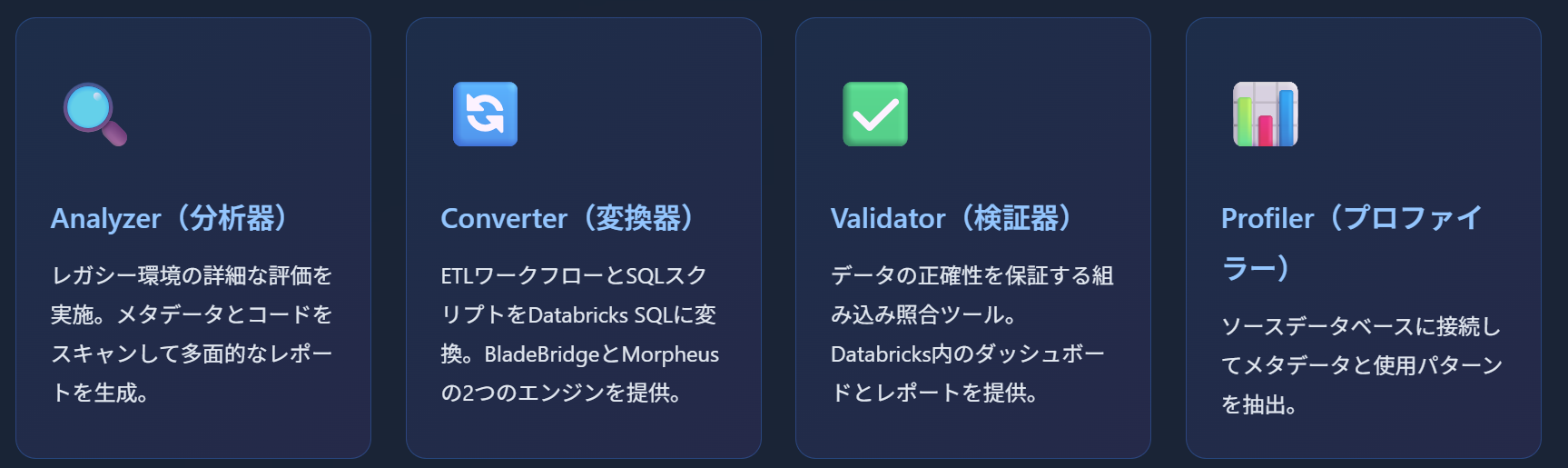
Databricks への移行を加速する
📘 Lakebridgeとは?
移行プロセスの自動化

Lakebridgeは、Databricks Labsが開発した無料・オープンソースの移行ツールキットです。
レガシーデータウェアハウスやETLシステムからDatabricks SQLへのシームレスな移行を支援します。
💡 主な特徴: 移行タスクの最大80%を自動化し、プロジェクトのタイムラインを最大2倍高速化!
データソース: Databricks公式ブログ
🧩 主要コンポーネント
💻 Windows 11以上へのインストール
前提条件
- Windows 10以上(Chocolatey 使用の場合)
- Python 3.10~3.13。databricks-connectが必須。3.14は2025/10/22時点で非対応な事を個人的に動作確認
- Java 11以上
- Databricks CLI(v0.200以降)
インストール手順
ステップ1: Chocolatey のインストール
ChocolateyはWindows向けのパッケージマネージャーです。ソフトウェアのインストールやアップデートをコマンド一発で簡単にできる便利なツールです。
💡 ✅ インストール手順
🔹 ステップ1:PowerShellを「管理者として」起動
- スタートメニューを開きます。
- 「PowerShell」と検索します。
- 表示された「Windows PowerShell」を右クリック → 「管理者として実行」を選びます。
💡※必ず「管理者」として実行してください!
🔹 ステップ2:Chocolateyのインストールコマンドを実行
以下のコードをそのままコピーして貼り付けて、Enterキーを押してください:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
Chocolateyがインストール済みの場合はアップデートを実施
choco upgrade all
🔹 ステップ3:インストールが完了するのを待つ
数十秒〜数分でインストールが完了します。
🔹 ステップ4:インストール確認
PowerShellで以下を入力して、Chocolateyのバージョンが表示されれば成功です:
choco -v
🔧 Chocolateyコマンドが認識されない場合の対処法
インストール後もchocoコマンドが認識されない場合は、以下のパスがシステムのPATH環境変数に含まれているか確認してください:
C:\ProgramData\chocolatey\bin
🔧 手動でPATHに追加する手順:
-
システムのプロパティを開く
- Windowsキー + Rを押して「ファイル名を指定して実行」を開く
-
sysdm.cplと入力してEnterキーを押す
-
環境変数の設定画面を開く
- 「詳細設定」タブをクリック
- 「環境変数」ボタンをクリック
-
システム環境変数のPathを編集
- 「システム環境変数」の一覧で「Path」を選択
- 「編集」ボタンをクリック
-
新しいパスを追加
- 「新規」ボタンをクリック
-
C:\ProgramData\chocolatey\binを入力
-
設定を保存
- すべてのウィンドウで「OK」をクリック
- PowerShellを完全に再起動する
💡 PowerShellでの一時的な対処法:
PowerShellを再起動できない場合は、以下のコマンドで環境変数を再読み込みできます:
$env:Path = [System.Environment]::GetEnvironmentVariable("Path","Machine") + ";" + [System.Environment]::GetEnvironmentVariable("Path","User")
ステップ2: Python環境の準備
# Pythonインストール
choco install python
PowerShellのコンソールを管理者で開きなおす
pip install --upgrade pip
# Python 3.10以上がインストールされていることを確認
python --version
セキュリティに関するエラーが出たこちらを参照
https://qiita.com/sophytoeat/items/7219df8149c96f0e40d9
ステップ3: Java 11以上のインストール確認
# Java 11以上がインストールされていることを確認
java -version
Javaがインストールされていない場合、Chocolateyでインストール可能
choco install openjdk17
Javaが古い場合、Chocolateyでアップデート可能
choco upgrade openjdk17
ステップ4: Databricks CLI の Chocolatey によるインストール
Chocolateyを使用することで、Databricks CLIの最新版(v0.200以降)を簡単にインストールできます。
# Databricks CLIの最新版をChocolateyでインストール
choco install databricks-cli
# インストール後、バージョンを確認(v0.200以降であることを確認)
databricks --version
Databricks CLIが古い場合はChocolateyでアップデート
choco upgrade databricks-cli
パスが通っていない場合は、PowerShellを再起動するか以下を実行
$env:Path = [System.Environment]::GetEnvironmentVariable("Path","Machine") + ";" + [System.Environment]::GetEnvironmentVariable("Path","User")
💡 Chocolateyの利点:
- 常に最新の安定版がインストールされる
- 依存関係の自動解決
- 簡単なアップデート管理(
choco upgrade databricks-cli)- アンインストールも簡単(
choco uninstall databricks-cli)- 他の開発ツールも同じ方法で管理可能
🔧 Databricks CLIコマンドが認識されない場合の対処法
Databricks CLIをインストール後もdatabricksコマンドが認識されない場合は、以下のパスの確認が必要です:
# Chocolateyでインストールした場合
C:\ProgramData\chocolatey\bin
# または
C:\Users\[ユーザー名]\AppData\Local\databricks-cli\bin
🔧 実際のインストールパスを確認する方法:
# Chocolateyで管理されているパッケージの場所を確認
choco list databricks-cli
# または、Windowsのwhere コマンドでパスを検索
where /r C:\ databricks.exe
見つかったパスを前述の手順でPATH環境変数に追加してください。
🔧 Databricks CLIの実行権限エラーが発生する場合の対処法
Chocolateyでインストール直後、C:\ProgramData\chocolatey\bin\databricks.exeの実行権限が適切に設定されていない場合があります。
⚠️ 症状:
'databricks' は、内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチ ファイルとして認識されていません。Access is deniedエラーが表示される- ファイルは存在するがコマンドが実行できない
🔧 解決方法1:PowerShellで実行権限を付与
