目的
Python+BeautifulSoupによるスクレイピングを学習する。
背景
ウェブサイトから画像だけダウンロードしたいと思い、
スクレイピング出来たら簡単にできそうだと安易に考えたが、これが思いのほか大変だったので、とりあえずやったことを書く。
概要
スクレイピングの学習がしたかったので、画像をダウンロードする部分は作らない。そこはダウンローダーのフリーソフトIrvineを使用する。
また、ダウンロードした画像ファイルは、ナンバリングしたファイル名につけ直して、Zipファイルにまとめる。フローは以下の通り。
- 作成ツールでウェブサイトから画像のURLリストを作り、クリップボードにコピーする
- Irvineにペーストしてダウンロードする
- 作成ツールでファイル名を付けなおして、zipファイルに圧縮する
ところでIrvineの機能をちゃんと使えば、こんなの作らなくても全部できるだろ!とか言わないように。あくまでも目的はスクレイピングの学習なので。
環境と設定
Windows10で実施した。
chocolateyを使っているならpython3のインストールは、管理者権限でcmdまたはWindows PowerShellを起動して以下のコマンドを実行する。
> choco install python
途中選択肢が出る場合は、すべてy + Enterする。
インストールが終わったら、cmdまたはPowerShellを開きなおして、以下のコマンドを実行する。
> pip install requests
> pip install bs4
> pip install pyperclip
GitからSource code(zip)をダウンロードして、展開する。
展開したパスを「Git/traning/」とする。
Irvineをダウンロード&インストールして起動する。

デフォルトフォルダに「folder01」フォルダを新規作成する。

新規作成するフォルダ「folder01」は、スクリプト「HTML2imglist.py」
のあるパスとする。

「folder01」の右クリックコンテキストメニューから「フォルダ設定」を選んで、後から変更できる。
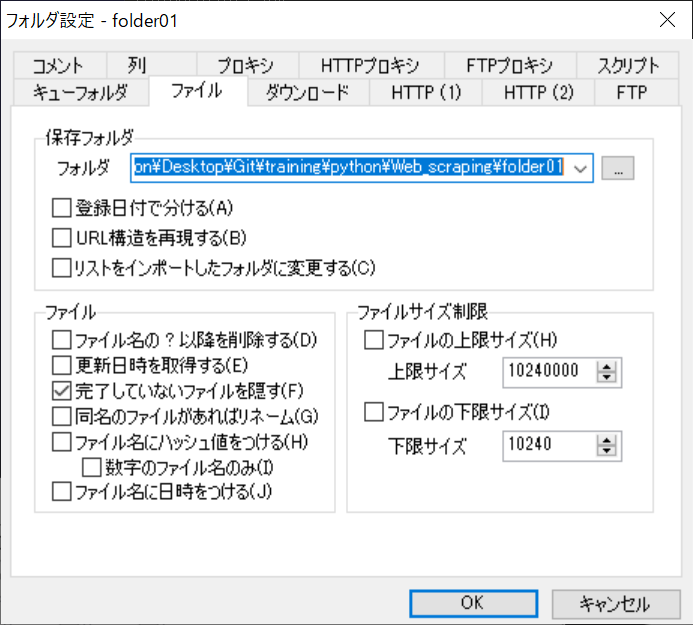
Irvineに「folder01」が追加された。

メニューから「ツール」-「オプション設定」を選ぶ。
タブ「クリップボード」を開き、チェックボックス「クリップボードから直接登録する」をONにする。

OKボタンをクリックして閉じる。
他にメニューから「管理」-「クリップボード監視」を選択してONにしなければならないかもしれない。私の手元ではONでもOFFでも動いた。
使い方
地元石川県のオープンデータがあるウェブサイトをターゲットとして説明する。
以下のような名勝のサムネイル画像をターゲットとする。

