はじめに
ソフトウェアテストの業界向けに役に立つ話、第二回目です。
前回に引き続き、 Airtest IDE という UI 自動化ソフトウェアを使用し、Android の自動化を行います。。今回は Airtest には備わっていない文字認識を実装し、組み合わせて使ってみました。

〜 前回 〜
Airtest を使ったAndroid アプリの自動操作
https://qiita.com/ids-kinoue/items/12bec45f319934afd476
前置き
文字認識(OCR)には、 Google Cloud のCloud Vision APIを使用します。(使用料がかかります)なお、 Google Cloud API の環境準備については長くなってしまうので、説明を省略します。
初めて使われる方は下記の記事を参考にしてください。
Google Cloud Vision API の OCR を使って Python から文字認識する方法
https://valmore.work/cloud-vision-api-ocr/
アカウントキーの環境変数
Cloud Vision API を Python で使用する場合、環境変数GOOGLE_APPLICATION_CREDENTIALSに「サービス アカウント キー」を設定することが必要ですが、 Airtest IDE から実行する場合、設定した環境変数が呼び出せないようです。その為、プログラム内で環境変数を割り当てます。
例:
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "path/to/your/credentials.json"
事前準備
デフォルトの Airtest IDE では、 IDE に組み込まれた Python が使用されていますので、pipで追加することができません。
Options > Settings > ▼ Airtest を開き、

ここにあなたの Python のパスを設定することで、普段使いの Python で動作させることができます。
pip install google-cloud-vision
pip install airtest
pip install pillow
pip install numpy
そして、今回使うパッケージをインストールします。
自動化する内容
今回も Airtest の GitHub にあるブラックジャックのサンプルアプリ「blackjack-release-signed.apk」を使用します。
https://github.com/AirtestProject/Airtest/tree/master/playground/blackjack_example
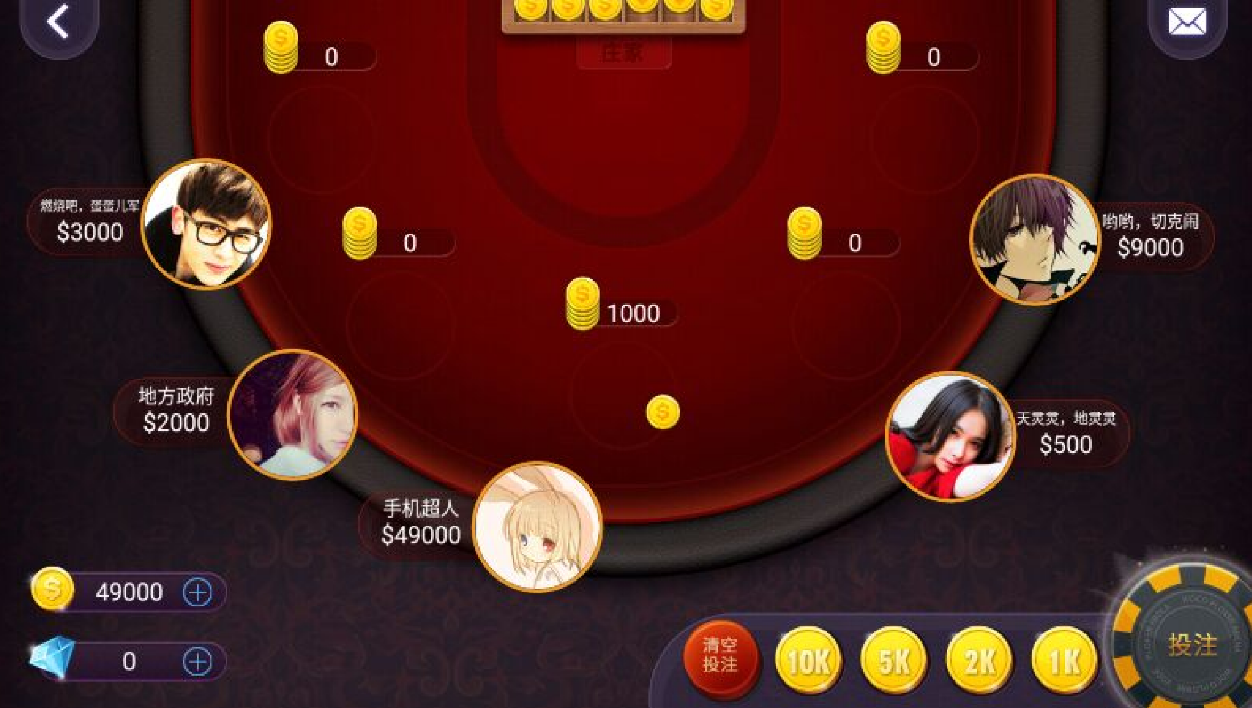
前回は画像をタッチしましたが、今回は文字を扱います。自動化する内容は以下です。
- 現在の自分の所持金がいくらか取得します。
- 所持金が【47000】以下になるまで、「1K」の画像をタッチし、お金をかけます。
- 最後に「投注」という画像をタッチし、ゲームをはじめます。
所持金はどこ?
