Lambda
Lambdaとは
Serverless
アプリケーション開発者が**「Serverの存在を意識しなくてよい」**クラウドコンピューティングモデル。(Serverlessという名前だけど、Serverがないわけではない)
クラウド提供会社(Amazon, Googleなど)が物理サーバーを実行し、ユーザにリソースを割り当てることでユーザはコードを直接プロダクション環境に配布することが出来るシステムである。
既存の方法
- オンプレミス
- システムで必要なすべてのインフラを直接管理
- インフラ担当者が必要
- Iaas(Infrastructure as a Service)
- インフラの仮想化サービス
- インフラを直接構築する必要なく、管理者パネルで構成・使用
- 仮想のサーバーにシステムを構築
- Paas(Platform as a Service)
- IaaSに追加で、ネットワークとRuntimeまで提供
- アプリを配布するだけで動かせる
Serverlessの方法
- BaaS(Backend as a Service)
- アプリ開発に必要なバックエンドの機能をAPIで提供することで、サーバー開発をしなくても必要な機能を実現可能
- FaaS(Function as a Service)
- Lambdaはここ!
- プロジェクトを関数(Function)として提供されたコンテナーに配布し、必要な時に呼び出す
Lambdaの特徴
- インフラのプロビジョニング、管理が不要
- すべてのアプリケーション・バックエンドのコードを別途の管理なしで実行可能
- プロビジョニング?
- システム資源を割当・配置・配布しておき、必要な時にシステムを使えるように準備しておくこと。
- 自動でスケール
- リクエスト数に応じて自動的に起動数がコントロールされる
- 価値に対する支払い
- 事前に必要なコストなし
- リクエスト数・実行時間に比例する課金(実際の処理量に対する課金のみ)
- 高可用&安全
- 可用性が高く、コードを実行・拡張するのに必要な部分はLambdaが処理
- メンテナンスや定期的なダウンタイムなし
詳細
Lambdaの概念
AWS Lambda 開発者ガイド:AWS Lambda の概念
AWS Lambdaでは、関数を実行してイベントを処理する。
関数にイベントを送信するにはLambda APIを使って関数を呼び出すか、関数を呼び出すようにAWSのサービス/リソースを設定する必要がある。
Function(関数)
AWS Lambdaでコードを実行するために呼び出すリソースのこと。
関数はソースコードとランタイムで構成される。
| \ | ソースコード | Runtime |
|---|---|---|
| 役割 | イベントを処理するロジック | Lambda⇔ソースコードの間で要求と応答を渡す |
| 指定 | ユーザーが直接指定 | Lambdaから提供される もしくは独自の物をビルド |

Runtime
- Lambdaではランタイムを通じて様々な言語での実行環境を提供する
- 実行環境は、ソースコードからアクセスできるライブラリと環境変数を提供
- 環境変数の設定はAWS Lambda 環境変数を参照
- カスタムランタイム
- ユーザーが直接ランタイムをビルドすることも可能
- 詳細はカスタム AWS Lambda ランタイム 参照
イベント
AWS Lambdaは、関数を呼び出すためのAWSの他のサービスと統合されている。
Lambdaと統合する各サービスでは、データがJSON形式で関数にイベントとして送信される。
Lambdaのランタイムはこのイベントをオブジェクトに変換し、それを関数コードに渡す。
イベントの例は、他のサービスで AWS Lambda を使用するにて例 Application Load Balancer のイベントを参照
Trigger
Lambda関数を呼び出すリソースまたは設定のこと。
LambdaはAWSの他サービスや外部アプリケーション、もしくはLambdaからのイベントソースマッピングなどによって呼び出される。
Lambdaトリガーの区分

