ー はじめに ー
もし、この記事を読む読者の方がアニメ好きならば、「涼宮ハルヒの憂鬱」の名を知らぬ人はいないでしょう。
今回は後世に名を残した「エンドレスエイト」より、絵コンテ・演出家、作画監督をディープラーニングで認識することができるのかを検証していきたいと思う。
### ☆「涼宮ハルヒの憂鬱」を知らない方へ 涼宮ハルヒの憂鬱とは原作者:谷川 流氏、角川スニーカー文庫から刊行されているSF系学園ストーリー(筆者談、諸説あり)
2009年4月から放映されたアニメ2期「涼宮ハルヒの憂鬱」にて、世間を騒がす大事件が起きました。
「エンドレスエイト」
原作である「涼宮ハルヒの暴走」の名が指し示す通り、アニメ涼宮ハルヒの憂鬱が暴走を起こし、全く同じ内容を8週にかけて放映しました。
今回はその8回分の同じ内容のアニメを活用し、ディープラーニングの能力を検証していきたいと思います。

蛇足にはなりますが「涼宮ハルヒの憂鬱」の名誉の為、書いておきます。
エンドレスエイトの各8話は8回制作され、8回収録されたものであり、決して使い回しではありません。賛否両論ありますが、映像や声優の演技は違うので、色々な楽しみ方ができます。
興味を持った方は是非、アニメ「涼宮ハルヒの憂鬱」をご視聴下さい!
さらに詳しく知りたい方は原作「涼宮ハルヒシリーズ」を講読下さい!
また、今回は検証を行う上である程度のネタバレが含まれます。
純粋に「涼宮ハルヒの憂鬱」を楽しみたい方は2期の全話28話(2期は1期の14話を含む。ハイビジョン版のなので絵が綺麗)の視聴をオススメします。
ー 検証の動機 ー
前回「Deep Learningで長門有希を画像認識させたい」を作成する為、改めて「涼宮ハルヒの憂鬱」の情報を集めたのですが、おもしろい事実を発見しました。
エンドレスエイトⅠ
作画監督: 米田光良
絵コンテ・演出家:高橋真梨子
エンドレスエイトⅡ
作画監督: 荒谷朋恵
絵コンテ・演出家:西屋太志
エンドレスエイトⅢ
作画監督: 三好一郎
絵コンテ・演出家:高橋博行
エンドレスエイトⅣ
作画監督: 高雄統子
絵コンテ・演出家:植野千世子
エンドレスエイトⅤ
作画監督: 荒石原立也
絵コンテ・演出家:池田和美
エンドレスエイトⅥ
作画監督: 北之原孝将
絵コンテ・演出家:門脇未来
エンドレスエイトⅦ
作画監督: 石立太一
絵コンテ・演出家:秋竹斉一
エンドレスエイトⅧ
作画監督: 米田光良
絵コンテ・演出家:高橋真梨子
つまり!
1話〜7話の絵コンテ・演出家、作画監督は違う。
1話と8話は同じ絵コンテ・演出家、作画監督である。
1話〜8話の内容の構成はほぼ同じ。
ということが分かりました。
この事実を知って筆者は思いました。
1〜7話を判別するモデルを作って、8話目を認識させるとどうなるんだろう?
普通の人にエンドレスエイトの1〜7話を見せ、その後に8話目を流し「さて、今回の話と同じ作画監督、絵コンテ・演出家が作ったのは何話目でしょう?」と質問したとしても、運以外で正解できる人はまずいないと思います。
しかし、人間が見つけられない特徴を見つけ、学習することができるディープラーニングであれば、正解することが出来るのではないか。
同じキャラクター、同じストーリー、同じ構成の作画から、各絵コンテ・演出家、各作画監督の構図の癖や描き方の特徴を見出すことができるのではないか。
筆者は機械学習に片足のつま先だけを浸した程度の知識しかないので、画像認識による分類を使い検証します。
この疑問を払拭するために、検証を行っていこうと思います。
ー 検証目標 ー
①エンドレスエイト1〜7話の画像を学習させ、各話に分類するモデルを作成する。
②エンドレスエイト8話目の画像をモデルに与え、その結果、何話目に分類されるのか検証する。
# ー 検証環境 ー macOS Big Sur 11.5.2 Python 3.9.7 Keras 2.6.0 tensorflow 2.6.0 VSCode
# ー 検証手順 ー
1、エンドレスエイト8話分の画像をとにかく集める。
2、1〜7話目の画像を水増しし、ラベル付けし、学習モデルを作成する。
3、エンドレスエイト8話目の画像をモデルに与えて結果を見る。
4、検証結果に一喜一憂する。
それでは早速、検証開始!
