Parsl について

Parsl の名前の由来は Parallel Scripting Library で、文字通りPython で実装された並列処理を行うためのライブラリです。 Parsl を使用すると、Pythonの関数とシェルやコマンドなどの外部コンポーネントで構成される並列プログラムを依存関係で結びつけて非同期・並列のワークフローを作成し実行することができます。ラップトップから共有メモリのマルチコアサーバー、小規模なHPCクラスター、クラウドのKubernetes、スーパーコンピュータまで、あらゆる計算リソースでParslプログラムを実行できるため、容易にスケールアップすることができます。
Parsl は次のような特徴を持っています。
- コードと実行環境の分離:任意の実行プロバイダ(PC、クラスター、スーパーコンピュータ、クラウドなど)や実行モデル(スレッド、パイロットジョブなど)、エグゼキューター(Slurm、SGE、PBSなど)をサポートするように設計されています
- 暗黙的な並列処理:関数をデコレータでアノテーションするだけで非同期に実行される
- ファイル抽象化:ローカルファイルと同様にリモートファイルを扱うことができる
- データフローモデルのワークフローを定義することができる
- 実行中にワークフローが決定される動的ワークフローを定義できる
- ノートブックやその他のインタラクティブなメカニズムによるインタラクティブな並列プログラミング
- 実行状況のモニタリング
Jupyterlab でのオンラインデモ が公開されているので、すぐに試用することができます。
導入事例 で紹介されているように、Parslは様々な科学分野の幅広い研究者に利用されています。
インストール
parsl は pip コマンドでインストールすることができます。
$ pip install parsl
parsl の使用方法
次の例は、"hello world" を出力するPython の関数とBashスクリプトを使った簡単なParslプログラムの書き方です。
In [2]: # %load 01_intro.py
...: import parsl
...: import os
...: from parsl.app.app import python_app, bash_app
...:
...: conf = parsl.load()
...:
...: @python_app
...: def hello_python (message):
...: return f'Hello {message}'
...:
...: @bash_app
...: def hello_bash(message, stdout='hello-stdout'):
...: return f'echo "Hello {message}"'
...:
...: # Pythonアプリを起動
...: p = hello_python('World (Python)')
...:
...: # Bashスクリプトを実行
...: b = hello_bash('World (Bash)')
...: c = b.result()
...:
...: # 結果を表示する
...: print(p.result())
...: with open('hello-stdout', 'r') as f:
...: print(f.read())
...:
...: print(f'bash exit code: {c}')
...:
Hello World (Python)
Hello World (Bash)
bash exit code: 0
In [3]:
Parsl は Python の関数を @python_app デコレータを使ってアプリ(Apps)として、また @bash_app デコレータを使って外部アプリケーションを呼び出すアプリとしてラップします。デコレーションされた関数は、すべての入力の準備ができたときに並列に実行することができます。
実行ログ
parsl プログラムを実行すると、カレントディレクトリに runinfoディレクトリが作成されて、実行ログが記録されます。
% tree -L 2 runinfo
runinfo
├── 000
│ └── parsl.log
└── 001
└── parsl.log
2 directories, 2 files
詳細はここでは触れませんが、次のようなログが記録されます。
% cat runinfo/000/parsl.log
2021-10-10 08:27:54.939 parsl.dataflow.dflow:84 [DEBUG] Starting DataFlowKernel with config
Config(
app_cache=True,
checkpoint_files=None,
checkpoint_mode=None,
checkpoint_period=None,
executors=[ThreadPoolExecutor(
label='threads',
managed=True,
max_threads=2,
storage_access=None,
thread_name_prefix='',
working_dir=None
)],
garbage_collect=True,
initialize_logging=True,
internal_tasks_max_threads=10,
max_idletime=120.0,
monitoring=None,
retries=0,
run_dir='runinfo',
strategy='simple',
usage_tracking=False
)
2021-10-10 08:27:54.939 parsl.dataflow.dflow:86 [INFO] Parsl version: 1.1.0
2021-10-10 08:27:54.939 parsl.dataflow.usage_tracking.usage:125 [DEBUG] Tracking status: False
2021-10-10 08:27:54.939 parsl.dataflow.dflow:114 [INFO] Run id is: 4cf091d5-7477-4531-8313-388558e2bd46
2021-10-10 08:27:55.149 parsl.dataflow.memoization:164 [INFO] App caching initialized
2021-10-10 08:27:55.149 parsl.dataflow.strategy:127 [DEBUG] Scaling strategy: simple
2021-10-10 08:27:55.163 parsl.dataflow.dflow:795 [DEBUG] Task 0 will be sent to executor threads
(以下略)
Parsl の set_stream_logger() を呼び出すと、実行ログは標準出力にも送出されるようになります。
In [2]: # %load 02_logging.py
...: import parsl
...: import os
...: from parsl.app.app import python_app, bash_app
...:
...: # すべてのログを標準出力へ送出
...: parsl.set_stream_logger()
...:
...: conf = parsl.load()
...:
...: @python_app
...: def hello_python (message):