※ The source of pic:Understanding the Different Ways to Invoke Lambda Functions
-
同期呼び出し (Push)
- Lambda関数を呼び出す一番直接的な方法
- Lambda Invoke APIを呼び出すことで関数が実行される
- 詳細は同期呼び出し 参照
- Lambdaを同期的に呼び出すサービス
-
非同期呼び出し (Event)
- Lambdaにイベントを渡すと、Lambdaが残りの処理をする方式
- 詳細は非同期呼び出し 参照
- Lambdaを非同期的に呼び出すサービス
- Lambdaにイベントを渡すと、Lambdaが残りの処理をする方式
-
イベントソースマッピング (Poll-Based)
- Lambdaがイベントソースを読み取り、Lambda関数を呼び出す方式
- 詳細はAWS Lambda イベントソースマッピング 参照
- Lambdaがイベントを読み取るサービス
- Lambdaがイベントソースを読み取り、Lambda関数を呼び出す方式
Concurrency(同時実行数)
同時実行数とは、ある時点で関数が処理しているリクエストの数のこと
基本的はLambdaのリクエスト処理の流れは以下となる。
- トリガーによって特定の関数が呼び出される
- Lambdaはその関数のインスタンスを割り当ててイベントを処理
- 関数コードの実行が完了すると、別のリクエストを処理できる
リクエストの処理中(インスタンスを使用中)に関数が再度呼び出されると、別のインスタンスが割り当てられるため、関数の同時実行数が増える
同時実行数はリージョンレベルの制限の対象となる(デフォルト:1,000)
ただ、関数別の同時実行数の制限や、特定の同時実行数を達成できるよう設定することも可能
詳細はLambda関数の同時実行数の管理 参照
制限
基本的に、リージョンごとに適用される
詳細はAWS Lambda の制限を参照
コンピューティング・ストレージリソースの制限
※ 同時実行数、関数・レイヤーストレージの制限は、サポートセンターコンソールにて制限緩和申請可能
| リソース | デフォルト制限 |
|---|---|
| 同時実行数 | 1,000 |
| 関数・レイヤーストレージ | 75GB |
| VPCあたりのElastic Network Interfaceの数 | 250 |
関数の設定・デプロイ・実行の制限
※ 下記制限は制限緩和申請不可
| リソース | 制限 |
|---|---|
| 関数のメモリ割り当て | 128MB~3,008MB(64MBごとに増加可能) |
| 関数タイムアウト | 900 秒 (15 分) |
| 関数の環境変数 | 4 KB |
| 関数リソースベースのポリシー | 20 KB |
| 関数レイヤー | 5つのレイヤー |
| 関数の同時実行数のバースト | 500~3000 (リージョンによって異なる) |
| 呼び出しの頻度 (1 秒あたりのリクエスト) | 10 倍の同時実行数の制限 (同期的 – すべてのリソース) 10 倍の同時実行数の制限 ( 非同期的 – AWS 以外のソース) 無制限 (非同期的 – AWS サービスのソース) |
| 呼び出しペイロード (リクエストとレスポンス) | 6 MB (同期)、 256 KB (非同期) |
| デプロイパッケージサイズ | 50 MB (zip 圧縮済み、直接アップロード) 250 MB (解凍、レイヤーを含む) 3 MB (コンソールエディタ) |
| テストイベント (コンソールエディタ) | 10 |
| /tmp ディレクトリのストレージ | 512 MB |
| ファイルディスクリプタ | 1,024 |
| 実行プロセス/スレッド | 1,024 |
料金体系
基本的に、使用した分(関数に対するリクエストの数とコードの実行時間)の料金が発生する
詳細はAWS Lambda 料金
リクエスト数
月100万件まで無料
超過分は100万件で$0.20
