この記事はフロムスクラッチ Advent Calendar 2016 の10日目の記事です。
前回に引き続きKinesisネタです。
やったこと
2016年8月にKinesis Analyticsが公開され、手軽にストリーミングデータを処理することができるようになりました。Kinesis Analyticsによって、ストリーミングデータに対してSQLでフィルタリング、変換、および集約が可能となったということで、実際に触って試してみました。
手順
1. 下準備をする
- S3のバケットを作っておきます。
- Kinesis Firehose のストリームを作っておきます。
Firehoseの設定について、こちらの記事を参考にしてください。
API GatewayとKinesis Firehoseを使ってGETリクエストをS3にJSONで出力する
2. テスト用のストリームを作成する
Firehose の作成したストリームで、Test with demo data を開き、[Start sending demo data] ボタンをクリックします。[Sending demo data] と表示されれば、テスト用のデモデータが生成されています。
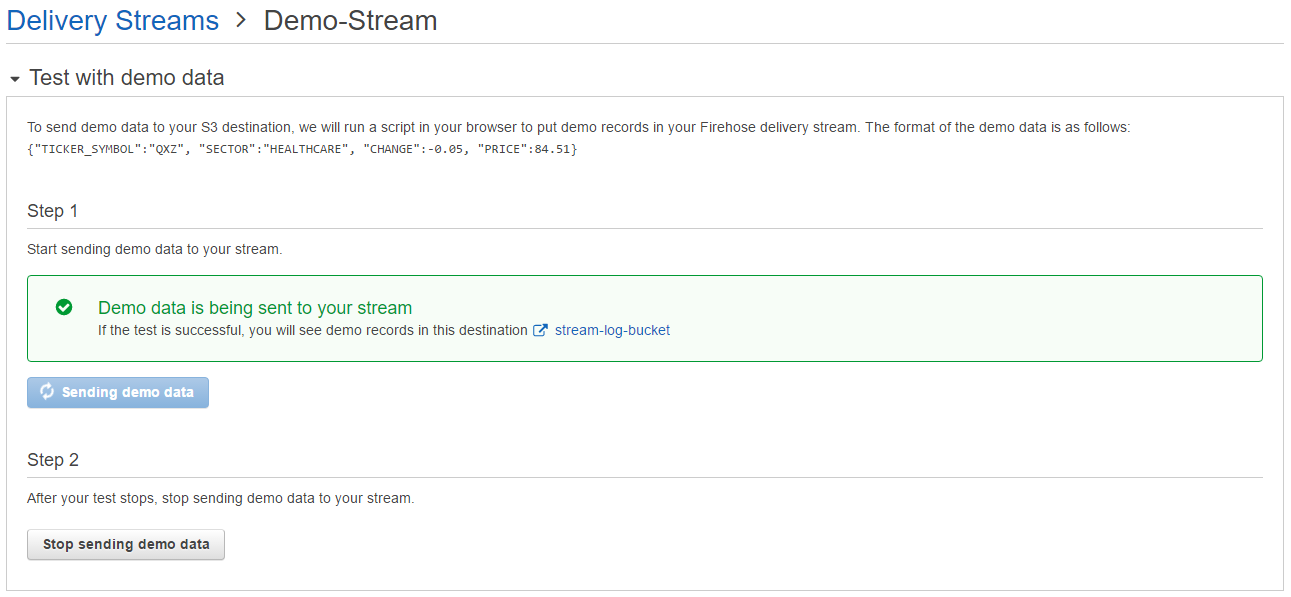
デモデータは以下のようなフォーマットのJSONが生成されています。
{"TICKER_SYMBOL":"QXZ", "SECTOR":"HEALTHCARE", "CHANGE":-0.05, "PRICE":84.51}
3. Kinesis Analytics の設定をする
3.1. インプットストリームの設定
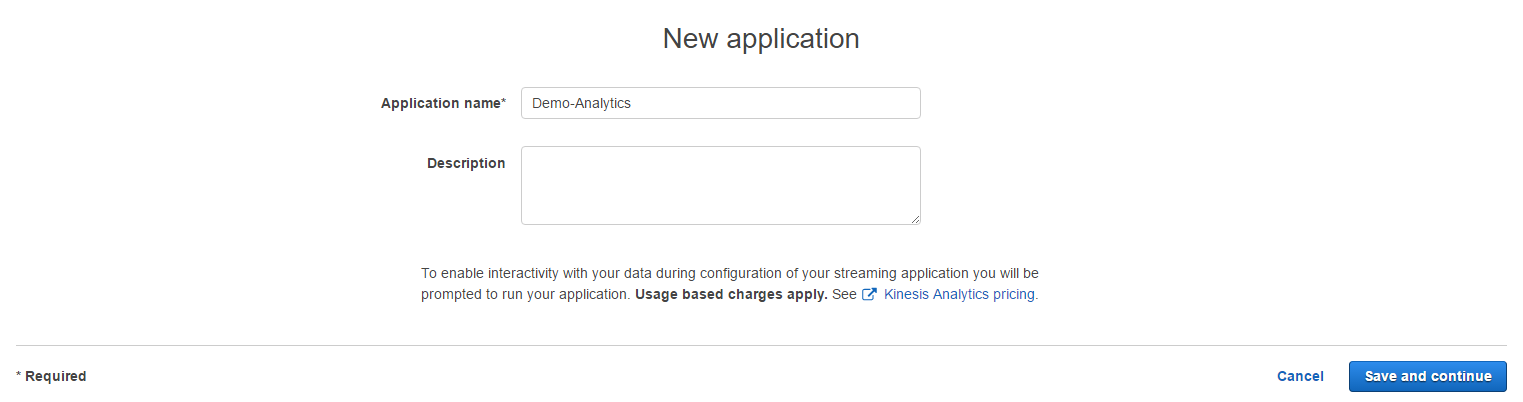
Kinesis Analytics を開き、[Create new application] をクリックします。Application name に任意の名前を入力し、[Save and continue] をクリックします。
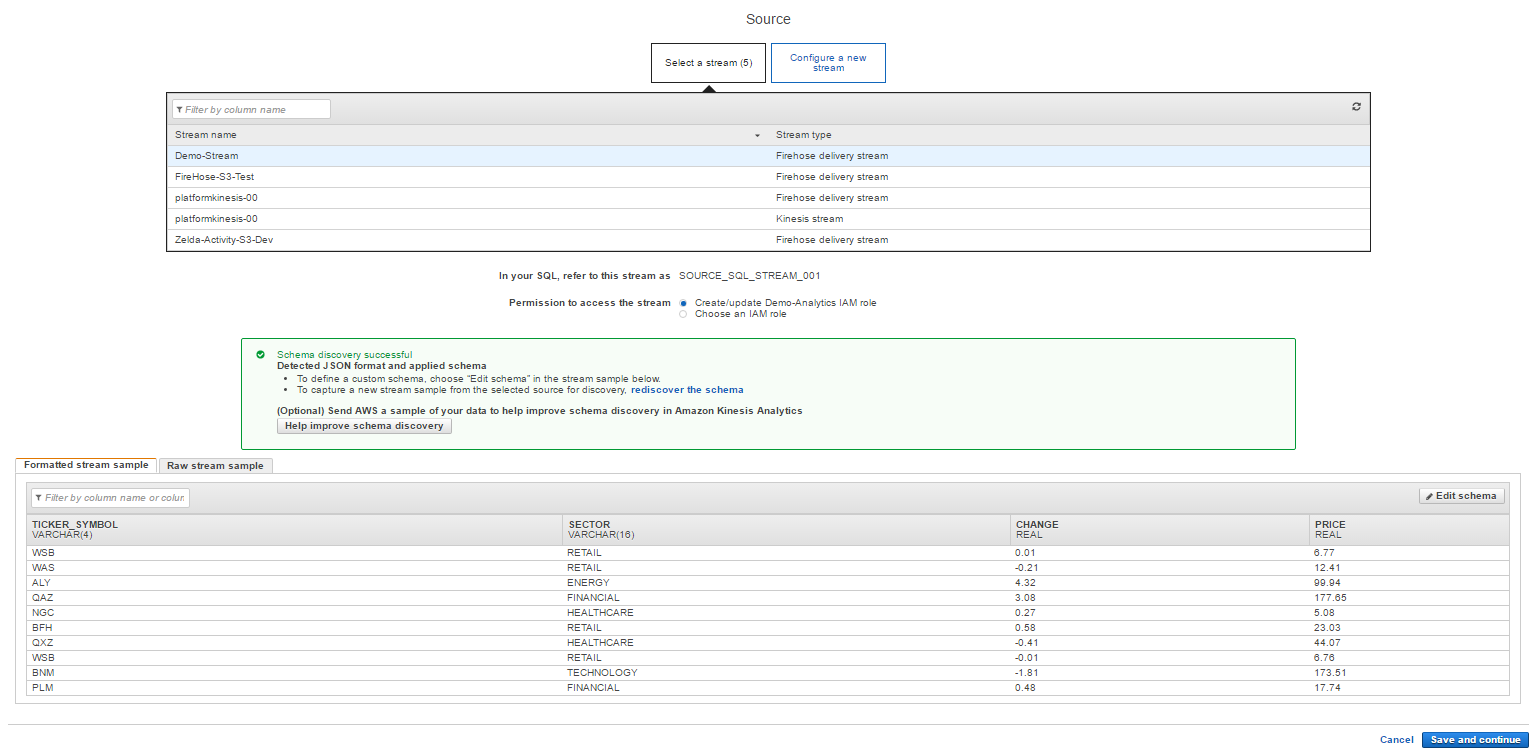
[Connect to a source] をクリックし、先ほど作成した Firehose のストリームを選択します。しばらくするとストリームの内容を読み取って、画面下部にサンプルが表示されるので、内容を確認します。