「Git/traning」パスでコマンドプロンプト(cmd)を起動したとすると、パスを「Git/traning/python/Web_scraping」に移動する。
ダウンロードしたい画像があるウェブサイトのURLを引数に指定して、スクリプトを実行する。
> cd .\python\Web_scraping
> python Html2imglist.py https://www.hot-ishikawa.jp/photo/
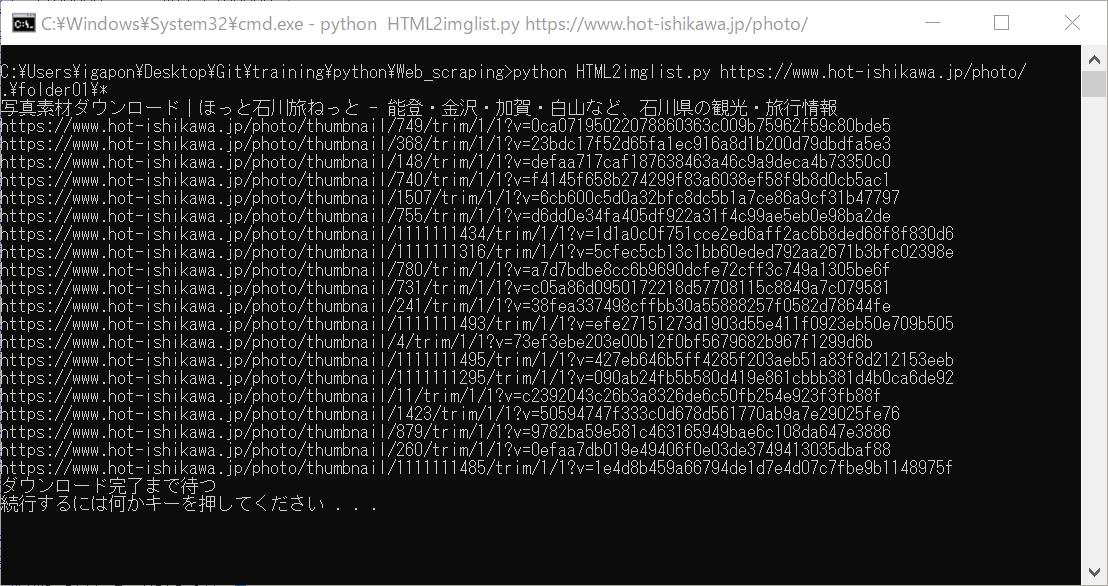
するとタイトルと、画像のURLリストがクリップボードにコピーされる。
Irvineを起動して、「folder01」にペーストするとダウンロードが開始されるので完了するまで待つ。

コマンドプロンプトに戻り何かキーを押せば、ダウンロードした画像ファイルを、ナンバリングしたファイル名につけ直し、Zipファイルにまとめる。
↑「folder01.zip」が出来ている。
さらに何かキーを押せば、「folder01」フォルダを空にする。
「folder01.zip」をビューアソフト、例えばImage Viewerにドラッグ&ドロップしてみると。

無事表示された。
Image Viewerは、→キーで次のスライド、←キーで前のスライドに切り替わる。
スクレイピング
ターゲットにしたサイト「写真素材ダウンロード|ほっと石川旅ねっと」のソースコードを表示して、titleタグを確認する。

これをCSSセレクタで表現すると「html head title」となる。
また、画像ファイルまでのタグ構造を確認する。

ダウンロードしたいファイルは以下のsrc属性である。
475行目:<img class="img-responsive" src="/photo/thumbnail/749/trim/1/1?v=0ca07195022078860363c009b75962f59c80bde5" alt="兼六園">
~
486行目:<img class="img-responsive" src="/photo/thumbnail/740/trim/1/1?v=f4145f658b274299f83a6038ef58f9b8d0cb5ac1" alt="金沢駅">
ここまでのタグの連なりは以下の通りになっている。
<html>
<body>
~
<div class="photoItems">
<ul>
<li>
<div class="photoItem">
<a>
<img src="対象の画像1枚目">
</a>
</div>
</li>
<li>
<div class="photoItem">
<a>
<img src="対象の画像2枚目">
</a>
</div>
</li>
これらをCSSセレクタで表現すると「html body div .photoItems ul li div .photoItem a img」となる。
少し省略して「html body div .photoItem img」とする。
この画像ファイルの記載のされ方は、ウェブサイトによって変わるので、HTML2imglist.pyファイルの以下の変数で指定できるようにした。
50行目:title_css_select = 'html head title'
51行目:img_css_select = 'html body div .photoItem img'
52行目:img_attr = 'src'
おわりに
CSSセレクタがスクレイピングそのものなんだなと思った。
そう考えると、この記事はスクレイピングを何も学習していないことになるけど、気のせいに違いない。
関連リンク
ターゲットにしたサイト
参考