コードの実行時間(Duration)
関数に割当てたメモリ量によって異なる
100ミリ秒単位で以下の料金となる
ここでの実行時間とは、Lambdaのライフサイクルでの関数・メソッド実行にかかった時間のこと
この料金表をベースで、1円だと何秒使えるのかも計算してみた
(1ドル=100円計算、小数点以下切り捨て)
| メモリ(MB) | 料金(100ミリ秒) | 秒数(1円) |
|---|---|---|
| 128 | 0.000000208USD | 4,807秒 |
| 512 | 0.000000833USD | 1,200秒 |
| 1024 | 0.000001667USD | 599秒 |
| 1536 | 0.000002500USD | 400秒 |
| 2048 | 0.000003333USD | 300秒 |
| 3008 | 0.000004896USD | 204秒 |
以上の通り、1円あればこれだけ使用可能なので価格面では負担なく気軽に使える
機能
AWS Lambdaには以下の機能が準備され、関数の管理やフレームワークの切り替えなどをサポートする
プログラミングモデル
詳細はプログラミングモデル
AWS Lambdaでは、コードとランタイムコードとのインターフェイスを定義する共通のプログラミングモデルを提供する。
デプロイパッケージ
関数のコードと依存関係を含むZIPアーカイブ
- Lambda APIを使用して関数を管理 or AWS SDK以外のライブラリや依存関係を含める場合
- デプロイパッケージを作成する必要ある
- アップロード方法
- Lambdaに直接アップロード
- Amazon S3 バケットを使用してLambda にアップロード
- デプロイパッケージが 50 MB 以上の場合は、Amazon S3を使用する必要があります。
- Lambda コンソールエディタを使用して関数を作成する場合
- コンソールでデプロイパッケージを管理(他にライブラリを追加する必要がない限り)
- デプロイパッケージにライブラリがすでに含まれている関数をアップロードすることも(合計サイズが 3 MB 以内の場合)
デプロイパッケージを直接作成するケース
Lambda APIを使用して関数を管理する場合や、AWS SDK以外のライブラリや依存関係を含める必要がある場合は、デプロイパッケージを作成する必要がある。
パッケージをLambdaに直接アップロードするか、Amazon S3バケットを使用してLambdaにアップロードする感じ。(デプロイパッケージが 50 MB 以上の場合は、Amazon S3を使用)
デプロイパッケージを作成しないケース
Lambdaコンソールエディタを使用して関数を作成する場合は、コンソールでデプロイパッケージを管理する。
他にライブラリを追加する必要がない限り、この方法を使用したらよい。
この方法でデプロイパッケージにライブラリがすでに含まれている関数をアップロードすることもできるが、合計サイズが3MB以内の場合に限る。
デプロイパッケージのサイズを減らすには
関数の依存関係をレイヤーにパッケージ化したらよい。
レイヤーにより依存関係を独立して管理することで、複数の関数で使えるし他のアカウントと共有できる。
レイヤー
ライブラリ、カスタムランタイム、またはその他の依存関係を含むZIPアーカイブ。
複数の関数で共通に使われるパッケージ・ライブラリをZIPに圧縮し、レイヤーにアップロードすることで、各関数からコード修正なしでパッケージ・ライブラリを使用可能。
詳細
- Lambda関数は最大5つのレイヤー参照可能
- アップロードするパッケージを実行するランタイムが選べる
- パッケージをアップロードすると新しいレイヤーが生成され、各レイヤーはVersion別に管理される(修正不可なので、修正したい場合は新しくアップロードを行い、新しいリビジョンを使用)
メリット
- パッケージング・アップロードするコードが少なくなる
- 依存性を再活用できる
- 関数のコードをミニマル化し、目的に集中したコードにすることが出来る
- 配布時間・頻度の短縮
