データの Github になる!を目指す delika 。お恥ずかしながら今まで存じ上げず、ふと Qiita で何か書こうかな、と眺めていたら Qiita で delika の記事投稿キャンペーンをやっていたので、やってみました!
この記事で利用している Elastic Stack は ver 8.1.0 です。
まずはデータを取り込み!
delika には creative commons などでライセンスされたパブリックなデータセットが公開されています。さっそくいくつか取り込んでみましょう。
品川区避難所
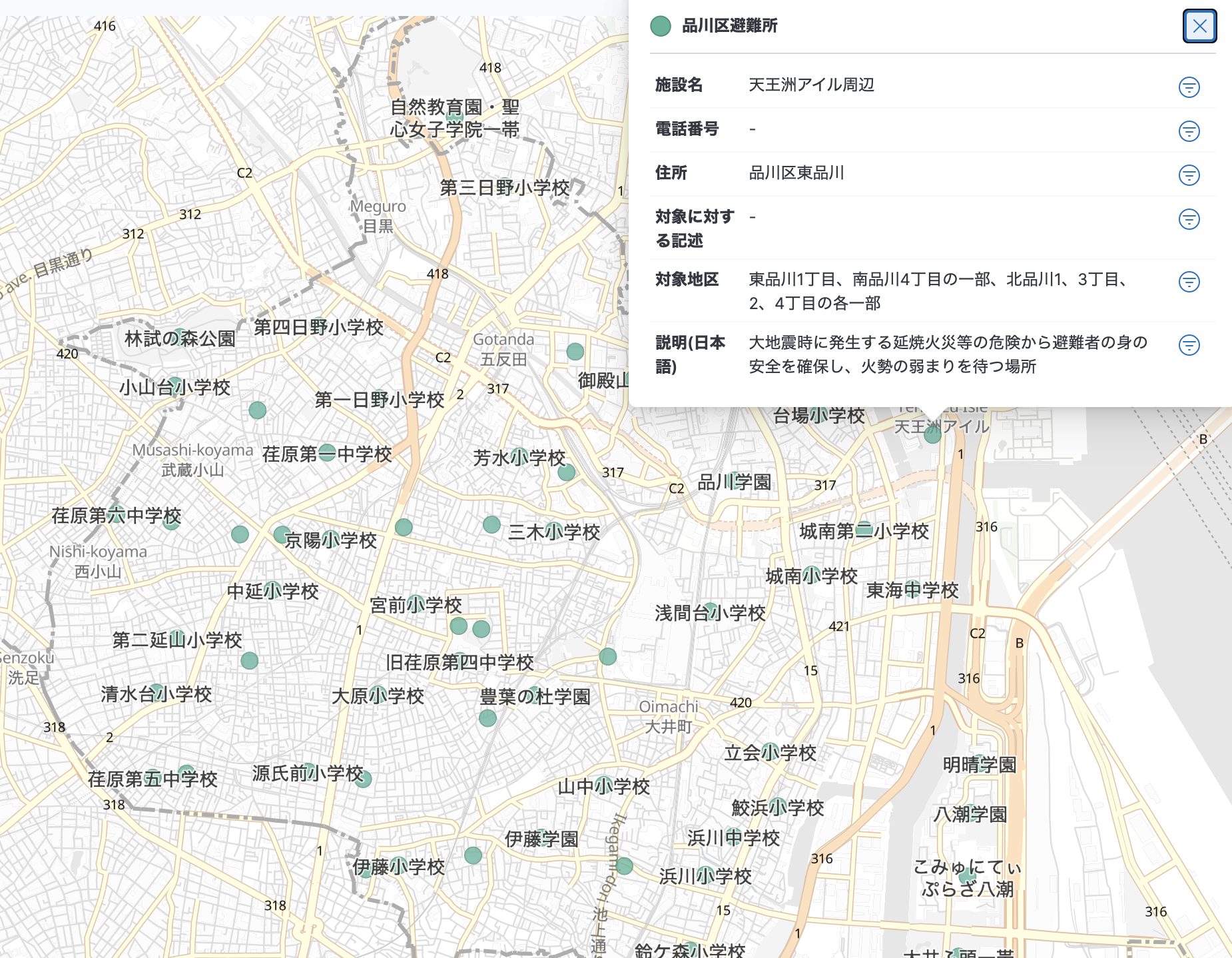
CC 2.1 JP ライセンスで最初に見つけたデータが 品川区避難所 のデータ。delika 上でプレビュー確認すると、緯度経度を持っている。ってことは Kibana Map でいけるよね?と、試してみました。
緯度、経度と二つのカラムになっているので、一つの geo_point フィールドに変換するために ingest pipeline を作成。
汎用的に呼べるように、テスト後のスクリプトを登録しておきます。
PUT _scripts/geo-point
{
"script": {
"lang": "painless",
"source": """
Map p = new HashMap();
p.put('lat', ctx[params.lat]);
p.put('lon', ctx[params.lon]);
ctx[params.output] = p;
"""
}
}
すると、色々な ingest pipeline から、 ID 指定で呼び出せるようになります。
{
"script": {
"id": "geo-point",
"params": {
"output": "location",
"lat": "緯度",
"lon": "経度"
}
}
}
で、 Machine Learning の Data Visualizer で、 delika からダウンロードした CSV ファイルをどーん、とインポート。 さきほど作った geo-point スクリプトを使って location フィールドを作成します。(同様のデータ編集は Add combined field からもできるのかな??知らなかった)
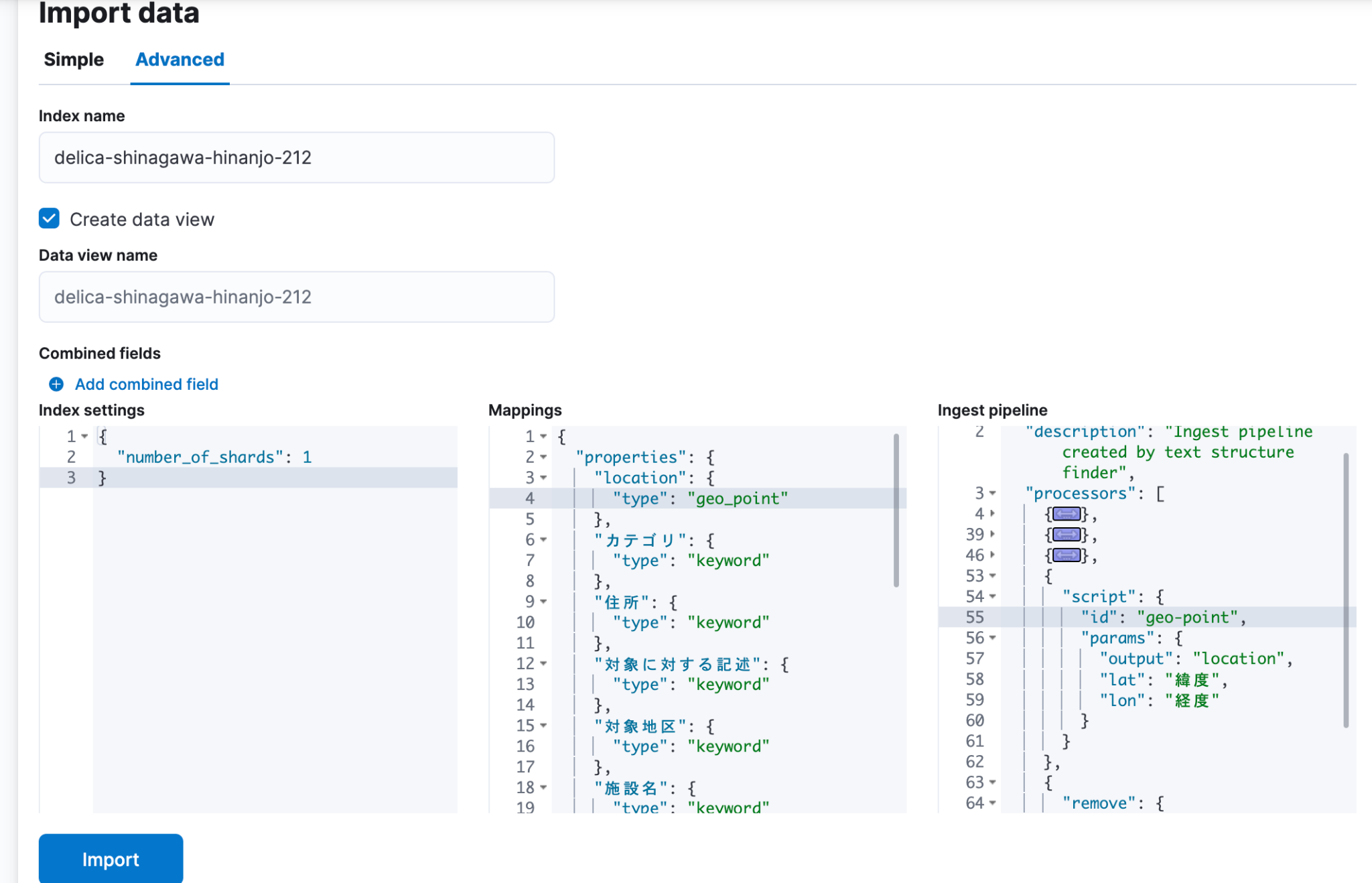
取り込むと、各フィールドの統計情報がわかりやすく表示されるのは、知らないデータを扱う際にとても便利ですよね。
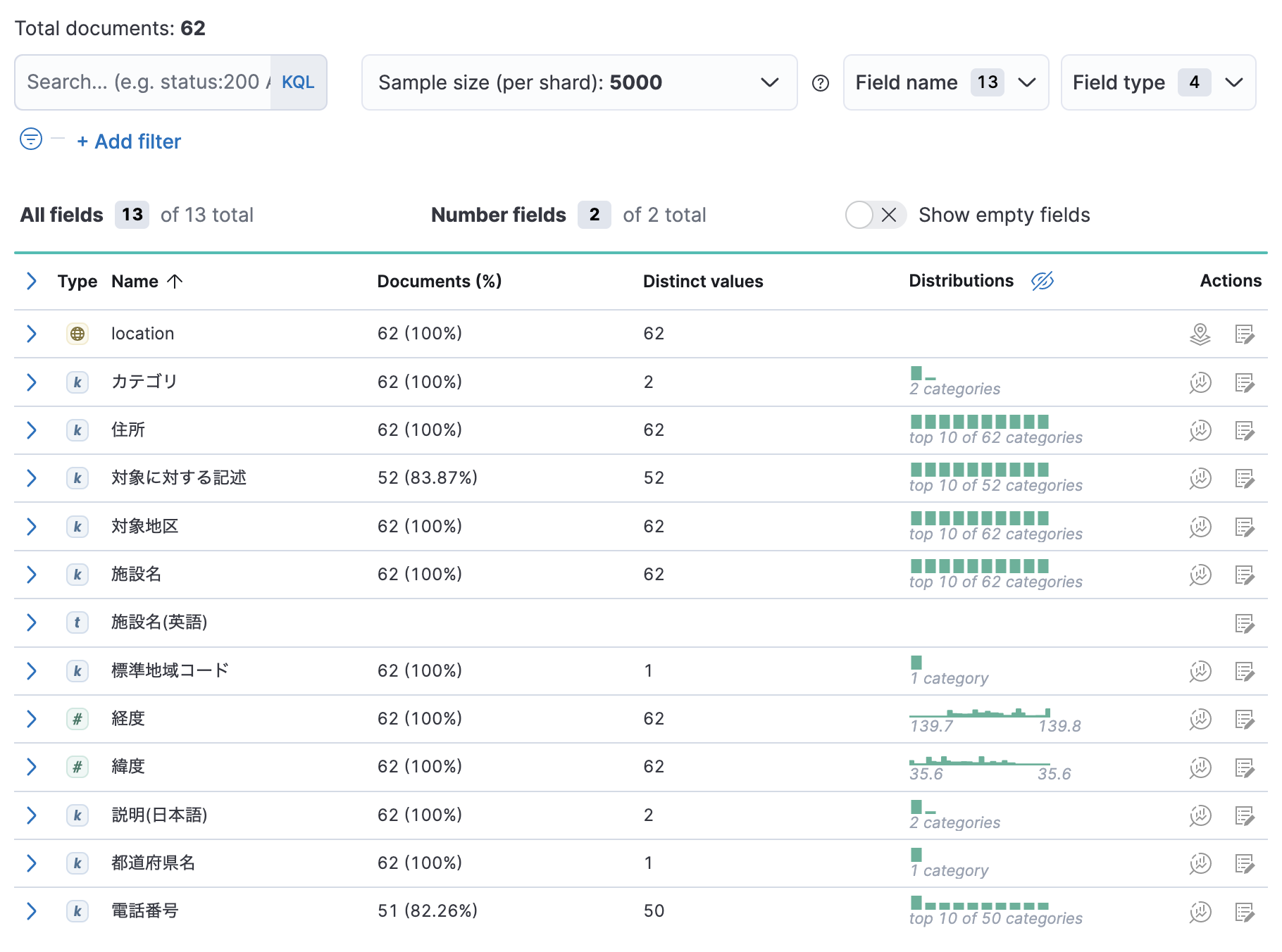
Kibana Map で表示
Map で Document のレイヤーを追加し、ツールチップで各種フィールドの値を表示する設定を加えてっと。
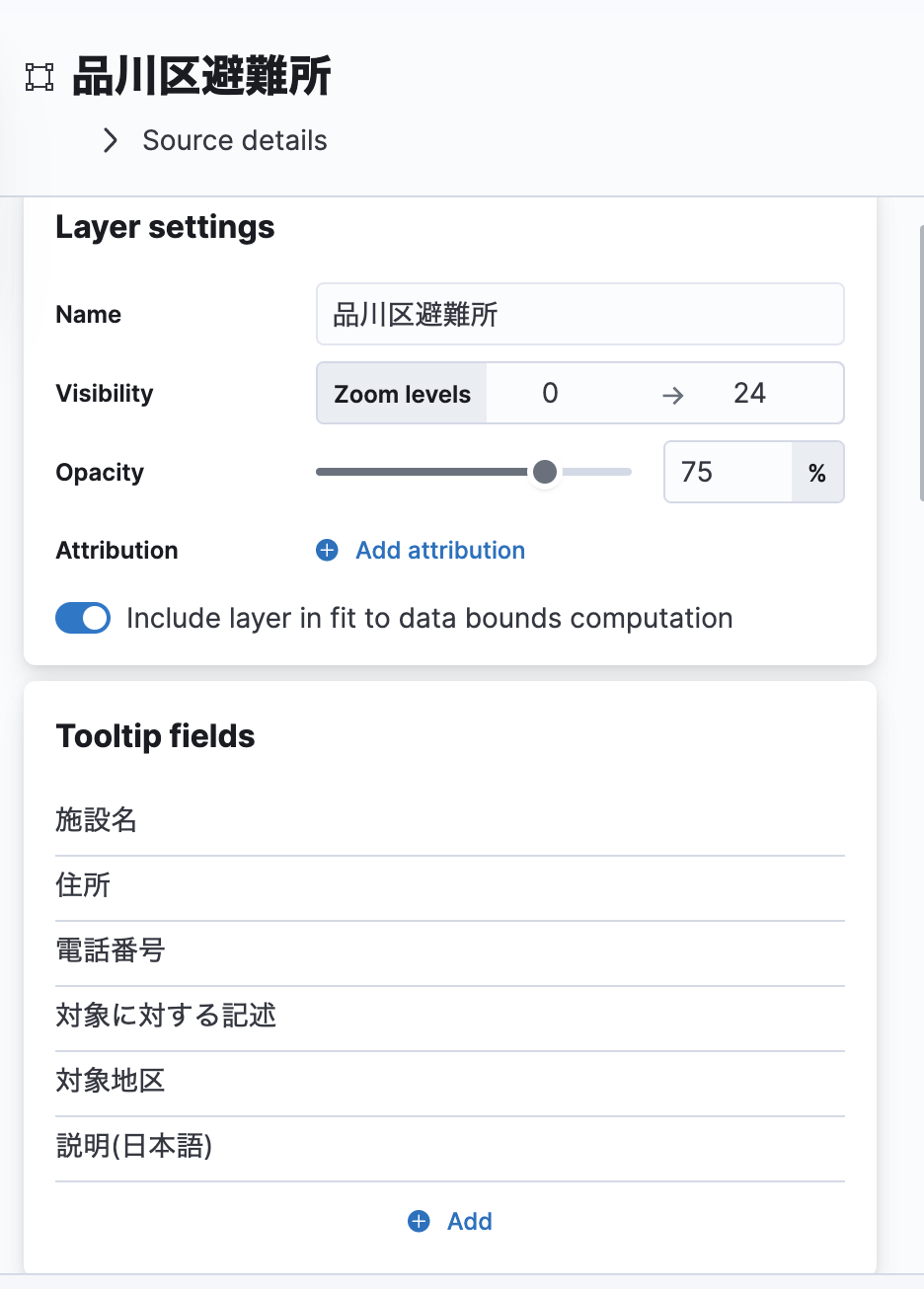
