イントロダクション
OpenCLは、ヘテロジニアスなマルチコア環境、特にGPUを含む系をターゲットとして広まってきたという印象がありますが、近年、その勢力図に変化が現れつつあります。マルチコアCPU、GPUに続くOpenCL界の第3勢力、それは・・・
F P G A。
本記事では、OpenCL for FPGAとはどのような技術なのか、マルチコアCPU/GPUに比べて本当にはやいのか・・・その光と闇を暴き、真実を明らかにしたいと思います。
FPGA向けOpenCL実装
2014年12月現在、OpenCL C言語を用いてデザインが可能なツールを出しているFPGAベンダーはAlteraとXilinxの2社です。
XilinxのSDAccelは先日リリースされたばかりで情報が少ないため、本記事ではAltera SDK for OpenCL(以下AOCL)を題材として取り上げます。
AOCLの構成要素は大きく分けて次の2つで:
- OpenCL C Compiler
- OpenCL Runtime Library
前者の役割は、OpenCL C言語をFPGAのビットストリームにコンパイルすること。すなわち、FPGA内部のロジックをデザインするためのツールです。後者はOpenCL APIを提供するライブラリ群で、CPU上で動作するユーザアプリケーションからFPGAを制御するために使われます。
これらの事実からも分かりますが、AOCLがターゲットとするハードウェアは何らかのバス経由でCPUとFPGAが接続されたシステム全体です。これは、現時点で存在する構成では、
- CPU+PCIeスロットに接続されたFPGAボード
- FPGA混載SoC
の2つと言っていいでしょう。
(原理的にはFPGA+FPGA上のソフトコアCPUという構成も可能です)
CPUとFPGAというヘテロ構成は、XilinxのZynqやAlteraのCyclone/Arria SoCのように組み込み機器向けのFPGA混載ARMとして一定の地位を築いてきましたが、直近ではIBMがCAPIでPower8にFPGAを接続したり、インテルがFPGA搭載プロセッサの投入を表明するなど、エンプラ向けデータセンタにも入りつつあります。HPC分野では重力多体問題専用計算機GRAPEが有名ですね。(GRAPE-DRからはASICになりましたが)
このようにCPUとFPGAを協調動作させてプログラマブルなシステムを構成するとなれば、ヘテロジニアス環境をターゲットとするOpenCLはもってこい、と言えるでしょう。
Altera OpenCL C Compiler
とはいえ、OpenCL C言語とFPGAの間にはあまりにも深い溝があるように思えます。この橋渡しをするのが、Altera OpenCL C Compilerです。
まず、AOCLのコンパイルフェーズは以下のふたつに分けられます。
- OpenCL C言語からQuartusⅡプロジェクトファイル群への変換
- QuartusⅡプロジェクトファイル群からFPGAビットストリームへの変換
FPGA界では、フェーズ1のようなビヘイビア(機能のみの記述)からRTLへの変換を動作合成・高位合成などと呼ぶようです。フェーズ2は一般的なFPGAのデザイン開発で用いられる手段と同じで、論理合成、配置配線、タイミング検証、ビットストリーム出力などの工程で構成されています。
AOCLのコンパイラはaocというコマンドラインツールとして提供されていて、以下のように使えます。