1、エンドレスエイト8話分の画像をとにかく集める。
以前モデル作成をした際はスクリーンショットで集めましたが、流石に精神が崩壊しそうだったので以前に使ったコードを使います。
import os
import pyautogui
import time
start = time.time()
for l in range(1,8):
for i in range(494):
im = pyautogui.screenshot('./test3/' + str(l) +'_'+ str(i) + '.png', region=(499,600,1300,742))
time.sleep(3)
end = time.time()
print('result time is :', end - start)
ちなみにこのコード、実際やると分かりますが、コード実行からの動画スタートタイミングまでの時間誤差などの影響で、実は綺麗に各話数ごとにファイル名が付かなかったりします。
なので、range数を多くして実行し、動画が終わったらで手動でコードを止めた方が確実に楽です。
筆者は心配性なので、各話終わる毎に止めてファイルにまとめてました。
詳しくはこちらの記事を参照してください。

こんな感じに切り抜きます。
2、1〜7話目の画像を水増しし、ラベル付けし、学習モデルを作成する。
データの水増し、ラベル付け、学習モデル作成までは前回作った時の方法をそのまま使いました。詳しくはDeep Learningで長門有希を画像認識させたい。の記事でご確認ください。
完成したモデルの中で一番精度の良かったものがこちら
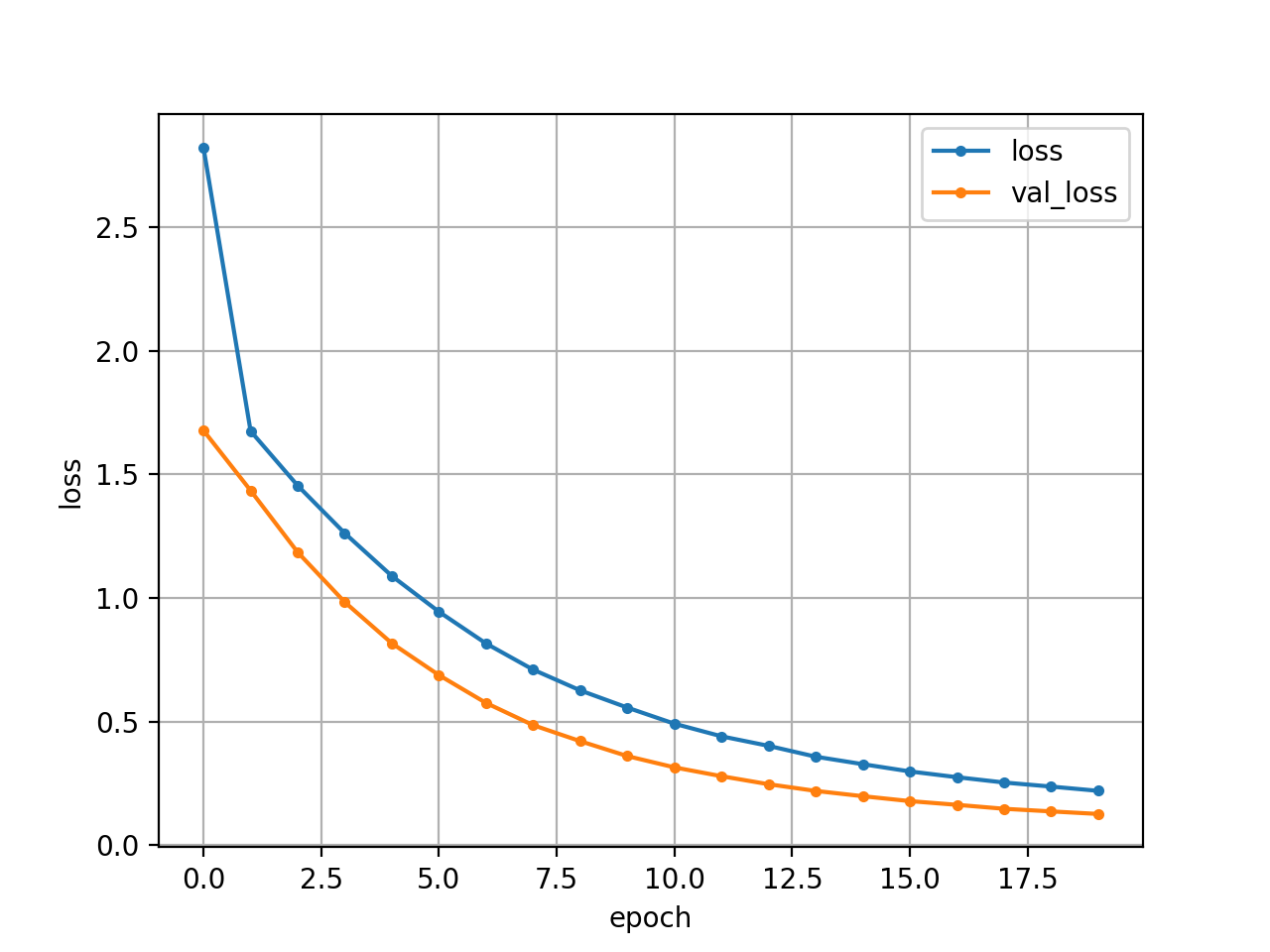
Test loss: 0.12673038244247437
Test accuracy: 0.9659311175346375
3、エンドレスエイト8話目の画像をモデルに与えて結果を見る。
ここから、作品のネタバレを含みますので、ご注意ください。
エンドレスエイト8話目の画像をモデルに与える前に全話の簡単な流れを確認し、全話共通のシーンを抜き出します。
各話の流れ一覧はこちら
**エンドレスエイト1話** ハルヒから電話→プール→喫茶店で夏休みの計画立てる→盆踊り→河川敷で花火→セミとり→バイト→天体観測→バッティングセンター→花火大会を見にいく→ハゼ釣り→肝試し→映画館→海水浴→ボーリング→カラオケ→夏休みの反省会→キョン帰宅→就寝
**エンドレスエイト2話** ハルヒから電話→プール→喫茶店で夏休みの計画立てる→解散後、キョン、長門を呼び止める→盆踊り→河川敷で花火→セミとり→バイト→古泉からの呼び出し→長門、ループを説明(15,498回目)→天体観測→バッティングセンター→肝試し→ボーリング→カラオケ→夏休みの反省会→デジャブ→キョン就寝
**エンドレスエイト3話** ハルヒから電話→プール→喫茶店で夏休みの計画立てる→盆踊り→河川敷で花火→セミとり→バイト→古泉からの呼び出し→長門、ループを説明(15,499回目)]→天体観測→バッティングセンター→花火大会を見に行く→ハゼ釣り→肝試し→映画→海水浴→ボーリング→カラオケ→夏休みの反省会→デジャブ→キョン就寝