どのような方法で所持金を取得するか考えてみます。
画面上に数字は沢山ありますね。OCRで文字を取得出来ても、どの数字が自分の所持金なのか、わかりません。なので、どこに所持金があるのかを知る必要があります。大抵のゲームでは、所持金の近くにはお金を示すアイコンがあります。
よって、お金のアイコンの画像を探し、その近くにあるテキストを取り出すことで所持金を取得するという手が考えられます。

このように画像を軸とすれば、所持金の位置が変わってもちゃんと取得できそうです。また、お金のテキストが左側にある場合も考えられるので、方向を選べるようにします。
お金を取り出すクラス
import io
import os
import numpy as np
from PIL import Image
from google.cloud import vision
from airtest.core.cv import Template
from airtest.core.helper import G
from airtest.aircv.utils import cv2_2_pil
class AirOCR:
def __init__(self, key: str):
self.key = key
self._set_env()
self.client = vision.ImageAnnotatorClient()
def _set_env(self) -> None:
"""Google Cloudの「サービス アカウント キー」を環境変数に設定します。"""
if not os.path.isfile(self.key):
raise Exception("Googleの認証キーが見つかりませんでした。")
else:
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = self.key
def get_money(self, image: Template, position: str = "right", image_scale: int = 1.5) -> str:
"""所持金のテキストを取得します。"""
money_image_coordinate = self._get_image_coordinate(image)
content = self._get_window_capture()
bounds, texts = self._get_text(content=content)
txt_pos = self._get_best_text_coordinate(bounds, position)
img_width, img_height = self._get_size(money_image_coordinate)
add_height = (img_height * image_scale) - img_height
add_width = (img_width * image_scale) - img_width
img_center_x = self._get_center(money_image_coordinate["x"])
img_center_y = self._get_center(money_image_coordinate["y"])
hit_index = []
LEFT_TOP = 0
LEFT_BOTTOM = 1
RIGHT_BOTTOM = 2
RIGHT_TOP = 3
for idx, (x, y) in enumerate(txt_pos):
if position == "left" and \
x <= img_center_x and \
y >= money_image_coordinate["y"][LEFT_TOP] - add_height and \
y <= money_image_coordinate["y"][LEFT_BOTTOM] + add_height:
hit_index.append(idx)
if position == "right" and \
x >= img_center_x and \
y >= money_image_coordinate["y"][RIGHT_TOP] - add_height and \
y <= money_image_coordinate["y"][RIGHT_BOTTOM] + add_height:
hit_index.append(idx)
if position == "top" and \
x >= money_image_coordinate["x"][LEFT_TOP] - add_width and \
x <= money_image_coordinate["x"][RIGHT_TOP] + add_width and \
y <= img_center_y:
hit_index.append(idx)
if position == "bottom" and \
x >= money_image_coordinate["x"][LEFT_TOP] - add_width and \
x <= money_image_coordinate["x"][RIGHT_BOTTOM] + add_width and \
y >= img_center_y:
hit_index.append(idx)
hit_txt_pos = [(x, y) for i, (x, y) in enumerate(txt_pos) if i in hit_index]
img_center = [(self._get_center(money_image_coordinate["x"]), self._get_center(money_image_coordinate["y"]))]
best_idx = self._find_nearest_index(origin=img_center, target=hit_txt_pos)
nearest_idx = hit_index[best_idx]
if not texts[nearest_idx]:
raise Exception("対象画像の近くにテキストが見つかりませんでした。")
else:
return texts[nearest_idx]
def _get_text(self, content: bytes) -> (list, list):
"""デバイス画面をVision APIに与え、画面上の全てのテキストを取得します"""
image = vision.Image(content=content)
response = self.client.text_detection(image=image)
document = response.full_text_annotation
bounds = []
text = []
texts = []
for page in document.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
