Azure Machine Learningは、Webブラウザで手軽に機械学習のモデルを作成することができるプラットフォームです(2015年2月正式リリース)。
ここで作成したモデルはWeb APIから呼び出すことができます。
今までは機械学習を組み込む・・・となるとPython等のライブラリを使うことが一般的で、なれた言語とは異なるプラットフォームで開発しなければならないことも少なくありませんでしたが、これでWebリクエストさえ飛ばせれば機械学習アルゴリズムを利用したアプリケーションを開発することが可能になりました。
今回は、このAzure Machine Learningを利用したアプリケーション開発について、その手順を紹介します。以下は、今回作成したモデルの最終的な図になります。このフローに沿って解説していこうと思います。
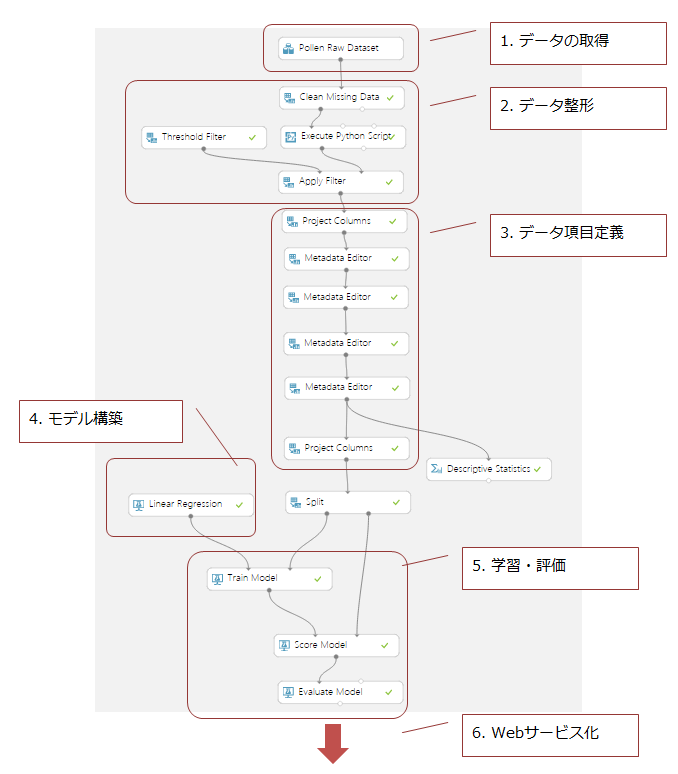
このモデル、およびこのモデルを利用したアプリケーションのコードは以下のGithubリポジトリからアクセスできます。ただ、後述する通りモデルの精度は残念なものなので、自分なりのチューニングなどしてみるもの一興かと思います。
リポジトリのWikiには参考になるサイトへのリンクも貼ってあるので、併せてご参照ください。
0.データの準備とモデル設計
最初に、どんなデータを学習させて何をさせようとするのかを決めておきます。具体的には、最終的なモデルのインプット/アウトプットを設計し、そのためのデータにあたりを付けます。
機械学習でできることは、本当にざっくり言ってしまえば「値の予測」か「分類の判定」です。これはどんな複雑な、ディープラーニングのような学習機でも変わりません。
まず何を予測/分類したいのかを決め、それに必要なデータが公開していないか漁る、という進め方をした方が効率的に時間が使えることが多いです(経験的に)。ただ、公開されているデータというのもそうないので、その制約に縛られてしまうことも多いですが・・・
今回は、花粉の飛散量を予測することにします。天気予報で得られるパラメーターを入力として花粉の飛散量を予測し、花粉対策に役立てる・・・という寸法です。
花粉の飛散量は以下で公開されているので、これを学習データとして利用します。
天気予報は、実はありそうでなかなか無償で使えるものがなかったのですが、いい感じのものを見つけたのでこちらを利用します。飛散量のデータには気温の他に風速や風向きなどがあるのですが、こちらのAPIではそれらもとることができます。
1.データの取得
ここからAzure Machine Learningを使っていきます。こちらから今すぐご利用しましょう。左下の+ボタンから新規にモデルを作成することができます。
最初は、データの読み込みから始めます。
Data sourceとして一番使うのは「Web URL via HTTP」だと思います。今回はGitHubリポジトリにCSVファイルをpushし、そのRAWのアドレスを指定してデータをロードしました。