...: return f'Hello {message}'
...:
...: @bash_app
...: def hello_bash(message, stdout='hello-stdout'):
...: return f'echo "Hello {message}"'
...:
...: # Pythonアプリを起動
...: p = hello_python('World (Python)')
...:
...: # Bashスクリプトを実行
...: b = hello_bash('World (Bash)')
...: c = b.result()
...:
...: # 結果を表示する
...: print(p.result())
...: with open('hello-stdout', 'r') as f:
...: print(f.read())
...:
...: print(f'bash exit code: {c}')
...:
2021-10-10 08:29:17 parsl.dataflow.rundirs:35 [DEBUG] Parsl run initializing in rundir: runinfo/007
2021-10-10 08:29:17 parsl.dataflow.dflow:84 [DEBUG] Starting DataFlowKernel with config
Config(
app_cache=True,
checkpoint_files=None,
checkpoint_mode=None,
checkpoint_period=None,
executors=[ThreadPoolExecutor(
label='threads',
managed=True,
max_threads=2,
storage_access=None,
thread_name_prefix='',
working_dir=None
)],
garbage_collect=True,
initialize_logging=True,
internal_tasks_max_threads=10,
max_idletime=120.0,
monitoring=None,
retries=0,
run_dir='runinfo',
strategy='simple',
usage_tracking=False
)
2021-10-10 08:29:17 parsl.dataflow.dflow:86 [INFO] Parsl version: 1.1.0
2021-10-10 08:29:17 parsl.dataflow.usage_tracking.usage:125 [DEBUG] Tracking status: False
2021-10-10 08:29:17 parsl.dataflow.dflow:114 [INFO] Run id is: e0e4cbeb-4677-4643-b012-9bdd0427a036
(中略)
Hello World (Python)
Hello World (Bash)
bash exit code: 0
In [3]:
Parslの設定
Parslはコードと実行環境を分離します。そのためには、実行時に使用するリソースのプール(クラスター、クラウド、スレッドなど)を記述する構成モデルに依存します。
前述の例では、ローカルでの並列実行を容易にするために、スレッドのローカルプールを使用するように設定します。
conf = parsl.load()
これは、次と同じことです。
from parsl.configs.local_threads import config
conf = pars.load(config)
これにより、デフォルトの設定が読み込まれます。
In [3]: conf.config
Out[3]:
Config(
app_cache=True,
checkpoint_files=None,
checkpoint_mode=None,
checkpoint_period=None,
executors=[ThreadPoolExecutor(
label='threads',
managed=True,
max_threads=2,
storage_access=None,
thread_name_prefix='',
working_dir=None
)],
garbage_collect=True,
initialize_logging=True,
internal_tasks_max_threads=10,
max_idletime=120.0,
monitoring=None,
retries=0,
run_dir='runinfo',
strategy='simple',
usage_tracking=False
)
使用状況の追跡
Parsl はオープンソースで無料で使用することができます。しかし、Parsl プロジェクトは米国の資金提供機関 NSF(National Science Foundatioon) から資金提供を受けて開発がされています。Parsl プロジェクトが資金提供を受け続けるため、およびNSF自身が資金提供を主張するためには、こうした投資によって科学界が恩恵を受けていることを証明する必要があることから、Parsl では使用状況を追跡するための機能を備えています。
環境変数 PARSL_TRACKING=trueを設定するか、設定オブジェクト(parsl.config.Config)でusage_tracking=Trueを設定することで、Parslプロジェクトへ使用状況を送信することができます。
デフォルトは通知しないようになっています。
Parslプロジェクトでは、可能な限り匿名化された使用状況の追跡から、使用状況の測定、バグの特定、ユーザビリティ、信頼性、パフォーマンスの向上を図っています。利用状況の集計は、NSFへの報告目的でのみ使用されます。
Parslプロジェクトに送信される情報は次のものです。
- 匿名化されたユーザーID
- 匿名化されたホスト名
- 匿名化されたParslスクリプトID
- 開始時刻と終了時刻
- Parslの終了コード
- 使用されたエクゼキュータの数
- 失敗の数
- ParslとPythonのバージョン
- OSとOSのバージョン
この機能の詳細は、 ドキュメントの Usage statistics collectionを参照してください。
Parsl の構成要素
Parsl は次のコンポーネントから構成されています。
- アプリ(Apps):python_app、bash_app、join_app
- Futures:AppFutures、DataFutures
- File:ローカルファイル、リモートファイル
- ワークフロー
アプリ(Apps)
Parslでのアプリ(Apps)とは、実行リソース(クラウド、クラスタ、ローカルPCなど)上で非同期に実行できるコードの断片のことをいいます。Parslは純粋なPythonアプリ(python_app)と、Bashで実行されるコマンドラインアプリ(bash_app)、他のアプリを組み合わせてサブワークフローを形成することができるJoinアプリ(join_app)を提供しています。
Pythonアプリ(python_app)
最初の例として、文字列'Hello World!'を返す簡単なPython関数を定義してみましょう。この関数は、@python_appデコレーターを使ってParslアプリにします。
@python_app
def hello ():
return 'Hello World!'
