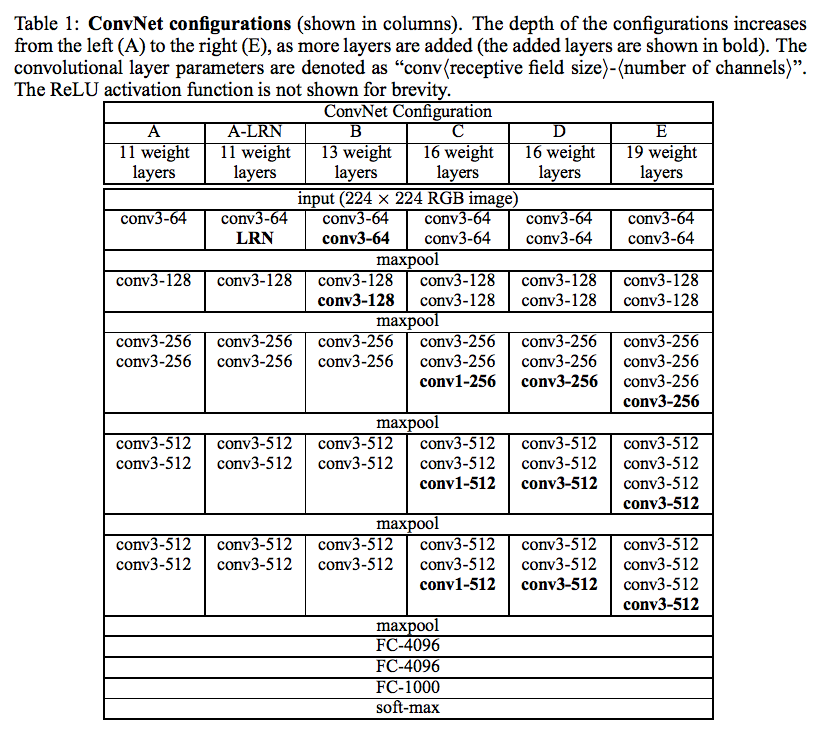
2.2 CONFIGURATIONS
2.3 DISCUSSION
- 先行研究では、7x7 だが、本研究では 3x3を用いる
- 7x7 の1レイヤーよりも、3x3の3レイヤーの方が良いと考える。それは、
- 2回、活性化関数を通るので、その分、判断する機会が増える
- 3x3にすると全体のパラメータ数が少なくてすむ
3 CLASSIFICATION FRAMEWORK
3.1 TRAINING
- トレーニングの手法・手順を述べる
- 主なパラメータは以下の通り
- Momentunのあるミニバッチ勾配降下法
- 多項ロジスティック回帰
- バッチサイズ: 256
- momentum: 0.9
- 正規化
- トレーニングはweight decay 重み減衰によって正則化
- L2 penarty(λ) は$5 \times 10^{-4}$
- さらに、ドロップアウトは、0.5で、2つのfully-connected layersの後に置く
- トレーニングはweight decay 重み減衰によって正則化
- Learning rate は、$10^{−2}$で、validation set accuracy の向上が止まったら、1/10する。合計3回、1/10 して、かつ 370K iterations (74 epochs)より多かったら、終了
3.1 TRAINING: 初期化
- 初期化は重要
- 初期設定を訓練するのに一番浅い構成A(表1)のトレーニングを開始
- この構成Aは、$10^{-2}$の分散を持つ正規分布でランダムに初期化
- より深い構成は、最初の4つの畳み込みレイヤとFully connectedレイヤは構成Aのもので初期化、他は正規分布でランダム
- 初期設定を訓練するのに一番浅い構成A(表1)のトレーニングを開始
3.1 TRAINING: 画像スケーリング
-
ニューラルネットの入力は、224x224 だが元画像は違う
- サイズ $S$ にリサイズ -> 224x224 でランダムな位置でCrop
- サイズ $S$ は 224px より大きい

-
2の方法でトレーニングを行った
- サイズ $S$ を 256px または、384px に固定する
- サイズ $S$ を定義された範囲で、ランダムにする
- $[256;512]$ は、256〜512の範囲でランダム
-
さらに、データを増やすために、ランダムなRGBカラーシフトと、ランダムな横方向の画像反転をしている(Data augmentation)
3.2 TESTING
- テスト時は、画像と訓練済みConvNetが与えられる
- 以下で、テスト時の手順を述べる
- 画像の短辺は、サイズ $Q$ にスケーリングされる
- このサイズ $Q$ は、サイズ $S$とは異なる場合がある
- 完全接続(Fully Connected)レイヤは、Convolution レイヤに変換する(これは、Fully-convolutional networkと呼ばれるネットワーク)
- 最初の1つの Fully Connectedレイヤーは、7×7 の Convolution レイヤに変換
