MLflow
MLflowはオープンソースで、機械学習処理のライフサイクル管理を行うソフトウェアです。Kubernetesで管理している環境だとKubeflow、AWSならSageMakerとか、この分野の用途で利用できるものはいろいろあるかと思いますが、OSSでいろんなシーンで適用できそうです。
現時点(2018/10/03)でバージョン0.7というのがリリースされており、絶賛開発中のようです。
MLflowは、要素として3つで構成されています。
- MLflow Tracking : 学習の実行履歴管理
- MLflow Projects : 学習処理の実行定義
- MLflow Models : 学習モデルを用いたAPIサーバの実行定義
MLflow Tracking
学習モデル生成時に、生成されたモデルの実体や学習モデルの評価結果のスコア情報等を記録し、履歴管理する機能です。
学習処理用のコードに簡単なコードを追加するだけで、自動的に実施時間情報やバージョン等様々な情報を記録してくれます。
インストール
MLflowのインストールは以下のようにpipで簡単に入ります。
$ pip install mlflow
Trackingの管理を行うには、Tracking serverを起動する必要があります。
$ mlflow server --file-store /mlflow --port 5000 --host 0.0.0.0
「http://TrackingServerIP:5000」
デフォルトでポート5000番でサーバが稼働するのでそちらにアクセス。
すると、過去にどういったハイパーパラメータおよびどのコードでモデルが生成され、その時のスコアがどうだったか等のリストが表示されるWeb UIにアクセス可能です。
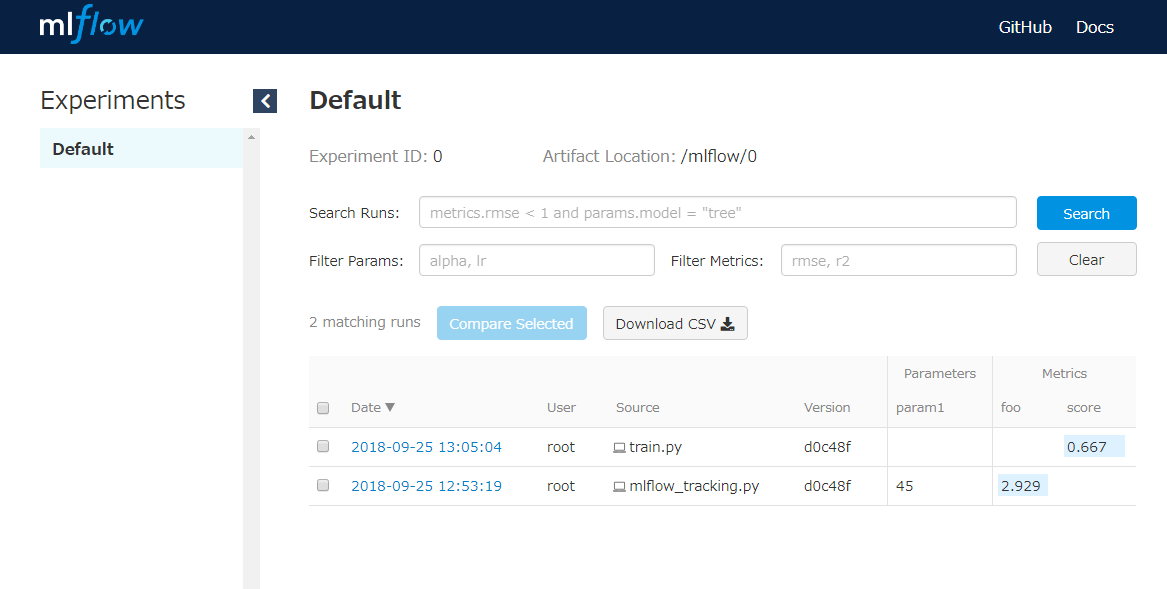
Trackingデータは大きく4つの要素から成り立っています。
- Parameters : モデル学習時のハイパーパラメータの管理用要素
- Metrics : 学習モデルの状態を示すスコア情報等の管理用要素
- Tags : 学習モデルを識別の管理のための任意のタグ要素
- Artifacts : 学習により生成されるモデル等の生成物管理用要素
学習用のコード内で以下のように組み込むことで、状況の各要素をTracking Serverの管理下に置くことができます。
サンプルとして、以下のようなRandomForest分析を行うコードがあるとします。
# !/usr/bin/python3
import sklearn.datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# parameter
n_estimators = 15
max_depth = 3
random_state = 71
# iris dataを分類してみる
iris = sklearn.datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=random_state)
# RandomForestClassifierを利用して学習
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=random_state)
model.fit(X_train, y_train)
# 予測結果確認
print(model.predict(X_test))
# 精度情報確認
print(model.score(X_test, y_test))
このとき、scikit-learnのRandomForestClassifier実行時に引き渡すハイパーパラメータ(上記例だと、n_estimators、max_depth、random_state)、生成されたモデル(上記例だと、model(sklearn.ensemble.forest.RandomForestClassifierクラス))、精度情報(上記例だとscore)を実行の都度管理したいとします。