# Databricks CLIの実行ファイルに実行権限を付与
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
# ファイルの属性を確認
Get-ItemProperty "C:\ProgramData\chocolatey\bin\databricks.exe" | Select-Object Name, Attributes
# 実行権限を明示的に設定
icacls "C:\ProgramData\chocolatey\bin\databricks.exe" /grant Everyone:F
# 実行可能かテスト
databricks --version
🔧 解決方法2:Windowsエクスプローラーでの権限設定
-
ファイルの場所を開く
- Windowsエクスプローラーで
C:\ProgramData\chocolatey\binを開く -
databricks.exeファイルを見つける
- Windowsエクスプローラーで
-
プロパティを開く
-
databricks.exeを右クリック - 「プロパティ」を選択
-
-
セキュリティタブで権限を設定
- 「セキュリティ」タブをクリック
- 「Users」グループを選択
- 「編集」ボタンをクリック
-
実行権限を付与
- 「Users」を選択した状態で権限一覧を確認
- 「読み取りと実行」にチェックが入っていることを確認
- 入っていない場合は「許可」欄にチェックを入れる
- 「OK」をクリックして保存
ステップ5: Databricks CLIの構成
Databricks CLI v0.200以降では認証方法が変更されています。以下の手順で設定を行います。
💡 重要: v0.257.0では従来の
databricks configureコマンドが応答しない場合があります。新しい認証方法を使用してください。
💡 重要: 以下の作業からはWindowsPCの管理者IDではなく普段使っているIDで実施してください。
🔹 方法:OAuth認証を使用(推奨)
# OAuth認証でログイン(ブラウザが自動で開きます)
databricks auth login
# プロンプトに従ってDatabricksホストを入力
# 例: https://[your-workspace].cloud.databricks.com
# 設定の確認
databricks auth profiles
ステップ6: Lakebridgeのインストール
# Databricks CLIを使用してLakebridgeをインストール
databricks labs install lakebridge
番外編: Lakebridgeのアップデート
# Databricks CLIを使用してLakebridgeをアップデート
databricks labs upgrade lakebridge
インストールやアップデートの確認
databricks labs list
⚠️ Windows固有の注意点:
- PowerShellを管理者権限で実行することを推奨
- ファイルパスにスペースが含まれる場合は引用符で囲む
- エンコーディング問題を避けるため、ファイルはUTF-8で保存
- ウイルス対策ソフトがインストールをブロックする場合は、一時的に除外設定を追加
- 環境変数の変更後は必ずPowerShellを再起動する
🎯 完全なコマンドリスト
⚠️ フォルダ名やファイル名に全角文字が含まれている場合、システムエラーが発生することがあります。さらに、表示されるエラーメッセージからは、その原因が文字コードに関連していることを特定することが困難な場合が多く、問題の解決に時間を要することがあります。
| コマンド名 | 説明 | ヘルプ表示 |
|---|---|---|
analyze |
レガシーデータウェアハウス環境の詳細評価 | databricks labs lakebridge analyze --help |
install-transpile |
トランスパイルコンポーネントのインストールと設定 | databricks labs lakebridge install-transpile --help |
transpile |
SQLおよびETLコードのDatabricks互換形式への変換。事前にinstall-transpileの実行が必要 | databricks labs lakebridge transpile --help |
reconcile |
データの正確性と整合性の検証 | databricks labs lakebridge reconcile --help |
aggregates-reconcile |
集計レベルのデータ照合 | databricks labs lakebridge aggregates-reconcile --help |
configure-reconcile |
照合インフラストラクチャの設定 | databricks labs lakebridge configure-reconcile --help |
configure-database-profiler |
データベースプロファイリング機能の設定 | databricks labs lakebridge configure-database-profiler --help |
💻 設定ファイル: config.yml
Lakebridge の設定を定義するファイルです。install-transpileコマンドで自動生成されます。
| 設定項目 (Setting Item) | 説明 (Description) | デフォルト値/例 (Default Value/Example) |
|---|---|---|
catalog_name |
Databricksのデフォルトカタログ名 | remorph |
schema_name |
Databricksのデフォルトスキーマ名 | transpiler |
source_dialect |
移行元のSQL方言(synapse, oracle, teradata等) | synapse |
error_file_path |
エラーログの出力先パス | C:\Users\username\errors.log |
output_folder |
変換後ファイルの出力先ディレクトリ | C:\Users\username\transpiled |
skip_validation |
変換後の構文検証をスキップするかどうか |
true / false
|
transpiler_config_path |
トランスパイラー設定ファイルのパス | C:\Users\username\.databricks\labs\remorph-transpilers\bladebridge\lib\config.yml |
transpiler_options |
トランスパイラーの追加オプション | overrides-file: null |
version |
設定ファイルのバージョン | 3 |
💡 設定例:
catalog_name: remorph
error_file_path: C:\Users\hogehoge\errors.log
output_folder: C:\Users\hogehoge\transpiled
schema_name: transpiler
skip_validation: true
source_dialect: synapse
transpiler_config_path: C:\Users\hogehoge\.databricks\labs\remorph-transpilers\bladebridge\lib\config.yml
transpiler_options:
overrides-file: null
version: 3
📋 各コマンドの詳細解説
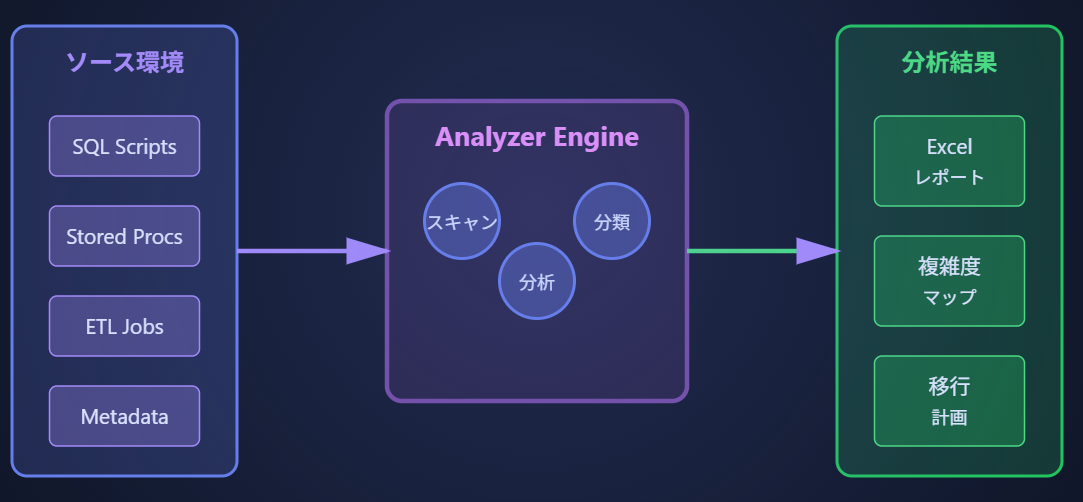
analyze