こんな感じになりました!
『データに関する記事を書こう!』の記事投稿キャンペーンのダミーデータ
お次はキャンペーンのダミーデータです。こちらは
CC BY-NC-SA 4.0 となっています。
- qiita-dummy-article-tags
- qiita-dummy-articles
- qiita-dummy-tags
の三つのファイルに分かれていて、 JOIN する系です。
JOIN 後のリッチな JSON ドキュメントとしてインポートしたいので、 enrich の元となる CSV を取り込み、 enrich の定義をガシガシ作っていきます。
# 記事とタグの JOIN 用
PUT _enrich/policy/delika-qiita-dummy-article-tags
{
"match": {
"indices": "delika-qiita-dummy-article-tags",
"match_field": "article_id",
"enrich_fields": ["tag_id"]
}
}
POST _enrich/policy/delika-qiita-dummy-article-tags/_execute
# タグID と タグ名の JOIN 用
PUT _enrich/policy/delika-qiita-dummy-tags
{
"match": {
"indices": "delika-qiita-dummy-tags",
"match_field": "id",
"enrich_fields": ["name"]
}
}
POST _enrich/policy/delika-qiita-dummy-tags/_execute
タグ名エンリッチのテスト
実際にインポートする前にテストしておきます。まずはタグ ID からタグ名への変換。
# 1段階
POST _ingest/pipeline/_simulate
{
"docs": [ { "_source": { "tags": [ 1, 2 ] } } ],
"pipeline": {
"processors": [
{
"enrich": {
"policy_name": "delika-qiita-dummy-tags",
"field": "tags",
"target_field": "tag_names",
"max_matches": 10
}
}
]
}
}
結果はこんな感じ、ちゃんと引っ張れてますね。
{
"docs" : [
{
"doc" : {
"_index" : "_index", "_id" : "_id", "_source" : {
"tag_names" : [
{ "name" : "Python", "id" : 1 },
{ "name" : "JavaScript", "id" : 2 }
],
