スプレッドシートで管理している内容をRuby on Railsのアプリケーションにdeployするという運用があり、これまでは、
- スプレッドシートを編集(運用チーム)
- 開発チームに依頼(運用チーム)
- スプレッドシートの内容をcsvで保存(開発チーム)
- csvファイルを所定のディレクトリに置く(開発チーム)
- capistranoを使ってec2にdeployする(開発チーム)
という運用でした。
これ、めんどくせえなぁ、という事で運用を見直した話となります。
お話する内容
こんな仕組みが作れたよ、という話
システム構成
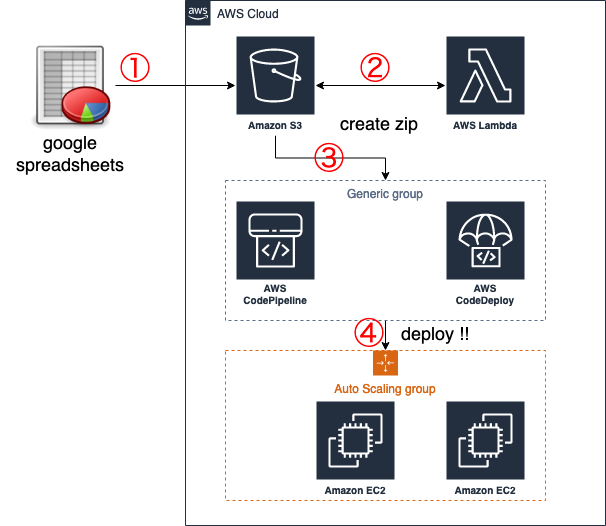
登場人物
- SpreadSheets
- S3
- Lambda
- CodePipeline with CodeDeploy
- EC2
流れ
① スプレッドシート上のdeployボタンが押される
② 特定のフォルダをWatchしていたLambdaが実行されてzipファイルに固める
③ S3上の特定のファイルをWatchしていたCodePipelineが実行される
④ CodeDeployにより各EC2にcsvファイルがコピーされ、deployコマンドが実行される
① スプレッドシート上のdeployボタンが押される
例えばこんなスプレッドシートがあります。
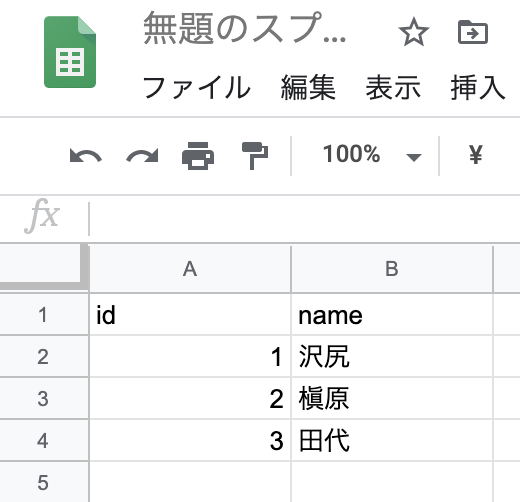
これをCSVファイルにしてS3にアップしたい。
こちらを参考にさせていただきました。
GoogleスプレッドシートのデータをS3へCSVとして保存する
- S3へのPutObject権限だけをもつIAMユーザーを作成してアクセスキーなどをコピー
- csvとzipファイルの保存先となるS3 bucketを作る(今回は
xxxx-auto-deploy。csvはcsv/に、zipファイルはzip/に保存される) - スプレッドシートの
ツール>スクリプトエディタよりスクリプトを生成 - スクリプト内ではcsvファイルの他、codedeployで使われるappspec.ymlとappStart.shが生成される
-
挿入>図形描画よりボタンを生成 - ボタンに対して作った関数を割り当てる(例では
myFunction)
スクリプト:
const aws_bucket_name = "xxxx-auto-deploy";
const aws_access_key = "xxxx";
const aws_secret_key = "xxxx";
const s3 = S3.getInstance( aws_access_key, aws_secret_key );
// スプレッドシートを取得
const ss = SpreadsheetApp.openById('xxxx');
const activeSheet = ss.getSheetByName('シート1');
async function myFunction() {
var _data = activeSheet.getRange("A:B").getDisplayValues();
// csvデータ用の配列を用意
var csv = '';
// データをチェックしながらループ
for (var i = 0; i < _data.length; i++){
v = _data[i];
if(v[0] === ''){
continue;
}
var l = '"' + v[0] + '","';
l += v.slice(1,-1).join('","'); //←ここ2列以下のCSVだといらなかった
csv += l + '","' + v[v.length - 1] + '"' + "\n";
}
//csvをS3にアップ
var blob = Utilities.newBlob(csv, MimeType.CSV).setName("data.csv");
await s3.putObject( aws_bucket_name,'csv/data.csv', blob, {logRequests:true} );
//codedeployで使うymlとshも生成
var txt = ''
var appspec = `version: 0.0
os: linux
files:
- source: ./
destination: /home/user/application/
hooks:
ApplicationStart:
- location: appStart.sh
`;
//appspec.ymlをS3にアップ
txt = Utilities.newBlob(appspec, MimeType.PLAIN_TEXT);
await s3.putObject( aws_bucket_name, 'csv/appspec.yml', txt, {logRequests:true} );
var appStart = `#!/bin/bash
echo "deploy!"
