決定木
##決定木とは
Yes/Noで答えられる質問で構成された木構造によりデータを分析するアルゴリズムであり、分類木と回帰木を組み合わせたものを指す。
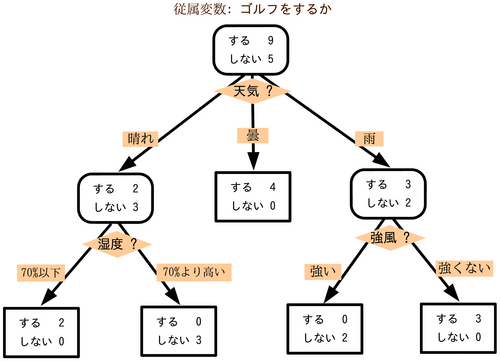
図1:決定木の例
例えば子の図1の決定木であれば、木の根の部分でゴルフをするかしないかという質問に対して(Yes/Noで答えられる)すると答えた人が9人、しないと答えた人が5人であることを表してる。その次に晴れと曇りと雨の書く場合についてゴルフをするかしないかとう質問をする。それぞれ答えていき木の葉の部分がデータの分析結果を表す。
決定木の長所
決定木の長所は
- 分析結果を木構造のグラフで可視化できる。
- 可視化により専門的な知識がない人にも説明が容易にできる。
- 可視化によりデータセットの深い理解につながる。
- データスケールに対して完全に不変であること。
- 特徴量が各々独立しているから正規化や標準化の必要がない。
の2点である。
- 特徴量が各々独立しているから正規化や標準化の必要がない。
決定木の短所
決定木の短所は
- 実行時間が長い。
- 後刈りや前刈りといった処理をしても過剰適合しやすい。
の2点である。
凡化性能をたかめるためにアンサンブル法という手法が使われる。ほとんどのアプリケーションではアンサンブル法が使われている。
決定木のアンサンブル法
アンサンブル法とは
アンサンブル法のアンサンブルとは
*仏: ensemble)は、音楽用語で2人以上が同時に演奏すること。 合奏、重奏、合唱、重唱の意味、あるいはそれらの団体の意味にも用いられる。
という意味である。個々の力では少し足りないが、いくつかを組み合わせればより大きな力を発揮するというイメージがつかめると思う。
では機械学習でのアンサンブル法とは、複数の機械学習モデルを組み合わせてより強力な学習モデルを作る事である。ここでは決定木のアンサンブル法であるランダムフォレストと勾配ブースティング木について紹介する。
##ランダムフォレスト
ランダムフォレストとは、'ブートストラップサンプリング'を行い、それぞれのデータを決定木で分析し、そのそれぞれの分析結果をから多数決により最終的な分析結果を出力するアルゴリズムである。ただし、サンプリングしたデータから決定木をいくつか作る際、特徴量のサブセットをランダムに抽出し、その特徴量を使うものの中から最適な決定木を作成する。これにより特徴量の異なる決定木をいくつも作ることができ乱数性が高くなる。
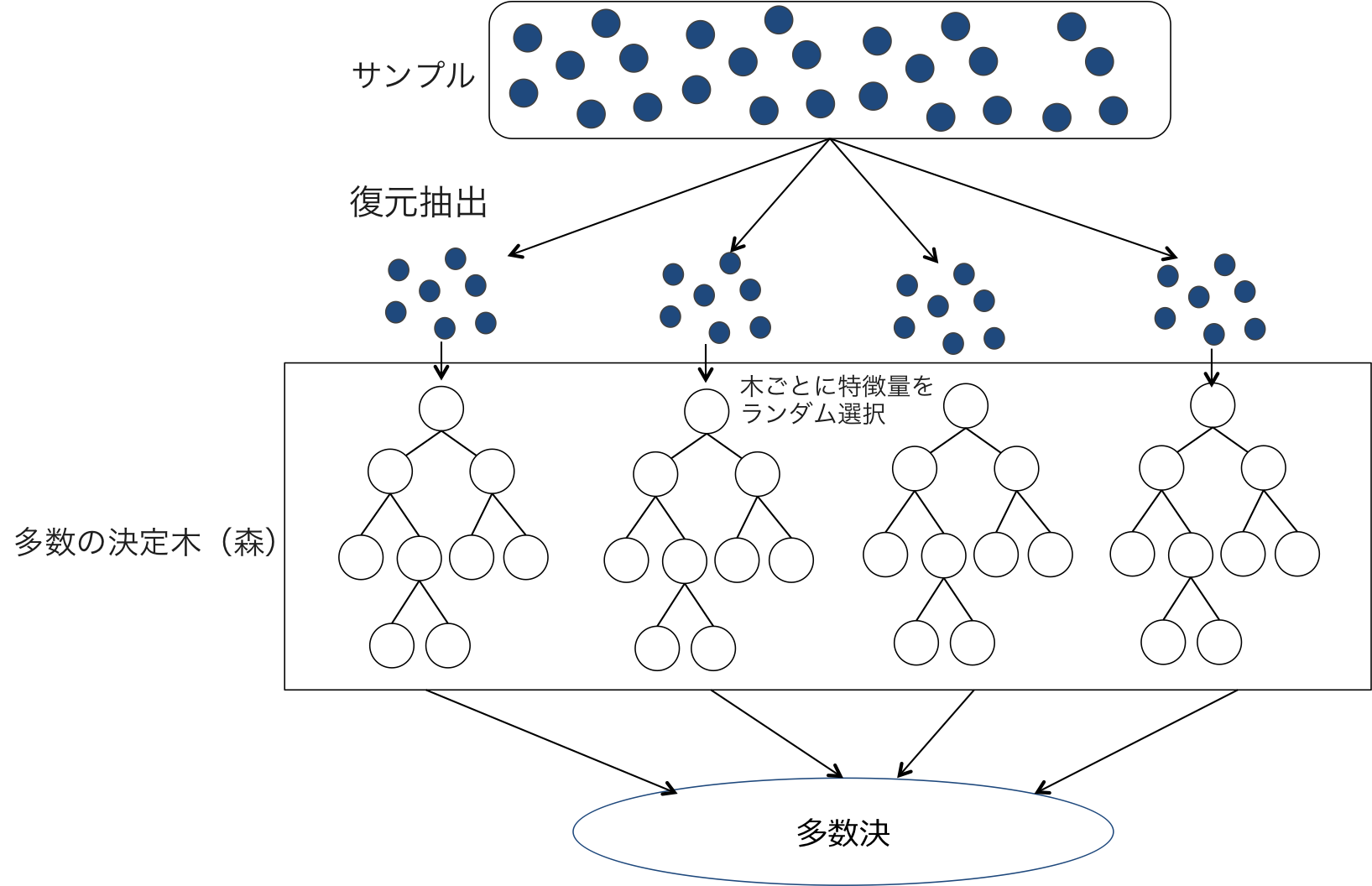
*図2:ランダムフォレストのイメージ
ブートストラップサンプリング
