今回は「H2O.ai」という機械学習分析プラットフォームを試しに使ってみます。
自分でモデルをプログラム実装しなくても様々なモデルを試せるのでうまく使えると便利そうです。
(H2Oというと、WebサーバソフトウェアのH2Oというのがありますが、これとは別ものなのでご注意ください。)
サービスだとDataRobotとか機械学習プラットフォームとして有名ですね。
これと類似のカテゴリのものだと思います。
インストール
H2O.aiのサーバをまずは動かします。
Javaで実装されているので以下からjarを落としてきて動かすだけで済むようです。
https://h2o-release.s3.amazonaws.com/h2o/master/4275/index.html
適当にサーバにjdkをインストール後、インストールします。
$ wget https://h2o-release.s3.amazonaws.com/h2o/master/4275/h2o-3.19.0.4275.zip
$ gunzip h2o-3.19.0.4275.zip
$ cd h2o-3.19.0.42785
$ java -jar h2o.jar
これでデフォルト54321ポートで管理画面が起動します。
データの準備
分析処理を少し試すため、Kaggleで公開されている「タイタニック号の事故での生存予測問題」のデータを使ってみます。
train.csvとtest.csvを入手しておきます。
画面から事前準備
http://ホスト名:54321/にアクセスすると以下のような画面が表示されます。
対応しているモデルとしては以下の辺りがあるようです。
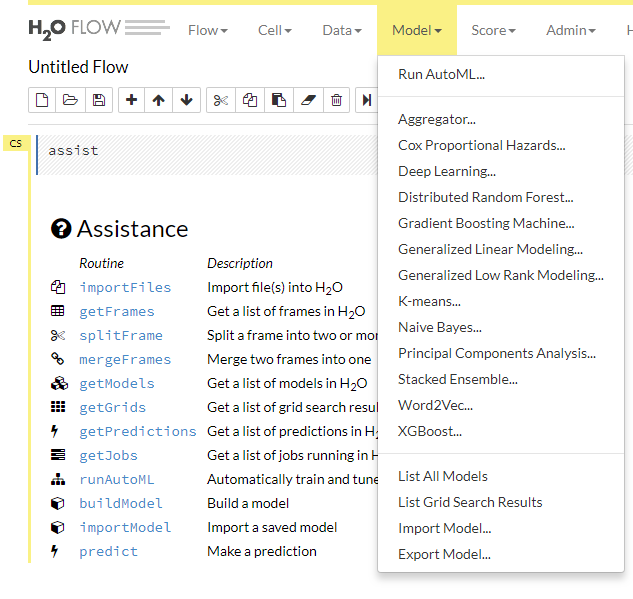