`;
//appStart.ymlをS3にアップ
txt = Utilities.newBlob(appStart, MimeType.PLAIN_TEXT);
await s3.putObject( aws_bucket_name, 'csv/appStart.sh', txt, {logRequests:true} );
return true;
}
すんません。だいぶ短めにまとめたのでだいぶ雑です。
やってる事はシンプル。csvファイルを作るのと3つのファイルをS3のcsv/にアップしてるだけ。
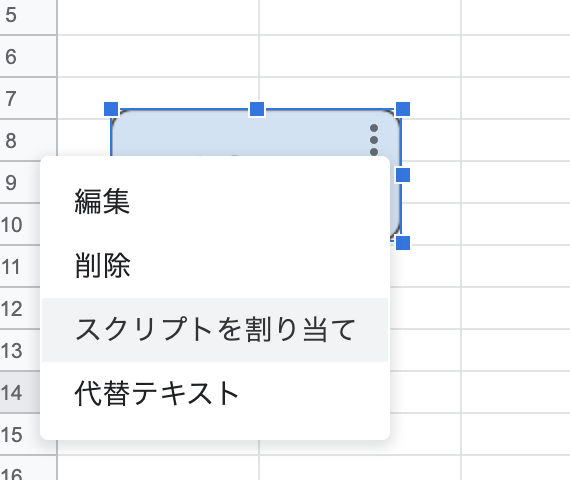

ボタン作って割り当てる。
これでボタンを押すとS3にファイルがアップされる。
② 特定のフォルダをWatchしていたLambdaが実行されてzipファイルに固める
S3のPutをトリガーに実行されるLambdaを作成します。
| Key | Value |
|---|---|
| functionName | 適当 |
| runtime | Python3.8 |
| トリガー | S3 |
| アクセス権限 | ログ書き込み+S3の書き込み読み込み(特定のバケットでOK)| |
S3のPutトリガー
トリガーとしてS3を選択し、下記のような設定にします
| Key | Value |
|---|---|
| イベントタイプ | ObjectCreatedByPut |
| サフィックス | appStart.sh |
| プレフィックス | csv |
サフィックスにはスクリプトからS3にアップされる最後のファイルにしています。
appStart.shがcsvフォルダ内にPutされるとこのLambdaが実行される
スクリプトの中身
import datetime
import boto3
import zipfile
import os.path
import os
print('Loading function...')
s3 = boto3.resource('s3')
s3_cli = boto3.client('s3')
tmp_dir = '/tmp'
def lambda_handler(event, context):
now = datetime.datetime.now()
sourceFileName = 'deploy.zip'
try:
# バケット名
input_bucket = event['Records'][0]['s3']['bucket']['name']
# zipというフォルダにdeploy.zipをいうファイルを置きたい。ファイルは一旦/tmpにDL
uploadZipFileName = 'zip/{}'.format(sourceFileName)
localZipFileNamme = '{}/{}'.format(tmp_dir, sourceFileName)
bucket = s3.Bucket(input_bucket)
# csvやymlを/tmpにDL
filenames = []
print('Downloading s3 file...')