aoc hello.cl
__kernel void hello(void)
{
printf("hello\n");
}
このように何もオプションを付けない場合、引数に指定したOpenCLカーネルファイルをデフォルトのターゲットFPGAのビットストリームへと変換し、hello.aocxとして出力します。.aocxファイルはelf形式になっていて、FPGAビットストリームの他にもいくつかのメタデータが一緒に格納されています。
ちなみに、ターゲットFPGAの規模によりますが、フェーズ2の実行には小一時間は待つことになる上にメモリもバカ食いです。こればっかりは諦めて、メモリ32GBくらい積みましょう。
Verilogに変換した段階でコンパイルを止めたい場合には、-cオプションをつけましょう。
aoc -c hello.cl
引数から.clという拡張子を除いたディレクトリ内に、QuartusⅡのプロジェクトファイル群が出力されます。このプロジェクトファイル群にはOpenCL C言語から変換されたVerilogの他に、FPGAとCPUをつなぐバスやDMACなど、FPGAをOpenCLデバイスとして動作させるための周辺ロジックが全て含まれています。この、いわばOpenCLカーネルをはめ込むテンプレートに当たる部分をBSP(Board Support Package)と呼び、Altera自身やOpenCL対応FPGAデバイスを作っているサードパーティベンダが、ドライバとともに提供しています。ということは、BSPとドライバさえ用意できれば、自分たちで設計したFPGAデバイス上でOpenCLを用いたプログラミングが可能になる、ということですね。胸熱です。
フェーズ1で周辺回路が統合されるということは、ターゲットのFPGAデバイスをこの時点で選択する必要があります。このために、aocには--boardというオプションが用意されています。
aoc --board c5soc hello.cl
例えば上の例では、cyclone V SoC向けのビットストリームを作っています。選択できるデバイスの一覧を見るには次の通り。
aoc --list-boards
新しいデバイスをサポートしたBSPを入手した場合には、BSPへのパスをaocに教える必要があります。aocは環境変数AOCL_BOARD_PACKAGE_ROOTを参照してるので、こうやります。
AOCL_BOARD_PACKAGE_ROOT=/path/to/BSP aoc --list-boards
基本的には以上のコマンドが使えればhello worldくらいは動かすことができるでしょう。他のオプションは--helpを参照して下さい。
最後に、ちょっとマニアックな使い方について。
実はaoc自身はperlで書かれたコンパイラドライバで、フロントエンドはaocl-clang、バックエンドにはaocl-opt/aocl-llcという別の実行ファイルを呼び出しています。この名前から分かる通り、aocはclang/llvm上に構築されています。
aocはperlなのでちょっと読むと--helpでは出てこないオプションが幾つかあって、これを使うとLLVM IRを始めとする幾つかの内部情報をダンプすることができます。まあ、見れたところで解析するのは結構たいへんなのですが、最終結果のVerilogを直接読むより楽だったり有効な情報もあるので紹介します。