注意点
- Lambdaの容量制限に関して
- Lambdaの250MB制限は、ソースコードの容量+レイヤーの容量
- ただ単にライブラリーを分けるだけだと、総容量には変更なし
- レイヤーを有効活用するには、共通パッケージ・ライブラリをアップロードすること
- Lambda関数を呼び出すと、呼び出された順番でレイヤーが**/optフォルダに生成される**
- すべて同じフォルダに生成されるので、名前が重複すると上書きされる
関数スケーリングと同時実行数の管理
関数スケーリング
Lambdaは、コードを実行するインフラストラクチャを管理し、受信リクエストに応じて自動的にスケーリングする。
トラフィックが起きて関数の単一のインスタンスではイベントを処理できない場合、Lambdaは追加のインスタンスを実行することでスケールアップする。
また、トラフィックが低下すると、非アクティブなインスタンスはフリーズまたは停止される。
(未使用のインスタンスは課金されない)
トラフィック時に、関数はリージョンの同時実行数の限度までインスタンスを追加する。
これは十分なインスタンス数が確保されるまで、または同時実行数の上限に達するまで続く。
リクエストが入ってくるスピードに関数のスケールが追いつけない場合、または関数が同時実行数の最大値に達した場合、追加リクエストはスロットルエラーで失敗する (ステータスコード 429)。
リージョン別の同時実行数制限
| 同時実行数 | リージョン |
|---|---|
| 3,000 | 米国西部 (オレゴン)、米国東部(バージニア北部)、欧州 (アイルランド) |
| 1,000 | アジアパシフィック (東京)、欧州 (フランクフルト) |
| 500 | その他 |
同時実行制御
予約された同時実行数の設定
特定関数の同時実行数が常に一定レベルになるように、関数に予約された同時実行数を設定可能。
ある関数が予約された同時実行数を使用している場合、他の関数はその同時実行数を使えない。
予約された同時実行数は関数の最大同時実行数も制限し、関数全体に適用される。
同時実行数を予約することは以下の効果がある
-
他の関数が関数のスケーリングを防げなくなる
- 同時実行数を予約されてない関数はすべて、予約されていない残りの同時実行数のプールのみを共有する(予約した分の同時実行数は、予約した関数のみが使える)
- 同時実行数を予約されてない関数は、相変わらず同時実行数が足りなったらスケールアップできなくなる
-
関数のスケーリングが制御不能にならない
- 予約された同時実行数は関数の最大同時実行数に上限を設定する為、特定関数がリージョンで利用可能なすべての同時実行数を関数が使用したり、ダウンストリームリソースを過負荷することを防げる
詳細は予約された同時実行数の設定 参照
プロビジョニングされた同時実行数の設定
- ただ予約するだけだと、各インスタンスでの最初のリクエストは、コードのロードと初期化に時間がかかる
- 初期化に時間がかかると、トラフィックが急昇するときの影響が大きくなる可能性がある。
- 初期化による遅延時間の変動なしで関数をスケーリングできるようにするには、プロビジョニングされた同時実行数を使う
- プロビジョニング済み同時実行を割り当てると、着信リクエストは非常に低いレイテンシーで処理される
- もしプロビジョニングされた同時実行数がすべて使用中の場合でも、関数は通常どおりスケールアップして追加のリクエストを処理
Lambda APIを使用して同時実行を設定
AWS CLI または AWS SDK で同時実行の設定と自動スケーリングを管理することも可能
-
Application Auto Scalingでプロビジョニング済み同時実行数を自動スケーリング
- Lambdaで生成される使用率メトリクスに基づいて、プロビジョニング済み同時実行のレベルを自動調整するターゲット追跡スケーリングポリシーを作成
詳細はLambda API を使用して同時実行を設定する 参照
ライフサイクルとCold/WarmStart
ライフサイクル