print(hello().result())
In [2]: # %load 03_python_app.py
...: import parsl
...: from parsl.app.app import python_app
...: # from parsl.configs.local_threads import config
...:
...: config = parsl.load()
...:
...: @python_app
...: def hello_python():
...: return 'Hello world'
...:
...: future = hello_python()
...: print(future .result())
...:
Hello world
In [3]:
この例からもわかるように、python_app は標準的なPythonの関数呼び出しをラップしています。そのため、任意の引数を渡すことができ、標準的なPythonオブジェクトを返すことができます。
In [2]: # %load 04_multiply.py
...: import parsl
...: from parsl.app.app import python_app
...: # from parsl.configs.local_threads import config
...:
...: config = parsl.load()
...:
...: @python_app
...: def multiply(a, b):
...: return a * b
...:
...: app = multiply(5, 9)
...: print(app.result())
...:
45
In [3]:
Parslアプリはリモートで実行される可能性があることに注意してください。そのため、必要な依存関係はすべて関数本体に含めておく必要があります。例えば、アプリがdatetimeライブラリを必要とする場合、関数内でそのライブラリをインポートする必要があります。
In [2]: # %load 05_hello_with_time.py
...: import parsl
...: from parsl.app.app import python_app
...: # from parsl.configs.local_threads import config
...:
...: config = parsl.load()
...:
...: @python_app
...: def hello_python():
...: import datetime
...: return f'Hello world: {datetime.datetime.now()}'
...:
...: app = hello_python()
...: print(app.result())
...:
Hello world: 2021-10-10 09:08:14.044477
Bashアプリ(bash_app)
ParslのBashアプリは、Bashシェルのように、外部アプリケーションの実行をコマンドラインからラップすることができます。また、Bashスクリプトを直接実行するためにも使用することができます。Bashアプリを定義するには、ラップされたPython関数が、実行されるコマンドライン文字列を返す必要があります。
Bashアプリの最初の例として、Linuxのコマンドechoを使って文字列Hello World!を返してみましょう。この関数は@bash_appデコレーターを使ってBashアプリにしています。
なお、echoコマンドは、Hello World! を標準出力に出力します。この出力を使用するためには、標準出力をキャプチャするようにParslに指示する必要があります。これは app 関数で stdout キーワード引数を指定することで行います。stderrをキャプチャするときも同様です。
In [2]: # %load 06_bash_app.py
...: import parsl
...: from parsl.app.app import bash_app
...: # from parsl.configs.local_threads import config
...:
...: config = parsl.load()
...:
...: @bash_app
...: def echo_hello(stdout='echo-hello.stdout', stderr='echo-hello.stderr'):
...: return 'echo "Hello World!"'
...:
...: app = echo_hello()
...: c = app.result()
...:
...: with open('echo-hello.stdout', 'r') as f:
...: print(f.read())
...:
...: print(f'ExitCode: {c}')
...:
Hello World!
ExitCode: 0
In [3]:
result()`メソッドを呼び出すと、実行したコマンドの終了コードが返されます。
Joinアプリ
Joinアプリは @join_app デコレーターで指定できます。
Joinアプリは、ワークフローがいくつかのアプリを起動する必要があるが、いくつかの初期のアプリが完了するまで、それらのアプリを特定できない場合に便利です。
例えば、前処理ステージの後にN個の中間ステージが続くが、Nの値は前処理が完了するまでわからない場合や、実行するアプリの選択が前処理の出力に依存する場合などです。
次のコードは、pre_process()の後に、option_one()またはoption_two()のアプリを選択し、その後にpost_process()を呼び出す場合の例です。
@python_app
def pre_process():
return 3
@python_app
def option_one(x):
# 何かの処理
return x*2
@python_app
def option_two(x):
# 何かの処理
return (-x) * 2
@join_app
def process(x):
if x > 0:
return option_one(x)
else:
return option_two(x)
@python_app
def post_process(x):
return str(x)
post_process(process(pre_process()))).result()]
もしJoinアプリの機能がない場合は次のようなPythonアプリをコードすることになります。
@python_app
def process(x):
if x > 0:
f = option_one(x)
else:
f = option_two(x)
return f.result()
これは option_one()とoption_two() が完了するまでワーカーの実行プロセスをブロックすることになります。
option_one()とoption_two() を実行するのに十分なワーカーが存在しない場合、これはデッドロックになる可能性があります。
Parslでは、アプリは他のアプリの完了を待つようなコードはするべきではありません。常に依存関係を通じてparslに処理させるように留意してください。
データの受け渡し
Parslアプリは、Pythonオブジェクトまたはファイルの形でデータを交換できます。データフロー セマンティクスを実施するために、Parsl はアプリに出入りするデータを追跡する必要があります。これらの依存関係をParslに認識させるために、Parslアプリの関数はinputsとoutputsのキーワード引数を与えることができます。
まず、hello1.txt、hello2.txt、hello3.txtという名前の3つのテストファイルを作成します。このファイルには、"hello 1"、"hello 2"、"hello 3"というテキストが含まれています。
In [2]: # %load 07_create_testfiles.py
...: import os
...:
...: cwd = os.getcwd()
...: for i in range(3):
...: with open(os.path.join(cwd, f'hello-{i}.txt'), 'w') as f:
...: c = f.write('hello {}\n'.format(i))
...:
In [3]:
次のようにテスト用の helloファイルが作成されます。
% grep hello hello-[012].txt
hello-0.txt:hello 0
hello-1.txt:hello 1
hello-2.txt:hello 2
次に、catコマンドを使ってこれらのファイルを連結するアプリを書いてみましょう。helloファイルのリストを入力し(インプット)、そのテキストを連結してall_hellos.txtという名前の新しいファイルを作成します(アウトプット)。後述するように、catアプリが別のコンピュータで実行される場合には、Parsl Fileオブジェクトを使用してファイルの場所を抽象化します。
In [2]: # %load 08_concentate_testfiles.py
...: import parsl
...: from parsl.app.app import bash_app
...: from parsl.data_provider.files import File
...:
...: config = parsl.load()
...:
...: @bash_app
...: def cat(inputs=[], outputs=[]):
...: infiles = " ".join([i.filepath for i in inputs])
...: return f'cat {infiles} > {outputs[0]}'
...:
...: cwd = os.getcwd()
...: concat = cat(inputs=[File(os.path.join(cwd, 'hello-0.txt')),
...: File(os.path.join(cwd, 'hello-1.txt')),
...: File(os.path.join(cwd, 'hello-2.txt'))],
...: outputs=[File(os.path.join(cwd, 'all_hellos.txt'))])
...:
...: # 結果ファイルを読み出す
...: with open(concat.outputs[0].result(), 'r') as f:
...: print(f.read())
...:
hello 0
hello 1
hello 2
In [3]: !cat all_hellos.txt
hello 0
hello 1
hello 2
In [4]:
Futures
Futuresの言葉の意味としては、「未来」や金融デリバティブの「先物取引」をいいます。Parslのプログラミングでは、「未来」の概念に基づいています。 通常のPython関数が呼び出されると、Pythonインタープリタは関数の実行が完了するのを待ち、結果を返します。長時間実行される関数の場合、完了を待つことは望ましくないかもしれません。そうしたときは、関数は非同期に実行される方がよいはずです。
Parslでは 関数を呼び出すと、その関数が計算する「未来の値」を表す Futuresオブジェクトがすぐに返されます。 関数の計算が別の実行スレッドで行われている間、呼び出したスレッドは他の作業を行うことができます。 呼び出し側のスレッドは、後で関数が完了するのを待って、結果を取得することができます。Future は基本的にParslが非同期タスクのステータスを追跡するためのオブジェクトで、ステータスや結果を調べることができるようになっています。
Parslには重要な2種類のFuturesがあります。AppFutures と DataFutures です。これらの2つのタイプのFuturesは、関連していますが、微妙に異なるワークフローパターンの構築を可能にします。
AppFutures
AppFuturesは、Parslスクリプトが構築される基本的な構成要素です。Parslアプリの呼び出しはすべてAppFutureを返し、アプリの実行を管理したり、ワークフローを制御したりするのに使われます。
次のコードは、Pythonアプリの結果を待つためにAppFuturesがどのように使用されるかを示したものです。
In [2]: # %load 09_app_futures.py
...: import parsl
...: from parsl.app.app import python_app
...:
...: config = parsl.load()
...:
...: @python_app
...: def hello():
...: import time
...: time.sleep(5)
...: return 'Hello World'
...:
...: app = hello()
...:
...: # app が終了済みかどうかをチェックする
...: print(f'Done: {app.done()}')
...:
...: # app の結果を出力する
...: # 注意:この呼び出しはブロックされ、app の終了を待つ
...: print(f'Result: {app.result()}')
...:
...: print(f'Done: {app.done()}')
...:
Done: False
Result: Hello World
Done: True
In [3]:
DataFutures
AppFuturesが非同期アプリの実行を表すのに対し、DataFuturesはアプリが生成するファイルを表します。Parslのデータフローモデルでは、データはファイルを介してあるアプリから別のアプリへと流れますが、アプリが必要なファイルの作成を検証し、入力ファイルが作成されたときにその後の依存関係を解決するために、このような構造が必要なわけです。アプリを起動する際、Parslは出力ファイルのリストを指定する必要があります(outputsキーワード引数を使用)。アプリが実行されると、各ファイルのDataFutureが返されます。アプリの実行中、Parsl はこれらのファイルを監視し、1) ファイルが作成されていることを確認し、2) 依存するアプリにファイルを渡します。
In [2]: # %load 10_data_futures.py
...: import parsl
...: import os
...: from parsl.app.app import python_app, bash_app
...: from parsl.data_provider.files import File
...:
...: config = parsl.load()
...:
...: # 入力で与えられた message を出力ファイルに出力するアプリ
...: @bash_app
...: def slowecho(message, outputs=[]):
...: cmdline = f'sleep 5; echo {message} &> {outputs[0]}'
...: return cmdline
...:
...: # 出力ファイルを指定してslowechoを呼び出す
...: outfile = File(os.path.join(os.getcwd(), 'hello-world.txt'))
...: hello = slowecho('Hello World!', outputs=[outfile])
...:
...: # AppFutureのoutputs プロパティーは、DataFuturesのリストです。
...: print(hello.outputs)
...:
...: # AppFutures が終了したかチェック
...: print(f'Done: {hello.done()}')
...:
...: # 出力されたDataFutureの内容を、AppFuture の終了時に出力する
...: with open(hello.outputs[0].result(), 'r') as f:
...: print(f.read())
...:
...: # ここでDataFutures とAppFuture が終了したかを確認
...: print(hello.outputs)
...: print(f'Done: {hello.done()}')
...:
[<DataFuture at 0x7f17277ff610 state=pending>]
Done: False
Hello World!