その場合、mlflowのライブラリをコードに読み込み、以下のようにmlflow.log_param、mlflow.sklearn.log_model、mlflow.log_metricを使って記録できます。このときの注意点として、set_tracking_uriを記録の前に呼び出し、先程起動したTracking ServerのURIを指定しておく必要があります。これを忘れると、起動したTracking serverの管理下とは無関係で、分析コードを実行したローカルに./mlrunsというディレクトリが作成され、その配下で管理されることになります。
# !/usr/bin/python3
import sklearn.datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
# parameter
n_estimators = 15
max_depth = 3
random_state = 71
# iris dataを分類してみる
iris = sklearn.datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=random_state)
# RandomForestClassifierを利用して学習
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=random_state)
model.fit(X_train, y_train)
# 予測結果確認
print(model.predict(X_test))
# 精度情報確認
score = model.score(X_test, y_test)
# MLflowに記録
mlflow.set_tracking_uri('http://localhost:5000')
mlflow.start_run()
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
mlflow.log_param("random_state", random_state)
mlflow.log_metric("score", score)
mlflow.sklearn.log_model(model, "ml_models")
mlflow.end_run()
このコードを実行します。
$ python learning_job.py
実行後に改めて画面を確認すると、1件、作成したコードにより生成された実績情報が保存されているのがわかります。
parameters、metrics、artifactsがそれぞれ管理されているのが確認できます。(今回tagは使っていません)
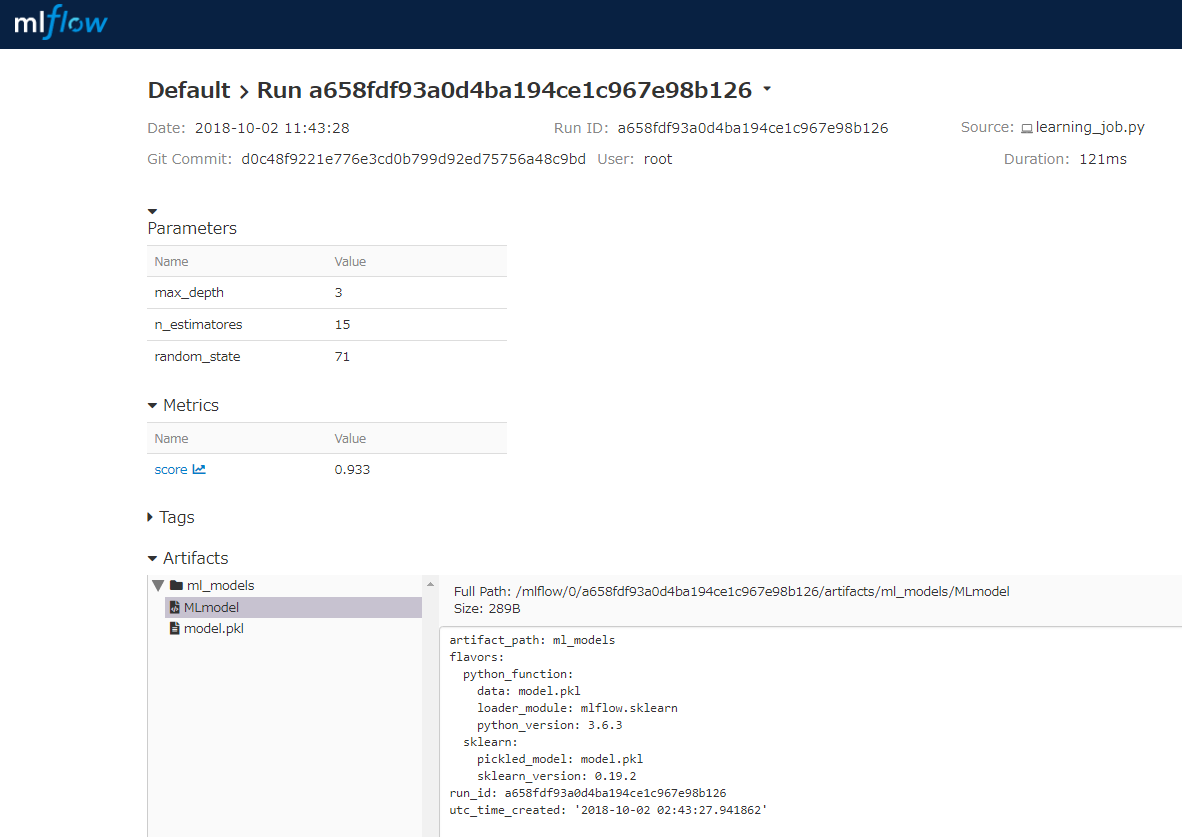
変数の値を変更して何度か試すと以下のようにその都度、run_idとセットでその実行時の情報が自動的に記録されていくことになります。
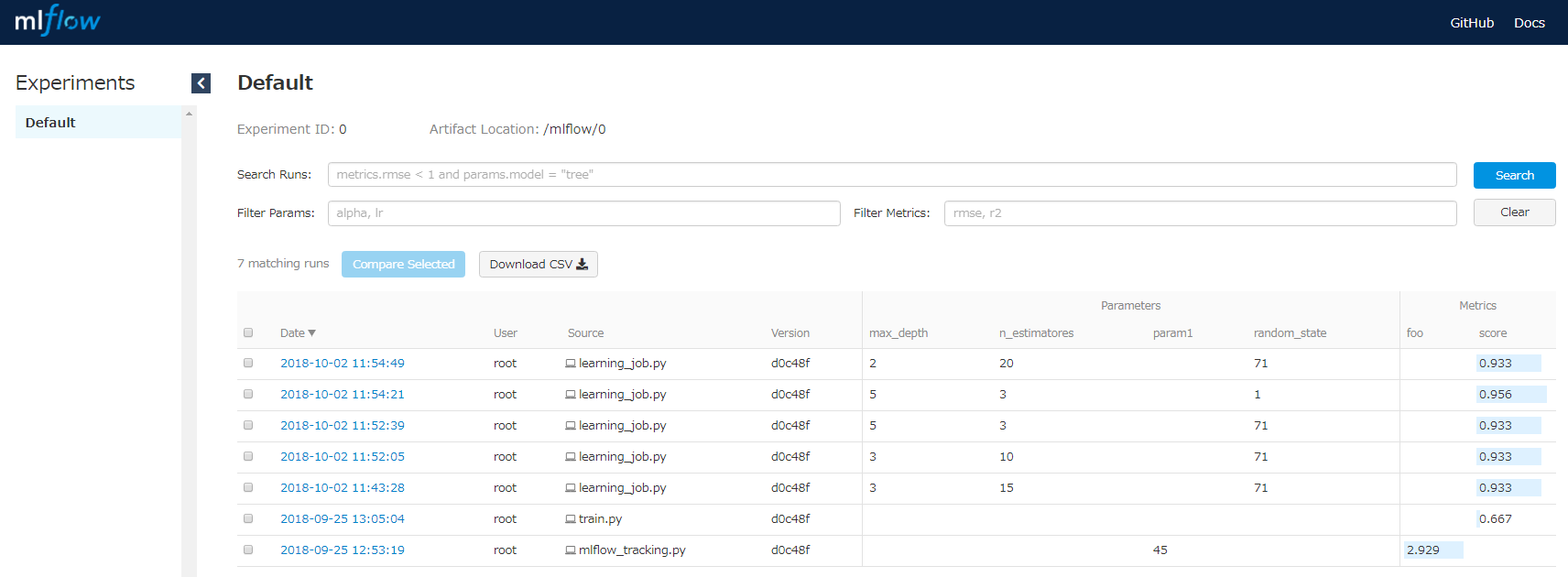
MLflow Projects
先程は手動でpythonコマンドでスクリプトを実行して学習を行いましたが、MLflow Projectsの機能を使うと、学習処理の実行環境を自動構築し学習処理を実行させることができます。
例えば以下のようにProjectsの定義ファイル(MLproject)を作成します。
name: ProjectA
conda_env: conda.yaml
entry_points:
main:
parameters:
n_estimators: {type: float, default: 10}
max_depth: {type: float, default: 5}
random_state: {type: float, default: 71}
command: "python learning_job.py {n_estimators} {max_depth} {random_state}"
先程作成した学習モデルの生成用コードのパラメータ部分をProjects定義に切り出しています。
学習コードの実行環境の情報をconda.yamlに記載します。
name: ProjectA
channels:
- defaults
dependencies:
- python=3.6.3
- numpy=1.14.5
- pandas=0.23.3
- scikit-learn=0.19.2
- pip:
- mlflow
学習用コード(learning_job.py)を引数を読み込んで実行するように変更します。
