What is BigQuery
- フルマネージドデータウェアハウス
- 機械学習、地理分析、BIがビルトイン
- サーバーレス: CPUとストレージの分離
- SQL
- スケーラブル
- Federated query: 外部データにクエリできる
- 列指向ストレージ
BigQueryML
- SQLで機械学習を実行できる
- コンソール、
bqコマンド、 REST API、その他外部ツールで使える - 利用できるモデル
- 線形回帰
- 二値ロジスティック回帰
- 多項ロジスティック回帰
- K-means
- Matrix Factorization
- 時系列分析
- ブースティング木
- DNN
- AutoML Tables
- 学習済みのTensorFlowモデル
- Autoencoder
- BigQueryを使うのでデータ出力などが不要
BigQuery Omni
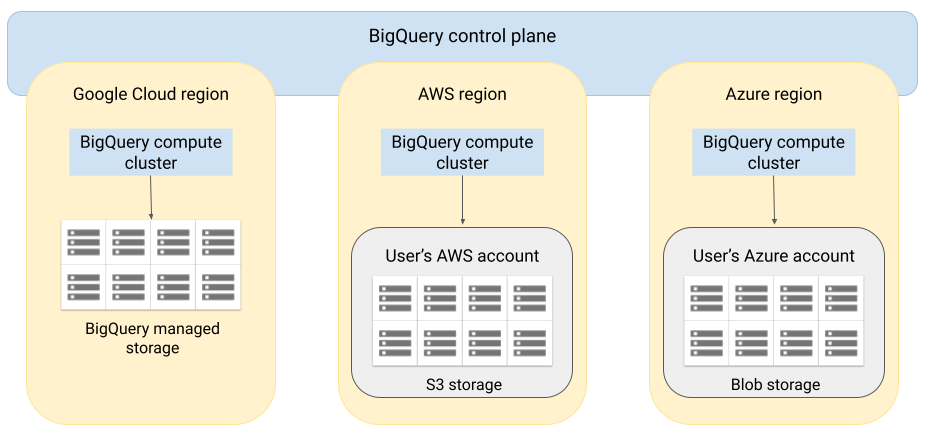
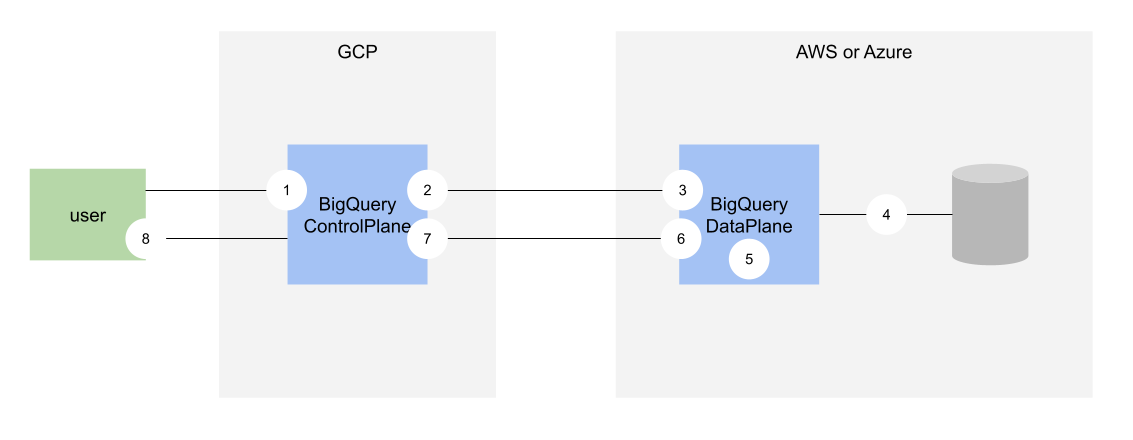
- S3やAzure blob storageにあるデータをBigQueryで使える
- BigQueryのエンジンを他のクラウド上で動かす
- サーバレス
- 外部テーブルとしての利用のみ
- 使えるリージョンが限られている
Storage
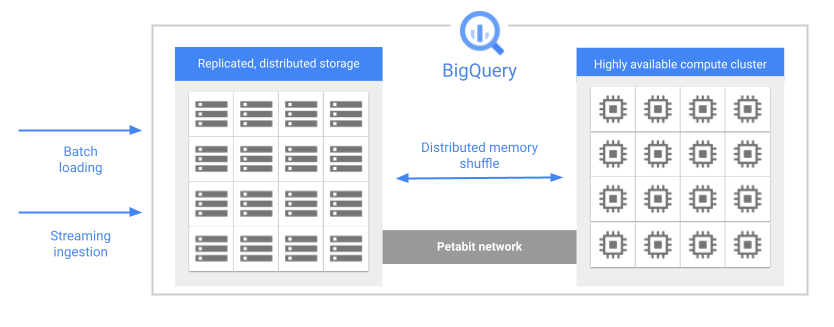
- 大規模データの分析に最適化されている
- クエリが実行されると複数のワーカーで並列処理をする
- クエリは完全にインメモリで実行される
- データを自動で暗号化する
- Capacitorというストレージフォーマットを使っている
- マテリアライズドビュー: 事前に計算されたビュー
- テーブルやリソースをデータセットというコンテナに整理する
-
STRUCTはネストされたフィールドをサポートする -
ARRAYは繰り返すフィールドをサポートする - パーティション: テーブルの分割
- 時間に関する列
- 整数値列
- データが格納された時刻: 自動
- クラスタリング: 1つ以上の列について、似たデータを近傍に配置する
Organize resources
- データセット
- 論理的コンテナ
- 構成とアクセスコントロールの単位
- schemaのようなもの
- テーブル、ビュー、関数などを含む
- ロケーションを決める必要がある
- ロケーションは後から変えられない
- 外部テーブルを使う場合は近いところにする
- プロジェクト
- GCPプロジェクト
- 複数のデータセットが属する
- フォルダ
- プロジェクトをグルーピングするもの
- フォルダ自体をフォルダにまとめることができる
- クオータはプロジェクトレベルで測定される
- 会計を分けたい場合、プロジェクトおよびビリングアカウントを分ける
- データセットと外部テーブルを両方ともマルチリージョンにするのは非推奨
- テーブル
- expiration timeを設定できる
- 他のデータセットへコピーできる
- JSONでスキーマを定義できる
- csv, json, sheetに対してスキーマオートディテクトを利用できる
Loading data
-
load jobでファイルから読む -
LOAD DATASQLでファイルから読む - BigQuery Data Transfer Service を使う
- BigQuery Storage Write APIを使う
- Dataflow
- Connector for SAP
- ネストやリピートされたフィールドを使って非正規化するのが望ましい
Govern
- デフォルトでCloud Loggingおよびadmin activityやaudit logを取り込んでいる
- IAMに基づいて、行レベルや列レベルでのアクセス制御ができる
Data loss prevention
- データに対する監査や分類ができる
- データの変更をチェックできる
- データのマスキングなどを確認できる
Customer Managed Encryption Key
- BigQueryのデータはデフォルトで暗号化される
- Key Encryption Keyにユーザーが管理するものを使える
- AEAD暗号化でテーブル内のデータごとに暗号化できる
Business intelligence tools
- spread sheetやLookerやTableauなどと接続できる
- Jupyter notebookなどからも接続できる
Geospatial analytics
- 地理データに基づいて分析や可視化ができる
- 標準SQLのGeographyタイプのデータを読み込める
終わり
以上です。
GCPの主力サービスだけあって、ドキュメントも豊富でした。