"tags" : [ 1, 2 ]
},
"_ingest" : { "timestamp" : "2022-04-16T15:07:11.48173318Z" }
}
}
]
}
記事からタグ一覧を JOIN して、さらにタグ名に変換
foreach プロセッサを使うのがミソですね。不要なフィールドは削除して綺麗にしておきます。
# 2段階 enrich して、不要なフィールドは削除
POST _ingest/pipeline/_simulate
{
"docs": [ { "_source": { "id": 1 } } ],
"pipeline": {
"processors": [
{
"enrich": {
"policy_name": "delika-qiita-dummy-article-tags",
"field": "id",
"target_field": "tags",
"max_matches": 10
}
},
{
"foreach": {
"field": "tags",
"processor": {
"enrich": {
"policy_name": "delika-qiita-dummy-tags",
"field": "_ingest._value.tag_id",
"target_field": "_ingest._value.tag_name",
"max_matches": 1
}
}
}
},
{
"foreach": {
"field": "tags",
"processor": {
"set": {
"field": "_ingest._value",
"value": "{{_ingest._value.tag_name.name}}"
}
}
}
}
]
}
}
結果はこんな感じ
{
"docs" : [
{
"doc" : {
"_index" : "_index", "_id" : "_id",
"_source" : {
"id" : 1, "tags" : [ "Perl", "初心者", "Elasticsearch" ]
},
"_ingest" : {
"_value" : null, "timestamp" : "2022-04-16T15:11:51.259629479Z"
}
}
}
]
}
Data Visualizer で取り込んで、可視化
テスト済みのプロセッサを加えて、取り込みます。
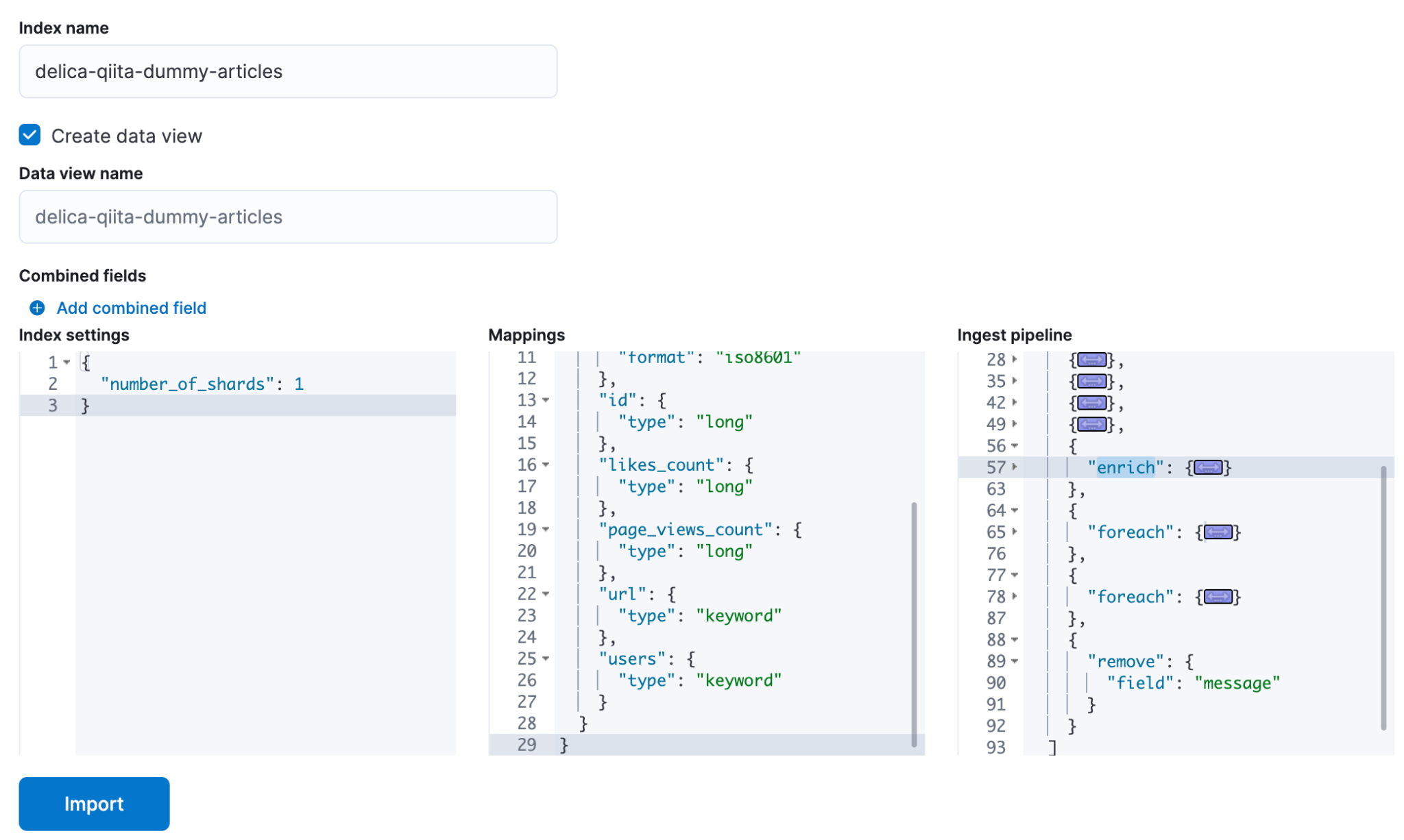
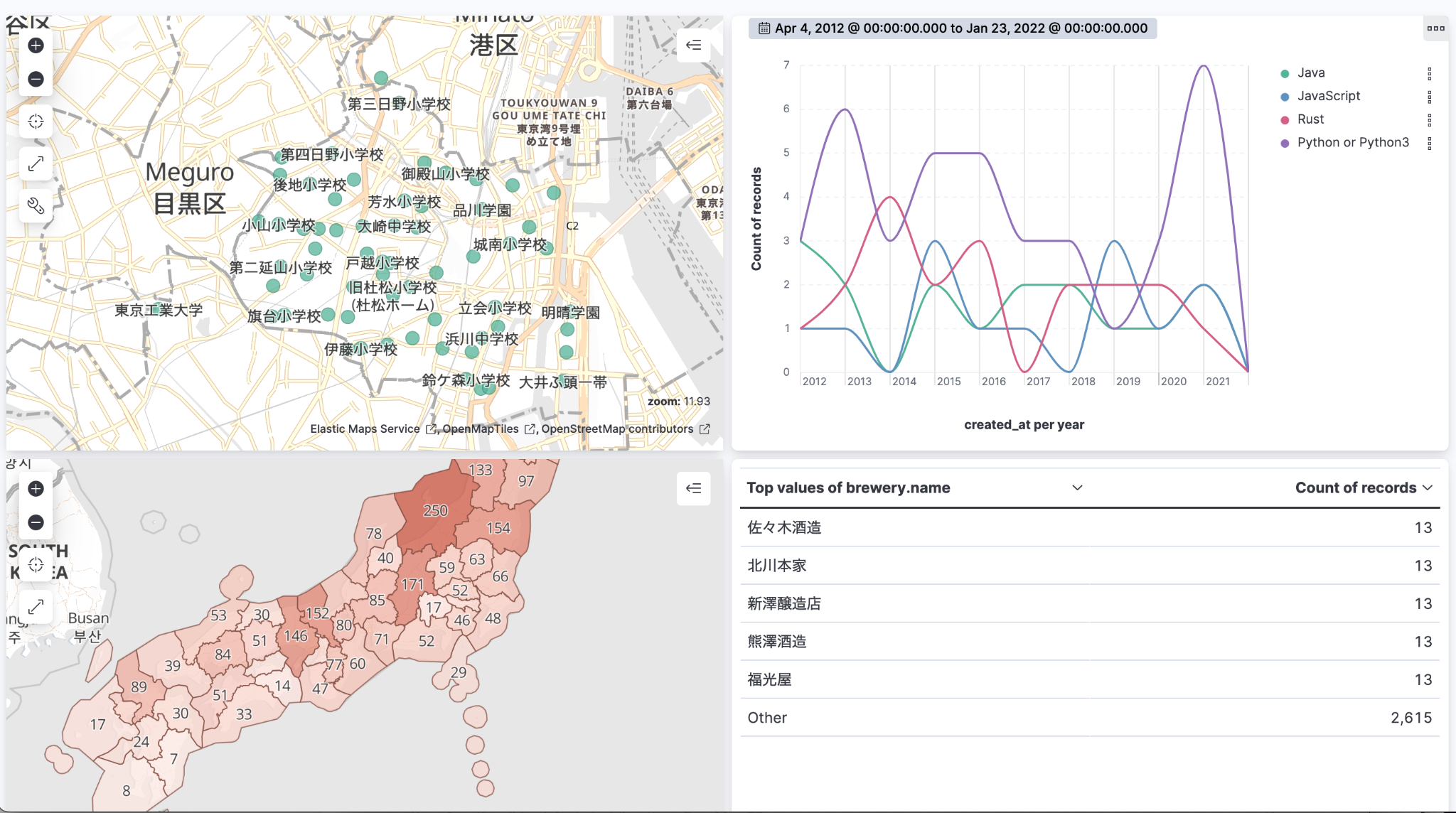
すると、こんな感じに。ふむふむ 2013 年からのデータなんですね。
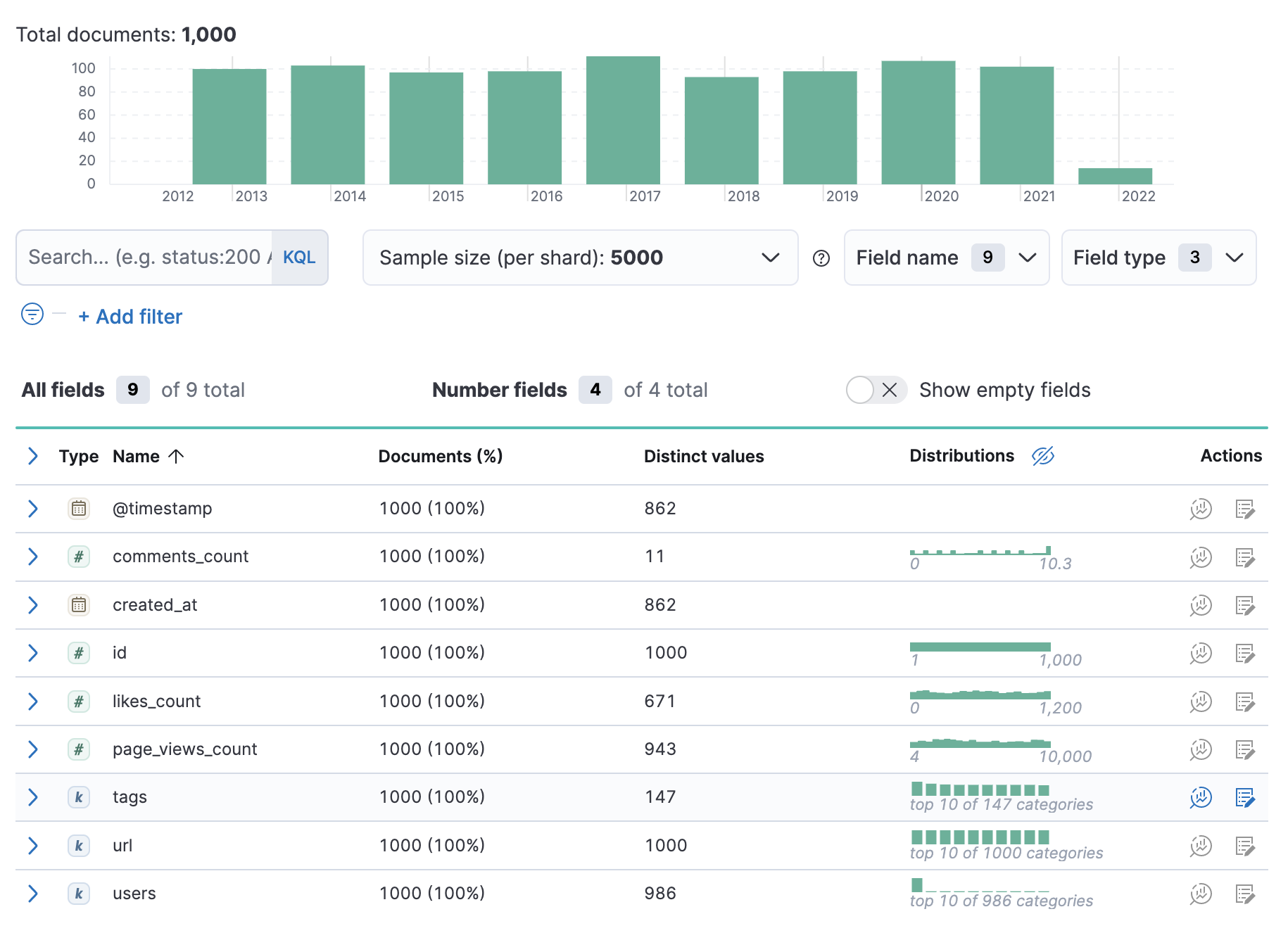
Kibana Lens を使って、タグのついた投稿の数から、「プログラミング言語トレンドの推移」的なチャートを作ってみました。ダミーデータですからね、現実とは異なります的な。