※残念ながら2015/3時点ではJSON/XMLデータに対応していないため(Azure Marketplaceで使われているODataは使えます)、フィードやAPIから取得したデータをそのまま入れるのは難しい状況です。
データを取得するため、というか作成したプロセスを実行するには下にある「RUN」のボタンを押します。実行が行われるとデータが取得されているはずです。
Azure Machine Learningの特性として、データの可視化機能が簡単に使えるという点があります。場所が分かりにくいですが、実行後以下の場所で右クリックを押すと「Visualize」というメニューがあるはずです。それを実行すると取得したデータの情報を見ることができます。これできちんとデータが取得できているか確認しましょう。
また、Statistical Functionsをつなげることでデータの統計情報について詳細を参照することができます。これは、今後異常値の検知などを行っていくのに役立ちます。
データがきちんとロードできていたら、Visualizeと同様コンテキストメニューから「Save as Dataset」でデータを保存しておきます。
今後データフローを構築していく中で、何度もプロセスを実行することになります。そのたびにHTTPリクエストで大量のデータを取ってくるのは効率が悪い上取ってくる相手にも負荷をかけてしまうので、Datasetとして保管しいつでも使えるようにしておきます。
ここまでのポイントをまとめておきます。
- データの取得はReaderで行う。「Web URL via HTTP」により、Web上のファイルを取り込むことができる
- RUNによりプロセスの実行を行う
- コンテキストメニューによりデータのサマリを見ることができる。Statistical Functionsと合わせ、データの内容の確認に利用する
- データは一旦取得したら「Save as Dataset」で保管しておく
2.データ整形
データの中には欠損や異常値があったりするので、それを取り除いたり埋めたりする作業を行います。これをしているかしていないかでだいぶ精度が変わったりするので、非常に重要なプロセスです。
下記は、取り込んだデータをStatistical FunctionsのDescriptive Statisticsに繋ぎVisualizeしたものです。
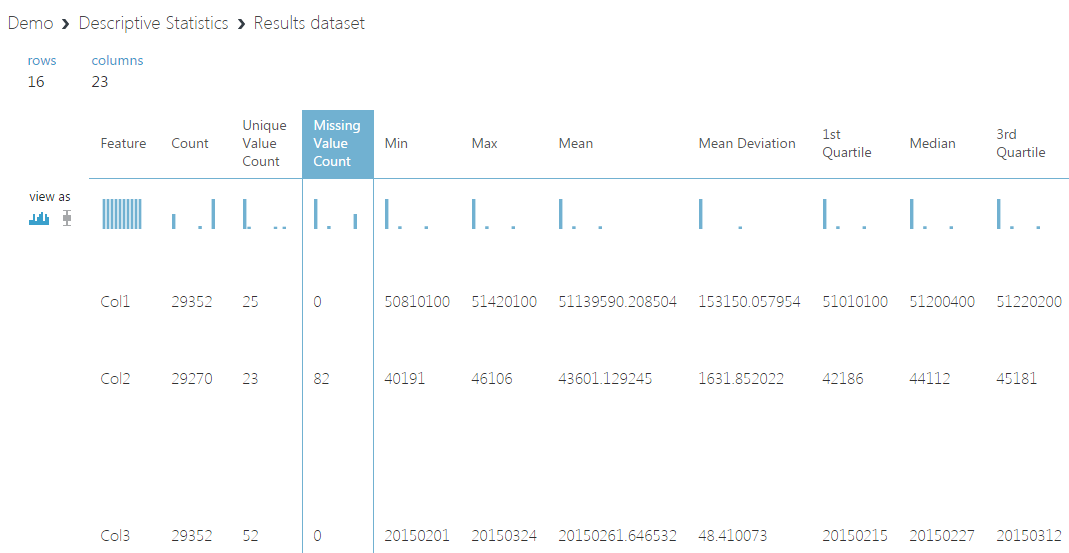
ここから以下のようなことが分かります。
- Col2(アメダス測定局コード)が空白の欠損データが存在する
- Col11(花粉飛散数)は、単位が個数/m3なのでマイナスはないはずだがマイナスのデータがあり、また最大値が異常に大きい(89773)
- Col14/Col15(気温・降水量)に異常値と思われる値が-999のデータがある
欠損・異常値のデータ件数はそれぞれ82件・4件と全体約30,000件からしてだいぶ少ないので、今回はすべて削除してしまうことにします。
花粉の飛散量については確認したところ一応正常なデータっぽいので一旦はこのまま・・・いったんですが、精度があまり出なかったので最終的には1,500を超えるものは1,500を上限として設定しました。