[<DataFuture at 0x7f17277ff610 state=finished with file <<class 'parsl.data_provider.files.File'> at 0x7f17384499d0 url=/home/iisaka/Tutorial.Parsl/01_Intro/hello-world.txt scheme=file netloc= path=/home/iisaka/Tutorial.Parsl/01_Intro/hello-world.txt filename=hello-world.txt>>]
Done: True
In [3]:
データ管理
Parslはデータフローパターンの実装を可能にするように設計されています。これらのパターンは、アプリケーション間で渡されるデータが実行の流れを管理するワークフローを定義することができます。データフローのプログラミングモデルは、多くのアプリケーションで必要とされる並行処理を、暗黙の並列処理によってシンプルかつ直感的に表現することができるため、人気があります。
ファイル
Parslのファイル抽象化は、アプリケーションの実行場所に関わらず、ファイルへのアクセスを抽象化します。アプリ内でParslのファイルを参照する(filepathを呼び出す)と、Parslはアプリが実行されているファイルシステムに対するファイルの位置にパスを変換します。
In [2]: # %load 11_filepath.py
...: import parsl
...: from parsl.app.app import python_app, bash_app
...: from parsl.data_provider.files import File
...:
...: config = parsl.load()
...:
...: # ファイルの内容を別のファイルにコピーするアプリ
...: @bash_app
...: def copy(inputs=[], outputs=[]):
...: cmdline = f'cat {inputs[0]} &> {outputs[0]}'
...: return cmdline
...:
...: # テストファイルの作成
...: cwd = os.getcwd()
...: c = open(os.path.join(cwd, 'cat-in.txt'), 'w').write('Hello World!\n')
...:
...: # Parslの Fileオブジェクトを作成
...: parsl_infile = File(os.path.join(cwd, 'cat-in.txt'),)
...: parsl_outfile = File(os.path.join(cwd, 'cat-out.txt'),)
...:
...: # copy アプリへ Parsl の File オブジェクトを渡して呼び出す
...: copy_future = copy(inputs=[parsl_infile], outputs=[parsl_outfile])
...:
...: # 結果を読み出す
...: with open(copy_future.outputs[0].result(), 'r') as f:
...: print(f.read())
...:
Hello World!
In [3]:
リモートファイル
Parslのファイル抽象化では、リモートでアクセス可能なファイルを表現することもできます。この場合、ファイルのリモートロケーションを使用してFileオブジェクトをインスタンス化することができます。Parsl は依存するアプリを実行する前に、ファイルを実行環境に自動でステージングします。また、Parsl はファイルの場所をローカル ファイル パスに変換して、依存するアプリがローカル ファイルと同じ方法でファイルにアクセスできるようにします。Parsl は Globus、FTP、HTTP、rsync でアクセス可能なファイルをサポートしています。
次のコードは、内容に乱数を含んだ一般にアクセス可能なファイルからFileオブジェクトを作成します。このオブジェクトは、ローカルファイルと同じように sort_numbers() アプリに渡すことができます。
In [2]: # %load 12_remote_file.py
...: import parsl
...: from parsl.app.app import python_app
...: from parsl.data_provider.files import File
...:
...: parsl.load()
...:
...: @python_app
...: def sort_numbers(inputs=[]):
...: with open(inputs[0].filepath, 'r') as f:
...: strs = [n.strip() for n in f.readlines()]
...: strs.sort()
...: return strs
...:
...: unsorted_file = File('https://raw.githubusercontent.com/Parsl/parsl-tuto
...: rial/master/input/unsorted.txt')
...:
...: f = sort_numbers(inputs=[unsorted_file])
...: print (f.result())
...:
Out[2]: <parsl.dataflow.dflow.DataFlowKernel at 0x110800dc0>
['0', '1', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '2', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '3', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '4', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '5', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '6', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '7', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '8', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '9', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99']
In [3]:
ワークフローの構築
Parsl でワークフローを作成してみましょう。他のワークフローシステムとは異なり、Parslはデーターフローモデルに基づいてワークフローを作成します。つまり、アプリ間の制御やデータの受け渡しから、暗黙のワークフローが作成されます。このモデルの柔軟性により、シーケンシャルなワークフローから複雑なネストされたパラレルなワークフローまで、さまざまなワークフローを作成することができます。
以下では、アプリ間でAppFuturesやDataFuturesを渡すことで、さまざまなワークフローを作成することができることを説明します。
シーケンシャルワークフロー
あるタスクから別のタスクにAppFutureを渡すことで、単純なシーケンシャル(Sequential)またはプロシージャル(Procedural)ワークフローを作成できます。
次の例は、まず乱数を生成し、それをファイルに書き込む処理をシーケンシャルに実行します。
In [2]: # %load 20_sequential_workflow.py
...: import parsl
...: from parsl.app.app import python_app, bash_app
...: from parsl.data_provider.files import File
...:
...: conf = parsl.load()
...:
...: # 乱数を生成するアプリ
...: @python_app
...: def generate(limit):
...: from random import randint
...: return randint(1,limit)
...:
...: # ファイルに値を書き出すアプリ
...: @bash_app
...: def save(variable, outputs=[]):
...: cmdline = f'echo {variable} &> {outputs[0]}'
...: return cmdline
...:
...: # 1〜10の範囲で乱数を生成
...: random = generate(10)
...: print(f'Random number: {random.result()}')
...:
...: # 乱数をファイルに保存
...: outfile = File(os.path.join(os.getcwd(), 'sequential-output.txt'))
...: saved = save(random, outputs=[outfile])
...:
...: # 結果を出力
...: with open(saved.outputs[0].result(), 'r') as f:
...: data = f.read()
...: print(f'File contents: {data}')
...:
Random number: 9
File contents: 9
In [3]:
並列ワークフロー
Parslアプリが並列に実行される最も一般的な処理は、ループを使ったものです。次の例では、単純なループを使って多数の乱数を並列に生成する方法を示しています。
In [2]: # %load 21_parallel_workflow.py
...: import parsl
...: import os
...: from parsl.app.app import python_app, bash_app
...:
...: config = parsl.load()
...:
...: # delay秒遅延して乱数を生成するアプリ
...: @python_app
...: def generate(limit,delay):
...: from random import randint
...: import time
...: time.sleep(delay)
...: return randint(1,limit)
...:
...: # 1〜10の間の乱数を5つ生成する
...: rand_nums = []
...: for i in range(5):
...: rand_nums.append(generate(10,i))
...:
...: # アプリの終了を待つ
...: outputs = [i.result() for i in rand_nums]
...:
...: # 結果の出力
...: print(outputs)
...:
[8, 7, 10, 1, 4]
In [3]:
モンテカルロ法のワークフロー
多くの科学アプリケーションでは、モンテカルロ法を使ったシミュレーション計算を行っています。
このモンテカルロ法を使って円周率の近似値を求めるアルゴリズムは次のようになります。
- $ 1 \times 1$ の正方形内にランダムに点を打つ(一様分布にしたがった乱数を使う)
- 原点から距離が 1 以下なら 1 ポイント,1 より大きいなら 0 ポイント追加
- これらの操作を N 回繰り返して総獲得ポイントを P とする
- $ \dfrac {4P}{N} $ を円周率 $ \pi $ の近似値として得る
関数 pi() の各呼び出しは,独立かつ並列に実行されます.avg_three() アプリは,pi() の呼び出しから返されたFutures の平均を計算するために使用されます.