酒だ酒だ! sakenowa!
飲んだ日本酒を記録して、好みの日本酒を見つける、 sakenowa のデータも CC BY 4.0 で公開されていました。sakenowa-data。
このデータセット、面白いです。そしてそれなりに複雑で取り込みがいがありますね!
- sakenowa-area
- sakenowa-brand-flavor-tags
- sakenowa-brands
- sakenowa-breweries
- sakenowa-flavor-charts
- sakenowa-flavor-tags
今回は使いませんでしたが、ランキングのデータもあります:
- sakenowa-rankings-area
- sakenowa-rankings-overall
Enrich の定義して、取り込み用のプロセッサを記述
データの種類が多いので、 enrich を書くのも一苦労です。とはいえ、形式的なものなのでそれほどでも。
PUT _enrich/policy/delika-sakenowa-area
{
"match": {
"indices": "delika-sakenowa-area",
"match_field": "id",
"enrich_fields": ["name"]
}
}
POST _enrich/policy/delika-sakenowa-area/_execute
PUT _enrich/policy/delika-sakenowa-brand-flavor-tags
{
"match": {
"indices": "delika-sakenowa-brand-flavor-tags",
"match_field": "brandId",
"enrich_fields": ["tagId"]
}
}
POST _enrich/policy/delika-sakenowa-brand-flavor-tags/_execute
PUT _enrich/policy/delika-sakenowa-breweries
{
"match": {
"indices": "delika-sakenowa-breweries",
"match_field": "id",
"enrich_fields": ["name", "areaId"]
}
}
POST _enrich/policy/delika-sakenowa-breweries/_execute
PUT _enrich/policy/delika-sakenowa-flavor-charts
{
"match": {
"indices": "delika-sakenowa-flavor-charts",
"match_field": "brandId",