aoc -c --force-internal-rel hello.cl
社内開発時に使ってました感バリバリのオプション名ですね。
このオプションをつけると、以下の様な付加情報をコンパイル先ディレクトリの下にファイルとして出力してくれます。
- LLVM IRな中間コード
- カーネルから変換された回路の可視化
- メモリインターコネクトの構成
なお、AOCL 14.1以降ではオプションが以下のように変わっています。
aoc -c --save-temps --dot hello.cl
--save-tempsで中間コードをダンプでき、--dotでカーネルパイプラインやインターコネクトを可視化することができます。
Altera OpenCL Runtime Library
AOCLではターゲットデバイスがFPGAになっているだけで、Runtime LibrayのOpenCL APIセマンティクスは、基本的には他社のOpenCL実装と一緒です。ただし一点、AOCLではclCreateProgramWithSourceを使うことはできません。というのも、OpenCL CからFPGAビットストリームへの変換には長い時間がかかるため、AOCLはオンラインコンパイラを提供していないからです。
そこで、clCreateProgramWithBinaryを使用してビットストリームを含む.aocxファイルをロードし、cl_programを作ります。
// OpenCL C API直接使っていいのは小学生までだよねー
std::vector<char> code(load("hello.aocx", std::ios_base::binary));
cl::Program::Binaries binaries(1, std::make_pair(&code[0], code.size()));
cl::Program program(context, devices, binaries);
このAPI呼び出しにより、hello.aocxに格納されているFPGAビットストリームを使用して、FPGAのコンフィグレーションが行われます。あとは他のOpenCL実装と全く同じように使用できます。hello.ccの全容は以下のとおりです。
# define __CL_ENABLE_EXCEPTIONS
# include <CL/cl.hpp>
# include <cstdio>
# include <cstdlib>
# include <fstream>
# include <iostream>
# include <stdexcept>
std::vector<char> load(const char *path, std::ios_base::openmode mode=std::ios_base::in)
{
std::ifstream ifs(path, mode);
if (!ifs.is_open()) {
throw std::runtime_error(std::string("cannot open ") + std::string(path));
}
// get size
ifs.seekg(0, std::ifstream::end);
std::ifstream::pos_type end = ifs.tellg();
ifs.seekg(0, std::ifstream::beg);
std::ifstream::pos_type beg = ifs.tellg();