**エンドレスエイト4話** ハルヒから電話→プール→喫茶店で夏休みの計画立てる→解散後、キョン長門を呼び止める→盆踊り→河川敷で花火→セミとり→バイト→古泉からの呼び出し→長門、ループを説明(15,513回目)→天体観測→バッセン→映画→夏休みの反省会→デジャブ→キョン就寝
**エンドレスエイト5話** ハルヒから電話→プール→喫茶店で夏休みの計画立てる→解散後、キョン長門を呼び止める→盆踊り→河川敷で花火→セミとり→バイト→古泉からの呼び出し→長門、ループを説明(15,521回目)→肝試し→雨宿り→公園で遊ぶ→夏休みの反省会→デジャブ→キョン就寝
**エンドレスエイト6話** ハルヒから電話→プール→喫茶店で夏休みの計画立てる→解散後、キョン長門を呼び止める→盆踊り→河川敷で花火→セミとり→バイト→古泉からの呼び出し→長門、ループを説明(15,524回目)→天体観測→バッティングセンター→花火大会→釣り→肝試し→海→映画→ボーリング→カラオケ→夏休みの反省会→デジャブ→キョン就寝
**エンドレスエイト7話** ハルヒから電話→プール→喫茶店で夏休みの計画立てる→解散後、キョン長門を呼び止める→盆踊り→河川敷で花火→セミとり→バイト→古泉からの呼び出し→長門、ループを説明(15,527回目)→天体観測→バッティングセンター→夏休みの反省会→デジャブ→キョン就寝
**エンドレスエイト8話** ハルヒから電話→プール→喫茶店で夏休みの計画立てる→解散後、キョン長門を呼び止める→盆踊り→河川敷で花火→セミとり→バイト→古泉からの呼び出し→長門、ループを説明(15,532回目)→バッティングセンター→雨の描写→夏休みの反省会→キョン起床→学校で小泉とポーカー
全話共通のシーン
- ハルヒから電話
- プール
- 喫茶店で夏休みの計画立てる
- 盆踊り
- 河川敷で花火
- セミとり
- バイト
- 夏休みの反省会
以上8シーンを抜き出し、学習済みモデルに与えてみます。
該当画像は検証1の手順で198枚用意する事ができました。
それでは、学習済みモデルにぶち込みましょう。
今回は数が多いので、数値で表示する様にします。
評価を行うためのコード
import cv2
from keras.models import load_model
import numpy as np
model = load_model("./endless_model.h5")
# 画像を一枚受け取り、何話目に近いかを判定する
def pred_gender(img):
img = cv2.resize(img,(64,64))
pred = np.argmax(model.predict(img.reshape(1,64,64,3)))
if pred ==0:
return "roop1"
elif pred == 1 :
return "roop2"
elif pred == 2 :
return "roop3"
elif pred == 3 :
return "roop4"
elif pred == 4 :
return "roop5"
elif pred == 5 :
return "roop6"
elif pred == 6 :
return "roop7"
# 用意した枚数分の名前リストを作る
listr = list(range(1,199))
listb = []
for a in listr:
listb.append("./loop8/x" +str(a)+".png")
# 結果を受け取るリストを作成
listc=[]
for i in listb:
img = cv2.imread(i,1)
img = cv2.resize(img,(64,64))
pred = np.argmax(model.predict(img.reshape(1,64,64,3)))
listc.append(pred)
# 各話の一致枚数を表示
for a in range(7):
print("エンドレスエイト{}話".format(a+1))
print(listc.count(a))
print()
# 結果一覧
print(listc)
評価結果は、
、
、
、
、
、
、
、
、
、
、
、
エンドレスエイト1話
48
エンドレスエイト2話
30
エンドレスエイト3話
33
エンドレスエイト4話
26
エンドレスエイト5話
20
エンドレスエイト6話
25
エンドレスエイト7話
16
[1, 2, 1, 0, 6, 1, 5, 0, 2, 5, 2, 2, 2, 2, 2, 2, 2, 0, 2, 5, 5, 1, 5, 0, 5, 2, 3, 3, 0, 0, 0, 0, 0, 3, 0, 5, 5, 2, 4, 2, 6, 0, 3, 4, 4, 3, 3, 6, 1, 0, 0, 0, 1, 4, 2, 0, 5, 6, 6, 5, 0, 2, 2, 0, 5, 5, 1, 1, 0, 4, 1, 1, 1, 1, 1, 4, 2, 0, 3, 3, 0, 5, 5, 3, 3, 3, 3, 2, 3, 3, 0, 5, 5, 3, 1, 0, 2, 2, 4, 2, 3, 3, 5, 3, 5, 3, 1, 0, 4, 1, 1, 0, 0, 0, 0, 5, 5, 3, 3, 0, 0, 1, 6, 6, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 2, 2, 2, 2, 6, 3, 5, 6, 4, 4, 2, 2, 1, 5, 4, 6, 2, 4, 1, 6, 3, 0, 5, 2, 3, 3, 3, 4, 6, 1, 0, 0, 2, 1, 4, 2, 0, 0, 0, 4, 4, 1, 1, 0, 0, 0, 4, 1, 0, 2, 5, 0, 2, 3, 5, 4, 5, 0, 6, 6, 4, 2, 3, 3, 1, 6, 6, 4, 6, 1, 4]
一応、エンドレスエイト1話と判定された画像が多い結果になりました。
なんとも言えない結果になってしまったので、0(1話目)と判定されていないシーンの塊を確認してみたところ、凡ミスが発覚しました。
同じシーンでも1話目になかったデジャブのシーンであったり、

語り合いのシーンであったり、

同じシーンだとしても1話目にはなかった展開(物語上の繰り返しによって変化した日常シーン)の画像があったので、これらを省き、再度検証してみました。
結果はこちら
エンドレスエイト1話
45
エンドレスエイト2話
19
エンドレスエイト3話
28
エンドレスエイト4話
23
エンドレスエイト5話
14
エンドレスエイト6話
22
エンドレスエイト7話
11