"enrich_fields": ["f1", "f2", "f3", "f4", "f5"]
}
}
POST _enrich/policy/delika-sakenowa-flavor-charts/_execute
PUT _enrich/policy/delika-sakenowa-flavor-tags
{
"match": {
"indices": "delika-sakenowa-flavor-tags",
"match_field": "id",
"enrich_fields": ["tag"]
}
}
POST _enrich/policy/delika-sakenowa-flavor-tags/_execute
プロセッサではフィールドの有無をしっかり確認しましょう
今回の取り組みで一番ハマったのがここ。 Ingest Pipeline で色々と加工する時に、例外が発生すると、データ取り込みの際にエラーになるんです。そして Data Visualizer 経由で取り込むとエラーの原因をデバッグするのが大変。。紆余曲折あり、最終系が次の形、 null チェック、しっかりしたら大丈夫!
先ほどのキャンペーンダミーデータの発展系ですね。
POST _ingest/pipeline/_simulate
{
"docs": [
{
"_source": {
"breweryId": 1,
"name": "新十津川",
"id": 1
}
},
{
"_source": {
"breweryId": 2,
"name": "男山",
"id": 2
}
},
{
"_source": {
"breweryId": 14,
"name": "蔵物語",
"id": 16
}
}
],
"pipeline": {
"processors": [
{
"enrich": {
"policy_name": "delika-sakenowa-breweries",
"field": "breweryId",
"target_field": "brewery"
}
},
{
"enrich": {
"policy_name": "delika-sakenowa-area",
"field": "brewery.areaId",
"target_field": "brewery.area"
}
},
{
"enrich": {
"policy_name": "delika-sakenowa-flavor-charts",
"field": "id",
"target_field": "flavor"
}
},
{
"enrich": {
"policy_name": "delika-sakenowa-brand-flavor-tags",
"field": "id",
"target_field": "tags",
"max_matches": 30
}
},
{
"foreach": {