for symbol in word.symbols:
text.append(symbol.text)
bounds.append(block.bounding_box)
texts.append(''.join(text))
text = []
return bounds, texts
def _get_image_coordinate(self, image: Template) -> dict:
"""デバイス画面から画像を探して、4点座標を辞書で返します。"""
screen = G.DEVICE.snapshot(filename=None)
result = image.match_all_in(screen)
image_coordinate = {}
if result:
image_coordinate["x"] = [c[0] for c in result[0]["rectangle"]]
image_coordinate["y"] = [c[1] for c in result[0]["rectangle"]]
else:
raise Exception("所持金のイメージが見つかりませんでした。")
return image_coordinate
def _get_best_text_coordinate(self, bounds: list, position: str) -> list:
"""認識したテキストの内、最適なテキストを選択します。"""
LEFT_TOP = 0
RIGHT_TOP = 1
RIGHT_BOTTOM = 2
LEFT_BOTTOM = 3
coordinate = []
for bound in bounds:
x_list = [
bound.vertices[LEFT_TOP].x,
bound.vertices[RIGHT_TOP].x,
bound.vertices[RIGHT_BOTTOM].x,
bound.vertices[LEFT_BOTTOM].x
]
y_list = [
bound.vertices[LEFT_TOP].y,
bound.vertices[RIGHT_TOP].y,
bound.vertices[RIGHT_BOTTOM].y,
bound.vertices[LEFT_BOTTOM].y
]
if position == "right":
x = min(x_list)
y = self._get_center(y_list)
coordinate.append((x, y))
elif position == "left":
x = max(x_list)
y = self._get_center(y_list)
coordinate.append((x, y))
elif position == "top":
x = self._get_center(x_list)
y = min(y_list)
coordinate.append((x, y))
elif position == "bottom":
x = self._get_center(x_list)
y = max(y_list)
coordinate.append((x, y))
return coordinate
def _get_center(self, coordinate: list) -> int:
"""座標の中心を返します。"""
return sum(coordinate[0:4]) / 4
def _get_size(self, coordinate: dict) -> (int, int):
"""横幅と高さを返します。"""
width = max(coordinate["x"]) - min(coordinate["x"])
hight = max(coordinate["y"]) - min(coordinate["y"])
return width, hight
def _get_window_capture(self) -> bytes:
"""接続されているデバイスのイメージを取得します。"""
cv2_image = G.DEVICE.snapshot(filename=None)
pil_image = cv2_2_pil(cv2_image)
bytes_image = self._pil_2_bytes(pil_image)
return bytes_image
def _pil_2_bytes(self, pil_image: Image) -> bytes:
"""PIL.Imageをbytesに変換します。"""
bytes_image = io.BytesIO()
pil_image.save(bytes_image, format='PNG')
bytes_image = bytes_image.getvalue()
return bytes_image
def _find_nearest_index(self, origin: tuple, target: list) -> int:
"""ヒットしたテキストの中からもっとも距離が近い対象のindexを返します。"""
target_np = np.array(target)
origin_np = np.array(origin)
line_segment = [np.linalg.norm(t - origin_np) for t in target_np]
idx = np.where(min(line_segment) == line_segment)
best_index = int(idx[0])
return best_index
docstring あり版(長いので畳みました。)
import io
import os
import numpy as np
from PIL import Image
from google.cloud import vision
from airtest.core.cv import Template
from airtest.core.helper import G
from airtest.aircv.utils import cv2_2_pil
class AirOCR:
def __init__(self, key: str):
"""
Parameters
----------
key : str
Google Cloud Platformの「サービス アカウント キー」のファイルパス
キーのタイプ: JSON
例: "path/to/your/credentials.json"
"""
self.key = key
self._set_env()
self.client = vision.ImageAnnotatorClient()
def _set_env(self) -> None:
"""
Google Cloudの「サービス アカウント キー」を環境変数に設定します。
"""
if not os.path.isfile(self.key):