レガシー環境を包括的に分析し、移行計画の基礎となる詳細レポートを生成。
主な機能:
- メタデータとレガシーコードのスキャン
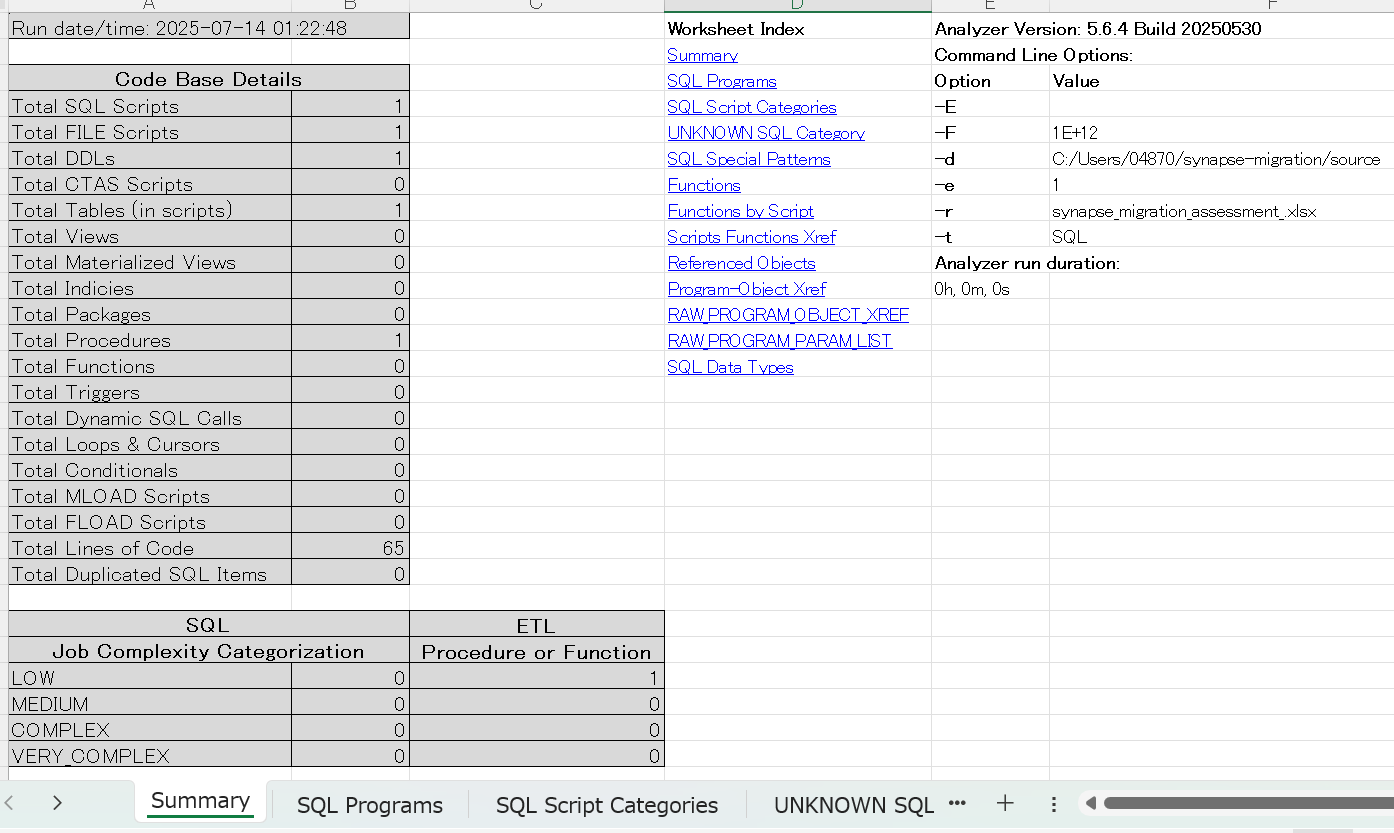
- マルチタブ形式のExcelレポート生成
- ワークロードの複雑度分類(低・中・複雑・非常に複雑)
- 移行対象オブジェクトのインベントリ作成
databricks labs lakebridge analyze ^
--source-directory ./synapse-migration/source ^
--source-tech "Synapse" ^
--debug ^
--report-file "synapse_migration_assessment_.xlsx"
install-transpile
トランスパイラーコンポーネントのインストールと設定を行います。
主な機能:
- トランスパイラー設定のインストール
- config.yml(バージョン3)の管理
- 既存設定からの自動移行
- アーティファクトの配置
databricks labs lakebridge install-transpile ^
--artifact ./transpiler-artifact.jar
transpile
レガシーSQLとETLコードをDatabricks SQL互換形式に自動変換します。
主な機能:
- BladeBridgeとMorpheusトランスパイラーエンジン
- ストアドプロシージャの変換
- エラーハイライトと互換性警告
- FIXMEコメントの自動挿入
databricks labs lakebridge transpile ^
--input-source ./synapse-scripts ^
--output-folder ./databricks-scripts ^
--source-dialect "Synapse" ^
--catalog-name "main" ^
--schema-name "default" ^
--skip-validation "false"
サポートされるソースプラットフォーム: Synapse・Oracle・Teradata・Snowflake・Netezza・SQL Server 詳細
reconcile
移行したデータの正確性と完全性を自動的に検証します。
主な機能:
- レガシーシステムとDatabricks間のデータ比較
- スキーマ、カラム、行レベルの検証
- 完全一致、集計、しきい値ベースのチェック
- 不一致レポートの自動生成
databricks labs lakebridge reconcile
サポートされるソース: Snowflake・Oracle・Databricks
aggregates-reconcile
集計メトリクスレベルでの高速なデータ照合を実行します。
主な機能:
- サマリーレベルのデータ検証
- 集計関数の結果比較
- パフォーマンス最適化された照合
- 大規模データセット対応
databricks labs lakebridge aggregates-reconcile
💡 ヒント: 大規模なデータセットの場合、まず集計レベルの照合を実行してから、必要に応じて詳細な行レベルの照合を行うことを推奨します。
configure-reconcile
照合処理に必要なインフラストラクチャと設定を自動構成します。
主な機能:
- 照合ジョブのデプロイ
- 照合テーブルの自動設定
- モニタリングダッシュボードの設定
- 設定ファイルの管理
databricks labs lakebridge configure-reconcile
configure-database-profiler
ソースデータベースのプロファイリング機能を設定します。
主な機能:
- データベース接続設定
- メタデータ抽出の構成
- 使用パターンの分析設定
- プロファイリングスケジュール設定
databricks labs lakebridge configure-database-profiler
⚠️ 重要な注意事項とサポート体制
⚠️ Databricks Labsプロジェクトについて:
- 探索目的でのみ提供(Exploration purposes only)
- 正式なSLA(サービスレベル契約)なし
- コミュニティサポートのみ(GitHub Issues経由)
- 本番環境での使用は自己責任
技術的制限事項
- 手動コードエクスポート: 分析のためのコードの手動エクスポートが必要
- ルールベースの変換: 事前定義されたルールを使用、複雑なパターンには手動介入が必要
- 値レベル検証の制限: スキーマ、カラム、行レベルの検証に焦点
- 設定の複雑性: 効果的な使用には深い設定知識が必要
🎯 まとめ
このガイドでは、Databricks Lakebridgeの7つの主要コマンドの正確な使用方法を解説しました。
各コマンドはdatabricks labs lakebridge [command] --help形式でヘルプを表示できます。
📚 参考リソース:
Lakebridgeは移行タスクの最大80%を自動化し、プロジェクトのタイムラインを最大2倍高速化できる強力なツールセットです。適切な技術的専門知識と慎重な計画により、効果的な移行を実現できます。
🔬 各コマンドの詳細実行例とアーキテクチャ
グローバルフラグ
| グローバルフラグ | 説明 |
|---|---|
-h, --help
|
helpを表示 |
--debug |
デバッグログを有効にします。 |
-o, --output
|
出力形式を指定します(text または json、デフォルトはtext)。 |
-p, --profile
|
使用するDatabricks CLIプロファイルを指定します(デフォルトは~/.databrickscfgのプロファイル)。 |
-t, --target
|
バンドルターゲットを指定します(適用可能な場合)。 |
データソースの種類
| データソースの種類 |
--source-tech での指定形式 |
|---|---|
| ABInitio | ABInitio |
| Informatica Cloud | Informatica Cloud |
| SAS | SAS |
| ADF | ADF |
| MS SQL Server |
"MS SQL Server"(引用符必須) |
| Snowflake | Snowflake |
| Alteryx | Alteryx |
| Netezza | Netezza |
| SPSS | SPSS |
| Athena | Athena |
| Oozie | Oozie |
| SQOOP | SQOOP |
| BigQuery | BigQuery |
| Oracle | Oracle |
| SSIS | SSIS |
| Cloudera (Impala) |
"Cloudera (Impala)"(引用符必須) |
| Oracle Data Integrator |
"Oracle Data Integrator"(引用符必須) |
| SSRS | SSRS |
| Datastage | Datastage |
| PentahoDI | PentahoDI |
| Synapse | analyzeコマンド時は"Synapse"で、transpileコマンド時は"synapse" |
| Greenplum | Greenplum |
| PIG | PIG |
| Talend | Talend |
| Hive | Hive |
| Presto | Presto |
| Teradata | Teradata |
| IBM DB2 |
"IBM DB2"(引用符必須) |
| PySpark | PySpark |
| Vertica | Vertica |