ワークフローは次のようになります。
App Calls pi() pi() pi()
\ | /
Futures a b c
\ | /
App Call avg_points()
|
Future avg_pi
In [2]: # %load 30_monte_calro.py
...: import parsl
...: from parsl.app.app import python_app, bash_app
...: from parsl.configs.local_threads import config
...:
...: config = parsl.load()
...:
...: @python_app
...: def pi(num_points):
...: from random import random
...:
...: inside = 0
...: for i in range(num_points):
...: x, y = random(), random() # ボックスにランダムな点をうつ
...: if x**2 + y**2 < 1: # 円の中にポイントがあるかチェック
...: inside += 1
...:
...: return (inside*4 / num_points)
...:
...: # 3つの値の平均値を計算するアプリ
...: @python_app
...: def mean(a, b, c):
...: return (a + b + c) / 3
...:
...: # pi の近似値を求める
...: a, b, c = pi(10**6), pi(10**6), pi(10**6)
...:
...: # 3つの値の平均を求める
...: mean_pi = mean(a, b, c)
...:
...: # 結果の出力
...: print(f"a: {a.result():.5f} b: {b.result():.5f} c: {c.result():.5f}")
...: print(f"Average: {mean_pi.result():.5f}")
...:
a: 3.14092 b: 3.14195 c: 3.14246
Average: 3.14178
In [3]:
実行と設定
Parslは、任意の__実行プロバイダ__(PC、クラスター、スーパーコンピュータ、クラウドなど)や__実行モデル__(スレッド、パイロットジョブなど)をサポートするように設計されています。スクリプトの実行に使用されるコンフィギュレーションは、目的の環境でアプリをどのように実行するかをParslに伝えます。Parslは、特定のアプリやスクリプトのリソース構成を記述するために、ブロックと呼ばれる高レベルの抽象化を提供しています。
捕捉:パイロットジョブ
大量のタスクを処理するための一括処理ジョブのこと
サポートしている実行プロバイダー
- LocalProvider::ラップトップやワークステーションでローカルに実行することができるプロバイダ
- CobaltProvider: Cobalt スケジューラを介してリソースをスケジュールすることができるプロバイダ
- SlurmProvider: Slurm スケジューラを使ってリソースをスケジュールすることができるプロバイダ
- CondorProvider: Condor スケジューラーによるリソースのスケジューリングすることができるプロバイダ
- GridEngineProvider: GridEngine スケジューラを使用してリソースをスケジュールすることができるプロバイダ
- TorqueProvider : Torque スケジューラでリソースをスケジュールすることができるプロバイダ
- PBSproProvider : PBSPro スケジューラでリソースをスケジュールすることができるプロバイダ
- AWSProvider::Amazon Web Servicesのクラウドノードをプロビジョニングおよび管理するためのプロバイダ
- AzureProvider:Microsoft Azure のクラウドノードをプロビジョニングおよび管理するためのプロバイダ
- GoogleCloudProvider。Google Cloudからクラウドノードのプロビジョニングと管理を行うことができるプロバイダ
- KubernetesProvider:Kubernetesクラスター上のコンテナのプロビジョニングと管理を行うためのプロバイダ
- AdHocProvider: アドホック・クラスターを形成するノードの集合体の実行を管理するためのプロバイダ