詳細を書くとこんな感じ
| 順番 | 段階 | 詳細 | 料金発生 |
|---|---|---|---|
| 1 | (ENI)の作成 | VPCを利用する場合のみ、10~30秒 | 〇 |
| 2 | コンテナの作成 | 2~4 : 指定されたランタイム S3からのDLやZIPファイルの展開など |
× |
| 3 | デプロイパッケージのロード | × | |
| 4 | デプロイパッケージの展開 | × | |
| 5 | ランタイム起動&初期化 | 各ランタイム(2~4)の初期化処理 | × |
| 6 | 関数・メソッド実行 | ハンドラーで指定した関数・メソッドを実行 | 〇 |
| 7 | コンテナの破棄 | 不要になった関数のコンテナを破棄 | × |
料金発生の詳細
-
- (ENI)の作成
- Amazon Virtual Private Cloud (Amazon VPC)による課金(Lambdaの課金ではない!)
- Elastic Network Interface (ENI) でのトラフィックミラーリングの有効化を選択した場合、トラフィックミラーリングが有効になっている各ENIで1時間ごとに課金される(東京リージョンの場合、0.018USD/h)
-
- 関数・メソッド実行
- こちらでの実行時間がDurationとして、Lambdaの利用料金請求の基準となる
Cold/WarmStart
- ColdStart
- 1~7までのすべてのライフサイクルを一通り実行
- もちろん遅い
- WarmStart
- 作成されたコンテナを再利用(1~6までの処理を省略)
- 早いので、出来るだけこちらの状態を維持したい
ColdStartになる状況
使用可能なコンテナがない場合にColdStartとなる
- コンテナがない場合
- 利用可能な同時実行数以上にリクエストが来た場合
- コード・設定を変更した場合
WarmStartを維持するには
- 従来の方法
- 安定的にリクエストが発生していればColdStartは発生しない
- 定期的にLambdaを呼び出す(CloudWatchなどを利用)
- 維持の為に頻繁に呼び出したらコストがかかる…
- 今の方法
- プロビジョニングされた同時実行数の設定を利用
- 本機能を活性化すると、Lambdaの実行環境を設定した数量分事前に用意
- これも料金はかかる
関数ブループリント
Lambdaコンソールで関数を作成する際、様々なブループリントが提供される。
ブループリントでは、AWS のサービスや一般的なサードパーティのアプリケーションでLambdaを使用する方法を示すサンプルコードおよび関数設定プリセットが含まれている。
すでにソースコードが完成されてあるため、環境変数を設定するなどの簡単な操作だけで開発できる。
Lambdaの連携先・使い道によって数多くのブループリントが提供されてるので、開発に時間かけたくない場合は積極的にこちらから欲しい機能を探してみよう。
※ すべてのブループリントはCreative Commons Zero(CC0)で提供されるので、著作権の心配もなし
アプリケーションテンプレート
Lambdaコンソールでは関数のブループリントと同じく、Serverlessアプリケーションを簡単に作成できるテンプレートも提供される。
アプリケーションテンプレートは、MIT No Attribution ライセンスで提供される。
ケースによる使い方
Lambdaを使うケースってどういった感じなんだろう。
考えてみた結果、以下の二つのケースを作ってみることにした。
- CloudWatch Eventと連携したバッチ
- Lambda Layerを利用するケース
ここはハンズオンとして、スクショーやソースコードも書いておく。
最終的にやりたいのはこんな感じ。
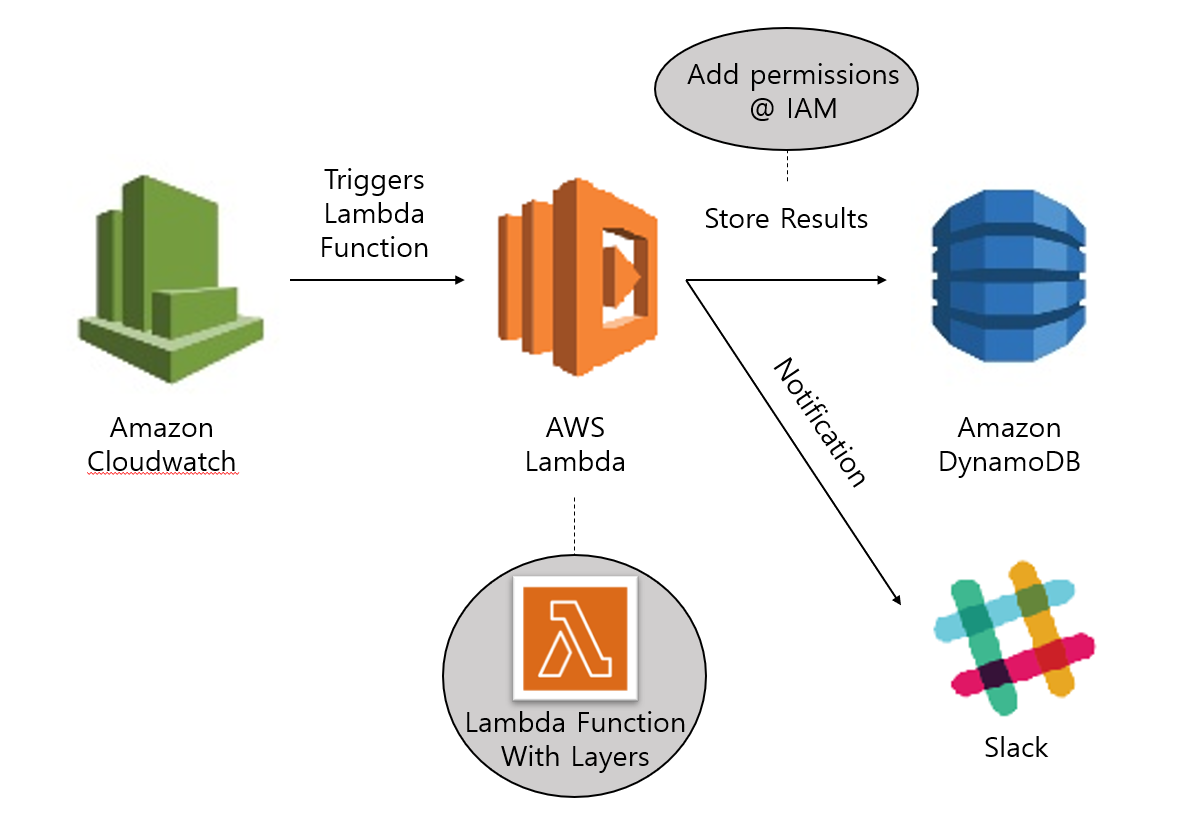
CloudWatch Eventと連携したバッチ
AWS Lambda (node.js) + CloudWatch + DynamoDB + IAM
指定した時間になったら、timestampとrandomな数字をDBに入力するものを作ってみた。
DynamoDB
DBは**DynamoDB**を使う。
まずは以下のように、検索することから。