# !/usr/bin/python3
import sklearn.datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
import sys
# parameterを読み込み
n_estimators = int(sys.argv[1]) if len(sys.argv) > 1 else 10
max_depth = int(sys.argv[2]) if len(sys.argv) > 2 else 5
random_state = int(sys.argv[3]) if len(sys.argv) > 3 else 71
# iris dataを分類してみる
iris = sklearn.datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=random_state)
# RandomForestClassifierを利用して学習
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=random_state)
model.fit(X_train, y_train)
# 予測結果確認
print(model.predict(X_test))
# 精度情報確認
score = model.score(X_test, y_test)
# MLflowに記録
mlflow.set_tracking_uri('http://localhost:5000')
mlflow.start_run()
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
mlflow.log_param("random_state", random_state)
mlflow.log_metric("score", score)
mlflow.sklearn.log_model(model, "ml_models")
mlflow.end_run()
この状態でProjectを実行してみます。
$ mlflow run random_forest_sample -P n_estimators=15 -P max_depth=2 -P random_state=71
conda.yamlに書かれた環境を自動でインストールされ、指定したパラメータを元に学習処理が自動実行されます。
(手元の環境では少しエラーが出てTracking server uriをリモートサーバに設定するとAPI呼び出しに失敗しました。。動作は確認中ですが、localにモデルを保存するように実行する場合は問題ないです。)
MLflow Models
ここまでで、学習モデルの管理ができました。
あとは、学習で生成されたモデルに対するAPIサーバを立ててみます。
モデルを使ってAPIサーバを立てる機能がMLflow Modelsです。
Tracking APIを用いて学習結果のモデルを保存すると、pickleで保存されたモデルの実体(model.pkl)とセットで、自動的にこのモデルの定義ファイル(MLmodel)も生成されます。
内容は以下のような感じです。
artifact_path: ml_models
flavors:
python_function:
data: model.pkl
loader_module: mlflow.sklearn
python_version: 3.6.3
sklearn:
pickled_model: model.pkl
sklearn_version: 0.19.2
run_id: ed89791b038c49c0bea7053bd486cc77
utc_time_created: '2018-10-02 09:24:32.403696'
flavorsとしてmodelの稼働環境が定義されています。
この例だと、sklearnというflavorでmodel.pklが管理されることになるため、mlflowのコマンドを使い以下のようにModelを読み込んだAPIサーバを立ち上げることができます。
$ mlflow sklearn serve -p 11111 -m /mlflow/mlruns/0/ed89791b038c49c0bea7053bd486cc77/artifacts/ml_models