この1,500という値はデータ提供元であるはなこさんによると花粉の数1,000以上はもうすべからく危険領域であるようだったので、それより少し多めの数でカットすることにしました。
統計情報によると花粉飛散量の3rd Quartile(75%四分位点・小さい準から並べて75%のデータが入る地点)は45であり、ほとんどのデータが小さい範囲に入っていることが分かります。なので、カットの影響はそれほどないはずです。
この時点で回帰というよりは花粉飛散量を大中小ぐらいに分けた分類問題にした方がよさそうな気配がしますが、今回はAzure Machine Learningを使ってアプリケーションを作ってみるということが目的だったので、いったんそこは棚上げにして次に進みます。
欠損データと異常値について方針を決めたら、それを実装していきます。
- 欠損データの処理には、Data TransformationのClean Missing Dataを使います
- 値によるデータ削除にはPython Language ModelsのExecute Python Scriptを使います
- 値の上限・下限といった設定にはData TransformationのFilterを使います
実際は以下のような感じで実装しました。
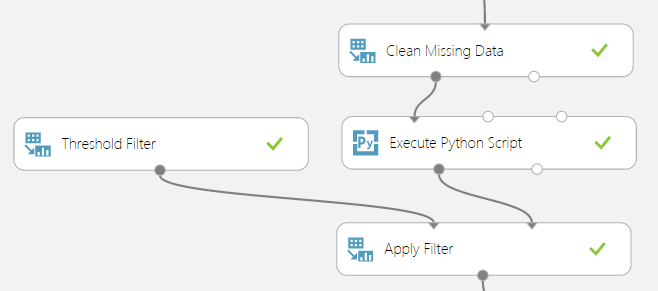
Clean Missing Dataに限らず、以後この列に対して~という設定のためにColumn Selectorを開くことがままあります。ここでの設定方法には少し注意が必要です。
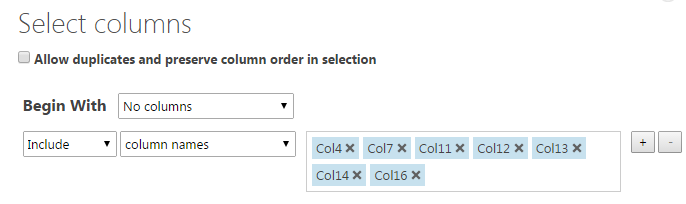
基本的には、「全ての列からxxを除く」か「yyの列のみ」という指定になります。つまり、Begin WithがAll columnsの場合はExclude、No columnsの場合はIncludeを使うのが原則です。All columnsでさらにIncludeしたりすることに意味はないので注意してください。
Filterは名前からして「xx列がyy以上のデータを削除する」という用途に使えるかと思いきや、そうではありません。Filterは値の上限や下限を設定したりするのに使います(Threshold Filter、Greater Than 1,500なら1,500以上は1,500に設定される)。Apply FilterとFilterを組み合わせることでFilterの適用が可能です。
逆に、「xx列がyy以上のデータを削除する」という用途に使えるものは今のところない・・・ようなので(Clean Missing Dataは欠損値に対してしか作用しない)、Python Scriptで対応することにします。
Python Scriptは受け取るDatasetが引数として渡され、返り値として後続のフローに渡すデータセットを返します。引数の型はpandasというデータフレームを扱えるライブラリの形式で入ってきます。なお、書けるPythonは2015/3時点では2.7なのでPython3ユーザーは注意してください。