| Informatica - Big Data Edition |
"Informatica - Big Data Edition"(引用符必須) |
| Redshift | Redshift |
| Informatica - PC |
"Informatica - PC"(引用符必須) |
| SAP HANA (CalcViews) |
"SAP HANA (CalcViews)"(引用符必須) |
📊 analyze コマンドの完全ガイド
Analyzeコマンドのアーキテクチャ
フラグ
| フラグ | 説明 |
|---|---|
--report-file |
生成されるExcelレポートファイル名を指定します(.xlsx拡張子が必要)。 |
--source-directory |
解析対象のSQLスクリプトやETLジョブの定義ファイルが含まれるディレクトリを指定します。 |
-o, --source-techt
|
解析対象のソース技術(例:sql-server)を指定します。 |
実際のサンプルデータを使った実行例
# プロジェクトディレクトリ構造の準備
mkdir -p ./synapse-migration/source/{stored_procedures,views,tables,etl_jobs}
# サンプルストアドプロシージャの配置
# ./synapse-migration/source/stored_procedures/sp_update_sales.sql
# ./synapse-migration/source/stored_procedures/sp_calculate_inventory.sql
# ./synapse-migration/source/views/vw_customer_summary.sql
# ./synapse-migration/source/tables/create_fact_sales.sql
# Analyzeコマンドの実行
databricks labs lakebridge analyze ^
--source-directory ./synapse-migration/source ^
--source-tech "Synapse" ^
--debug ^
--report-file "synapse_migration_assessment_.xlsx"
# 実行結果の例:
# レポート生成: synapse_migration_assessment_20241115.xlsx
Excelの例
まずはExcelをClaudeに要約を頼むと時短で最高
💡 分析のベストプラクティス:
依存関係の分析を含めることで、移行順序の最適化が可能になります。複雑度しきい値を適切に設定することで、段階的な移行計画を立てやすくなります。
🛠️ install-transpile コマンドの完全ガイド
Install-Transpileコマンドのアーキテクチャ(推測)
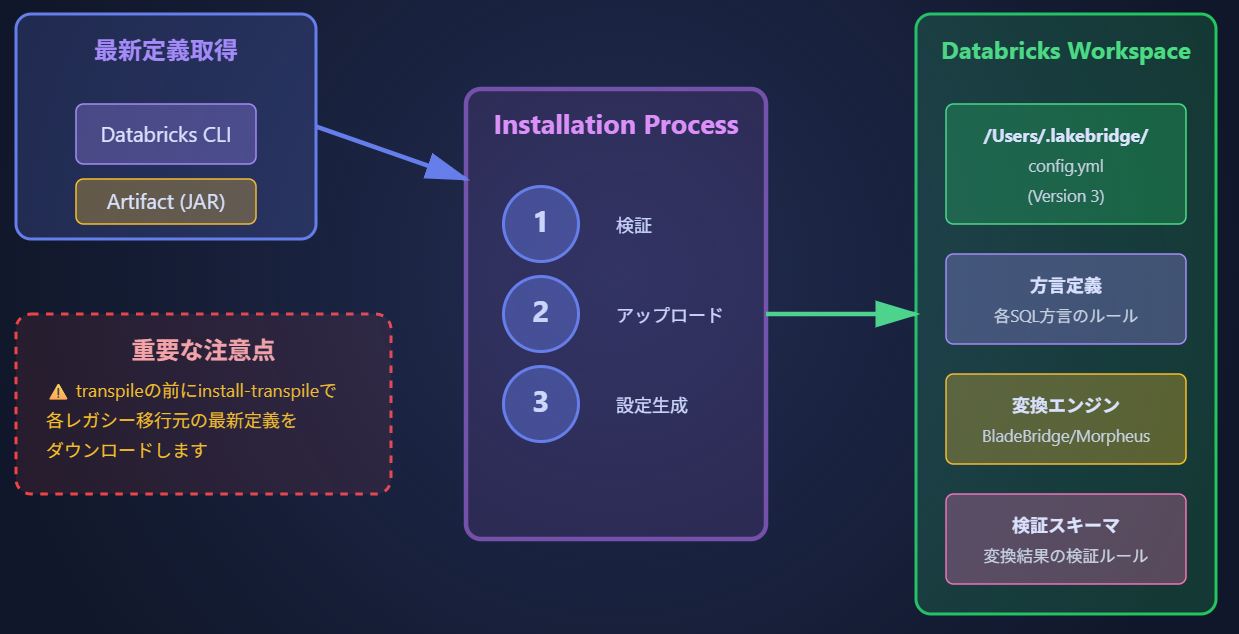
⚠️ 必須の前提条件:
transpileコマンドを使用する前に、必ずinstall-transpileコマンドを実行してトランスパイラーコンポーネントをインストールする必要があります。これを行わないと、「supported dialects: )」のようなエラーが発生し、SQL方言が認識されません。
⚠️ 注意:
install-transpileの実行はセキュリティソフトウェアの干渉でエラーが発生する事があります。
原因:Windows Defender やその他のアンチウイルスソフトウェアが、Databricks Lakebridge のインストールプロセスを潜在的な脅威と誤認し、ファイルの作成や実行をブロックしている可能性があります。
解決策:除外設定を追加する: C:\Users\ユーザー名.databricks\ ディレクトリ全体をアンチウイルスソフトウェアのスキャン対象から除外する設定を追加することを検討してください。
主な機能と役割
install-transpileコマンドは、Lakebridgeのトランスパイル機能を使用するために必要な基盤を構築します。このコマンドは、新しいプリンターを使用する前にドライバーをインストールするのと同じように、SQL変換に必要なすべてのコンポーネントをワークスペースに配置します。
- トランスパイラーエンジンのインストール: BladeBridgeとMorpheusエンジンの設定
- SQL方言定義の配置: MS SQL Server、Oracle、Synapse等の文法ルール
- 変換ルールセットの設定: 各方言からDatabricks SQLへの変換規則
- config.yml (Version 3) の生成: ワークスペース固有の設定ファイル
- 検証スキーマの導入: 変換結果の正確性を確認するためのルール
フラグ
| フラグ | 型 | 説明 | 使用例 |
|---|---|---|---|
--artifact |
string | トランスパイラーアーティファクト(JARファイル)へのローカルパスを指定します。このオプションは省略可能で、指定しない場合はデフォルトのアーティファクトが使用されます。カスタムの変換ルールや特定バージョンのエンジンを使用したい場合に指定します。 | --artifact ./custom-transpiler-v2.1.jar |
インストールプロセスの詳細
# 最もシンプルな実行方法(推奨)
databricks labs lakebridge install-transpile --debug
# 実行結果の例:
Do you want to override the existing installation? (default: no): yes
Select the source dialect:
[0] Set it later
[1] datastage
[2] informatica (desktop edition)
[3] informatica cloud
[4] mssql
[5] netezza
[6] oracle
[7] snowflake
[8] synapse
[9] teradata
[10] tsql
Enter a number between 0 and 10: [定義の番号を選択]
Specify the file to use for overrides - press <enter> for none (default: <none>):
Enter input SQL path (directory/file) (default: Set it later):
Enter output directory (default: transpiled):
Enter error file path (default: errors.log):
Would you like to validate the syntax and semantics of the transpiled queries? (default: no):
Open config file https://adb-x~~~~/config.yml in the browser? (default: no):
1. 既存インストールの上書き確認
Do you want to override the existing installation? (default: no):
解説
この質問は、LakeBridgeが既にインストールされている場合に表示されます。既存の設定ファイル(config.yml)や関連ファイルを上書きするかどうかを確認するための重要な選択です。
💡 推奨: yesを選択: 新しいプロジェクトや設定をやり直したい場合
**no(デフォルト)**を選択: 既存設定を維持したい場合
2. ソース方言(Source Dialect)の選択
Select the source dialect:
[0] Set it later
[1] datastage
...
Enter a number between 0 and 10:
解説
移行元となるデータベースやETLツールの種類を選択します。この選択により、LakeBridgeは適切なSQL方言の変換ルールを適用し、最適な変換を実行します。
[0] Set it later
後で設定したい場合に選択。インストールのみ完了させたい場合に便利です。
[1] datastage
IBM InfoSphere DataStageからの移行。DataStageのジョブやスクリプトをDatabricksのワークフローに変換します。
[2] informatica (desktop edition)
Informatica PowerCenter Desktop Editionからの移行。ローカル環境のマッピングやワークフローを変換します。
[3] informatica cloud
Informatica Cloud (IICS)からの移行。クラウドベースのInformaticaサービスに特化した変換を行います。
[4] mssql
Microsoft SQL Serverからの移行。T-SQLストアドプロシージャやビューをDatabricks SQLに変換します。
[5] netezza
IBM Netezzaデータウェアハウスからの移行。Netezza固有の関数や構文を適切に変換します。
[6] oracle
Oracle Databaseからの移行。PL/SQLコードやOracle特有の機能をDatabricksに変換します。
[7] snowflake
Snowflakeからの移行。Snowflake SQLやUDF、ストアドプロシージャを効率的に変換します。
[8] synapse
Azure Synapse Analytics(旧SQL Data Warehouse)からの移行。Synapse SQL Poolsのコードを変換します。
[9] teradata
Teradata Databaseからの移行。Teradata SQL、BTEQ、マクロなどを包括的に変換します。
[10] tsql
汎用的なTransact-SQL(T-SQL)からの移行。SQL ServerやSybaseなどのT-SQL方言を変換します。
💡 推奨: 移行元のシステムに完全に一致するオプションを選択してください。不明な場合は[0]を選択して後で設定することも可能です。
3. オーバーライドファイルの指定
Specify the file to use for overrides - press for none (default: ):
解説
カスタム変換ルールや特殊な設定を含むオーバーライドファイルを指定できます。このファイルにより、標準的な変換ルールを企業固有の要件に合わせてカスタマイズすることが可能になります。
# override.yml の例
custom_functions:
source_function_name: target_function_name
CUSTOM_DATE_FORMAT: date_format
naming_conventions:
table_prefix: "dbt_"
schema_mapping:
old_schema: new_schema
💡 推奨: 通常は空エンター(デフォルト)で問題ありません。企業固有のSQL関数や命名規則がある場合のみファイルを指定してください。
4. 入力SQLパスの指定
Enter input SQL path (directory/file) (default: Set it later):
解説
変換対象となるSQLファイルまたはディレクトリのパスを指定します。ディレクトリを指定した場合、配下のすべてのSQLファイルが再帰的に処理されます。
# ディレクトリの例
/home/user/sql_scripts/
C:\Users\username\Documents\sql_files\
# ファイルの例
/home/user/main_procedure.sql
C:\Projects\migration\stored_procedures.sql
💡 推奨: 初期設定時は空エンターで「Set it later」を選択し、実際の変換時に指定する方が柔軟性があります。
5. 出力ディレクトリの指定
Enter output directory (default: transpiled):
解説
変換後のファイルを保存するディレクトリを指定します。元のディレクトリ構造を維持したまま、変換されたファイルが保存されます。
💡 推奨: デフォルトの「transpiled」フォルダを使用することを推奨します。整理された出力構造が維持されます。
⚠️ 注意: 指定したディレクトリに既存ファイルがある場合の動作を事前に確認してください。
6. エラーファイルパスの指定
Enter error file path (default: errors.log):
解説
変換中に発生したエラーや警告を記録するログファイルのパスを指定します。このファイルは変換品質の評価と問題の特定に重要です。
# 基本的な例
errors.log
# 日付入りの例
./logs/lakebridge_errors_$(date +%Y%m%d).log
# 詳細パスの例
/var/log/lakebridge/conversion_errors.log
💡 推奨: デフォルトの「errors.log」で問題ありません。プロジェクトごとに異なるログファイルが必要な場合はカスタマイズしてください。
7. 検証オプションの選択
Would you like to validate the syntax and semantics of the transpiled queries? (default: no):
解説
変換後のSQLコードの構文と意味の正しさを検証するかどうかを選択します。この検証により、変換の品質を確認できますが、Databricksクラスタまたはウェアハウスへの接続が必要です。
💡 推奨: 初期段階では「no」(デフォルト)を選択し、本番移行前の最終確認時に「yes」を選択することを推奨します。
⚠️ 注意: 検証を有効にする場合は、アクティブなDatabricksクラスタまたはSQLウェアハウスが必要です。
8. 設定ファイルのブラウザ表示
Open config file https://adb-x~~~~/config.yml in the browser? (default: no):
解説
生成された設定ファイル(config.yml)をDatabricksワークスペース内でブラウザで開くかどうかを確認します。GUIで設定を確認・編集したい場合に便利です。
💡 推奨: CLIでの作業を継続する場合は「no」(デフォルト)を選択してください。視覚的な確認が必要な場合のみ「yes」を選択します。
🔧 トラブルシューティング
権限エラーが発生する場合
出力ディレクトリへの書き込み権限を確認し、Databricks CLIの認証が正しく設定されているか確認してください。
変換エラーが多発する場合
ソース方言の選択が正しいか再確認し、エラーログを詳細に確認してください。
検証が失敗する場合
Databricksクラスタ/ウェアハウスが起動しているか、ネットワーク接続を確認してください。
インストール後の確認方法
# Databricks CLIを使用してconfig.ymlの存在を確認
databricks workspace list /Workspace/Users/hogehoge@hoge.co.jp/.lakebridge/
# 期待される出力:
ID Type Language Path
DIRECTORY /Workspace/Users/hogehoge@hoge.co.jp/.lakebridge/wheels