- 最後の2つの Fully Connectedレイヤーは、1x1 の Convolution レイヤに変換
- 上記の結果として、Class score map が得られる
- これは、分類クラス数・解像度・イメージサイズと一致したもの
- 最後に、平均プーリング演算(sum-pooled)して、分類クラス数と一致した固定長のベクトルを得る
- また、ランダムな横方向の画像反転して、データを増やす。スコアは平均を取る
- 上記の時、Fully-convolutional network のため、画像全体に対して、Netoworkを適用できる
- Training時のようなCropは不要となる
3.3 IMPLEMENTATION DETAILS
- C++ Caffe toolboxを使った
- 4つの NVIDIA Titan Black GPU を使い、並列化
- 1台の時に比べ、3.75 倍の性能を得た
- 1つのネットワークで、2〜3週間のトレーニング時間が必要だった
4 CLASSIFICATION EXPERIMENTS
- Datasetは、ILSVRC-2012
- 1000クラス
- 以下の通りデータを分割
- トレーニング:130万画像
- バリデーション:5万画像
- テスト:10万画像
4.1 SINGLE SCALE EVALUATION
- まず、$Q = S$ として評価した
- 以下の表の、train($S$)が、256, 384 のもの
- 次に、Trainingに、Multi scaleでトレーニングしたものを評価
- 以下の表の、train($S$)が、[256; 512] のもの
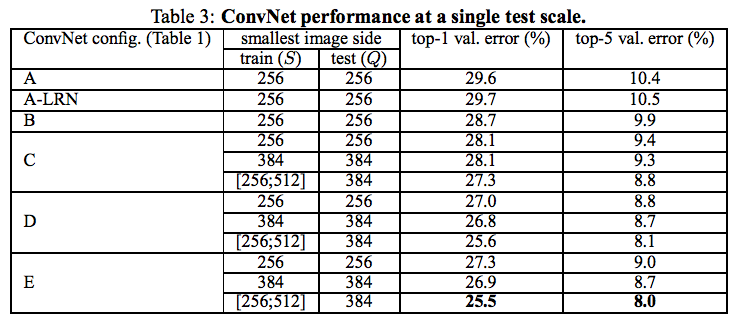
- 結果、[256; 512] のものが、顕著に結果
4.2 MULTI-SCALE EVALUATION
- サイズ $S$ を サイズ $S$ を中心に、$S - 32$、$S$、$S + 32$と、複数のサイズにしてテスト
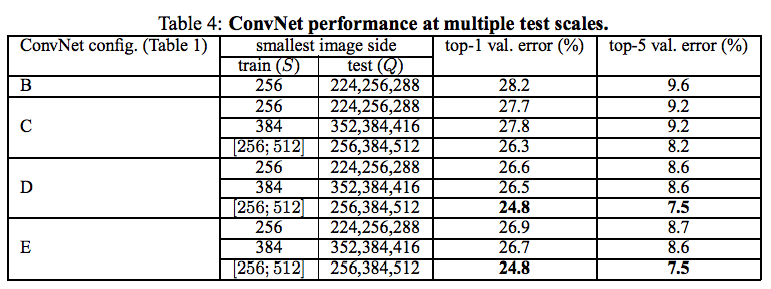
- こちらも、結果、[256; 512] のものが、顕著に結果
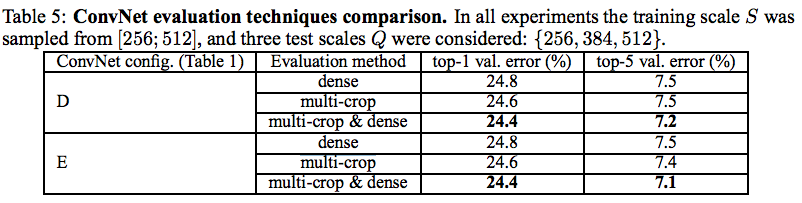
4.3 MULTI-CROP EVALUATION
- Multi-crop と、dense evaluation で評価
- Multi-crop は、1つの入力画像に対して複数のCropをする手法(Window sliding)
- dense evaluation は良くわからない。。(誰か教えて。。)
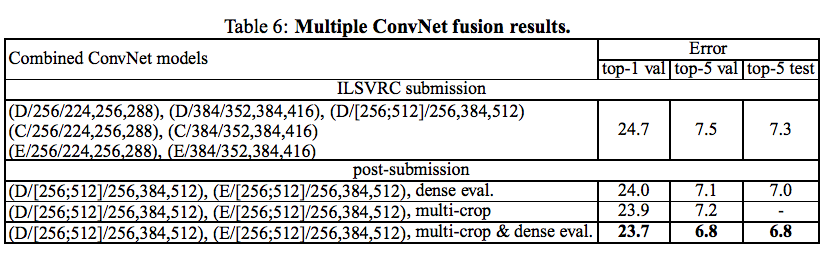
4.4 CONVNET FUSION
- 複数のモデルの出力を平均した結果
4.5 COMPARISON WITH THE STATE OF THE ART
- 他手法との比較
5 CONCLUSION
- 本研究では、大規模な画像分類のために非常に深い畳み込みネットワーク(最大19重層)を評価した
- 表現の深さは分類精度にとって有益であり、ImageNetチャレンジデータセットに対する最新の性能は、従来のConvNetアーキテクチャを用いて達成できることが示された