ブートストラップサンプリングとは、N個のデータから成る集合からN個の復元抽出を行うサンプリング法である。例えば集合{a,b,c,d,e}からブートストラップサンプリングを行うと{a,a,a,b,c}や{a,b,c,d,d}などの集合が得られる。
ランダムフォレストの長所
ランダムフォレストの長所は
- 多くの場合パラメータチューニングをする必要がない。
- データスケール変換をすること必要がない。
- CPUコアを用いて処理を並列化できる。
の3つである。
ランダムフォレストの短所
ランダムフォレストの短所は
- 大きなデータセットだと処理に時間がかかる。
点である。
勾配ブースティング回帰木
勾配ブースティング回帰木とは、名前に回帰とあるが回帰と分類両方に使えるアルゴリズムである。1つ前の決定木の誤りを次の決定木が修正するようにして決定木を順に作っていく(ブースティング)。
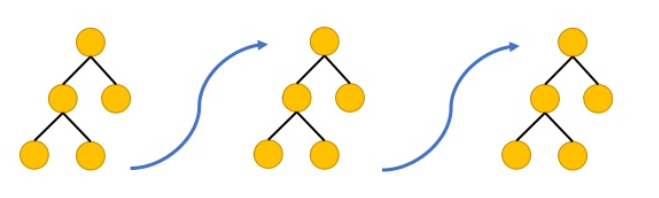
*図3:ブースティングのイメージ
図3のように木を何個も繋げて修正していくが、このとき事前枝狩りが行われる。どの木の深さも1~5くらいである。こに勾配ブースティング回帰木はよく使われている。
勾配ブースティング回帰木の特徴
-
勾配ブースティング回帰木は、事前枝刈りと木の個数の設定するパラメータのほかに学習率というパラメータがある。これがランダムフォレストとの違いでもある。学習率とは前の木を次の木でどのくらい修正するかを決める割合である。例えば、学習率10%であれば、10%だけ修正して次の木を作る。これらのパラメータを適切に設定できればランダムフォレストよりも性能が良くなる。
-
木の数を多く設定すればモデルが複雑になり過剰適合しやすくなる。(その訓練データだけに適合してしまう)
-
学習率を高くしすぎると過剰適合してしまう。
-
木の数をメモリ量や実行時間で決定してから学習率を決めるという方法が良く使われる。
ランダムフォレストと勾配ブースティング回帰木の比較
-
精度
- パラメータを適切に設定できれば勾配ブースティング回帰木の方が精度が良い。
-
実行時間
- 勾配ブースティング回帰木の方が訓練に時間がかかるが予測がはやくメモリも小さい。
-
パラメータ
- ランダムフォレストは
木の数、各々の木の深さであるのに対し、勾配ブースティング回帰木はそれに加えて学習率が追加される。
- ランダムフォレストは
-
木の数
- ランダムフォレストはバギングを行い並列的な木の処理を行ったが、勾配ブースティング回帰木はブースティングを行い直列的な木の処理を行った。ランダムフォレストは木が増えるほど精度が上昇するが、勾配ブースティング回帰木は複雑なモデルを許容することになり過剰学習が起こりうる
-
等しい点
- 高次元の疎なデータにはうまく機能しない。
- 特徴量のデータスケール変換を行わなくてよい。
以上の点が比較結果である。