"field": "tags",
"processor": {
"enrich": {
"policy_name": "delika-sakenowa-flavor-tags",
"field": "_ingest._value.tagId",
"target_field": "_ingest._value.tag_name",
"max_matches": 1
}
},
"if": "ctx.containsKey('tags')"
}
},
{
"remove": {
"field": "brewery.area.id",
"if": "ctx.containsKey('brewery')"
}
},
{
"remove": {
"field": "brewery.areaId",
"if": "ctx.containsKey('brewery')"
}
},
{
"remove": {
"field": "brewery.id",
"if": "ctx.containsKey('brewery')"
}
},
{
"remove": {
"field": "flavor.brandId",
"if": "ctx.containsKey('flavor')"
}
},
{
"foreach": {
"field": "tags",
"processor": {
"set": {
"field": "_ingest._value",
"value": "{{_ingest._value.tag_name.tag}}"
}
},
"if": "ctx.containsKey('tags')"
}
}
]
}
}
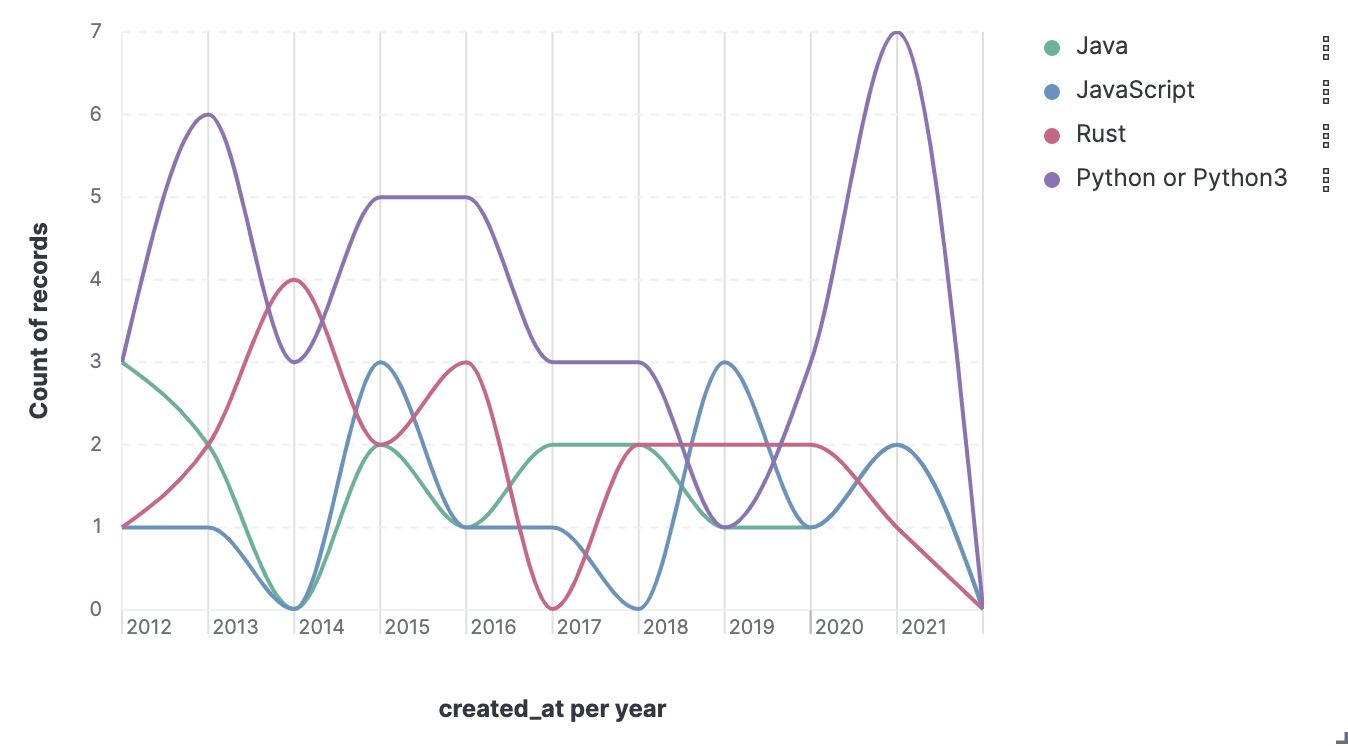
そして無事取り込まれましたの図。よっしゃ!各フィールドの分布も本物データっぽい。
Sakenowa データの可視化も多少追加。 Sakenowa はまだ色々とできそうです。
酒造で作っている銘柄一覧を表示するドリルダウンを設定
もう一つダッシュボードを作って、ドリルダウンの設定を加えるのは簡単。ドリルダウン先のダッシュボードで、銘柄の一覧を出すのも簡単。今回悩んだのは、酒造名をわかりやすくすっきりと表示する方法。銘柄一覧のデータテーブルに酒造名出すと、そもそもその酒造でフィルタリングかけているので、全行で同じデータが表示されて冗長なんですよね。
こういうのは、避けたい。
そこで、 Tree Map を使った小技を考案!
Tree Map でパーセント表示隠すと、見出しみたいに使える
デフォルトの Tree Map 表示だと、その項目しかなくても 100% って出ちゃうんですよね。
そこで、 Labels オプションから、パーセント表示をオフにしてあげれば ...
こんなにすっきり!
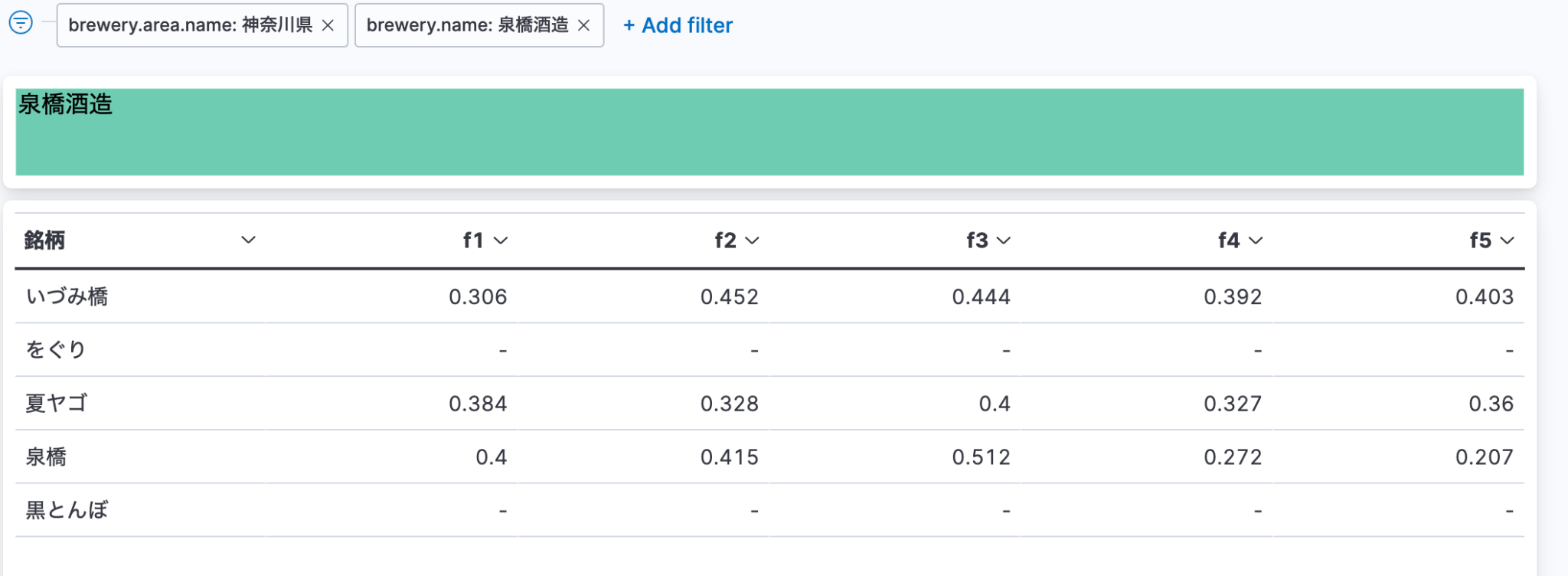
いざ日本酒探訪!
