先日、Neo4jの認定プロフェッショナルを取得し、ますますNeo4j(グラフDB)への興味が高まりつつあります。
「グラフデータベースでできることって、結局はRDBでも同じようなことできるし。。」といった意見も多いかと思いますが、現実世界の事象をより直感的に扱えるなど、良い点もあるのではないかと考えています。
ということで、グラフデータベースを使うことによるメリットをシステム運用の世界を題材に体験してみます。
グラフデータベースとは?
ノードとリレーションおよびその内容を示すプロパティで表現されるグラフ構造を扱うことができるデータベースです。関係性を表現するのに非常に扱いやすいものかと思います。
現実の世界で見ると、あらゆるものが何らかの関係性を持って働いています。人と人との関係性、人と会社の関係性、道路、電車、ユーザと取引履歴、等々。
いろいろと他に参考になる情報はあるので細かいところは割愛します。
参考: Graph DBとはなにか
試したこと
システム運用の世界だと、ネットワークの構成、サーバ構成等々構成情報の管理には非常に適しているのではないかと思います。
今回は、お試しということでLinuxサーバにインストールされているソフトウェア・ミドルウェア等のパッケージの依存関係のデータを収集し、Neo4jに登録、パッケージ間の関係性やパッケージの重要度などを分析してみます。
パッケージの依存関係情報の抽出
今回は、rpmインストールされているものに限定し、パッケージとそのパッケージが依存しているパッケージの情報を吸い出します。
こんな感じのスクリプトを一度流して、以下のようなCSV形式でパッケージとそのパッケージが依存するパッケージのリストを生成します。
# !/bin/bash
echo "package,depend_package"
IFS=$'\n';
for PACKAGE in `rpm -qa`
do
depend_list=()
for DEPEND in `rpm -q --requires ${PACKAGE} | cut -d ' ' -f 1`
do
pkg=`rpm -q --whatprovides ${DEPEND}`
if [ $? -eq 0 ]; then
depend_list=("${depend_list[@]}" ${pkg})
fi
done
for depend in `echo "${depend_list[*]}" | sort | uniq`; do
if[ ${PACKAGE} != ${depend} ]; then
echo "${PACKAGE},${depend}"
fi
done
done
$ bash get_package_dependlist.sh > package.csv
package,depend_package
gmp-4.3.1-13.el6.x86_64,glibc-2.12-1.212.el6.x86_64
gmp-4.3.1-13.el6.x86_64,libgcc-4.4.7-23.el6.x86_64
gmp-4.3.1-13.el6.x86_64,libstdc++-4.4.7-23.el6.x86_64
coreutils-8.4-47.el6.x86_64,bash-4.1.2-48.el6.x86_64
coreutils-8.4-47.el6.x86_64,coreutils-8.4-47.el6.x86_64
Neo4jに取り込み
Neo4jにはCSVからデータをロードできる機能があります。
作成したpackage.csvをNeo4jのサーバ上に配置し、以下のようなCypherクエリでLoadします。
このとき、ノードにはラベル「Package」を付与し、プロパティのnameにパッケージ名を設定します。
LOAD CSV WITH HEADERS FROM "file:/packages.csv" AS line