とりあえずテーブルを作成してみよう。
TablesタブからCreate tableボタン押下。

テーブルの設定を行う。
PrimaryKeyはtimestampに指定。
絶対重複にはならないはずだし、こんなのでいいやー

まだAWS始めたばっかだからFreeTierではあるけど…
お金かかるかも…っぽいものに関しては、最低限にしておこう。
とりあえずCostが一番少ない結果になるように頑張った。

これでDBの準備は完了!

Lambda① (~Function作成)
次は主役の**Lambda**を作ってみよう。
まずはFunctionを作成し、コードを書いておくことまでがここでの目標。
同じく、まずは検索から。

FunctionタブでCreate functionボタン押下。

しょぼいものなので、今回はBlueprintなど使わず、Scratchで作成する。
Author from scratchを選択し、Basic informationを埋めよう。
名前を入力&Runtime Languageを選択してFunctionを作成する。
今回はNode.js 12.xを選択した。

コードはこんな感じ。
// AWS
const aws = require('aws-sdk');
aws.config.region = 'ap-northeast-2';
// DynamoDB
const db = new aws.DynamoDB.DocumentClient();
const TABLE_NAME = 'lambda-batch-db-mark2';
exports.handler = async (event) => {
const timestamp = new Date().getTime();
const randomNo = Math.floor(Math.random() * 10000);
// DB Parameter
const param = {
TableName: TABLE_NAME, // DynamoDBのテーブル名
Item: {timestamp, randomNo}, // InsertするItem
};
// DB Insert
try {
await db.put(param).promise();
} catch (err) {
console.error('Error : Couldn\'t save on DB', err.message);
throw err;
}
console.log('success', param);
return param;
};
エディターがあるから、ある程度快適にコードが書ける。
作成が終わったら、必ず右上のSaveボタンを押下しよう!

ここまででFunctionの作成はOK。
CloudWatch
次に触るのは、CloudWatch。
指定した時間になったらLambdaを呼び出すようにRuleを作成する。
同じく、まずは検索から。

RulesタブでCreate ruleボタン押下。

Event Sourceでは、CloudWatchを動かすスケージュールを設定する。
ここでは適当に**「0,10,25,45 * * * ? *」**と書いてみた。
毎時0分、10分、25分、45分に動く設定。
そして、横のTargetで、上で作っといたLambda functionを選ぶ。
このために、Lambdaを2回に分けたのだ!
ちゃんと選べたら、Configure detailsボタンを押して次へ。

Rule definitionではルールの名前や説明などを記載する。
特に書く内容でもないので、必須の名前だけに。

これでCloudWatchのRule作成が終わった。

Lambda② (~DB連携)
ここまで出来たら、あとはDB連携と動作確認だけ。
まずはDB連携確認のためのテストから作ってみよう。
Lambdaに戻ってきて、Functionの編集画面でSaveボタンの横にあるTestボタンを押下。
特にパラメータなどもいらないので、適当に基本提供のテンプレートから選んで作成しよう。