FILE /Workspace/Users/hogehoge@hoge.co.jp/.lakebridge/config.yml
FILE /Workspace/Users/hogehoge@hoge.co.jp/.lakebridge/version.json
# config.ymlの内容を確認
databricks workspace export /Workspace/Users/hogehoge@hoge.co.jp/.lakebridge/config.yml
# 出力例:
hogehoge@hoge.co.jp/.lakebridge/config.yml
catalog_name: remorph
error_file_path: C:\Users\hogehoge\errors.log
output_folder: C:\Users\hogehoge\transpiled
schema_name: transpiler
skip_validation: true
source_dialect: synapse
transpiler_config_path: C:\Users\hogehoge\.databricks\labs\remorph-transpilers\bladebridge\lib\config.yml
transpiler_options:
overrides-file: null
version: 3
💡 インストールのベストプラクティス:
- 新しいプロジェクトでは、最初にinstall-transpileを実行してください
- チーム環境では、全員が同じバージョンのアーティファクトを使用することを推奨
- カスタムアーティファクトを使用する場合は、事前にテスト環境で検証してください
- 既存の設定がある場合、インストール前にバックアップを取ることを推奨
トラブルシューティング
💭 よくある問題と解決方法:
- 権限エラー: ワークスペースへの書き込み権限を確認してください
- ネットワークエラー: デフォルトアーティファクトのダウンロードにはインターネット接続が必要です
- 既存設定の競合: --forceオプション(未ドキュメント)で上書きできる可能性があります
- バージョン互換性: Databricks CLI v0.205.0以上が必要です
✅ 次のステップ:
install-transpileが正常に完了したら、transpileコマンドを使用してSQL変換を開始できます。インストール直後は、簡単なSQLファイルで動作確認を行うことを推奨します。
🔄 transpile コマンドの完全ガイド
Transpileコマンドのアーキテクチャ
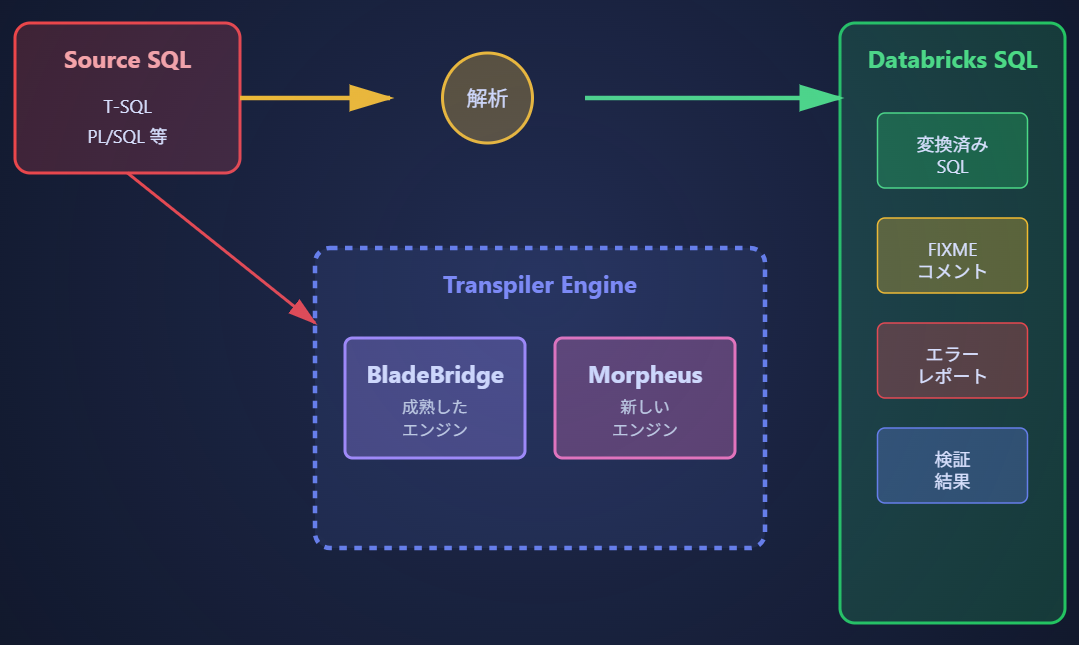
フラグ
| フラグ | 説明 |
|---|---|
| --catalog-name | 検証モードがDATABRICKSの場合にのみ適用されるカタログ名です。 |
| --error-file-path | エラーを保存するための出力場所。デフォルトは入力ソースフォルダです。 |
| --input-source | 入力スクリプトのフォルダまたはファイルです。 |
| --output-folder | トランスパイルされたコードを保存するための出力場所。デフォルトは入力ソースフォルダです。 |
| --schema-name | 検証モードがDATABRICKSの場合にのみ適用されるスキーマ名です。 |
| --skip-validation | トランスパイルされたコードを検証します。デフォルトはtrueで検証をスキップし、falseで検証します。 (デフォルトは"true") |
| --source-dialect | ダイアレクト名です。 |
| --transpiler-config-path | トランスパイラー設定ファイルへのパスです。2025/7/13時点でマニュアルに使用法が未記載 |
実際のサンプルデータを使った実行例
# サンプルストアドプロシージャ(変換前)
cat > ./synapse-migration/source/sp_calculate_monthly_sales.sql << 'EOF'
CREATE PROCEDURE [dbo].[sp_calculate_monthly_sales]
@StartDate DATETIME,
@EndDate DATETIME,
@StoreID INT = NULL
AS
BEGIN
SET NOCOUNT ON;
-- 一時テーブルの作成
CREATE TABLE #MonthlySales (
YearMonth NVARCHAR(7),
StoreID INT,
ProductCategory NVARCHAR(50),
TotalSales DECIMAL(18,2),
TransactionCount INT
);
-- 月次売上の集計
INSERT INTO #MonthlySales
SELECT
FORMAT(s.SaleDate, 'yyyy-MM') AS YearMonth,
s.StoreID,
p.Category AS ProductCategory,
SUM(s.SaleAmount) AS TotalSales,
COUNT(DISTINCT s.TransactionID) AS TransactionCount
FROM Sales s
INNER JOIN Products p ON s.ProductID = p.ProductID
WHERE s.SaleDate BETWEEN @StartDate AND @EndDate
AND (@StoreID IS NULL OR s.StoreID = @StoreID)
GROUP BY FORMAT(s.SaleDate, 'yyyy-MM'), s.StoreID, p.Category;
-- 結果の更新
MERGE MonthlySalesReport AS target
USING #MonthlySales AS source
ON target.YearMonth = source.YearMonth
AND target.StoreID = source.StoreID
AND target.ProductCategory = source.ProductCategory
WHEN MATCHED THEN
UPDATE SET
TotalSales = source.TotalSales,
TransactionCount = source.TransactionCount,
LastUpdated = GETDATE()
WHEN NOT MATCHED THEN
INSERT (YearMonth, StoreID, ProductCategory, TotalSales, TransactionCount, LastUpdated)
VALUES (source.YearMonth, source.StoreID, source.ProductCategory,
source.TotalSales, source.TransactionCount, GETDATE());
-- クリーンアップ
DROP TABLE #MonthlySales;
-- サマリーの返却
SELECT
COUNT(DISTINCT YearMonth) AS MonthsProcessed,
COUNT(DISTINCT StoreID) AS StoresProcessed,
SUM(TotalSales) AS GrandTotal
FROM MonthlySalesReport
WHERE LastUpdated >= DATEADD(MINUTE, -1, GETDATE());
END
EOF
# Transpileコマンドの実行(BladeBridgeエンジン使用)
REM 環境変数設定 コマンドプロンプトの文字コードがUTF-8でないと動かない!