- LSFProvider: IBMのLSFスケジューラを使ってリソースをスケジューリングするためのプロバイダ
サポートしているエグゼキューター
- ThreadPoolExecutor::ローカルリソースでのマルチスレッド実行をサポートします。
- HighThroughputExecutor:パイロットジョブモデルを用いた階層的なスケジューリングとバッチ処理を実装し、最大4000ノードでの高スループットなタスク実行を実現します。
- WorkQueueExecutor:実行バックエンドとしてWork Queueを統合します。Work Queueは、数万コアの規模に対応し、動的なリソースサイジングによる信頼性の高いタスク実行を実現します。
- ExtremeScaleExecutor:mpi4pyを使用して4000以上のノードにスケールアップします。このエクゼキュータは通常、スーパーコンピュータでの実行に使用されます。
サポートしているランチャー
- SrunLauncher:Slurm ベースのシステム用の Srun ベースのランチャーです。
- AprunLauncher:AprunベースのCRAYシステム用ランチャーです。
- SrunMPILauncher:Srun で MPI アプリケーションを起動するためのランチャーです。
- GnuParallelLauncher:GNU parallelを使用し、ノードやコアをまたいでワーカーを起動するランチャー。
- MpiExecLauncher:Mpiexec を使用して起動します。
- SimpleLauncher:ランチャーのデフォルトはシングルワーカーの起動です。
- SingleNodeLauncher:単一のノード上の workers_per_node カウントのワーカーを起動します。
サポートされているさまざまな実行プロバイダやエクゼキュータに関する詳細な情報は、Parslのドキュメントの Executor を参照してください。
モニタリング
Parslには、タスクの状態やリソースの使用状況を長期的に把握するための監視システムが提供されています。Parslの監視システムは、リモートマシン上で実行される個々のアプリに至るまで、プログラムの状態を追跡するのに役立つ詳細な情報と診断機能を提供することを目的としています。
モニタリングシステムは、ワークフローの実行中にSQLiteデータベースに情報を記録します。この情報は、parsl-visualize ツールを使用してWebダッシュボードで可視化したり、通常のSQLiteツールを使用してSQLでクエリを実行したりすることができます。
モニタリングの構成
Parsl のモニタリングは HighThroughputExecutor でのみサポートされています。
次の例は、Parsl構成でモニタリングを有効にする方法を示しています。ここでは、MonitoringHubがポート55055を使用して、10秒ごとにワーカーから監視メッセージを受信するように指定されています。
import parsl
from parsl.monitoring.monitoring import MonitoringHub
from parsl.config import Config
from parsl.executors import HighThroughputExecutor
from parsl.addresses import address_by_hostname
import logging
config = Config(
executors=[
HighThroughputExecutor(
label="local_htex",
cores_per_worker=1,
max_workers=4,
address=address_by_hostname(),
)
],
monitoring=MonitoringHub(
hub_address=address_by_hostname(),
hub_port=55055,
monitoring_debug=False,
resource_monitoring_interval=10,
),
strategy=None
)
可視化
Web・ダッシュボード・ユーティリティ parsl-visualize を実行するには、追加でモジュールをインストールする必要があります。
$ pip install "parsl[monitoring]"
Parsl プログラムの実行中または実行後に Web ダッシュボードを表示するためには、parsl-visualize を実行します。
$ parsl-visualize