Run IDがed89791b038c49c0bea7053bd486cc77の試行でできたモデルをsklearnフレーバーで読み込んで起動という感じです。
起動すると、上記の場合、11111ポートでModel用のAPIサーバがリッスンします。
あとは、11111ポートに対してデータを引き渡してinvocationsAPIを呼び出せば学習モデルを通して得られた結果が出力されるという流れです。
$ curl -XPOST -H "Content-Type:application/json" --data '[{"sepal_length":5.1,"sepal_width":3.2,"petal_length":1.5,"petal_width":0.3}]' "http://localhost:11111/invocations"
{"predictions": [2]}
作成されているモデルが、入力としてirisの特徴量4件を取るようなモデルのため、上記のようにPOSTデータを送付することで学習にかけた結果が返ってきます。
発展1: 学習時の他の生成物もセットで管理
例えば、学習モデルを生成したときの画像データや、ラベルリストのPythonオブジェクト等を学習モデルと紐づけて管理したい場合、以下のように一旦ファイルに書き出された内容をartifactとして複製して管理することができます。
import pickle
・・・略
labels = ['a', 'b', 'c', 'd']
with open('/tmp/label.list', mode='wb') as f:
pickle.dump(labels, f)
・・・略
mlflow.log_artifact('/tmp/label.list')
このように記録したartifactを、別のPythonプログラムから呼び出すにはMLflowのPytyon APIを活用します。
run_idとtracking server urlを指定して、modelを呼び出し、artifactに記録したlabel.listのオブジェクトを読み込んで表示は以下のように実現できます。
# !/usr/bin/python
import mlflow
import mlflow.sklearn
import mlflow.tracking
import pickle
tracking_uri = 'http://localhost:5000'
run_id = '8da8496ab64a46988996cb94837b6faf'
mlflow.set_tracking_uri(tracking_uri)
client = mlflow.tracking.MlflowClient()
# 保存済みのsklearnモデルを呼び出し
model = mlflow.sklearn.load_model("ml_models", run_id=run_id)
# 保存済みのartifactの一覧を表示
for artifact in client.list_artifacts(run_id=run_id):
print(artifact.path)
# 保存済みのartifactの中でlabel.listのファイルを読み込みpickleでloadしPythonオブジェクト化
with open(client.download_artifacts(run_id=run_id, path='label.list'), mode='rb') as f:
labels = pickle.load(f)
print(labels)
# 呼び出したモデルに対してpredict
print(model.predict([[3.1,2.2,3.0,1.3]]))
発展2: 保存されている学習実績の中からscoreの高いものを選択してロード
機械学習のスコア等をMetricsとして管理できるため、その結果をもとに必要なモデルをロードして機械学習APIを実装するといったことも可能です。
searchというAPIのメソッドが提供されています。
現時点では、PythonAPIとしては実装されておらず、REST APIのみの提供のようです。
今後の実装としては、Python APIのget_runのオプションとして検索できるような仕組みが検討されているようです。GitHub Issue #246