chcp 65001
set PYTHONIOENCODING=utf-8
set PYTHONUTF8=1
REM 絶対パスを使用したLakebridge実行
databricks labs lakebridge transpile ^
--input-source "C:\Users\ユーザー名\synapse-migration\source\sp_calculate_monthly_sales.sql" ^
--output-folder "C:\Users\ユーザー名\synapse-migration\databricks" ^
--source-dialect "synapse" ^
--catalog-name "sales_analytics" ^
--schema-name "reporting" ^
--skip-validation "true" ^
--error-file-path "C:\Users\ユーザー名\synapse-migration\errors" ^
--debug
# 実行結果の例:
# ✓ ファイル読み込み完了: sp_calculate_monthly_sales.sql
# ✓ 構文解析完了
# ✓ トランスパイル開始(エンジン: BladeBridge)
#
# 変換統計:
# - 総行数: 45
# - 変換成功: 42行 (93%)
# - 警告: 2行
# - エラー: 1行
#
# 警告:
# - Line 15: FORMAT関数は date_format に変換されました
# - Line 31: GETDATE() は current_timestamp() に変換されました
#
# エラー:
# - Line 8: 一時テーブル #MonthlySales は一時ビューに変換が必要です(FIXME追加)
#
# 出力ファイル: ./synapse-migration/databricks/sp_calculate_monthly_sales_databricks.sql
# エラーレポート: ./synapse-migration/errors/sp_calculate_monthly_sales_errors.log
変換後のDatabricks SQL(自動生成した例)
-- Databricks notebook source
-- MAGIC %python
-- MAGIC # 自動変換: sp_calculate_monthly_sales
-- MAGIC # 元のソース: Azure Synapse
-- MAGIC # 変換日時: 2024-11-15 10:30:45
-- MAGIC # 使用エンジン: BladeBridge v2.1
-- COMMAND ----------
-- MAGIC %python
-- MAGIC def calculate_monthly_sales(start_date, end_date, store_id=None):
-- MAGIC """
-- MAGIC 月次売上を計算するストアドプロシージャの変換版
-- MAGIC """
-- MAGIC
-- MAGIC # FIXME: 一時テーブル #MonthlySales を一時ビューに変換
-- MAGIC spark.sql("""
-- MAGIC CREATE OR REPLACE TEMPORARY VIEW monthly_sales AS
-- MAGIC SELECT
-- MAGIC date_format(s.SaleDate, 'yyyy-MM') AS YearMonth,
-- MAGIC s.StoreID,
-- MAGIC p.Category AS ProductCategory,
-- MAGIC SUM(s.SaleAmount) AS TotalSales,
-- MAGIC COUNT(DISTINCT s.TransactionID) AS TransactionCount
-- MAGIC FROM sales_analytics.reporting.Sales s
-- MAGIC INNER JOIN sales_analytics.reporting.Products p
-- MAGIC ON s.ProductID = p.ProductID
-- MAGIC WHERE s.SaleDate BETWEEN '{start_date}' AND '{end_date}'
-- MAGIC {store_filter}
-- MAGIC GROUP BY date_format(s.SaleDate, 'yyyy-MM'), s.StoreID, p.Category
-- MAGIC """.format(
-- MAGIC start_date=start_date,
-- MAGIC end_date=end_date,
-- MAGIC store_filter=f"AND s.StoreID = {store_id}" if store_id else ""
-- MAGIC ))
-- MAGIC
-- MAGIC # MERGEステートメントの実行
-- MAGIC spark.sql("""
-- MAGIC MERGE INTO sales_analytics.reporting.MonthlySalesReport AS target
-- MAGIC USING monthly_sales AS source
-- MAGIC ON target.YearMonth = source.YearMonth
-- MAGIC AND target.StoreID = source.StoreID
-- MAGIC AND target.ProductCategory = source.ProductCategory
-- MAGIC WHEN MATCHED THEN
-- MAGIC UPDATE SET
-- MAGIC TotalSales = source.TotalSales,
-- MAGIC TransactionCount = source.TransactionCount,
-- MAGIC LastUpdated = current_timestamp()
-- MAGIC WHEN NOT MATCHED THEN
-- MAGIC INSERT (YearMonth, StoreID, ProductCategory, TotalSales,
-- MAGIC TransactionCount, LastUpdated)
-- MAGIC VALUES (source.YearMonth, source.StoreID, source.ProductCategory,
-- MAGIC source.TotalSales, source.TransactionCount, current_timestamp())
-- MAGIC """)
-- MAGIC
-- MAGIC # 一時ビューの削除
-- MAGIC spark.sql("DROP VIEW IF EXISTS monthly_sales")
-- MAGIC
-- MAGIC # サマリーの返却
-- MAGIC return spark.sql("""
-- MAGIC SELECT
-- MAGIC COUNT(DISTINCT YearMonth) AS MonthsProcessed,
-- MAGIC COUNT(DISTINCT StoreID) AS StoresProcessed,
-- MAGIC SUM(TotalSales) AS GrandTotal
-- MAGIC FROM sales_analytics.reporting.MonthlySalesReport
-- MAGIC WHERE LastUpdated >= current_timestamp() - INTERVAL 1 MINUTE
-- MAGIC """).collect()
-- COMMAND ----------
-- MAGIC %python
-- MAGIC # 関数の実行例
-- MAGIC result = calculate_monthly_sales('2024-01-01', '2024-10-31', store_id=101)
-- MAGIC display(result)
✅ reconcile コマンドの完全ガイド
Reconcileコマンドのアーキテクチャ
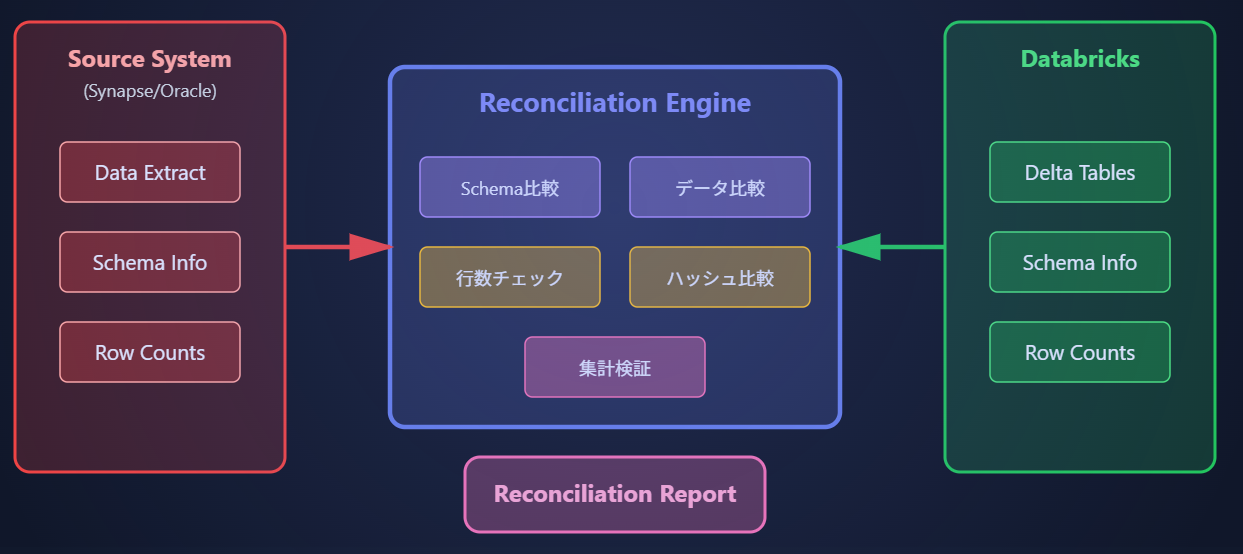
実際のサンプルデータを使った実行例
