論文情報
論文名:Zero-Shot Learning Through Cross-Modal Transfer
公開年:2013年
DOI:https://doi.org/10.48550/arXiv.1301.3666
1. Introduction
訓練データが存在しない画像内のオブジェクトを認識できるモデルを提案。
例えば、一度も猫の画像を学習したことがなくても、その画像が猫を示しているのか、あるいは犬や馬といった学習済みのクラスに属するのかを判別可能。
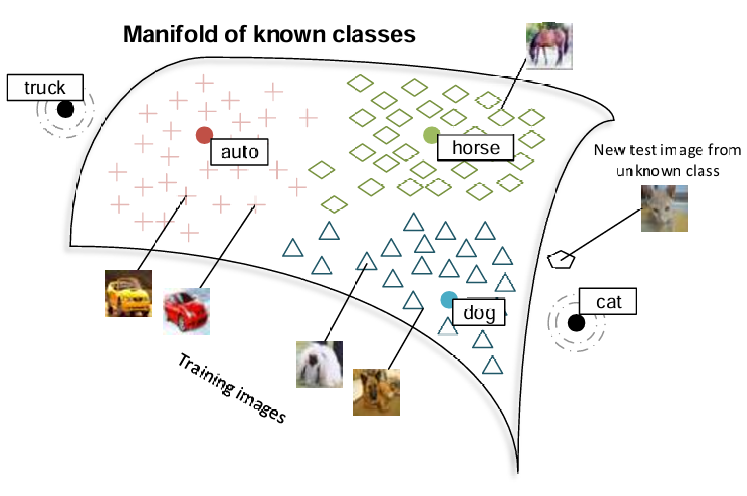
- NNモデルを大規模コーパスで学習し、単語同士の類似性を捉えた意味空間を形成する(Manifold of known classes)
- テスト画像(図だと猫の画像)が意味空間上にあるかを判定する(外れ値検出を使う)
- 意味空間上にない場合は、単語埋め込みを使ってそのクラスを特定する
2. Related Work
Zero-Shot Learning
本論文の取り組みは、Palatucci らの研究に近い。
One-Shot Learning
非常に少ない訓練データを用いて、物体クラスを学習することを指す。
本論文は、自然言語からのクロスモーダルな知識転移により、訓練データがなくても物体クラスを分類できる点が異なる。
Domain Adaptation
あるドメイン(分野)には多くの訓練データがあるが、別のドメインにはほとんどないような状況で有用。
Multimodal Embeddings
音声や映像、画像、テキストなど、複数のソースから情報を関連付けることができる。
Socher らは、単語と画像を共通の意味空間に投影し、注釈付けとセグメンテーションの分野においてSOTAを達成した。しかし、訓練データが若干量必要になる点がネック。
3. Word and Image Representations
単語同士の類似性を捉える方法として、文脈内での他の単語との共起性を学習する手法がある。この手法は、様々な自然言語処理タスクで効果的であることが証明されている。
例えば Huang らは、Wikipedia のテキストを使用して、各単語がその文脈内で発生する可能性を予測することで単語ベクトルを学習する。
このモデルでは、各単語の周りのウィンドウ内の局所的な文脈と、グローバルな文書文脈の両方を使用する。
4. Projection Images into Semantic Word Spaces
Huang らのモデルを活用し、画像ベクトルを50次元の単語の意味空間に投影した。
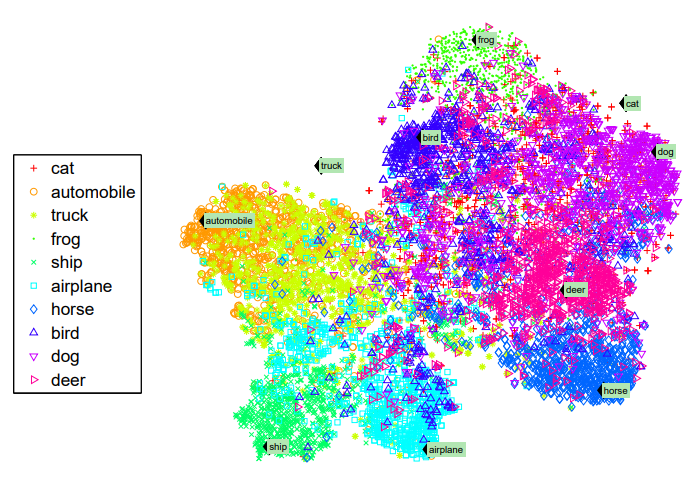
- T-SNEを用いて、単語の意味空間を50次元→2次元へ圧縮して可視化した図。緑背景の文字が単語ベクトルの位置。
- ほぼ全てのクラスは単語ベクトルの周りに密に分類されている一方で、Zero-Shot(猫とトラック)は近くにベクトルがない。しかし、意味的には類似したクラスに近い位置にある(猫は犬や馬に近く、車や船とは遠い)
7. Conclusion
提案モデルの特徴は以下のとおり。
- 単語同士の類似性を捉えた意味空間を使用することで、異なるモダリティ間で知識を転移するのに役立つ
- 外れ値検出で Manifold of known classes 上にあるかどうかを判定するフレームワークが、Zero-Shot 分類と既知の分類を1つのフレームワークに統合するのに役立つ