Firehoseのストリームで生成されているデモデータの内容と一致していることが分かります。
問題なければ [Save and continue] をクリックして、次の設定に進みます。
3.2. クエリの作成と登録
[Go to SQL editor] をクリックします。
まずは [Add SQL from templates] をクリックし、テンプレートからSQLを追加してみます。
Aggregate function in a tumbling time window を選択してみます。
エディタには以下のようなクエリが入力されているはずです。
-- ** Aggregate (COUNT, AVG, etc.) + Tumbling Time Window **
-- Performs function on the aggregate rows over a 10 second tumbling window for a specified column.
-- .----------. .----------. .----------.
-- | SOURCE | | INSERT | | DESTIN. |
-- Source-->| STREAM |-->| & SELECT |-->| STREAM |-->Destination
-- | | | (PUMP) | | |
-- '----------' '----------' '----------'
-- STREAM (in-application): a continuously updated entity that you can SELECT from and INSERT into like a TABLE
-- PUMP: an entity used to continuously 'SELECT ... FROM' a source STREAM, and INSERT SQL results into an output STREAM
-- Create output stream, which can be used to send to a destination
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (ticker_symbol VARCHAR(4), ticker_symbol_count INTEGER);
-- Create a pump which continuously selects from a source stream (SOURCE_SQL_STREAM_001)
-- performs an aggregate count that is grouped by columns ticker over a 10-second tumbling window
-- and inserts into output stream (DESTINATION_SQL_STREAM)
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
-- Aggregate function COUNT|AVG|MAX|MIN|SUM|STDDEV_POP|STDDEV_SAMP|VAR_POP|VAR_SAMP)
SELECT STREAM ticker_symbol, COUNT(*) AS ticker_symbol_count
FROM "SOURCE_SQL_STREAM_001"
-- Uses a 10-second tumbling time window
GROUP BY ticker_symbol, FLOOR(("SOURCE_SQL_STREAM_001".ROWTIME - TIMESTAMP '1970-01-01 00:00:00') SECOND / 10 TO SECOND);
簡単に説明すると、まず出力の為のSTREAMを作成し、その後STREAMに集計したデータを流し込む為のPUMPを作成しています。今回のサンプルは10秒毎のタンブリングウィンドウなので、10秒ずつticker_symbol毎のレコード数がカウントされて出力されるはずです。
更にクエリを追加してみます。
次は、スライディングウィンドウと言って、ストリームに新しいレコードが来るたびに、決められたウィンドウ幅で集計を行って出力する集計方法になります。サンプルではウィンドウ幅が10秒なので、レコードが来るたびに10秒前までのレコードを集計して出力するはずです。
-- ** Aggregate (COUNT, AVG, etc.) + Sliding time window **
-- Performs function on the aggregate rows over a 10 second sliding window for a specified column.