raise Exception("Googleの認証キーが見つかりませんでした。")
else:
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = self.key
def get_money(self, image: Template, position: str = "right", image_scale: int = 1.5) -> str:
"""
所持金のテキストを取得します。
Parameters
----------
image : Template
所持金のイメージが入った Airtest の Template クラス
position : str
所持金のイメージの中心点に対して、テキストがある位置
(left, right, top, bottom)
image_scale : int
所持金のイメージが小さすぎる場合に判定範囲を広げるために使用する。
テキストが左右にある場合、所持金のイメージの高さが調整されます。
テキストが上下にある場合、所持金のイメージの横幅が調整されます。
Returns
------
str
Vision APIで認識したテキストの内、条件に適合したテキスト。
Raises
------
Exception
所持金のイメージの近くにテキストが見つからなかった場合。
"""
money_image_coordinate = self._get_image_coordinate(image)
content = self._get_window_capture()
bounds, texts = self._get_text(content=content)
txt_pos = self._get_best_text_coordinate(bounds, position)
img_width, img_height = self._get_size(money_image_coordinate)
add_height = (img_height * image_scale) - img_height
add_width = (img_width * image_scale) - img_width
img_center_x = self._get_center(money_image_coordinate["x"])
img_center_y = self._get_center(money_image_coordinate["y"])
hit_index = []
LEFT_TOP = 0
LEFT_BOTTOM = 1
RIGHT_BOTTOM = 2
RIGHT_TOP = 3
for idx, (x, y) in enumerate(txt_pos):
if position == "left" and \
x <= img_center_x and \
y >= money_image_coordinate["y"][LEFT_TOP] - add_height and \
y <= money_image_coordinate["y"][LEFT_BOTTOM] + add_height:
hit_index.append(idx)
if position == "right" and \
x >= img_center_x and \
y >= money_image_coordinate["y"][RIGHT_TOP] - add_height and \
y <= money_image_coordinate["y"][RIGHT_BOTTOM] + add_height:
hit_index.append(idx)
if position == "top" and \
x >= money_image_coordinate["x"][LEFT_TOP] - add_width and \
x <= money_image_coordinate["x"][RIGHT_TOP] + add_width and \
y <= img_center_y:
hit_index.append(idx)
if position == "bottom" and \
x >= money_image_coordinate["x"][LEFT_TOP] - add_width and \
x <= money_image_coordinate["x"][RIGHT_BOTTOM] + add_width and \
y >= img_center_y:
hit_index.append(idx)
hit_txt_pos = [(x, y) for i, (x, y) in enumerate(txt_pos) if i in hit_index]
img_center = [(self._get_center(money_image_coordinate["x"]), self._get_center(money_image_coordinate["y"]))]
best_idx = self._find_nearest_index(origin=img_center, target=hit_txt_pos)
nearest_idx = hit_index[best_idx]
if not texts[nearest_idx]:
raise Exception("対象画像の近くにテキストが見つかりませんでした。")
else:
return texts[nearest_idx]
def _get_text(self, content: bytes) -> (list, list):
"""
デバイス画面をVision APIに与え、画面上の全てのテキストを取得します
text_detectionの詳しい説明は以下のfullTextAnnotationの説明を参照してください。
https://cloud.google.com/vision/docs/fulltext-annotations?hl=ja
Parameters
----------
content : bytes
Vision APIに渡すイメージ
Returns
-------
bounds : list
[
<class 'google.cloud.vision_v1.types.geometry.BoundingPoly'>,
<class 'google.cloud.vision_v1.types.geometry.BoundingPoly'>,
...
]
BoundingPolyクラスはテキストの矩形の四隅の座標点を示します。
vertices { x: 1 y: 2} vertices { x: 1 y: 2} vertices { x: 1 y: 2} vertices { x: 1 y: 2},
↓ それぞれリストに入っています。
vertices[0], vertices[1], vertices[2], vertices[3]
↓
vertices[0].x, vertices[0].y
texts : list
['テキスト1', 'テキスト2', ...]