std::size_t buf_size = end-beg;
// read all
std::vector<char> buf(buf_size, 0);
ifs.read(&buf[0], buf_size);
return buf;
}
int main(int argc, const char** argv)
{
try {
std::vector<cl::Platform> platforms;
cl::Platform::get(&platforms);
if (platforms.empty()) {
throw std::runtime_error("cannot get OpenCL platforms");
}
cl::Platform platform(platforms[0]);
cl_context_properties properties[] = {
CL_CONTEXT_PLATFORM, (cl_context_properties)(platform)(), 0
};
cl::Context context(CL_DEVICE_TYPE_ALL, properties);
std::vector<cl::Device> devices(context.getInfo<CL_CONTEXT_DEVICES>());
CL_CONTEXT_PLATFORM, (cl_context_properties)(platform)(), 0
};
cl::Context context(CL_DEVICE_TYPE_ALL, properties);
std::vector<cl::Device> devices(context.getInfo<CL_CONTEXT_DEVICES>());
std::vector<char> code(load("hello.aocx", std::ios_base::binary));
cl::Program::Binaries binaries(1,
std::make_pair(&code[0], code.size()));
cl::Program program(context, devices, binaries);
cl::Kernel kernel(program, "hello");
cl::Event event;
cl::CommandQueue queue(context, devices[0], 0);
queue.enqueueNDRangeKernel(
kernel,
cl::NullRange,
cl::NDRange(4,4),
cl::NDRange(1,1),
NULL,
&event);
event.wait();
} catch (const cl::Error& err) {
std::cerr
<< "ERROR: "
<< err.what()
<< "("
<< err.err()
<< ")"
<< std::endl;
return -1;
}
return 0;
}
ハードウェアへのマッピング
ここからはOpenCL C言語がどのような回路にマッピングされるかについて解説します。
まずは大枠から行きましょう。次のコードは、どのような回路に変換されるでしょうか?
__kernel
void add(__global const float* a, __global const float *b, __global float *c)