まずは訓練データのインポートから。
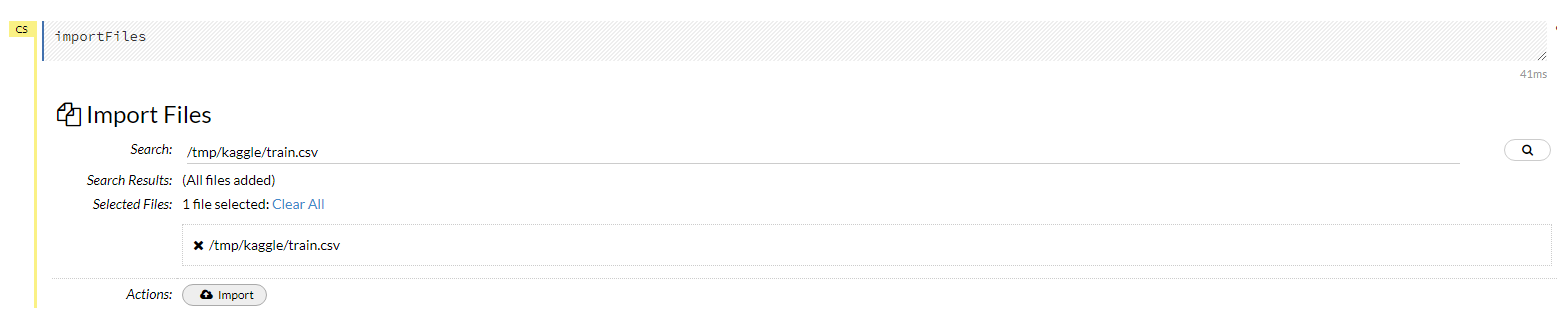
importFilesから先程準備したtrain.csvのデータをインポートします。
csvの配置先のパスを指定してインポートできます。
次に、ファイルの内容をParse処理します。
勝手に各カラムがどういったタイプのデータであるとか判定してパース処理してくれます。
自動判定された型が違う場合には修正を、特定のカラムを処理の対象外にしたい場合はタイプの部分をInvalidとすることも可能です。
一旦、今回は自動設定されたままの状態で進めてみます。

パースが完了すればこんな感じで結果が表示され、何件のデータがあるか、数値系のカラムであれば最大・最小がどうであるかといった統計情報も含めて表示されます。
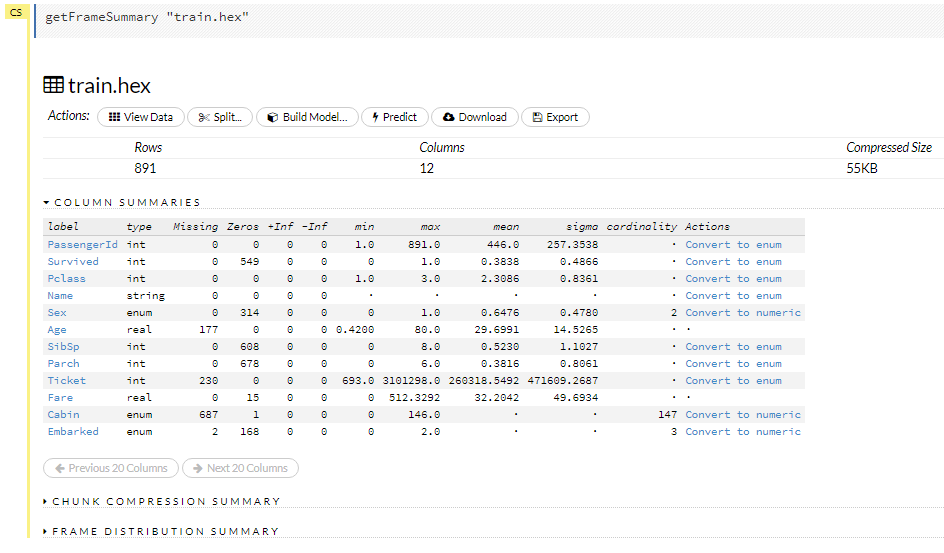
これでまずは事前準備が完了です。
モデルをBuild
上部のメニューのgetFramesからBuild Modelを実行します。
アルゴリズムを選択します。
今回は試しに「Distributed Random Forest」を選択。
training_frameとして先程インポート・パースしたtrain.hexを選択。response_columnとして最終的に予測させたいターゲットとなるSurvivedを指定。
あとはひとまずデフォルトのままで進みます。
本来なら検証用のデータセットもあるのが望ましいと思います。
今回のようにtrain.csvという感じで1データ・セットしかない場合でもそのデータを分割してトレーニング用、検証用と扱いをわける処理もH2O.ai上で簡単にできるようです。