-- .----------. .----------. .----------.
-- | SOURCE | | INSERT | | DESTIN. |
-- Source-->| STREAM |-->| & SELECT |-->| STREAM |-->Destination
-- | | | (PUMP) | | |
-- '----------' '----------' '----------'
-- STREAM (in-application): a continuously updated entity that you can SELECT from and INSERT into like a TABLE
-- PUMP: an entity used to continuously 'SELECT ... FROM' a source STREAM, and INSERT SQL results into an output STREAM
-- Create output stream, which can be used to send to a destination
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM_SLIDING" (ticker_symbol VARCHAR(4), ticker_symbol_count INTEGER);
-- Create a pump which continuously selects from a source stream (SOURCE_SQL_STREAM_001)
-- performs an aggregate count that is grouped by columns ticker over a 10-second sliding window
CREATE OR REPLACE PUMP "STREAM_PUMP_SLIDING" AS INSERT INTO "DESTINATION_SQL_STREAM_SLIDING"
-- COUNT|AVG|MAX|MIN|SUM|STDDEV_POP|STDDEV_SAMP|VAR_POP|VAR_SAMP)
SELECT STREAM ticker_symbol, COUNT(*) OVER TEN_SECOND_SLIDING_WINDOW AS ticker_symbol_count
FROM "SOURCE_SQL_STREAM_001"
-- Results partitioned by ticker_symbol and a 10-second sliding time window
WINDOW TEN_SECOND_SLIDING_WINDOW AS (
PARTITION BY ticker_symbol
RANGE INTERVAL '10' SECOND PRECEDING);
[Save and run SQL] をクリックするとクエリが登録され、集計結果が表示されます。
しばらく眺めていると、結果が更新されていくのがわかります。(集計の結果が正しいのかは、パッとみ分かりにくいですが・・・)
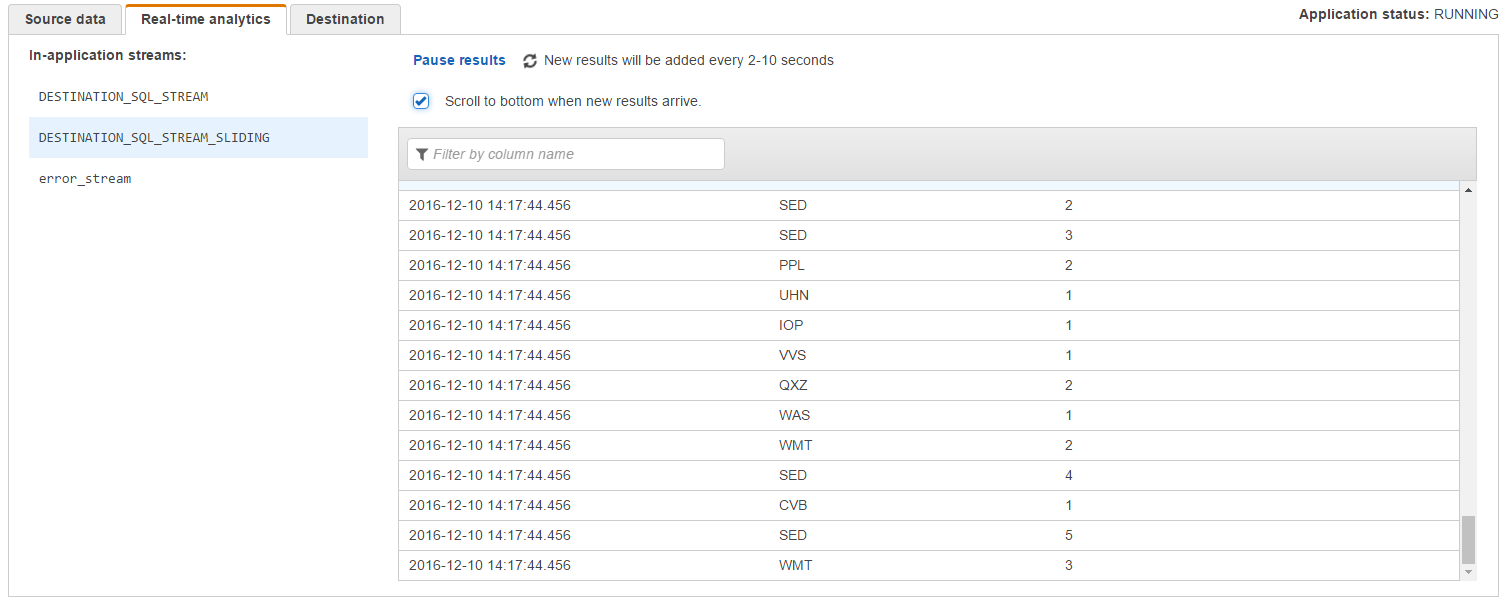
[Exit(done editing)] をクリックして設定を終えます。
3.3. 出力先の設定
最後に [Connect to destination] をクリックして出力の設定に移ります。
[Configure a new stream] を選択して、ここからFirehoseのストリームを作成してみます。