MERGE (a:Package { name: line.package })
MERGE (b:Package { name: line.depend_package })
MERGE (a)-[:depend]->(b)
/var/lib/neo4j/importにpackages.csvを配置し、各行を取り出し、packageとdepend_packageをそれぞれノードとして登録し、packageからdepend_packageにdependのリレーションを付与しています。
出来上がるとこんな感じです。
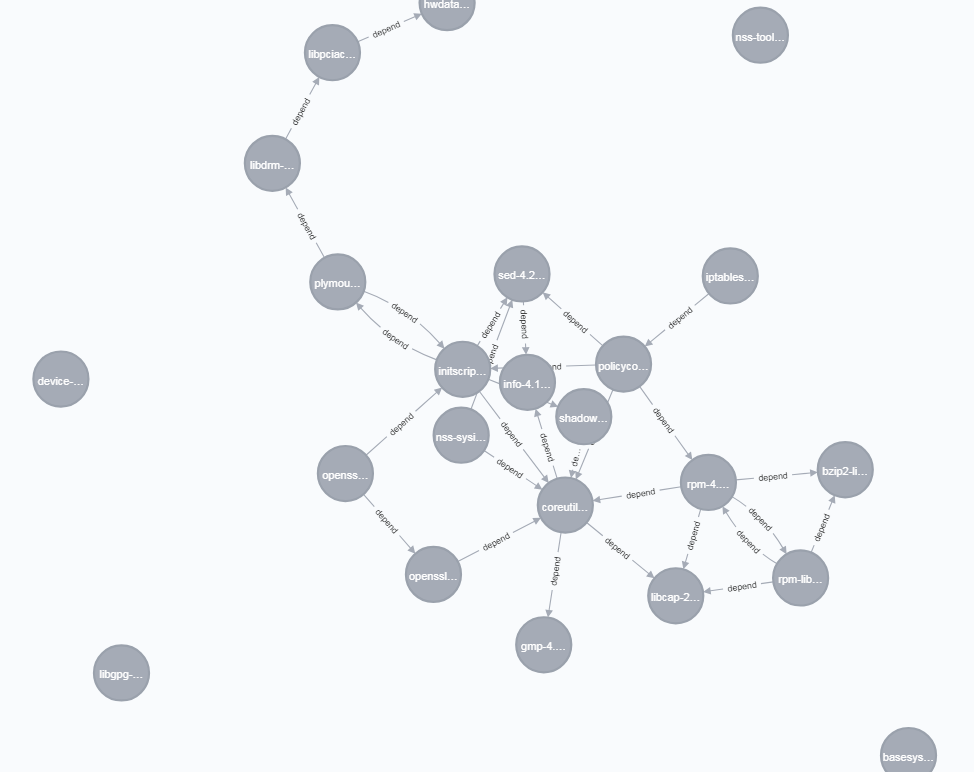
いろいろと分析をしてみる
グラフDBに入ってしまえばいろんな分析ができます。
まずは簡単なところから。
パッケージAが依存しているパッケージと、さらにその依存パッケージが依存しているパッケージを確認
単純に一つの依存先だけなら先程のスクリプトのようにrpmコマンドとかで簡単に確認できますが、もう1ステップ先までみるとなるとちょっと手間なのでグラフDBにいれて簡単に取り出してみます。
パッケージmariadb-server-5.5.56-2.el7.x86_64の依存関係を取得するクエリ
MATCH (a:Package)-[r*1..2]->(b:Package) WHERE a.name = "mariadb-server-5.5.56-2.el7.x86_64" RETURN a,r,b
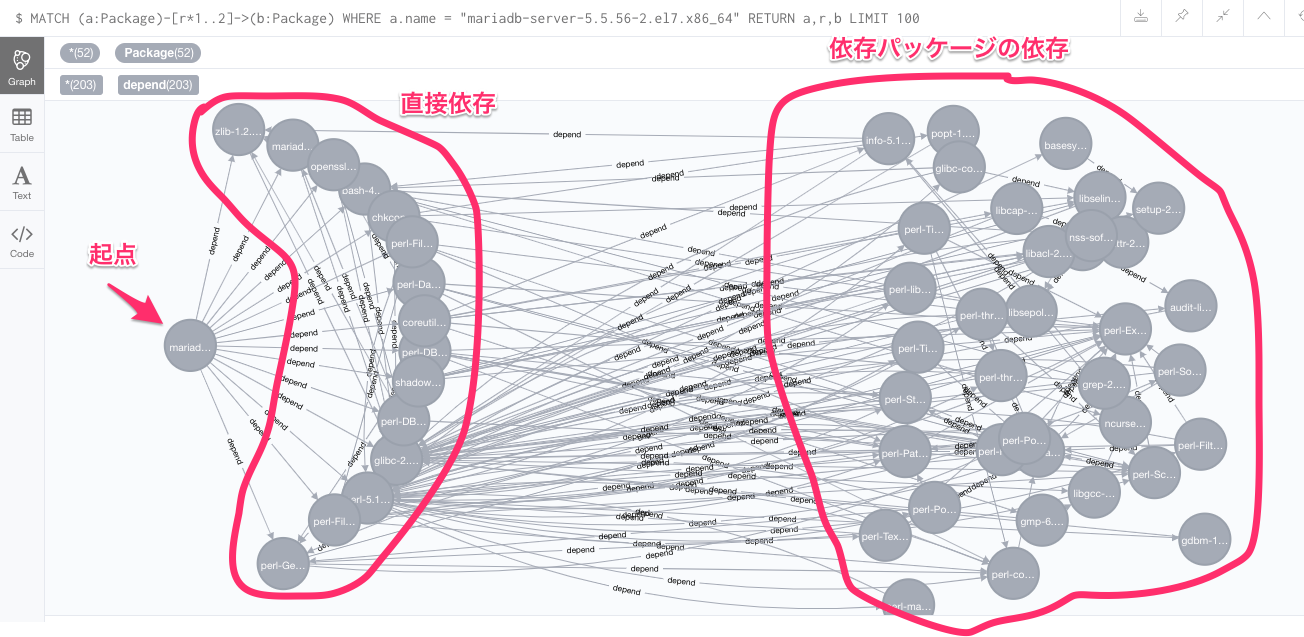
こんな感じで直接依存しているものと、さらにその先の依存しているものが抽出できます。
依存の多いパッケージのトップ5を確認
依存され度合いの高いパッケージのトップ5を確認してみます。
依存され度合いは、ノードへの入力dependリレーションの件数をカウントすればわかります。
件数をカウントしてorder byで多い順に並べ替えてlimit 5件取得で簡単に調べることができます。
MATCH (n:Package)<-[r:depend]-() RETURN n.name,count(r) AS depend_count ORDER BY depend_count DESC LIMIT 5
| name | depend_count |
|---|---|
| glibc-2.17-222.el7.x86_64 | 241 |
| bash-4.2.46-29.el7_4.x86_64 | 96 |
| perl-5.16.3-292.el7.x86_64 | 59 |
| zlib-1.2.7-17.el7.x86_64 | 56 |
| perl-Carp-1.26-244.el7.noarch | 41 |
glibcはいろいろなパッケージから依存されているのがわかりますね。
依存され度合いだけじゃなく、依存しているパッケージの数が多いものを調べるのみ上記の矢印方向を変えるだけで簡単にチェックできます。
MATCH (n:Package)-[r:depend]->() RETURN n.name,count(r) AS depend_count ORDER BY depend_count DESC LIMIT 5
このあたりがチェックできると、パッケージの変更時等に留意すべき対象がどのパッケージであるかなどさくっと確認できそうです。
似ているパッケージを探す
最後はちょっと応用です。パッケージ間で関係性が似ているものを探してみます。
関係性が似ているの定義として、今回は***「依存関係を持つ先のパッケージが同様のものは似ている」***とします。
例えば、パッケージAはパッケージC,D,Eに依存している、パッケージBはパッケージC,D,Fに依存しているといった場合、CとDの2つのパッケージが共通的に依存しています。
この度合いを、Overlap Similarityのアルゴリズムで算出してみます。