出来上がったダッシュボードで日本酒をさがしてみましょう。酒造の一覧では、地域、銘柄数、タグなどでフィルタリングできるようにしてみました。
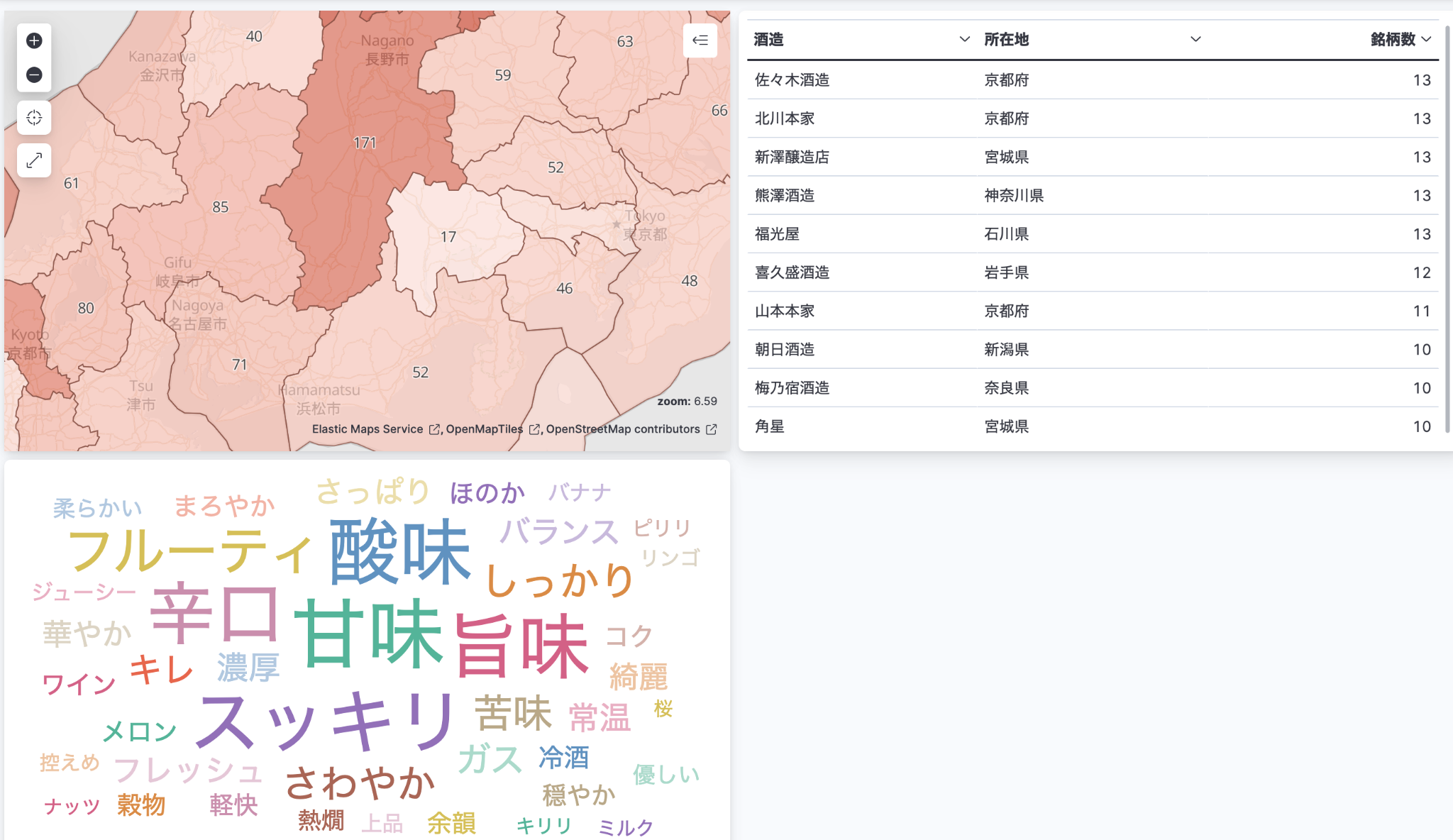
その時の気分で選んで、っと。おー、なんか甘くてとろけて美味しそう。
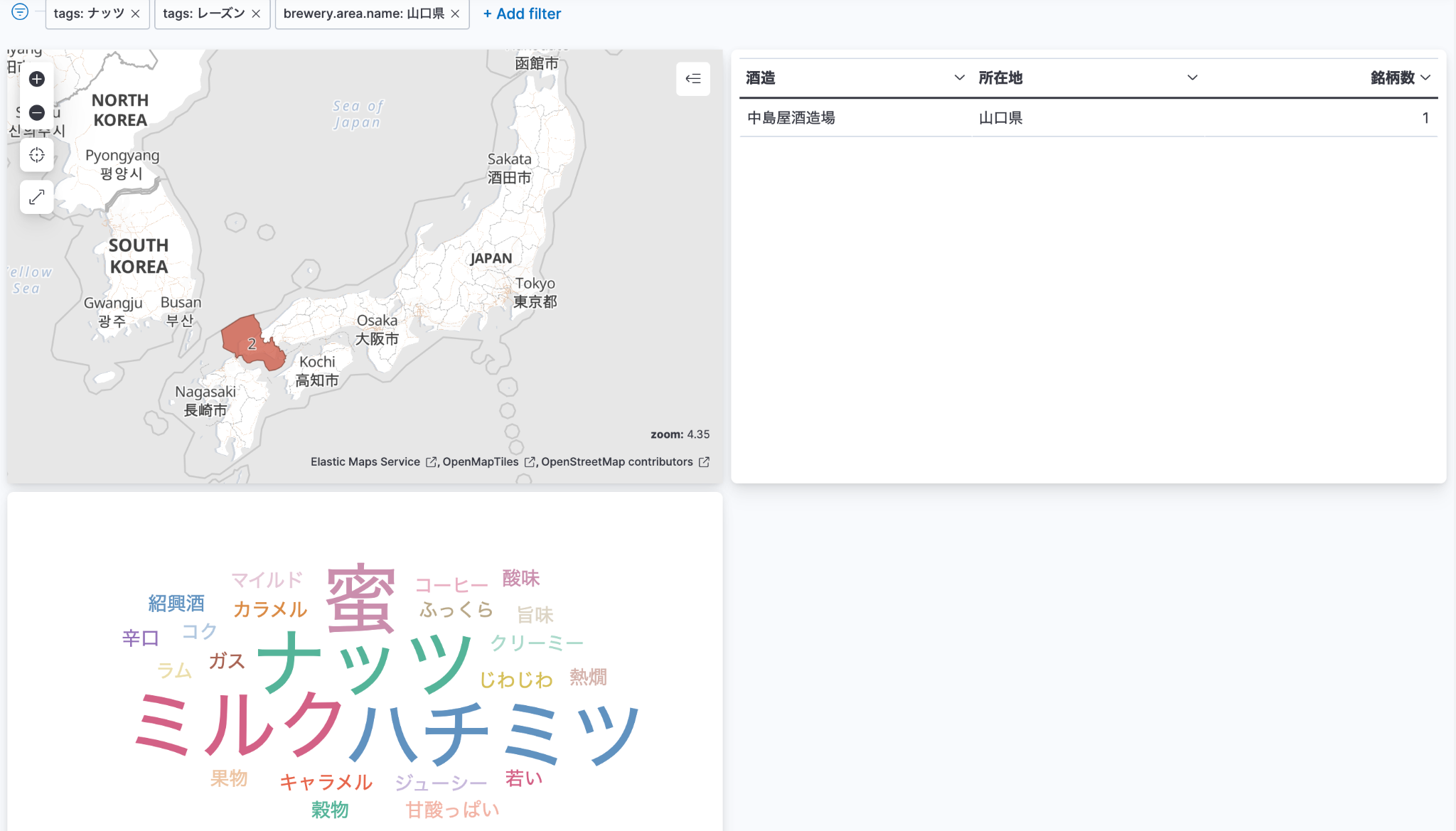
酒造名からドリルダウンで銘柄を見てみます!
飲んでみたい!