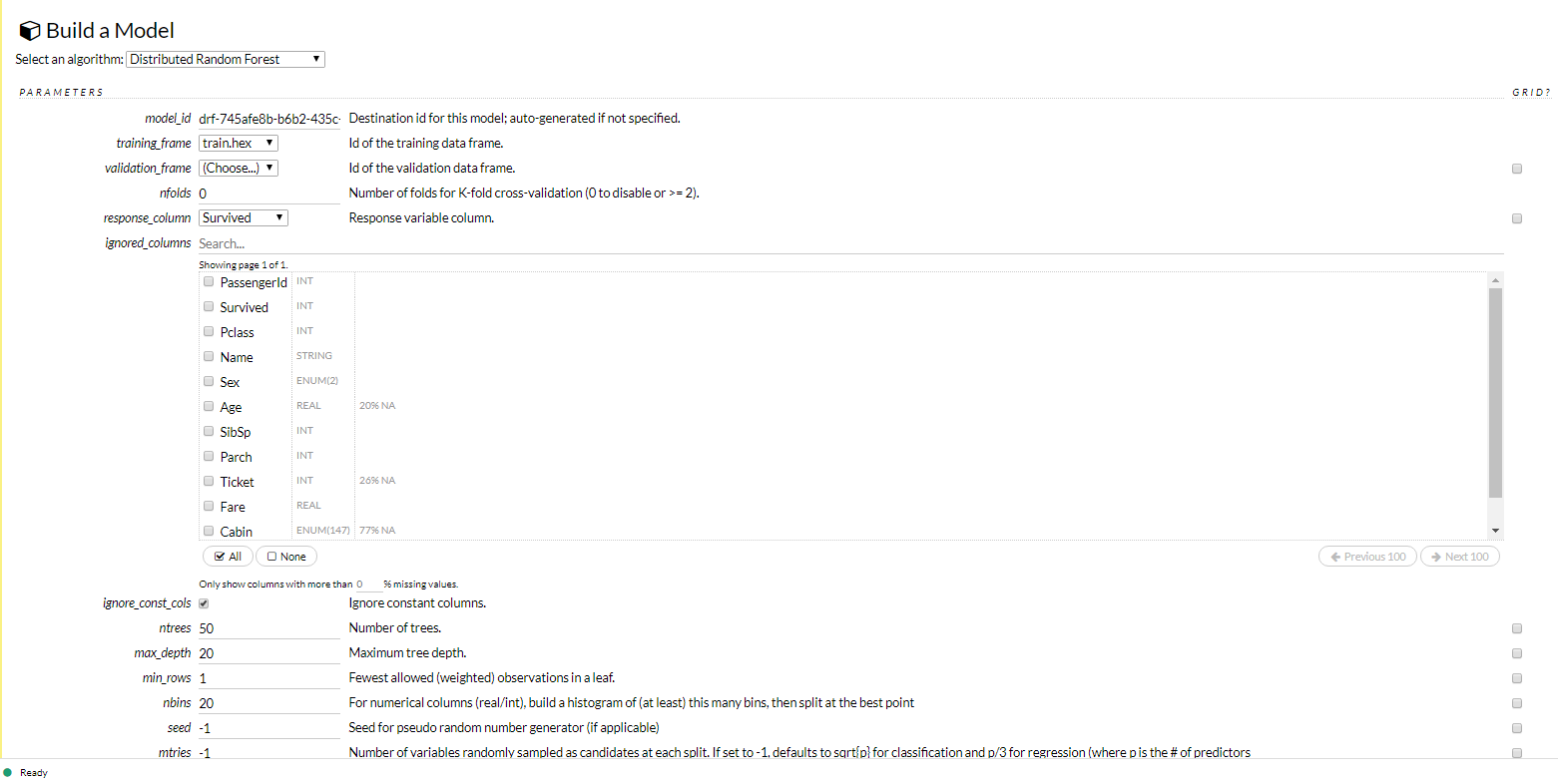
しばらくするとBuildジョブが完了します。

結果を見ると、各変数の重要度としてどれが高いか(今回だと性別がより効いてきそうだというのが)わかります。
ひとまずこれでモデルは完成。
テストデータに対して予測値を算出
先程のtrain.csvをインポートした時と同様にtest.csvをインポートします。
上部のメニューのScore→Predictから予測処理の実行ができます。
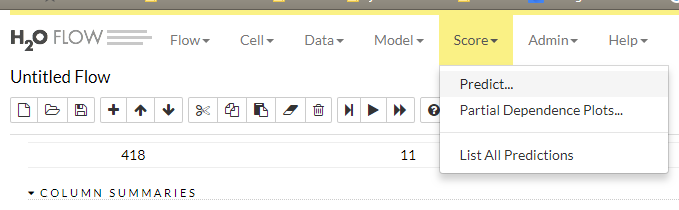
Modelは先程作成したランダムフォレストのモデルを選択。
Frameとして予測させたいデータが登録されているtest.hexを選択します。
あとはPredictを実行して結果を確認。
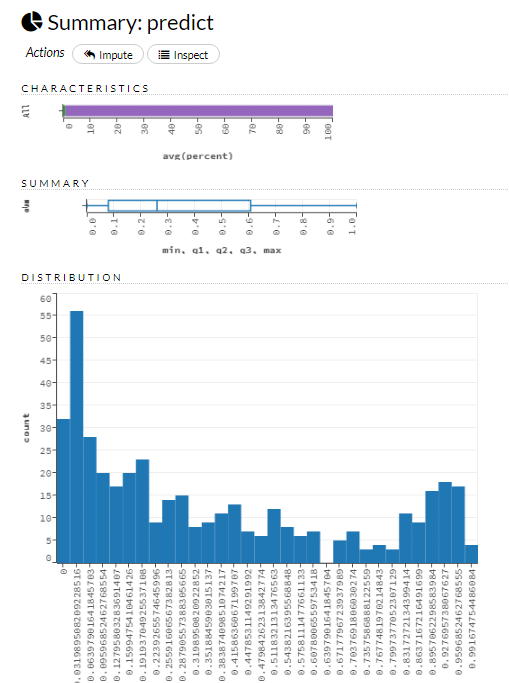
生存率のフラグが各乗客毎にどのような数値になりそうかの予測値が導かれています。
1により近い数値が出ているデータが生存すると予測されているものになっているのかと思います。(あまり細かいデータの見方までは把握しきれてないので今後の課題)
予測結果のデータはダウンロードも可能。

まとめ
とりあえず何の調整もせずに動かすだけなら非常に手間かからず便利に実行できます。
今回は試せてないですが、モデルを自分で選択するのではなく、AutoMLということでトレーニングデータとかを読み込ませてやれば自動で複数のモデルで分析処理をかけてくれる機能もあります。
モデルの選択とか検討する場合には非常に便利じゃないでしょうか。