Attribute-Driven Multimodal Hierarchical Prompts for Image Aesthetic Quality Assessment, MM24
題名の通りこちらの論文についてまとめる。論文はこちら
概要
- Image Aesthetics Quality Assessment はユーザーの美的感覚を模倣して、美的スコアを予測するタスクである。この研究は、SNSの普及に伴い、画像のレコメンデーションや、画像検索、画像のトリミング等に役立つとされる。
- 既存研究では、画像特徴量に加え、構図や明るさ、スタイル等の美的属性値を学習モデルに明示的に与える手法が高精度な予測につながるとされていた。しかし、数値を与えるがゆえに解釈性に欠けることや、画像と美的属性の関連性を学習することは、難しい。
- 近年、マルチモーダル学習が主流となりつつある。VLMに対してファインチューニングする手法や、プロンプトラーニングする手法があるが、ユーザーの美的評価に影響を与える要素を明らかにできていない。
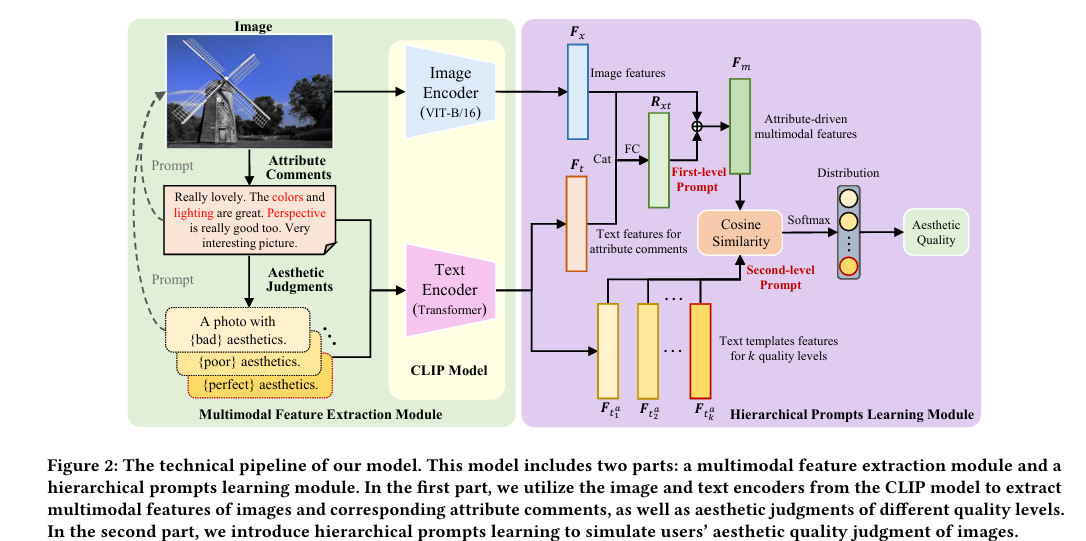
- そこで、本研究ではユーザーが美的属性に関するコメントを読んでから画像評価を行うことを考慮し、 VLMを活用した、attribute-driven multimodal hierarchical prompts learning method (AMHP)を提案する。これは、ユーザーの評価プロセスに近づけるために、VLMに対するプロンプトを美的属性に関するコメントと、美的スコア別のテキストテンプレートの入力2段階に分けて、プロンプト学習を行う手法である。これによって、ユーザーが評価を行う際の着目箇所と、美的属性の意味的情報の考慮を可能にした。(CLIPでマッピングを学習している)
- いくつかの美的評価用データセットにより、提案手法がSOTAの方法よりも優れていることを示した。
既存研究
- 画像特徴量とその画像の属性を考慮することで精度向上
- Photo Aesthetics Ranking Network with Attributes and Content Adaptation, 2016
- Theme-Aware Visual Attribute Reasoning for Image Aesthetics Assessment, IEEE Trans. 2023
- Aesthetic Attributes Assessment of Images, MM19
- Personalized Image Aesthetics Assessment with Attribute guided Fine-grained Feature Representation, MM23
- これらの研究では、数値的な属性特徴量や暗示的に属性を考慮していたり、画像と属性性のマッピング関係を学習させている。これは、効率的にユーザーの美的感覚と画像の関連性を学習するには難しいという問題点が残る。(深さとか、明るさとか数値で表現しているから、これは解釈性に欠けるっていう意味)
- 最近ではマルチモーダル学習することが良く行われている(semanticな情報をとれる
- AesExpert: Towards Multi modality Foundation Model for Image Aesthetics Perception, 2024
- AesBench:AnExpertBenchmark for Multimodal Large Language Models on Image Aesthetics Perception. 2024
- Deep Multimodality Learning for UAV Video Aesthetic Quality Assessment. MM22
- Joint Image and Text Representation for Aesthetics Analysis. In Proc, MM16
- AesCLIP: Multi-Attribute Contrastive Learning for Image Aesthetics Assessment, MM23
- マルチモーダルモデルをファインチューニングしている手法
- Exploring Clip for Assessing the Look and Feel of Images, AAAI 23
- シンプルなプロンプトで、マルチモーダルモデルを提案
- VILA: Learning Image Aesthetics from User Comments with Vision-Language Pretraining, CVPR 23
- - これらの、研究の問題点としてユーザーの美的評価に影響を与える要素を明らかにしていない。また、事前学習済みモデルを直接活用しているため、画像の品質を美的評価に最適化できていない。(この論文も
次に読みたい論文
- Semantics-Aware Image Aesthetics Assessment using Tag Matching and Contrastive Ranking, MM24
- Multi-Modality Multi-Attribute Contrastive Pre-Training for Image Aesthetics Computing, IEEE Transactions on Pattern Analysis and Machine Intelligence 2024
- これらは似たような手法で最新のもの。何が違うのかを知りたい。
簡単な独自のQ & A
- Semantic feature とは
- ユーザーの画像に対する評価コメントと、スコア別のテキストテンプレートを特徴量化したもの。画像特徴りょと区別するために、このように読んでいると思われる。画像をテキストでとらえることで、その意味を明示的にモデルに学習させるっていう意味で、semanticだと考えられる。
- multimodal fetureとは
- これは、画像特徴量とテキスト特徴量のこと
- 階層的なプロンプトとは
- CLIPに2段階でプロンプト学習を行っているため、階層的と呼ばれる。正確には階層的なプロンプト学習
感想
- CLIPをプロンプト学習することで特徴量抽出器として使っていて、実際に提案手法がパラメータを持つ部分はFCしかないため、拘束に学習が行える点が良いと思った。
- スコア分布の予測の際に、コサイン類似度を使っているが、これをなにか工夫できないかと考え中。これだと、CLIPによって得られた特徴量ありきな気がした。