"""
image = vision.Image(content=content)
response = self.client.text_detection(image=image)
document = response.full_text_annotation
bounds = []
text = []
texts = []
for page in document.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
for symbol in word.symbols:
text.append(symbol.text)
bounds.append(block.bounding_box)
texts.append(''.join(text))
text = []
return bounds, texts
def _get_image_coordinate(self, image: Template) -> dict:
"""
デバイス画面から画像を探して、4点座標を辞書で返します。
Parameters
----------
image : Template
所持金のイメージが入った Airtest の Template クラス
Raises
------
Exception
所持金のイメージが見つからなかった場合。
Returns
------
image_coordinate : dict
"""
screen = G.DEVICE.snapshot(filename=None)
result = image.match_all_in(screen)
image_coordinate = {}
if result:
image_coordinate["x"] = [c[0] for c in result[0]["rectangle"]]
image_coordinate["y"] = [c[1] for c in result[0]["rectangle"]]
else:
raise Exception("所持金のイメージが見つかりませんでした。")
return image_coordinate
def _get_best_text_coordinate(self, bounds: list, position: str) -> list:
"""
認識したテキストの内、最適なテキストを選択します。
Parameters
----------
bounds : list
position : str
Returns
------
coordinate : list
"""
LEFT_TOP = 0
RIGHT_TOP = 1
RIGHT_BOTTOM = 2
LEFT_BOTTOM = 3
coordinate = []
for bound in bounds:
x_list = [
bound.vertices[LEFT_TOP].x,
bound.vertices[RIGHT_TOP].x,
bound.vertices[RIGHT_BOTTOM].x,
bound.vertices[LEFT_BOTTOM].x
]
y_list = [
bound.vertices[LEFT_TOP].y,
bound.vertices[RIGHT_TOP].y,
bound.vertices[RIGHT_BOTTOM].y,
bound.vertices[LEFT_BOTTOM].y
]
if position == "right":
x = min(x_list)
y = self._get_center(y_list)
coordinate.append((x, y))
elif position == "left":
x = max(x_list)
y = self._get_center(y_list)
coordinate.append((x, y))
elif position == "top":
x = self._get_center(x_list)
y = min(y_list)
coordinate.append((x, y))
elif position == "bottom":
x = self._get_center(x_list)
y = max(y_list)
coordinate.append((x, y))
return coordinate
def _get_center(self, coordinate: list) -> int:
"""
座標の中心を返します。
Parameters
----------
coordinate : list