{
*c = *a + *b;
}
すごーくざっくり描くと、こうです。
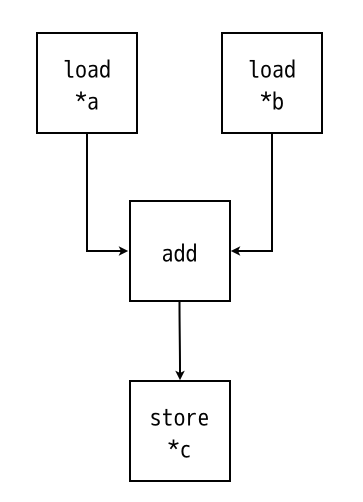
2つのロードユニット、1つの32bitの浮動小数点数加算、1つのストアユニットから構成される回路へと変換されました。実際はもうちょっと複雑なのですが、本質は変わりません。このように、AOCLは、構文木をそのまま回路へ変換するという実にシンプルなルールによって、動作合成を行っています。
さて、ここで問題です。この回路が200MHzで動作した場合、一秒間に何回の浮動小数点数演算を行うことができますか?
…
……
………
わかりましたか?
わかったというそこのあなた、すごいですね。今すぐエスパーへの転職をおすすめします。
実は、今ある情報だけでは、この回路の性能はわかりません。上の絵からは、次のような情報が何も読み取れないからです。
- LSUやALUが何サイクルで動作するのか
- どの部分が1サイクル中に動作を完了できるのか
これらは全て、コンパイラが何かすごい解析をして(すみません、あまり詳しくないです)決定します。で、OpenCLカーネルの実装者たる我々は、これらの情報を知ることはできますが、コントロールすることはできません。つまり、大前提として、OpenCL C言語を使う以上、所要サイクル数をきっちり決めた回路を作ることはできないのです。
先ほど紹介した--force-internal-rel (14.1以降は--dot) オプションを使用してカーネルを可視化することで、回路のレイテンシを見ることができます。例えばadd.clをコンパイルすると、add.dotというGraphviz形式のファイルがaddディレクトリ以下に出力されます。
こんな感じで変換すると、
dot -Tpng < add.dot > add.png
こうです。
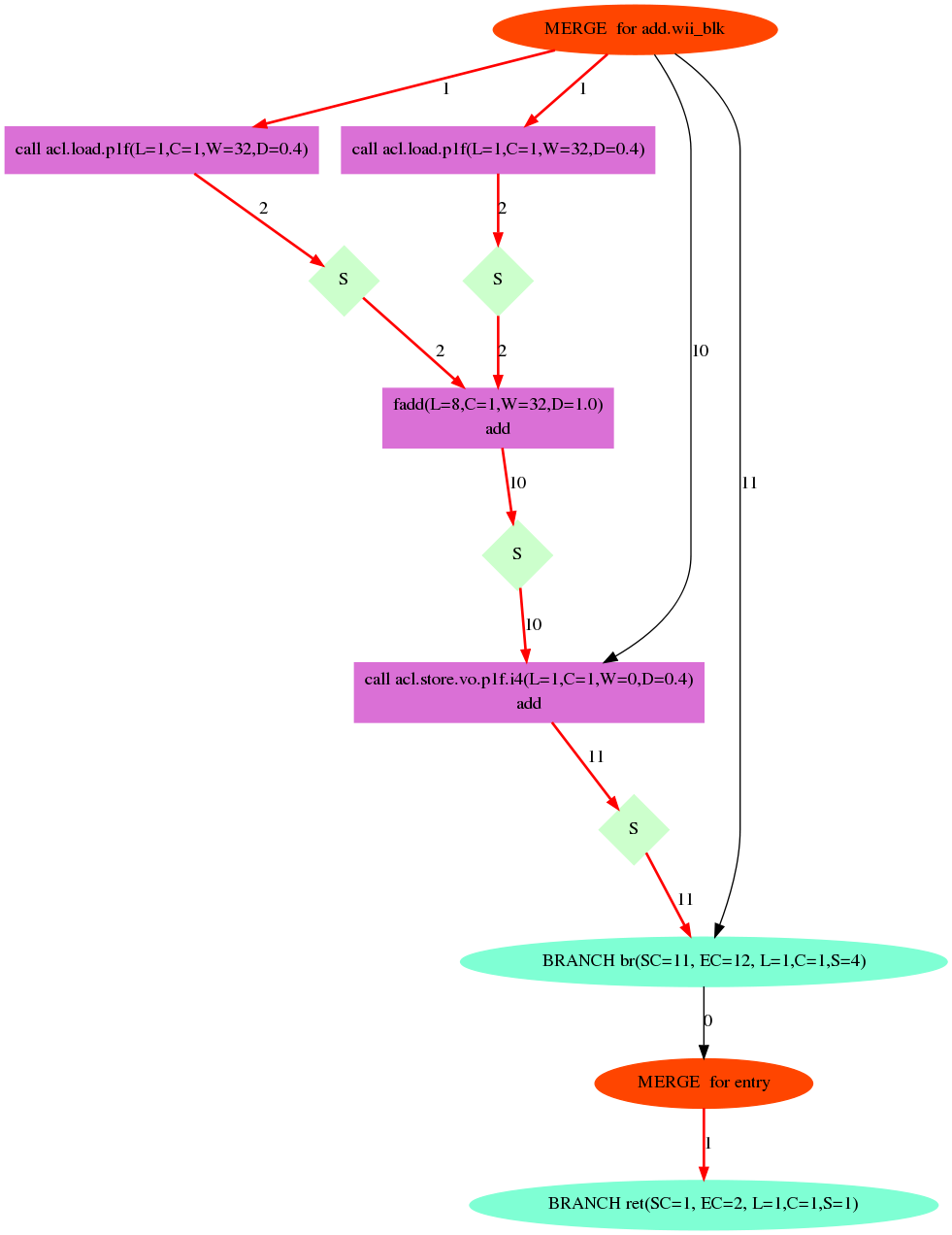
この図の読み方は公式のドキュメントには書いていないのですが、なんとなく雰囲気から察すると↓
たとえば真ん中にある紫のブロック、faddのノードには(L=8, C=...)などと書いてありますが、Lがノードが必要とするサイクル数です。つまり、この場合、faddはレイテンシ8です。
ノード間のエッジに付記されている数字が、そのエッジに至るベーシックブロック内のサイクル数を表します。赤いラインが回路のクリティカル・パスになっていて、このパス中の回路を最適化すれば、回路全体のサイクル数が縮まる可能性があります。
スレッド
OpenCL Cの言語規格にはスレッドモデルが規定されていて、最小単位はワークアイテムと呼ばれています。
例えば、おなじみのvecaddを例に:
__kernel
void vecadd(__global const int* a, __global const int *b, __global int *c)
{
const uint i = get_global_id(0);
c[i] = a[i] + b[i];
}
もちろんAOCLは、このカーネルもコンパイルできます。
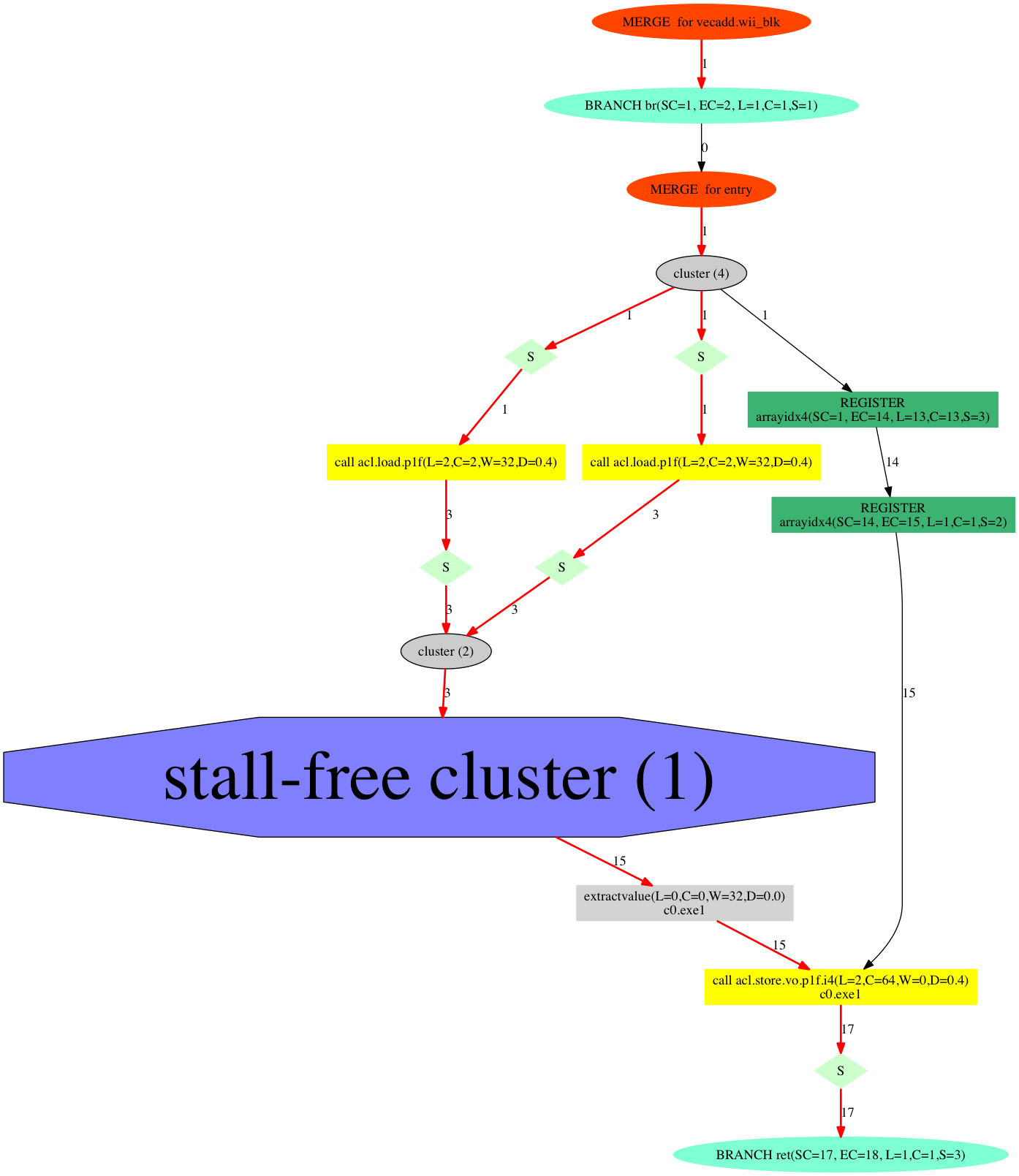
はて、さっき見たものとほとんど同じですね。vecaddはワークアイテム数だけ加算を行う必要がありますが、どうやってその動作を達成するのでしょうか?