Overlap Similarityは以下の記事で解説されている「Simpson係数(Overlap coefficient)」と呼ばれる係数を算出するアルゴリズムです。
式としては以下のようになります。
パッケージAの依存するパッケージの集合AとパッケージBの依存するパッケージの集合Bとした時の係数(overlap(A,B))は以下の式で求められます。
overlap(A,B) = \frac{| A \cap B |}{min(|A|,|B|)}
Neo4jは様々なグラフアルゴリズムを簡単に算出するためのプラグインが提供されています。
このプラグインを使うと、以下のページで解説されているようなグラフ同士の類似性のチェックやクラスタの検出などが実現できます。
- https://neo4j.com/docs/graph-algorithms/current/algorithms/similarity/
- https://neo4j.com/docs/graph-algorithms/current/algorithms/community/
graph algorithmsのプラグインの導入
まずは、算出を試す前にプラグインを導入して使えるようにします。
1. プラグインのjarファイルをダウンロード・配置
上記URLからjarをダウンロードします。
ダウンロードしたjarをNeo4jの導入サーバ内のNeo4jホームディレクトリ(/var/lib/neo4j)配下のpluginsに配置します。
$ cp graph-algorithms-algo-3.5.0.1.jar /var/lib/neo4j/plugins
2. neo4jの設定ファイルの変更
設定ファイル(/var/lib/neo4j/conf/neo4j.conf)にプラグインを読み込むための設定を行います。
・・・略
dbms.security.procedures.unrestricted=algo.\*
あとはNeo4jを再起動すればOKです。
類似性の分析
この状態で、以下の1Cypher queryを発行すれば指定のパッケージに類似しているもののスコアが簡単に算出できます。
MATCH (n:Package {name: "libcurl-7.19.7-53.el6_9.x86_64"})-[:depend]->(a)
MATCH (m:Package)-[:depend]->(b)
RETURN m.name AS package_name, algo.similarity.overlap(collect(distinct id(a)), collect(distinct id(b))) AS similarity ORDER BY similarity DESC LIMIT 10
ポイントは、algo.similarity.overlapという関数を呼び出しているところです。
先程のプラグインが有効になることで、algo.xxxという様々な関数が利用できるようになっています。
この中でOverlap Similarityのスコア算出用の関数がalgo.similarity.overlapです。この関数に2つの数値配列を渡すと、重複度合いをチェックしてスコア算出してくれます。
この時、配列には数値が登録されている必要があります。文字列の配列には対処していないので、上記例のように、ノードの名前ではなく、ノードのid情報の一覧を渡しています。
結果は以下のようになります。
| package_name | similarity |
|---|---|
| bridge-utils-1.2-10.el6.x86_64 | 1.0 |
| libattr-2.4.44-7.el6.x86_64 | 1.0 |
| e2fsprogs-libs-1.41.12-24.el6.x86_64 | 1.0 |
| libudev-147-2.73.el6_8.2.x86_64 | 1.0 |