もうこれでテストしてDB Insertが出来れば嬉しいけど…
悲しいことに、LambdaからDynamoDBへの接続は最初禁止となってる…
なので、IAM ConsoleでLambdaがDynamoDBを触れるようにRoleを追加しよう。
FunctionのConfigurationタブに戻り、Excution roleからIAM consoleに入るとしよう。
以下のように、青いリンクをクリックする。

そうしたら自動にAccess managementのRolesにて、今のFunctionのSummaryを見せてくれる。
これ、最初探すのにめちゃ迷ってた。
ここでAWSLambdaBasicExecutionRoleを開き、Edit policyボタン押下。

今は、さっき作ったCloudWatchのRoleしかない。
ここにDynamoDBへのPermissionを追加したいから、Add additional permissionsをクリックする。

DynamoDBのpermissionを作る。
ServiceでDynamoまで書いたら、DynamoDBの選択が可能となる。

次はActionsを決める。
どこまで許すかだけど、まぁ全部弄れるようにしておこう。
**All DynamoDB actions (dynamodb:*)**にチェックを入れよう。

Resourcesでも同じく、All resourcesを選択。
後はReview policyボタン押下。

ちゃんと設定できたか確認したら、Save changesボタンを押下。

これで私たちのfunctionにて、DynamoDBにアクセスできる!

早速テストしてみよう。
Lambda functionに戻り、さっき作ったtest eventを選び、Testボタンをクリック。
ちゃんとResponseが返ってきてることが確認できた。

そして、DynamoDBに移動し、テーブルを確認。
ちゃんとさっきの内容が入力できたことがわかる。

動作確認
後は、CloudWatchで設定した時間を待つだけ。
設定した時間になり、テーブルにデータが入ってきたのが確認できる。

Lambda Layerを利用するケース
AWS Lambda (node.js & Layer) + Cloudwatch + DynamoDB + Slack
最初は全然別の物を作ろうかなとも思ったけど…
時間の問題もあり、上の内容にLayerとSlack通知機能を追加で入れてみた。
Slack
まずはSlackがLambdaからのPostに反応するように、Webhookを付けたい。
適当にチャンネルを作って、以下のようにIncoming Webhookを検索しよう。
ここでは最近使用したアプリにてアプリをもっと連携さ…からApp追加に入ってたが…
今回見たら、アプリを追加するからはいるようになってる。
英語版だと、Recent AppsのAdd appsを選択すればこの画面が出る。

とりあえずSlackに追加ボタンをクリックする。

Webhookを付けるチャンネルを選び、Incoming Webhookインテグレーションの追加ボタン押下。

ここのWebhook URLは記憶しておこう。
このURLにメッセージをPostすれば、設定したチャンネルにてメッセージが出力される。

これでSlackの準備は漫然。
Lambda Layer
WebhookURLを取得したから、次はLambdaのコードを修正してPostしてみよう。
Postにはaxiosを使いたいし、せっかくnode_modulesを使うならmomentも使っておきたい。
こういったnode_modulesをLambdaで使うには、二つの方法がある。
- ソースコードとnode_modulesを一緒にZIPファイルで圧縮しアップロード
- Lambda Layerにnode_modulesをアップロードし、LambdaにLayerを適用
毎回ソースコードを修正するたびに圧縮→アップロードをするのはさすがにごめんだ。
ここでは当たり前のことに、Lambda Layerという文明の利器を使おう。
ってことで、まずは使用したいnode_modulesをアップロードするLambda Layerを作ろう。
LambdaにてLayerタブを選択し、Create layerボタンを押下。

Layerにアップロードするnode_modulesを準備しよう。
ここでめちゃくちゃ大事なポイントは、以下のツリーのようにnode_modulesフォルダをnodejsという名前のフォルダの中に入れてから圧縮すること。
こうしないと、Lambda Layerが認識してくれない。

公式HPによると、Node.jsの場合は以下の2パターン。
Node.js – nodejs/node_modules、nodejs/node8/node_modules
Node.js以外の場合は、以下のリンクを参照しよう。
ライブラリの依存関係をレイヤーに含める
nodejsフォルダに入れて圧縮出来たら、引き続きLayerを作成しよう。
名前とRuntimeを設定し、圧縮したライブラリーをアップロードしたらCreateボタン押下。
ここでRuntimeはLambda Functionと一致させるのがまた大事なポイント!