デフォルトでは、このコマンドは、現在の作業ディレクトリにあるデフォルトのmonitoring.dbデータベースが使用されていることを想定しています。コマンドラインにデータベースのURIを渡すことで、他のデータベースを読み込むことができます。例えば、データベースの絶対パスが /tmp/my_monitoring.db の場合は、次のように実行します。
$ parsl-visualize sqlite:////tmp/my_monitoring.db
デフォルトでは、arsl-visualize のWebサーバーは 127.0.0.1:8080 でリッスンします。ローカルのマシンで parsl-visualize を起動した場合は、ダッシュボードはhttp://127.0.0.1:8080 アクセスできます。Webサーバがクラスタのログインノードなどのリモートマシンに配置されている場合、ローカルマシンからクラスタへのSSHトンネルを使用する必要があります。
$ ssh -L 50000:127.0.0.1:8080 username@cluster_address
このコマンドを実行すると、ローカルマシンのポート50000がリモートクラスタのポート8080にバインドされます。ダッシュボードには、ローカルマシンのブラウザからhttp://127.0.0.1:50000 でアクセスできます。
また、可視化サーバーをパブリックインターフェースに配置することもできます。ただし、クラスタのセキュリティポリシーで許可されているかどうかをまず確認してください。次の例では、Webサーバーをパブリックポート(public_IP:5555を介してインターネットに公開)に配置する方法を示しています。
$ parsl-visualize --listen 0.0.0.0 --port 55555
ダッシュボード
ダッシュボードのワークフロー ページには、選択したデータベースで監視を有効にして実行されたすべてのParslワークフローが一覧表示されます。ワークフローの状態を高レベルで要約したものが以下のように表示されます。
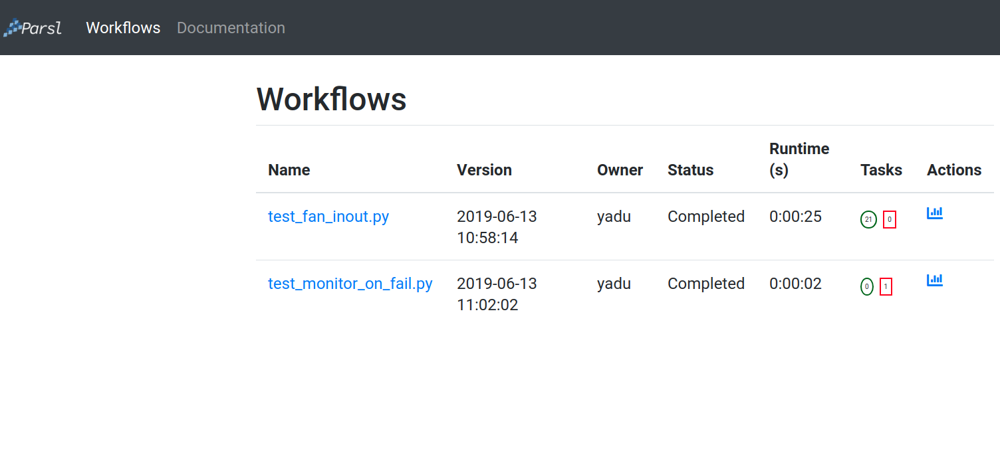
ダッシュボード全体を通して、青色の要素はすべてクリック可能です。例えば、表の中の特定のワークフロー名をクリックすると、次のセクションで説明する「Workflow Summary」ページに移動します。
ワークフローサマリー
ワークフローサマリーページでは、開始時間、終了時間、タスクサマリー統計など、ワークフローの実行レベルの詳細が表示されます。ワークフローサマリーの後には、App Summary が表示され、様々なアプリとそれぞれの起動回数が表示されます。
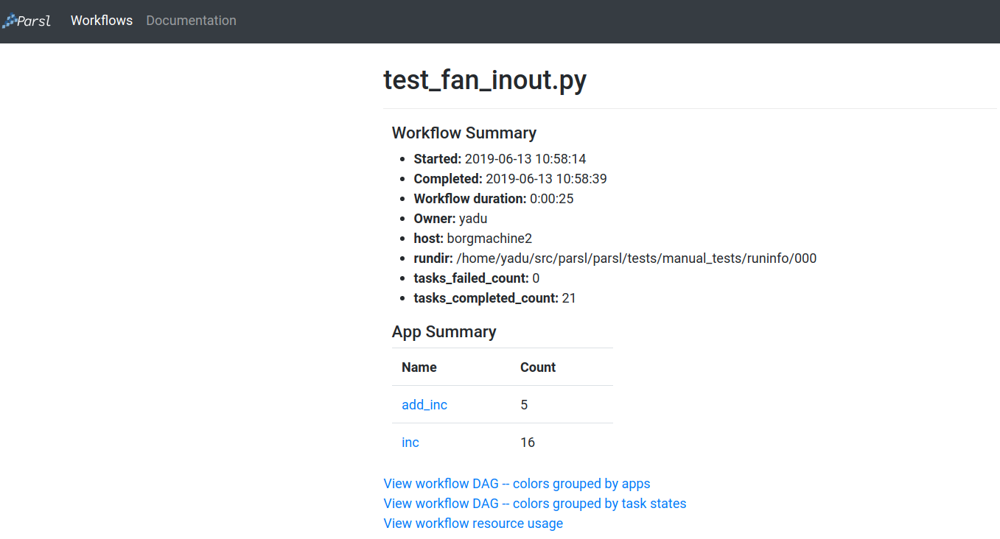
また、ワークフローサマリーでは、ワークフローの3つの異なるビューが表示されます。
ワークフローのDAG アプリを色で区別
この表示は、ワークフローの依存関係の構造を視覚的に確認するのに便利です。DAG内のノードにカーソルを合わせると、そのノードで表されるアプリとそのタスクIDのツールチップが表示されます。

ワークフローDAG - タスクの状態を色で区別
この可視化は、どのタスクが完了したのか、失敗したのか、現在保留になっているのかを識別するのに役立ちます。

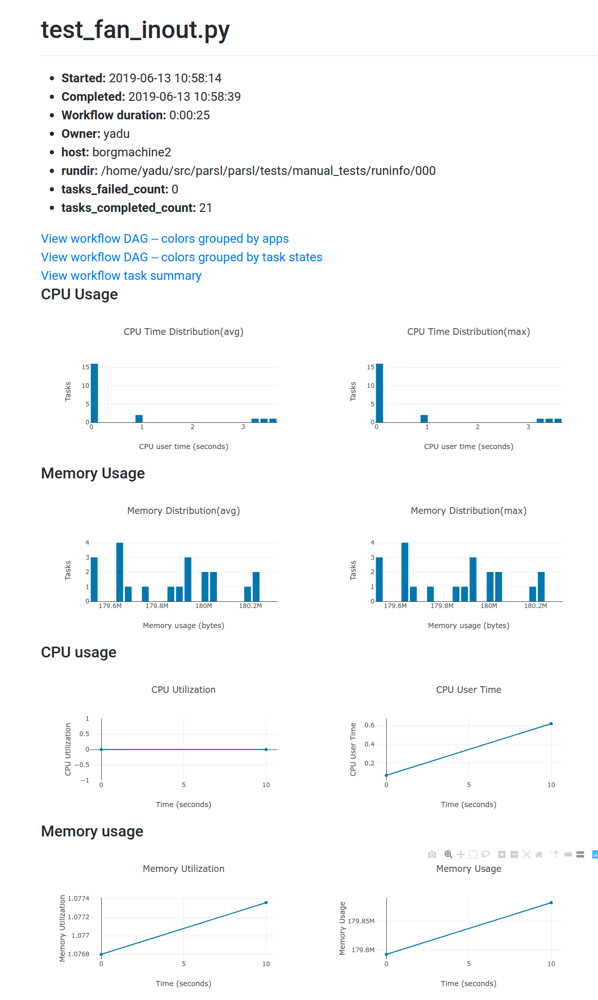
ワークフローのリソース使用状況
ワークフローレベルでのリソース使用状況を可視化します。例えば、ワーカー全体のCPU/メモリ使用率の累積を時間軸で表示します。
まとめ
多数のデータを扱ったり、シミュレーションを繰り返す場合などでは、特定の分野に特化したワークフローを構築することになります。これらのワークフローは、さまざまな独立したソフトウェア機能や外部アプリケーションを統合したものになります。しかし、多くの場合このようなワークフローを開発・実行・保守することは難しく、アプリケーションやデータの複雑なオーケストレーションや管理、特定の実行環境に合わせたカスタマイズが必要になります。そしてこうした作業は実行環境がリプレースなどで変わるたびに繰り返されることになります。
Parslではコードと実行環境が分離されているため、PythonスクリプトにParslディレクティブをアノテーションするだけで、ラップトップからクラスター、クラウド、グリッドなどのリソース上でスクリプトの実行をすることができるようになります。
Parslを使用することで、必要なデータの移動をオーケストレーションし、Python関数や外部アプリケーションの並列実行の管理が容易になります。