Firestore
について書きます。
Firebaseのお仲間かと思ったら、Datastoreの上位互換的な立ち位置のようです。
https://cloud.google.com/firestore/docs
Data model
- NoSQLのドキュメントデータベース
- ドキュメントはKey-Valueペアをもっている
- 小さなドキュメントがたくさんあるデータに適している
- ドキュメントの中にサブコレクションを作って階層的なデータを作れる
Structuring data
- ネストされたデータ
- シンプル、作るのが簡単
- ほかの構造と比べてスケーラブルではない
- サブコレクション
- リストが大きくなっても親ドキュメントの構造が変わらない
- クエリキャパシティがよい
- 簡単には消せない
- ルートレベルコレクション
- many-to-manyリレーションに良い
- データ取得が複雑になる
Location
- Firestoreのロケーションはデフォルトではプロジェクトのロケーションになる
- マルチリージョンやリージョンを指定できる
- レイテンシを下げるために利用するサービスに近いロケーションを選ぶ
Index
- single-fieldインデックス
- a sorted mapping
- デフォルトで自動でメンテしてくれる
- compositeインデックス
- a sorted mapping
- インデックスモード
- ascendhing
- descending
- array-contains
- スコープ
- コレクションスコープ: 1つのコレクションから結果が返る
- コレクショングループスコープ: 同じコレクションIDをもつコレクションから結果が返る
Encryption
- 自動でサーバーサイド暗号化
- クライアントサイドで暗号化したい場合、TLSを使う
Best practices
- ドキュメントIDに単調増加する名前を避ける
- インデックスが増えすぎるのを避ける
- インデックスが単調増加する値になるのを避ける
- 1秒に1回以上の書き込みは避ける
- できるだけ非同期的呼び出しを使う
- オフセットではなくカーソルを使う
- Firestore SDKは自動でリトライを行う、RESTやRPC APIでは自動でリトライしない
- ホットスポットを避けるために、辞書順で近いドキュメントの読み書きを避ける
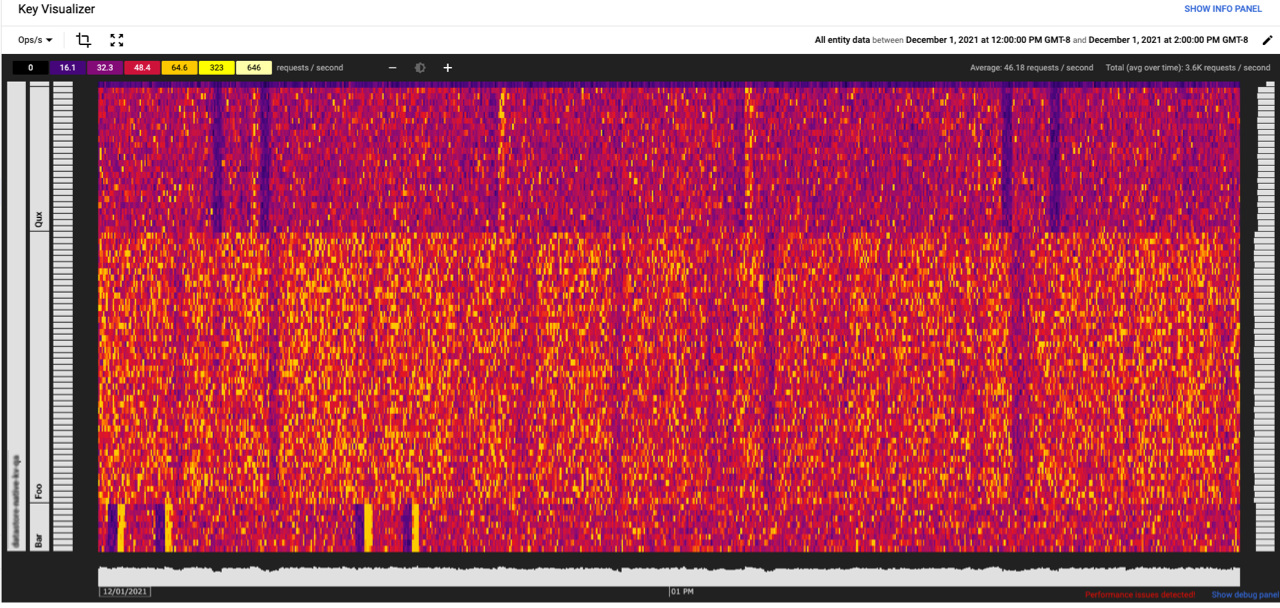
Key visualizer
- Firestoreの利用パターンを可視化できる
- パフォーマンス課題の発見
- データアクセスのパターン
Transaction
- トランザクション
- バッチ書き込み
- 最大500ドキュメントの書き込み