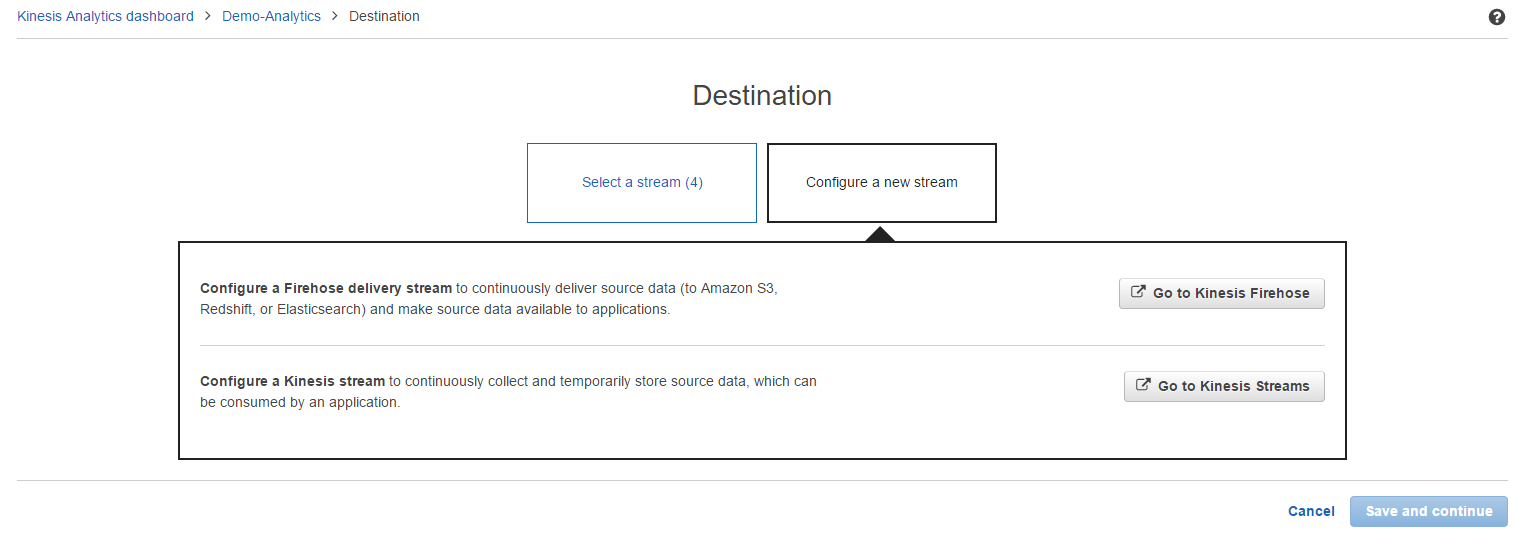
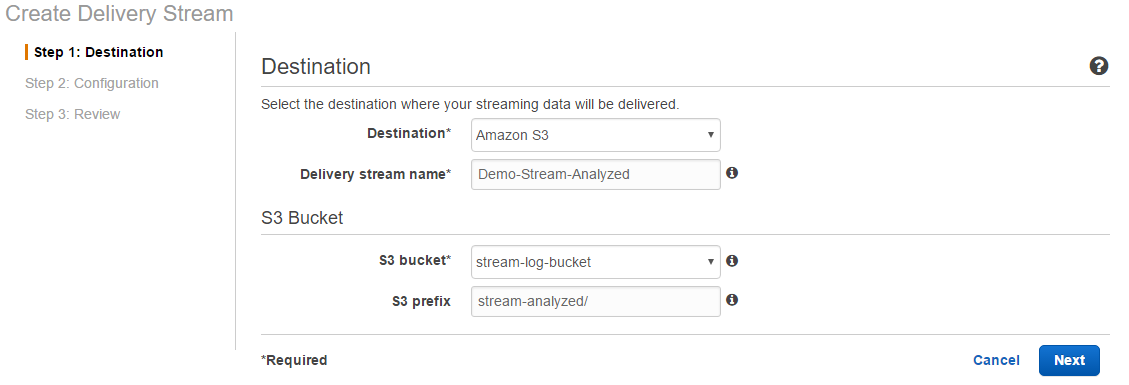
[Go to Kinesis Firehose] をクリックするとFirehoseの設定画面に遷移するので、出力先のS3を指定し、その後もひと通り設定を行います。
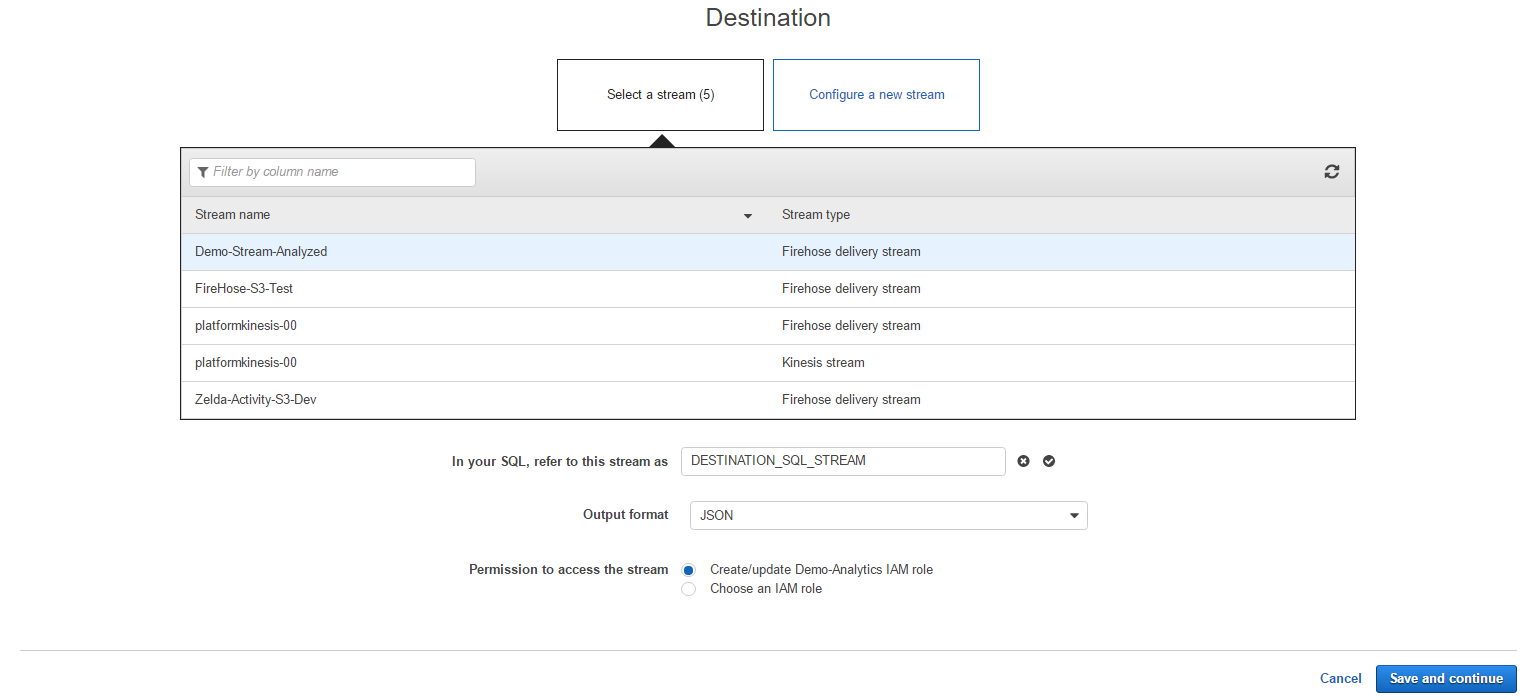
作成したFirehoseのストリームを選択します。出力するストリームはDESTINATION_SQL_STREAMとし、フォーマットはJSONを選択します。
4. 出力結果を確認する
少しするとS3にファイルが出力されます。

ファイルの中身を見てみると、先ほどSQL作成時に確認した内容が出力されていることが分かります。
うまくいったみたいです、よかったよかった。
{"TICKER_SYMBOL":"ASD","TICKER_SYMBOL_COUNT":8}
{"TICKER_SYMBOL":"SLW","TICKER_SYMBOL_COUNT":17}
{"TICKER_SYMBOL":"PPL","TICKER_SYMBOL_COUNT":12}
{"TICKER_SYMBOL":"BAC","TICKER_SYMBOL_COUNT":13}
{"TICKER_SYMBOL":"PJN","TICKER_SYMBOL_COUNT":7}
{"TICKER_SYMBOL":"QWE","TICKER_SYMBOL_COUNT":7}
{"TICKER_SYMBOL":"DEG","TICKER_SYMBOL_COUNT":6}
{"TICKER_SYMBOL":"DFG","TICKER_SYMBOL_COUNT":7}