正常にLambda Layerの作成ができた。
出来たけど…実はこのVersion1は失敗作。
Runtimeをnode.js 8.10にしてしまって、Lambda Functionと合わなくなった。
Runtimeが合わないと、FunctionにLayerを設定できない。

それでNode.js 12.xで新しくLayerを作ったら、Version 2になってしまった。
Version2しかないのは、失敗作のVersion1は消したから。
今からはこのVersion2で進めるから、Version1は忘れてほしい。

次は、作成したLayerをFunctionに追加しよう。
作成したFunctionのConfigurationにて、Add a layerボタン押下。

以下の画面で、先ほど作成したLayerを選び、Addボタン押下。
ここでVersionが合わないと、Layerがプルダウンに出ない…

ちゃんと追加されたことが確認できる。

Functionのソースコードを、Layerのnode_modulesを使用した以下のソースコードに変更する。
// node_modules by npm-library layer
const axios = require('axios');
const moment = require('moment');
// aws
const aws = require('aws-sdk');
aws.config.region = 'ap-northeast-2';
// DynamoDB
const db = new aws.DynamoDB.DocumentClient();
const TABLE_NAME = 'lambda-batch-db-mark2';
exports.handler = async (event) => {
// slack webhook url
const url = "https://hooks.slack.com/services/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";
const timestamp = moment().format('YYYY/MM/DD hh-mm-ss');
const randomNo = Math.floor(Math.random() * 10000);
const param = {
TableName: TABLE_NAME,
Item: {timestamp, randomNo},
};
// DB Insert
try {
await db.put(param).promise();
} catch (err) {
console.error('Error : Couldn\'t save on DB', err.message);
throw err;
}
console.log('success', param);
let message = '@channel:' + "\n";
message += '*' + timestamp + 'にRandom数値「' + randomNo + '」をDynamoDBに追加しました。' + '*';
// Slack Post
axios.post(url, {
text: message
})
.then((res) => {
console.log(`status : ${res.status}`)
})
.catch((error) => {
console.error(error)
});
return param;
};
PrimaryKeyをYYYY/MM/DD hh-mm-ssの文字列に変えたから、DynamoDBに新しいテーブルを作成しよう。

最後に連携テストをしたら、こんな感じでInsertできた。

動作確認
以下のように、時間になったらRandomな数字をDBに入れ、Slack通知までしてくれるようになった。

まとめ
Lambdaの長所/短所
長所
最初書いたLambdaの特徴を再び書くことになるけど…
- 開発速度
- Serverの事を考えず、Business Logicだけ作成して、LambdaにアップロードすればOK
- Auto-Scaling
- リクエスト数に応じて自動的に起動数がコントロールされるので、リクエストによってサーバーを管理する必要なし
- Demand-based Pricing
- 事前コストがなく、使った分だけ払えばよいので費用がカットできる
- 基本軽い作業に使うものなので、使った分払うとはいえ、重課金になることはない
短所
ほぼ長所しかないが、言うとしたらこんな感じかな。
- 重い作業とは合わない
- メモリ(~3,008MB)と時間(~15分)などの制限があり、緩和も不可=GPUを使うなどの重い作業は無理
- 代わりに、短時間で重い作業をするためのECS Fargate、または普通にECS/EC2を使う
- もしくは、技術の発展を待つ(2018年上半期まで、Lambdaの最大実行時間は5分だった)
- 同時実行数の制限による不安
- テストなどで実行回数が増えると、DoS(Denia of Service)攻撃みたいな感じになってしまう
- Serverless環境でのテスト
- 単体テストならローカルでできるから問題ないが、統合テストをする適切なツールがそこまで見当たらない
- 時間がたったら色々出てきて解決できるはず
使ってみて分かったこと
- AWS自体を触るのが初めてだったけど、各サービス間の連携や権限追加などがすごく簡単にできて驚いた
- 開発・アップロード・テストがすごく楽だった
- AWS初心者ならLambdaから始めてみるのがよいと思う