今回使用したScriptは以下のようなものです。異常値と思われる値のデータをはじいています。
# The script MUST contain a function named azureml_main
# which is the entry point for this module.
#
# The entry point function can contain up to two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
# print('Input pandas.DataFrame #1:\r\n\r\n{0}'.format(dataframe1))
# If a zip file is connected to the third input port is connected,
# it is unzipped under ".\Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
erased = dataframe1[dataframe1.Col11 >= 0]
erased = erased[erased.Col14 > -50]
erased = erased[erased.Col16 >= 0]
# Return value must be of a sequence of pandas.DataFrame
return erased,
ここまで来たらRunを実行してみて、Visualizeでちゃんとデータが処理されているか確認します(欠損値や異常値が消えているかなど)。
3.データ項目定義
データの項目定義とは、具体的には以下のようなものです。
- 特徴量として使う項目か、予測値(ラベル値)として使う項目か
- データ型
- 項目名の付与
今回は以後のプロセスで扱いやすいよう項目に名前を付け、データ型をFloatにして花粉飛散量を予測値・それ以外を特徴量にしています。
この作業には、Data Transformation > ManipulationのMetadata Editorを利用します。
そして、使う特徴量を絞り込みたい場合はData Transformation > ManipulationのProject Columnsで使う列を絞り込みます。
モデルでは特徴量を突っ込めばいいというものでもなく、予測対象に良く効く少数精鋭で行った方が基本的にはいいです。そのため、すべての特徴量を使う場合でも、プロセスの中にこのProject Columnsを置いておき、後で使う特徴量の数を調整できるようにしておいた方がいいです。
4.モデル構築
お待ちかねの機械学習モデルの構築を行います。ここまでがだいぶ長かったことからもわかるとおり、機械学習のプロセスとはその大半がデータの整形・加工のプロセスでもあります。
Machine LearningのセクションはEvaluate・Initialize Model・Score・Trainの4つに分かれています。

Initialize Model > Train > Score > Evaluateというのが基本的な流れです。モデルを初期化し、学習させ、評価用データで値を予測させてみて、その結果を評価する、という流れです。