for object in bucket.objects.filter(Prefix='csv/'):
_filename = object.key.split("/")[-1]
if _filename[-3:] not in ['csv','yml','.sh'] :
continue
file_path = os.path.join('', object.key.split("/")[-1])
filenames.append(_filename)
s3_cli.download_file(object.bucket_name, object.key, '{}/{}'.format(tmp_dir,_filename))
# DLしたファイルをzipファイルに固める(/tmp内で)
with zipfile.ZipFile( localZipFileNamme, "w", zipfile.ZIP_DEFLATED) as zf:
for name in filenames:
filename = os.path.join(tmp_dir, name) # 保存先
zf.write(filename=filename, arcname=name)
# Upload ziped file
print('Uploading ziped file...')
bucket.upload_file( localZipFileNamme, uploadZipFileName)
except Exception as e:
print(e)
print('Opps, Error happened')
raise e
print('Finish function!')
これで特定のバケットにzip/deploy.zipというファイルが生成されます。
今回の例だと3つのファイルがupされ、それがzipに固まる
- data.csv
- appspe.yml
- appStart.sh
③ S3上の特定のファイルをWatchしていたCodePipelineが実行される
AwsコンソールよりCodePipelineを開き、Pipelineを生成します。
| key | value |
|---|---|
| パイプライン名 | なんでもいい |
| サービスロール | 新しく生成(わかる人は既存でいい) |
| ソースプロバイダ | amazon S3 |
※ちなみに書いてない部分はデフォルト(2020/5/4現在)
ソースプロバイダ
CodepipelineはソースとしてS3を選択できます。
つまりcodedeploy時に使われるソースです。
| key | value |
|---|---|
| バケット名 | 今回はxxxx-auto-deploy |
| S3オブジェクトキー | zip/deploy.zip |
基本、これだけでOK
ビルドプロバイダ
要りません。スキップでOK
デプロイプロバイダ
CodeDeployです。
先にDeploy対象のアプリケーションとグループを作っておきましょう。
今回はec2が対象で、Nameタグに特定の文字列を指定してあるものとします。仮にauto-deployとしましょうか。
| key | value |
|---|---|
| アプリケーション名 | 適当 |
| コンピューティングプラットフォーム | EC2/オンプレミス |
| デプロイグループ名 | 適当 |
| デプロイタイプ | インプレース |
| デプロイ設定 | CodeDeployDefault.OneAtATime(1台ずつdeploy。これじゃなくてもいい) |
| 環境設定: Amazon EC2 インスタンス | キー:Name、値:auto-deploy |
| サービスロール | AWSCodeDeployRoleポリシーがアタッチされたロール。 |
これでcodePipelineの設定は完了です。
④ CodeDeployにより各EC2にcsvファイルがコピーされ、deployコマンドが実行される
今回のCodeDeployの流れとしては、codedeploy agentを介して、ec2インスタンス上で下記の動作が行われます。
- csvファイルのコピー
- appStart.shの実行
これらの設定がappspec.ymlに書いてあるわけです。
なお、csvファイルなどはS3上にあるため、ec2インスタンスよりS3ファイルのGetができる権限が必要となります。
Ec2インスタンスにS3ReadOnlyポリシーを付与したロールをアタッチするのがいいと思います。
それとcodedeployのagentのインストールと起動が必要です。
CodeDeploy エージェントのインストールまたは再インストール
これで完了。
スプレッドシート上のボタンを押すと一連の流れが動作し、appStart.shが実行されるはずです。
appStart.shは空に近い状態となっていますが、実際にはここにdeployコマンドを書いて、ec2上で実行させる感じです。
またcodedeployはapplicationStart以外にもコマンドを実行させるタイミングがいくつかあるので、このあたりを参考にしてみてください。
最後に
codedeployのログは/opt/codedeploy-agent/deployment-rootのあたりにあります(centos系のosの場合)。
deploy中は、tail -f /opt/codedeploy-agent/deployment-root/deployment-logs/codedeploy-agent-deployments.logとかを実行しておくとdeployの様子がわかりやすいと思います。
deployの設定がちゃんとできるまではちょこちょこ失敗とかすると思います。。ファイルの上書き問題とか(←これはBeforeInstallのあたりで削除してあげるといい)
なんか書きたいことざっと書いただけですがこんな感じで終わります。