はじめに
自然言語処理100本ノック第7章で「階層型クラスタリング」が出てきたので、初心者の私なりに理解できた部分を記載する。
第7章-68 問題文
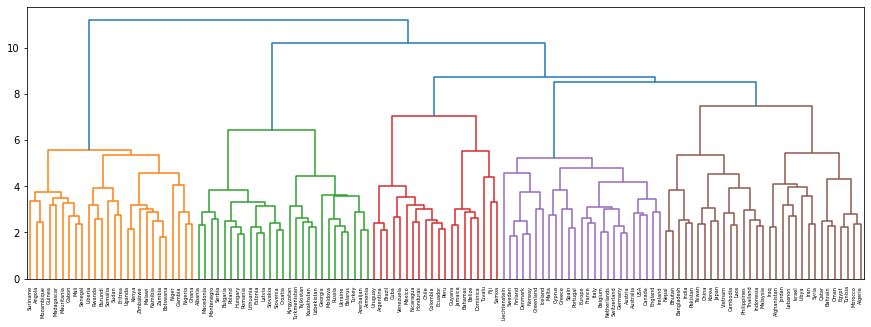
国名に関する単語ベクトルに対し,Ward法による階層型クラスタリングを実行せよ.さらに,クラスタリング結果をデンドログラムとして可視化せよ.
第7章-68 解答
以下のコードが正解となっている。(こちらの記事より引用)
from sklearn.cluster import KMeans
# k-meansクラスタリング
kmeans = KMeans(n_clusters=5)
kmeans.fit(countries_vec)
for i in range(5):
cluster = np.where(kmeans.labels_ == i)[0] #cluster毎に分類されたcuntriesのラベル(3,17,18,...)を取得
print('cluster', i)
print(', '.join([countries[k] for k in cluster])) #取得したラベルに紐づくcuntries(3:Zambia,17:Sudan,18:Namibia,...)を表示
出力
cluster 0
Zambia, Sudan, Namibia, Uganda, Guinea, Kenya, Zimbabwe, Angola, Gabon, Rwanda, Nigeria, Mozambique, Mauritania, Algeria, Madagascar, Ghana, Mali, Tunisia, Liberia, Niger, Senegal, Malawi, Eritrea, Burundi, Gambia, Botswana
cluster 1
Albania, Kazakhstan, Russia, Slovakia, Montenegro, Ukraine, Hungary, Turkey, Azerbaijan, Poland, Greece, Bulgaria, Romania, Lithuania, Slovenia, Moldova, Estonia, Belarus, Macedonia, Serbia, Latvia, Croatia, Armenia, Georgia, Cyprus, Uzbekistan, Turkmenistan
cluster 2
Ecuador, Guyana, Fiji, Suriname, Samoa, Nicaragua, Belize, Chile, Cuba, Bahamas, Peru, Tuvalu, Mexico, Jamaica, Colombia, Dominica, Venezuela, Honduras
cluster 3
England, Morocco, Switzerland, Greenland, Uruguay, Europe, Germany, Austria, Argentina, Australia, USA, Sweden, Ireland, Iceland, Belgium, Spain, Denmark, Finland, Canada, Netherlands, Liechtenstein, France, Norway, Malta, Brazil, Portugal, Italy, Japan
cluster 4
Indonesia, Iraq, Taiwan, India, Korea, Kyrgyzstan, Vietnam, Libya, Somalia, Iran, Jordan, Bangladesh, Qatar, Egypt, Nepal, China, Thailand, Cambodia, Lebanon, Bhutan, Malaysia, Tajikistan, Bahrain, Syria, Oman, Pakistan, Laos, Afghanistan, Philippines, Israel
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
plt.figure(figsize=(15, 5))
Z = linkage(countries_vec, method='ward')
dendrogram(Z, labels=countries)
plt.show()
linkage関数
ここで理解に苦しんだのは「linkage関数」である。
linkageはScipyに含まれるパッケージであり、以下のような構造となっている。
scipy.cluster.hierarchy.linkage(df, method='ward', metric='euclidean', optimal_ordering=False)
引数methodで、階層型クラスタリングの手法を選択している。
- method = 'single':最小結合法
- method = 'complite':最大結合法
- method = 'average':群平均法
- method = 'ward':ウォード法
今回選択した「ウォード法」とは、凝集型階層的クラスタリングと呼ばれるクラスタリングの手法の1つ。
凝集型階層的クラスタリングとは、
1.全ての点が別々のクラスタである状態から始める
2.「今あるクラスタの中で、最も距離が近い2つのクラスタを選んで1つのクラスタに合体する」という操作を行う
3.合体を目標のクラスタ数になるまで繰り返す
という手法となっている。
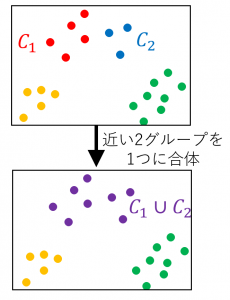
引用元:ウォード法によるクラスタリングのやり方
なお、metric='euclidean'については、点どうしの距離をユークリッド距離(2点間の直線距離)で定義するという意味である。他にもミンコフスキー距離・コサイン距離などを選択できるようだが、基本的にユークリッド距離を選択すれば良いようなので割愛する。
話を戻すと、
Z = linkage(countries_vec, method='ward')
dendrogram(Z, labels=countries)
ここではlinkage関数を用いて、countries_vec(国名一覧を単語ベクトルで表したもの)をウォード法により目標のクラスタ数(=5)になるまでクラスタリングを繰り返している、ということになる。