モデル構築ではInitialize Modelを選択し、今回は値の予測を行うのでLinear Regressionを利用します(実はNeural Networkでもやったんですが、あまり精度が出なかったので結局Linear Regressionに戻した)。
ちなみに、提供されているNeural Networkはディープラーニングにも十分対応できるものになっています。特にWindowsではDeep learning系のライブラリをインストールするのが難しかったりするので、大規模なものでない場合やとにかくパターンを色々試してみたい場合はこちらを使うのは十分ありだと思います。
各モデルには初期化パラメータがあり、どんな値を設定するかについてはやはり知識を問われます。Propertiesの一番下からドキュメントを参照することもできるので、そちらも見ながらパラメーターを設定します。
5.学習・評価
ここでモデルとデータがそろったので、それを利用して学習・精度の評価を行います。
まず、Data Transformation > Sample and Split > Splitを使用し学習用と評価用に分割します(下図のイメージ)。
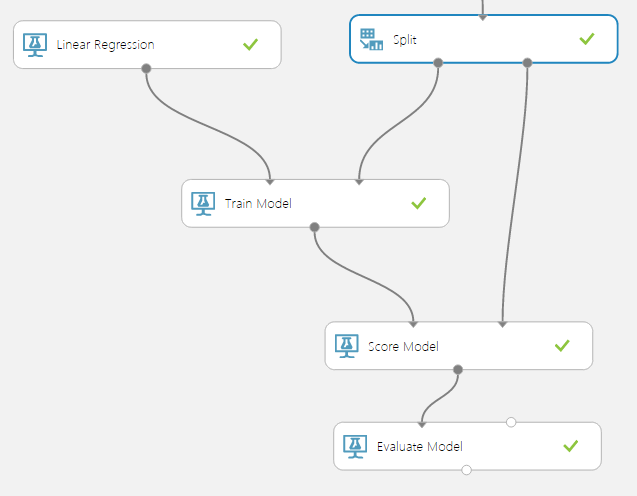
学習する前にデータの正規化をしないと、と思いますが多くの学習モデルはInitialize ModelのPropertyの一部として正規化の方法を指定するようになっているので、個別に正規化を行う必要はありません。今回のように値の予測を行う場合は、学習時正規化したなら予測値も正規化された値なので、本来は復元のための計算が必要になります・・・が、これもうまいことやってくれるようです。逆にData Transformation > Normalize Dataなどから正規化を行いモデルでの正規化をなしにすると、おそらくこの復元が効かなくなると思います。
学習に使用するTrain Modelで設定するのは予測値(ラベル値)の項目一つだけで、他の項目は特徴量としてモデルに渡されます。
Train Modelからは学習済みのモデルが渡され、それがScore Modelに繋がっていきます。ここで、学習済みのモデルを使用し評価データから値を予測します。予測した値と実際の値の差異は、最後のEvaluate Modelで参照することができます。
もちろん、ここはCross Varidationで一気に済ませるという手もあります。
フローを構築後に、今まで同様RUNでプロセスを実行することで実際に学習や評価が行われます。
気になる結果ですが・・・
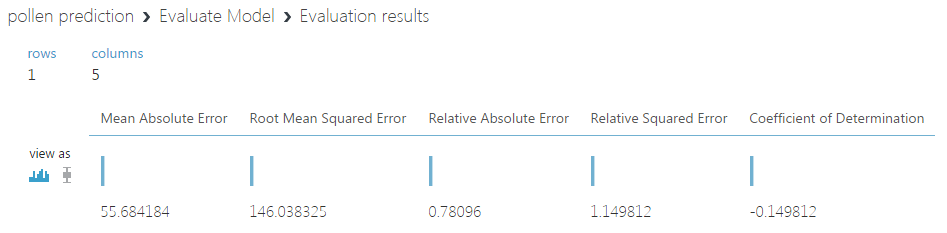
わかりやすいRoot Mean Squared Errorが146というのはあまりよくないニュースです。異常値をはじいた後の花粉飛散量の標準偏差は137.4186であり、Root Mean Squared Errorがこれよりも大きくなってしまっています。
これは予測した値が元々のデータ以上にばらついている、つまり全然あてにならないということを意味しているのでこのモデルによる予測値はほぼ信用ならないことを意味します。