おまけ、 8.x の新機能、KNN で似たような味の日本酒を探す
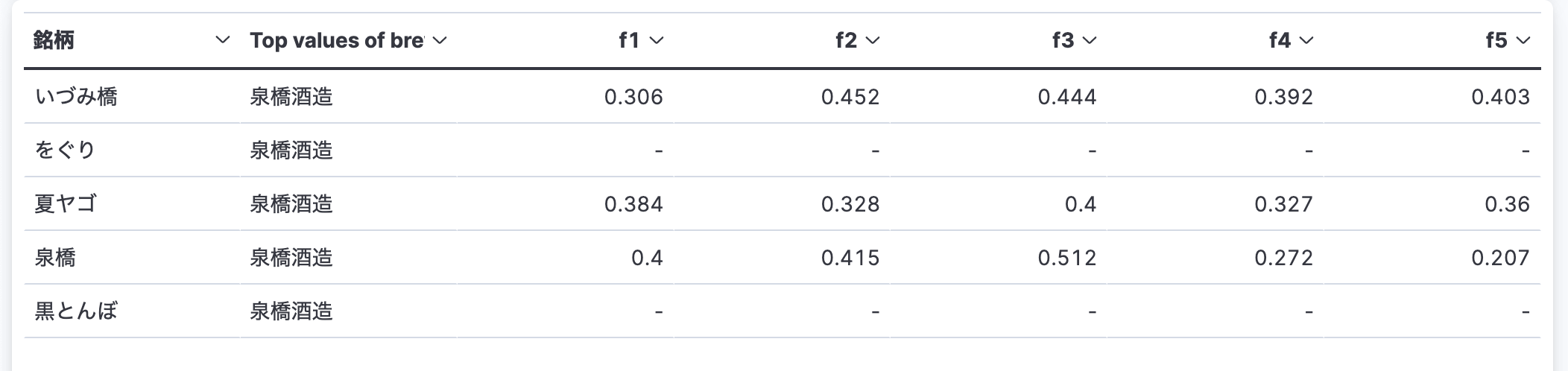
Sakenowa のデータセットには、各銘柄の f1 から f5 までの数値がついていました。それぞれの特徴がなんなのかは分かりませんが、これをベクトルとして扱えば、 KNN で似たようなテイストの銘柄が探せそうです。
Ingest pipeline にこんな感じの script プロセッサでコードを追加して、配列に変換。
if (ctx.containsKey('flavor')) {
ctx['flavor_vector'] = [
ctx['flavor']['f1'],
ctx['flavor']['f2'],
ctx['flavor']['f3'],
ctx['flavor']['f4'],
ctx['flavor']['f5']
];
}
マッピングには dense_vector の定義を追加しました。
"flavor_vector": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "dot_product"
}
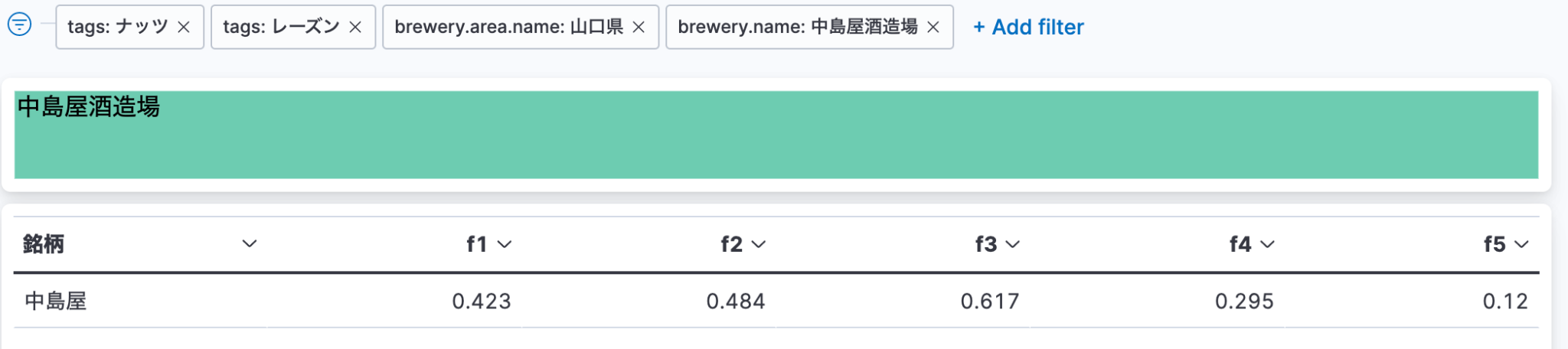
そして、先ほどの「中島屋」っぽいテイストを検索してみます。
GET delika-sakenowa-brands/_knn_search
{
"knn": {
"field": "flavor_vector",
"query_vector": [0.423, 0.484, 0.617, 0.295, 0.12],
"k": 3,
"num_candidates": 100
},
"_source": ["name", "brewery.name", "id", "tags", "flavor_vector"]
}
結果がこちら。「中島屋」自身がトップに来ていますね、確かに flavor_vector の傾向が近そうな銘柄が検索できました!
{
"took" : 1, "timed_out" : false,
"_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0
},
"hits" : {
"total" : { "value" : 100, "relation" : "eq" },
"max_score" : 0.9999994,
"hits" : [
{
"_index" : "delika-sakenowa-brands", "_id" : "PPG4MoABatE64WYgEKiF", "_score" : 0.9999994,
"_source" : {
"flavor_vector" : [ 0.422742747668764, 0.483615331307015, 0.616651032566715, 0.29511402062313, 0.119561104037828 ],
"name" : "中島屋", "brewery" : { "name" : "中島屋酒造場" },
"id" : 1974,
"tags" : [ "ハチミツ", "ナッツ", "レーズン", "果物", "ガス", "蜜", "甘酸っぱい", "若い", "ジューシー", "ミルク" ] }
},
{
"_index" : "delika-sakenowa-brands", "_id" : "0vG4MoABatE64WYgEqk0", "_score" : 0.99249893,
"_source" : {
"flavor_vector" : [ 0.450562124136379, 0.517157794317278, 0.571616530946918, 0.235612366670008, 0.109413827194259 ],
"name" : "玉風味", "brewery" : { "name" : "玉川酒造" },
"id" : 2599,
"tags" : [ "ワイン", "冷酒", "燗酒", "スパイス", "ジュース", "甘酸っぱい", "酸味", "グレープフルーツ", "じっくり" ] }
},
{
"_index" : "delika-sakenowa-brands", "_id" : "pPG4MoABatE64WYgD6e1", "_score" : 0.9875737,
"_source" : {
"flavor_vector" : [ 0.487210520058936, 0.455750958521687, 0.570253559820013, 0.367022332284362, 0.102992910932017 ],
"name" : "伊根満開", "brewery" : { "name" : "向井酒造" },
"id" : 1766,
"tags" : [ "ワイン", "甘酸っぱい", "紹興酒", "熱燗", "酸味", "チョコレート", "桜", "コーヒー", "綺麗", "フルーティ", "ジュース", "ブドウ", "甘味", "とろみ", "冷酒", "カラメル", "上品", "いちご", "ガス", "淡い" ] }
}
]
}
}
まとめ
いかがでしたでしょうか。Elastic Stack のようなデータ分析の仕組みを色々と試したい時に delika のパブリックなデータセットはとても便利ですね!プランによっては、さまざまなデータセットも利用できるようになるとか。データを共有する場所、仕組みがどんどん充実して、色々なことに利用できるようになってきて素晴らしいですね :)