Returns
------
int
"""
return sum(coordinate[0:4]) / 4
def _get_size(self, coordinate: dict) -> (int, int):
"""
横幅と高さを返します。
Parameters
----------
coordinate : dict
Returns
------
width : int
hight : int
"""
width = max(coordinate["x"]) - min(coordinate["x"])
hight = max(coordinate["y"]) - min(coordinate["y"])
return width, hight
def _get_window_capture(self) -> bytes:
"""
接続されているデバイスのイメージを取得します。
Returns
-------
bytes_image : bytes
Notes
-----
cv2では、RGBからBGRに変換されるので、RGBに戻しています。
PIL: RGB
cv2: BGR
"""
cv2_image = G.DEVICE.snapshot(filename=None)
pil_image = cv2_2_pil(cv2_image)
bytes_image = self._pil_2_bytes(pil_image)
return bytes_image
def _pil_2_bytes(self, pil_image: Image) -> bytes:
"""
PIL.Imageをbytesに変換します。
Parameters
----------
pil_image : Image (PIL.Image)
Returns
-------
bytes_image : bytes
"""
bytes_image = io.BytesIO()
pil_image.save(bytes_image, format='PNG')
bytes_image = bytes_image.getvalue()
return bytes_image
def _find_nearest_index(self, origin: tuple, target: list) -> int:
"""
ヒットしたテキストの中からもっとも距離が近い対象のindexを返します。
----------
Parameters
origin : tuple
target : list
Returns
-------
best_index : int
"""
target_np = np.array(target)
origin_np = np.array(origin)
line_segment = [np.linalg.norm(t - origin_np) for t in target_np]
idx = np.where(min(line_segment) == line_segment)
best_index = int(idx[0])
return best_index
思ったより、長くなってしまいましたが、前述のお金を取り出すOCR クラスを実装してみました。

お金のイメージの高さの1.5倍の範囲に入っている最も近いテキストを取り出すように書き、

方向は引数で指定できるようにしました。
書いたモジュールの呼び出し
from airtest.core.api import using, touch
from airtest.core.cv import Template
using("./ocr_test")
from ocr import AirOCR
Airtest IDE では別ファイルにある自分で書いた Python ファイルをそのまま呼び出せないようです。airtest.core.apiに用意されているusing関数を使用して呼び出します。
今回は「ocr_test」というディレクトリを作成し、その中に先ほど作ったクラスをocr.pyという名前で保存しました。
不要な文字を消す

50000+
所持金を取得すると、横にある「+」ボタンまで文字として取り出されてしまいました。
if "+" in money:
money = money.replace("+", "")
money = int(money)
これはいらないので、replaceで消し、int に変換します。
コード全文
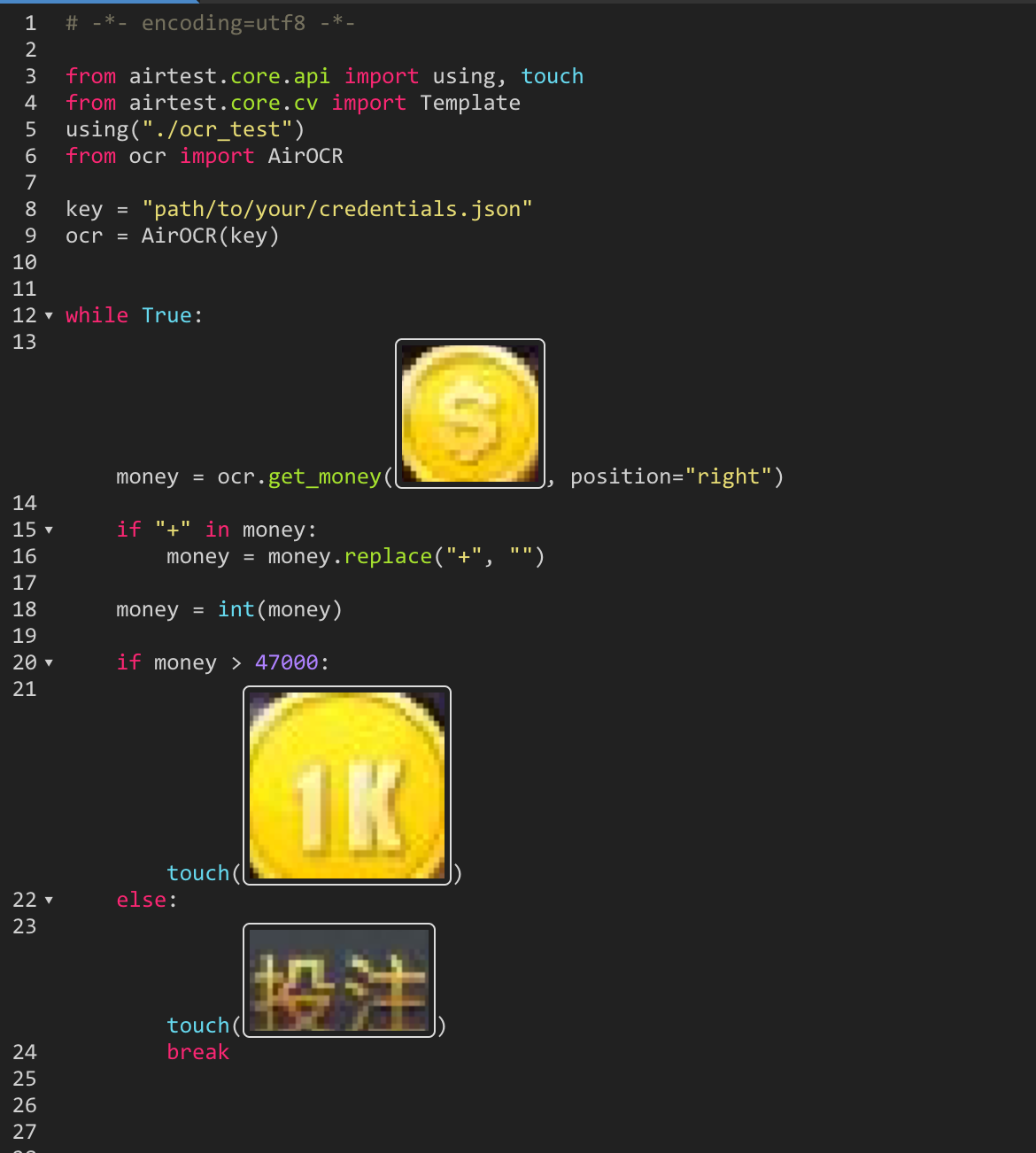
結果
OCR の部分の処理が遅いですが、ちゃんと所持金を扱った自動化ができました。