答えは、こうです:
そう、パイプラインです!この回路は、理想的には1サイクルに1ワークアイテムの計算を行うことができます。
つまり、多くのGPU向けOpenCL実装が、ワークアイテムを複数の演算コア、すなわち空間方向に展開しているのとは対照的に、AOCLは__パイプライニングによって時間方向へ展開する__という真逆のアプローチを取っているのです。
分岐
GPUではワークアイテム(正確にはwarp/wavefront内のワークアイテム)が別のコントロールフローを通ると、全てのコントロールフローを順次実行し結果をマスクするという挙動をするため、分岐コストがデカイです。
例えばこれ。
__kernel
void branch(__global const int *a, __global const int *b, __global int *c)
{
const uint i = get_global_id(0);
if (i & 0x1) {
c[i] = sugoku_osoi_kansu(a[i], b[i]);
} else {
c[i] = totemo_osoi_kansu(a[i], b[i]);
}
}
GPUなら分岐部分は倍遅くなります。でも、AOCLなら大丈夫。
各コントロールフローがそのまま回路へと変換され、分岐条件に基づいて結果をセレクトするだけなので、
レイテンシの一番長いコントロールフローに引っ張られるだけで済みます。かわりに、コントロールフローの数だけ回路が作られるので、FPGAのリソース消費が増大します。
こういった現象がおこるのも、GPUとFPGAではワークアイテムの展開方向が逆転しているからです。
ループ
もうひとつの制御構造、ループに着目します。AOCLはループをどのような回路に変換するでしょうか。
__kernel
void loop(__global const int *src, const int num, __global int *dst)
{
const uint i = get_global_id(0);
int sum = 0;
for (uint j=0; j<num; ++j) {