REST APIを使ってMetricのscoreが0.93以上の試行の情報のみをピックアップするには以下のようにリクエストします。
$ curl -XPOST http://localhost:5000/api/2.0/preview/m
lflow/runs/search -H "Content-Type: application/json" --data '{"experiment_ids":
[0],"anded_expressions":[{"metric":{"key":"score","double":{"comparator":">","va
lue":0.93}}}],"run_view_type":"ACTIVE_ONLY"}'
api/2.0/preview/mlflow/runs/searchがメソッドのエンドポイントURL。
送付するデータを整形すると以下のような感じです。
{
"experiment_ids": [
0
],
"anded_expressions": [
{
"metric": {
"key": "score",
"double": {
"comparator": ">",
"value": 0.93
}
}
}
],
"run_view_type": "ACTIVE_ONLY"
}
応答結果は以下のように返ってきます。
{
"runs": [
{
"info": {
"run_uuid": "8da8496ab64a46988996cb94837b6faf",
"experiment_id": "0",
"name": "",
"source_type": "LOCAL",
"source_name": "learning_job.py",
"user_id": "root",
"status": "FINISHED",
"start_time": "1538526828910",
"end_time": "1538526829016",
"artifact_uri": "/mlflow/0/8da8496ab64a46988996cb94837b6faf/artifacts",
"lifecycle_stage": "active"
},
"data": {
"metrics": [
{
"key": "score",
"value": 0.9333333333333333,
"timestamp": "1538526828"
}
],
"params": [
{
"key": "random_state",
"value": "71"
},
{
"key": "n_estimators",
"value": "15"
},
{
"key": "max_depth",
"value": "3"
}
]
}
},
{
"info": {
"run_uuid": "6dc25a27f9254efba2c61a0ca14c3bb3",
"experiment_id": "0",
"name": "",
"source_type": "LOCAL",
"source_name": "learning_job.py",
"user_id": "root",
"status": "FINISHED",
"start_time": "1538526812635",
"end_time": "1538526812742",
"artifact_uri": "/mlflow/0/6dc25a27f9254efba2c61a0ca14c3bb3/artifacts",
"lifecycle_stage": "active"
},
"data": {
"metrics": [
{
"key": "score",
"value": 0.9333333333333333,
"timestamp": "1538526812"
}
],
"params": [
{
"key": "random_state",
"value": "71"
},
{
"key": "n_estimators",
"value": "15"
},
{
"key": "max_depth",
"value": "3"
}
]
}
}
]
}
まとめ
機械学習のモデルの管理ツール・サービスは様々ありますが、OSSで柔軟性に富んだものとしてはMLflowも便利に使えるケースがあるかもしれないと思いました。まだまだ開発途中のようなので未実装の部分も多いですが、今後の開発が楽しみです。