| db4-4.7.25-22.el6.x86_64 | 1.0 |
| ethtool-3.5-6.el6.x86_64 | 1.0 |
| numactl-2.0.9-2.el6.x86_64 | 1.0 |
| zlib-1.2.3-29.el6.x86_64 | 1.0 |
| nspr-4.19.0-1.el6.x86_64 | 1.0 |
libcurlパッケージの依存先は以下。
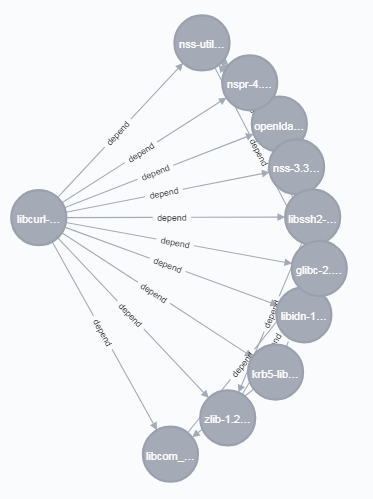
bridge-utilsパッケージの依存先は以下。
今回はあまり良い例ではないですね。。bridge-utilsの依存先パッケージはglibcのみで、そのglibcにlibcurlも依存しているため、1/1で1.0という結果に。。
Overlap Similarityは依存先パッケージが少ない方に合わせて計算するので上記のような結果に。
このアルゴリズムの場合、極端に少ないものがある場合その内容にひっぱられてしまうのでもう一つ別のJaccard係数を元にした類似度計算を行ってみます。
クエリは先程の関数をalgo.simirality.overlapをalgo.simirality.jaccardに変えるだけ。
このアルゴリズムでは以下の式で算出するので、一方の1依存パッケージのみだけであっても、その合算値で計算されるのでもう少しそれっぽいのが出てきそうです。
J(A,B) = \frac{| A \cap B |}{| A \cup B |}
MATCH (n:Package {name: "libcurl-7.19.7-53.el6_9.x86_64"})-[:depend]->(a)
MATCH (m:Package)-[:depend]->(b)
RETURN m.name AS package_name, algo.similarity.jaccard(collect(distinct id(a)), collect(distinct id(b))) AS similarity ORDER BY similarity DESC LIMIT 10
| package_name | similarity |
|---|---|
| libcurl-7.19.7-53.el6_9.x86_64 | 1.0 |
| curl-7.19.7-53.el6_9.x86_64 | 0.9090909090909091 |
| nss-tools-3.36.0-8.el6.x86_64 | 0.45454545454545453 |
| openssh-5.3p1-123.el6_9.x86_64 | 0.375 |
| openssh-clients-5.3p1-123.el6_9.x86_64 | 0.35294117647058826 |
| nss-sysinit-3.36.0-8.el6.x86_64 | 0.3076923076923077 |
| libkadm5-1.10.3-65.el6.x86_64 | 0.3 |
| openssl-1.0.1e-57.el6.x86_64 | 0.2857142857142857 |
| openldap-2.4.40-16.el6.x86_64 | 0.26666666666666666 |
| nss-softokn-3.14.3-23.3.el6_8.x86_64 | 0.25 |
libcurl自分自身とは当然1.0になるとして、その次に高いのがcurlパッケージとなり、似たようなライブラリを利用してるのがわかる結果になりました。
まとめ
自然界の状態をグラフで表現することで、いろいろな視点から分析できる可能性が高まるような気がします。RDBMS使っても似たようなことはできるとは思いますが、データの持ち方として、グラフ構造に特化しているグラフDBはよりすばやく必要な結果を得ることに繋がるので、活用しどころはあると思います。