sum += src[num*i+j];
}
dst[i] = sum;
}
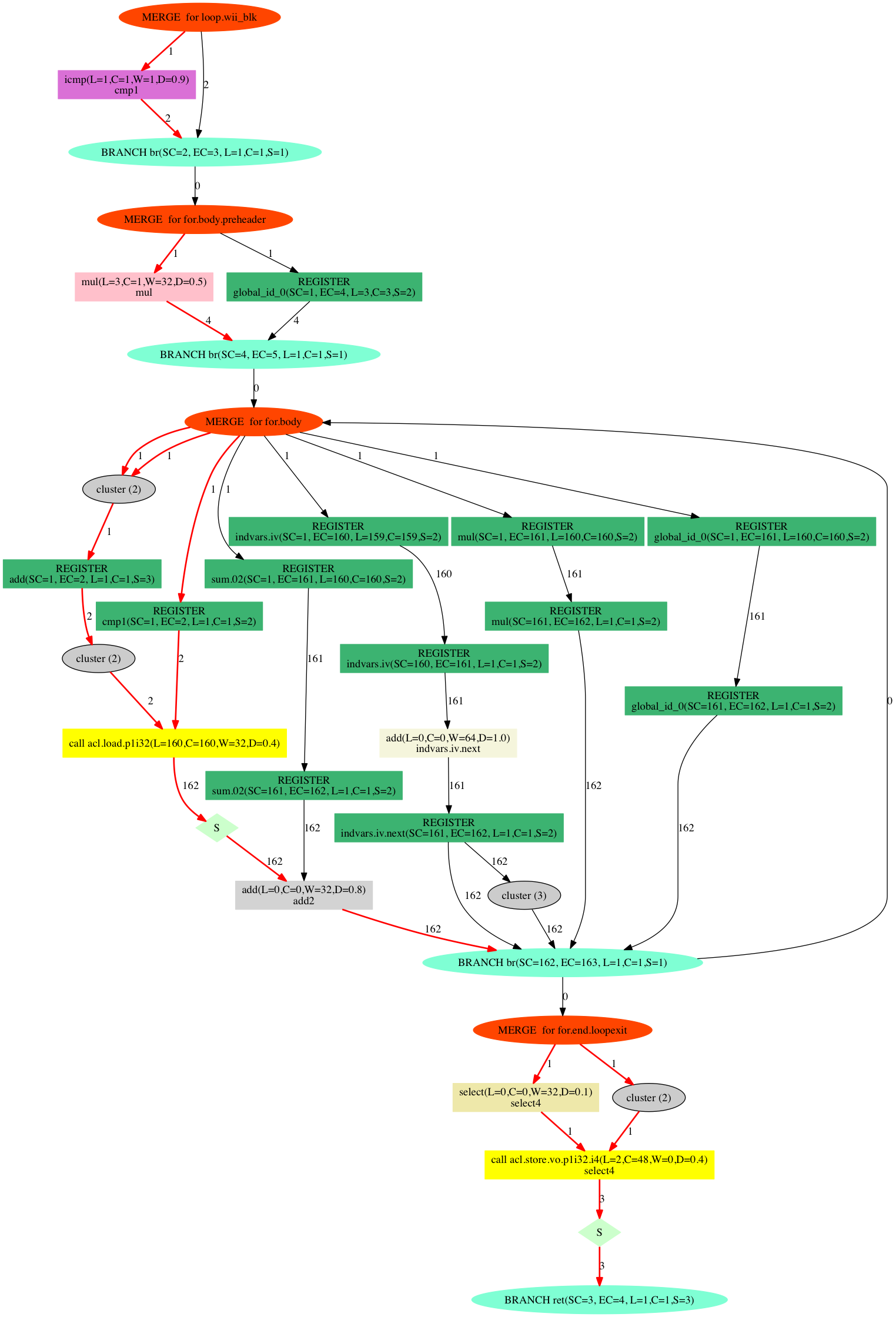
中央右端を上に向かって伸びるエッジがMERGE for for.bodyというノードにつながり、今まで存在しなかった、循環が形成されました。パイプライン中のデータがフィードバックされそうな雰囲気ですね。
このパイプラインのスループット(1サイクルあたりに処理できる平均ワークアイテム数)を考えてみましょう。パイプライン中をストールなく全てのワークアイテムが流れた、と仮定すれば、スループットは1です。
ちょっと考えると、循環が存在する回路ではこの状況が起こりえないことがわかります。例えば、ワークアイテム数30、ループ回数を2と仮定すると、sum+=src[numi+j]という式由来の加算回路には、302=60回はデータが流れる必要があります。つまりこのパイプラインは最低でも60サイクルはかかる・・・ということは、スループットは0.5です。
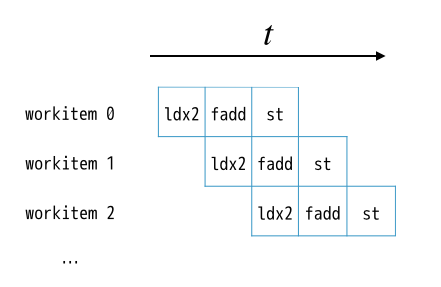
ループの制御について、もう少し詳しく説明します。まず、ループ先頭にはFIFOが作られます。全てのワークアイテムはこのFIFOを経由して、ループブロック内の回路へと供給されます。ループブロックのパイプラインの深さは15なので、15個のワークアイテムは常にこのループ中を流れることができて、ループから脱出するワークアイテムがあると後続のワークアイテムがFIFOからデキューされ、ループブロックに入ります。
言葉だけだとわかりにくいですね。ループブロック部分をloadとaddだけ構成されていると仮定した場合、パイプラインの動作を可視化するとこんな感じです。
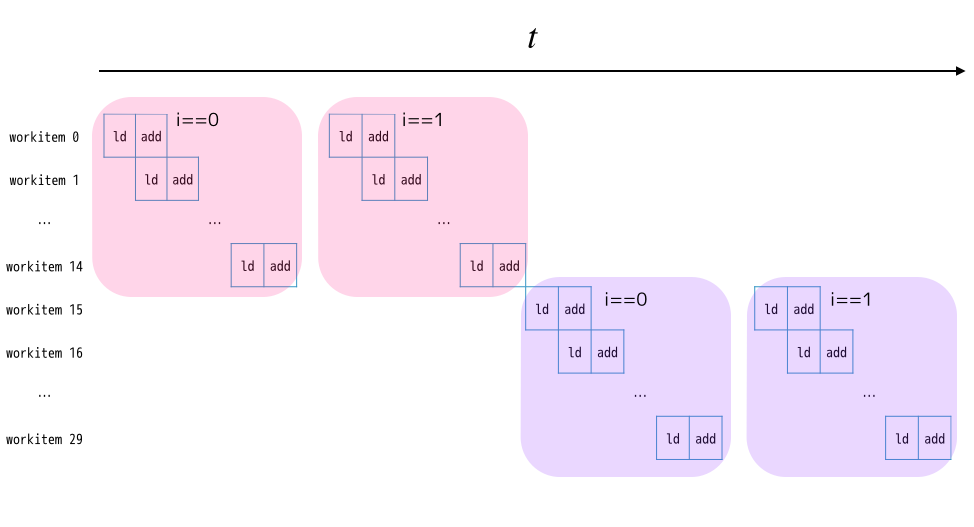
まとめると、繰り返しを含むパイプラインのスループットは、「1/繰り返しの回数」になります。
まとめ
OpenCL for FPGAの概要について説明しました。次回、「OpenCL meets FPGA #2 最適化編」に続きます。