1話目になかったシーン部分の多くが他の話に振り分けられていたようです。
このくらい差が出てくると達成感に近いものが出てきました。
検証結果に対する考察に関しては最後にまとめる事にして、このモデルでいくつか追加で検証を試してみます。
ー 追加検証 ー
ンドレスエイト8話目の全ての画像で判定させてみる。
エンドレスエイト1話
72(+27)
エンドレスエイト2話
54(+35)
エンドレスエイト3話
77(+49)
エンドレスエイト4話
39(+16)
エンドレスエイト5話
47(+33)
エンドレスエイト6話
31(+9)
エンドレスエイト7話
36(+25)
同じ絵コンテ・演出家、作画監督のエンドレスエイト以外の話を判定させてみる。
涼宮ハルヒの溜息Ⅲ(絵コンテ・演出家:石原立也 作画監督:池田和美)
エンドレスエイト1話
41
エンドレスエイト2話
52
エンドレスエイト3話
42
エンドレスエイト4話
64
エンドレスエイト5話(絵コンテ・演出家:石原立也 作画監督:池田和美)
28
エンドレスエイト6話
79
エンドレスエイト7話
19
涼宮ハルヒの溜息Ⅳ(絵コンテ・演出家:北之原孝将 作画監督:門脇未来)
エンドレスエイト1話
54
エンドレスエイト2話
35
エンドレスエイト3話
40
エンドレスエイト4話
57
エンドレスエイト5話
38
エンドレスエイト6話(絵コンテ・演出家:北之原孝将 作画監督:門脇未来)
94
エンドレスエイト7話
41
1期 涼宮ハルヒの憂鬱Ⅵ(絵コンテ・演出家:石原立也 作画監督:池田和美) >エンドレスエイト1話 69 エンドレスエイト2話 73 エンドレスエイト3話 63 エンドレスエイト4話 62 エンドレスエイト5話(絵コンテ・演出家:石原立也 作画監督:池田和美) 34 エンドレスエイト6話 31 エンドレスエイト7話 34
ー 検証結果、考察 ー
今回の検証をまとめていきます。
#####①絵コンテ・演出家、作画監督ごとに同じ場面を描いてもらった場合は、識別することができる。
②正解の訓練データに該当のシーンが無い、かつ、正解以外の訓練データにシーンがある場合は正しく識別できない。
③訓練データと全く異なる画像データを与えた場合、正しく判定出来る場合と出来ない場合がある。
①について、
本筋で検証を行った通りエンドレスエイト8話目を1話目と識別することが出来ました。
検証を行う上で、全ての話の訓練データに存在するシーンに絞り込むことで、より精度が上がった為、絵コンテ・演出家、作画監督の特徴を掴んでいると言えると思います。
②について、
追加検証にてエンドレスエイト8話目の全シーンの検証を行いました。その結果、1話目と3話目に判定された数が多かったのですが、①の検証結果からの増加量で見ると1話目(+27)3話目(+49)と大きく差が出ました。内容を確認したところ、やはり1話目にはなかった展開やシーンで他の話と判定される数が増加していました。特に、この夏が繰り返し行われている事を説明をするシーンが3話目に判定されることが多かったです。しかし、どの話にも無い、8話目のみにあるシーンで1話目が増加量を増やしていたことから「正解の訓練データに該当のシーンが無い、かつ、正解以外の訓練データにシーンがある場合は正しく識別できない」と推論を立てました。よくよく考えると、当然の結果ですね。
