はじめに
機械学習のモデルを生成する際は、所持するデータを以下の2種(または3種)にきちんと分割して訓練及びテストを行う必要があります。
・訓練データ(Training data)
(・検証用データ(Validation data))
・テストデータ(Test data)
訓練データにテストデータが混じっていると、生成したモデルの性能を正しく評価することができなくなる可能性があります。そのため、あらかじめどのようにデータの分割を行うかを決めておく必要があります。
機械学習を行うための基礎知識として、データの分割によく使用する手法を4つ紹介します。
目次
| 項番 | 項目 |
|---|---|
| 1 | ホールドアウト法(Hold-out) |
| 2 | ランダムサブサンプリング(Random Subsampling) |
| 3 | 交差検証(Cross-validation) |
| 4 | 層化抽出法(Stratified Sampling) |
1. ホールドアウト法(Hold-out)
最も初歩的な分割方法。
テストのためのデータを一定量確保しておき、残りのデータを訓練に使用する。

2. ランダムサブサンプリング(Random Subsampling)
ランダムにデータを抽出して訓練データセットを構築し、抽出されなかったサンプルをテストに使用する方法。
データセットの構築とテストを複数回行い、全試行の平均を最終的な評価結果として採用する。
Hold-outよりも評価結果の信頼性を高めることができる。
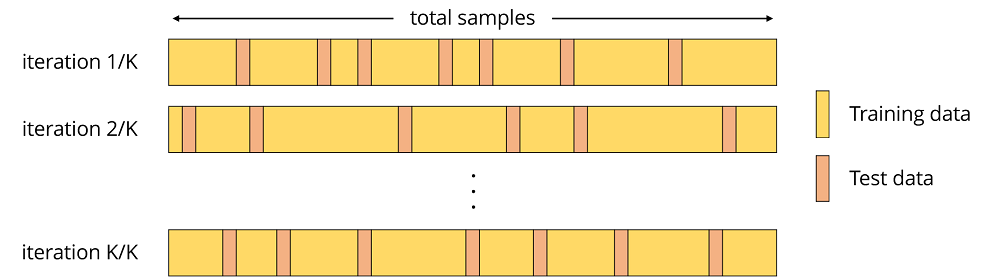
3. 交差検証(Cross-validation)
① k分割交差検証(K-fold Cross-validation)
- データを同じサイズのk個のサブセットに分割する。
- 1つのサブセットをテストとして使用し、残りを訓練として使用する検証を、サブセットの数だけ繰り返す。
- 全試行の平均を最終的な評価結果として採用する。
全てのデータがテストに使用されるため、ランダムサブサンプリングよりも評価結果の信頼性を高めることができる。
10分割の場合
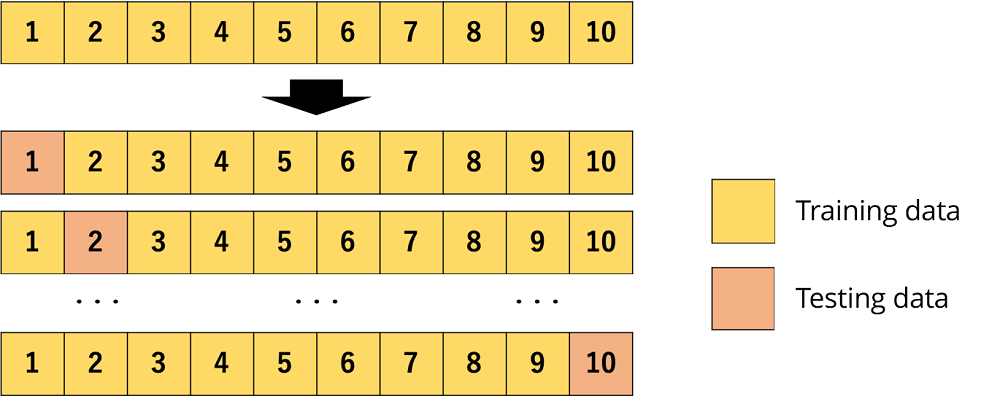
② 一個抜き交差検証(Leave-one-out Cross-validation)
サンプル数と同じだけデータをサブセットに分割をする交差検証。(k分割交差検証のkをデータ数とした場合と同じ。)
計算コストはかかるが、データを最大限活用することで評価結果の信頼性を高めることができる。

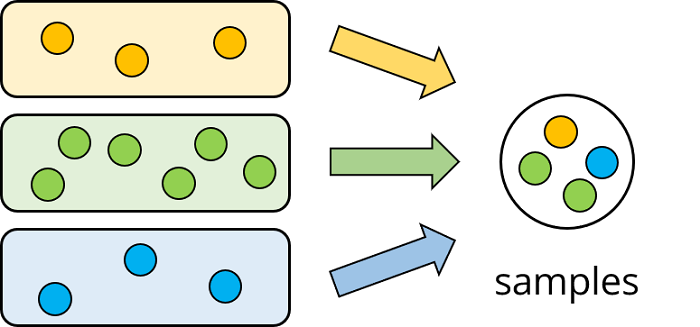
4. 層化抽出法(Stratified Sampling)
データを分割する際に、各クラスの比率を変えずに訓練及びテスト用データセットを構築する方法。
クラス間のデータの偏りを考慮してデータセットを構築することができる。
終わりに
備忘録として、よく使用するデータ分割法を簡潔にまとめました。
また知識がアップデートされたら追記・更新します!