{"TICKER_SYMBOL":"WSB","TICKER_SYMBOL_COUNT":18}
{"TICKER_SYMBOL":"KIN","TICKER_SYMBOL_COUNT":10}
{"TICKER_SYMBOL":"JYB","TICKER_SYMBOL_COUNT":10}
{"TICKER_SYMBOL":"TGH","TICKER_SYMBOL_COUNT":11}
{"TICKER_SYMBOL":"NGC","TICKER_SYMBOL_COUNT":12}
{"TICKER_SYMBOL":"DFT","TICKER_SYMBOL_COUNT":10}
{"TICKER_SYMBOL":"MJN","TICKER_SYMBOL_COUNT":8}
{"TICKER_SYMBOL":"BNM","TICKER_SYMBOL_COUNT":8}
{"TICKER_SYMBOL":"QAZ","TICKER_SYMBOL_COUNT":8}
{"TICKER_SYMBOL":"MMB","TICKER_SYMBOL_COUNT":9}
{"TICKER_SYMBOL":"CVB","TICKER_SYMBOL_COUNT":7}
{"TICKER_SYMBOL":"JKL","TICKER_SYMBOL_COUNT":9}
5. 今後やりたいこと
今回はデモデータだったのですが、もっと実際のデータに近いデータで色々と試してみたいですね。あと、出力先も手っ取り早くS3にしていますが、ElasticSearchに入れたりKinesis Streamsに入れてLambdaで処理したりということも可能で、そうするともっと活用の道が広がるのでっちも色々と試してみたいなーと。
おわり。