③について、
追加検証にて涼宮ハルヒの溜息Ⅲ、Ⅳ、また1期放映分の涼宮ハルヒの憂鬱Ⅵに関しても同じ絵コンテ・演出家、作画監督だったので判定してみましたが、判定結果はできる場合と出来ない場合に分かれました。こちらに関しても、判定された内容を確認してみたのですが、なぜこのような結果になったのか確定的な事がわかりませんでした。真正面から顔を捕らえ、尚且つ普通の表情をしているシーンに関しては正しく判定される事が多いような気がしましたが、正直、確証は得られません。
例えば、涼宮ハルヒの溜息Ⅳより

↑これはエンドレスエイト6話目と正しい絵コンテ・演出家、作画監督を判定しますが、

↑これはエンドレスエイト7話と判定します。
このようにキョンの目が糸のようになっているシーンでの誤判断が多いかと思いきや、

↑これはエンドレスエイト6話目と正しい絵コンテ・演出家、作画監督を判定しますが、

↑これはエンドレスエイト7話と判定するなど、違いがよくわかりません。
人間には理解できない特徴を掴んでいるのは間違いないですね。
ー まとめ ー
結論として、元々の検証動機へのアンサーとしては「同じシーンを書いたものであれば可能」という結論が出ました。当初から、完成したモデルでその他の追加検証をしようと思っていたので、今回は一話丸ごとを訓練データとして使いましたが、各話の同じシーンだけを訓練データにしてモデルを作ればさらに精度は良くなるのでは無いかと思います。
追加検証で行ったエンドレスエイト以外の画像分類結果を改めて考えてみたのですが、一つの仮説が浮かび上がりました。そもそも今回は絵コンテ・演出家、作画監督を判別するという、言うなれば「技術力」を判別する事を目標にしていました。しかし、「技術力」というものは、それ自体が曖昧であり、簡単に数値化できる代物ではありません。特に芸術という分野においてはなおさらでしょう。その上、今回の場合、各絵コンテ・演出家、作画監督は同じ制作会社ですし、そもそも作画に関しては彼等だけではなく大勢のスタッフと共に作り上げているものです。制作現場を見たわけではありませんが、もしかするとクレジット以外のスタッフの手伝いなんかもあったのかもしれません。
唯一、正しく判定できた数が多かった「絵コンテ・演出家:北之原孝将 作画監督:門脇未来」ペアに関して調べてみると、北之原孝将氏は社内の「プロ養成塾」の講師をされている程の実力者であったり、門脇未来氏はエンドレスエイト6話が初作画監督作品であったりと、他のペアと比べて特徴量が多かったのかも知れません。
エンドレスエイト8話目を丸ごと判定させた際に数が多かったエンドレスエイト3話目の絵コンテ・演出家、三好一郎氏(本名:木上 益治)はアニメーター界のレジェンドのような方でしたので、他の方々にも大きな影響を与えていたのでは無いかと思います。それによって類似点が多かったりしたのかも知れません。全ては想像の域を出ませんが、、、、、、
今回はディープラーニングで作画監督を見分けられるのかを検証しました。
結果としては「条件が合えば、見分ける事ができる」という事がわかりました。
色々と思う所や、さらに検証を進めたい部分はありますが、今回はここまでにしたいと思います。
もっと深い部分に関しては知識をもっと付けてから、再度取り組みたいと思います。

ご拝読、ありがとうございました。