事前準備:設定ファイルの作成
# reconcile設定ファイルの作成
cat > ./synapse-migration/config/reconcile-config.yml << 'EOF'
reconciliation:
source:
type: "synapse"
connection:
server: "synapse-server.database.windows.net"
database: "SalesDB"
authentication: "ActiveDirectoryInteractive"
target:
type: "databricks"
connection:
workspace_url: "https://adb-1234567890.azuredatabricks.net"
catalog: "sales_analytics"
schema: "reporting"
validation_rules:
- name: "row_count_check"
enabled: true
threshold: 0.01 # 1%の差異を許容
- name: "schema_validation"
enabled: true
check_data_types: true
check_nullable: true
check_column_order: false
- name: "data_sampling"
enabled: true
sample_size: 10000
sampling_method: "random"
- name: "aggregate_validation"
enabled: true
metrics:
- "SUM"
- "COUNT"
- "AVG"
- "MIN"
- "MAX"
- name: "hash_comparison"
enabled: true
algorithm: "SHA256"
chunk_size: 50000
tables_to_reconcile:
- source_table: "dbo.Sales"
target_table: "Sales"
primary_key: ["TransactionID"]
partition_column: "SaleDate"
- source_table: "dbo.Products"
target_table: "Products"
primary_key: ["ProductID"]
- source_table: "dbo.Customers"
target_table: "Customers"
primary_key: ["CustomerID"]
exclude_columns: ["LastModified", "ETLTimestamp"]
- source_table: "dbo.MonthlySalesReport"
target_table: "MonthlySalesReport"
primary_key: ["YearMonth", "StoreID", "ProductCategory"]
custom_checks:
- "TotalSales >= 0"
- "TransactionCount > 0"
output:
report_format: "html"
report_path: "./synapse-migration/reconciliation-reports"
include_detailed_mismatches: true
max_mismatch_records: 1000
EOF
# 照合環境の設定
databricks labs lakebridge configure-reconcile ^
--config-file ./synapse-migration/config/reconcile-config.yml ^
--create-dashboard true ^
--dashboard-name "Synapse_Migration_Reconciliation" ^
--notification-email "data-team@company.com"
サンプル実行:大規模テーブルの照合
# 照合の実行
databricks labs lakebridge reconcile ^
--config-file ./synapse-migration/config/reconcile-config.yml ^
--parallel-threads 8 ^
--checkpoint-enabled true ^
--checkpoint-interval 10000 ^
--continue-on-error true ^
--detailed-logging true
# 実行結果の例:
# ========================================
# Databricks Lakebridge Reconciliation
# Started: 2024-11-15 14:30:00
# ========================================
#
# [14:30:05] 接続テスト...
# ✓ ソースシステム (Synapse): 接続成功
# ✓ ターゲットシステム (Databricks): 接続成功
#
# [14:30:10] テーブル: dbo.Sales → Sales
# - スキーマ検証: ✓ 一致
# - 行数チェック:
# Source: 5,234,567 rows
# Target: 5,234,561 rows
# 差異: 6 rows (0.0001%)
# - データサンプリング (10,000 rows): ✓ 一致
# - ハッシュ比較:
# Chunk 1/105: ✓
# Chunk 2/105: ✓
# ...
# Chunk 104/105: ✓
# Chunk 105/105: ✗ 不一致検出
# - 集計検証:
# SUM(SaleAmount): ✓ 一致 ($45,678,234.56)
# COUNT(DISTINCT CustomerID): ✓ 一致 (123,456)
# AVG(SaleAmount): ✓ 一致 ($87.32)
#
# [14:35:45] テーブル: dbo.Products → Products
# - スキーマ検証: ✓ 一致
# - 行数チェック: ✓ 完全一致 (8,456 rows)
# - データサンプリング: ✓ 一致
# - ハッシュ比較: ✓ 完全一致
# - 集計検証: ✓ すべて一致
#
# [14:36:30] テーブル: dbo.Customers → Customers
# - スキーマ検証: ⚠ 警告
# - カラム 'MiddleName': ソースでNULL許可、ターゲットでNOT NULL
# - 行数チェック: ✓ 完全一致 (234,567 rows)
# - データサンプリング: ✓ 一致
# - ハッシュ比較: ✓ 完全一致
#
# [14:38:15] テーブル: dbo.MonthlySalesReport → MonthlySalesReport
# - スキーマ検証: ✓ 一致
# - 行数チェック: ✓ 完全一致 (1,234 rows)
# - カスタムチェック:
# ✓ TotalSales >= 0: すべてのレコードが条件を満たす
# ✓ TransactionCount > 0: すべてのレコードが条件を満たす
#
# ========================================
# 照合サマリー
# ========================================
# 処理時間: 8分15秒
#
# テーブル照合結果:
# ✓ 完全一致: 2/4 (50%)
# ⚠ 軽微な差異: 2/4 (50%)
# ✗ 重大な差異: 0/4 (0%)
#
# 詳細レポート:
# ./synapse-migration/reconciliation-reports/reconcile_20241115_143000.html
#
# Databricksダッシュボード:
# https://adb-1234567890.azuredatabricks.net/dashboards/synapse-migration-reconciliation
⚠️ パフォーマンスのヒント:
大規模テーブル(数億行以上)の照合時は、パーティション列を活用し、並列処理とチェックポイント機能を有効にすることで、処理時間を大幅に短縮できます。