Score ModelでVisualizeをしてみると、よりその傾向が顕著にわかります。下図は、予測した値であるScored Labelsと実際の値である花粉飛散量(pollen)をプロットしたものです。精度が高ければこの2つは完全な相関関係にあるはずなので、左から上に向かってきれいな線が出ていればうまく予測できていることになります・・・が、実際は。
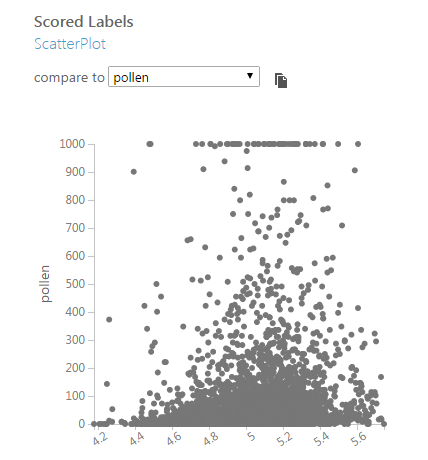
この予測は当初簡単かなと思ったんですが(気温が高ければ増えて雨が降れば減る・・・みたいな)、実際そうではありませんでした。
この後もチューニングを試みたんですが思うように精度が上がらなかったので、いったんここは棚に上げそこそこのモデルができたとし、この予測モデルをWebサービスとして使う準備に取り掛かります。
6. Webサービス化
Webサービス化ですが、以下の2種類があります。
- 学習用API:学習データを受け取り、モデルをトレーニングする
- 予測用API:予測用のデータを受け取り、予測値を返す
学習は今作っていた流れそのものなので、下のボタンの「Publish Web Service」を押すことでAPI化することができます。元のデータ以外にWeb APIからの受け取り口と、レスポンスのための出口を用意します。何れもボタンを押すと自動的に追加されます。
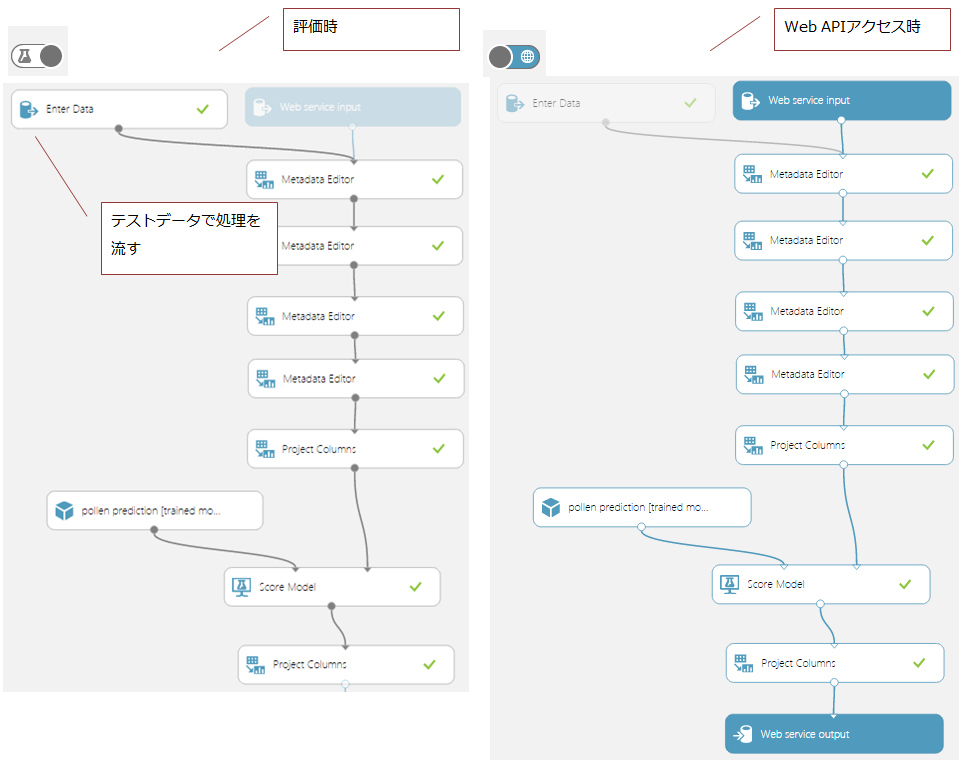
実は通常時とWeb APIアクセス時でフローを切り替えることができ、左下の方にあるボタンでどちらの時のフローを構築するのか切り替えることができます。
↓普段は(今までは)左の状態になっていたと思いますが、これを切り替えると右のWeb APIアクセス時にスイッチします

予測用APIを作成するには、以下のボタンを押します。

これを押すと、学習済みのモデルが組み込まれた予測用のフローがうねうね動いて作成されます。基本的には学習時のフローがコピーされますが、予測時には不要なものもあるのでそうしたプロセスを削除しながら予測時のフローを作成します。
今回は、以下のようなフローを作成しました。項目定義の部分は学習時のフローを踏襲していて、通常時は手で入力したデータを流してテスト(Data Input and Output > Enter Dataを利用)、Web APIアクセス時はPOSTされたデータを受け取り予測値を返します。
このフローを構築してRUNで動作を確認後、学習用APIと同様「Publish Web Service」でWeb Serviceを公開します。
Web APIのページからはアクセスURLやAPI Keyの確認ができます。
ここでAPIのテストができるほか、C#/Python/Rのサンプルコードまで載せてくれています。これを利用することで、学習/予測をWeb API経由で行えるようになります。
実装
今回は最初に決めたとおり天気予報をAPIから取得し、それを入力値として花粉飛散量を予測、これらの結果を合わせて表示させてみました。
pollen_prediction_by_azure/application.py
HTTPリクエストの形式は結構面倒なフォーマットですが、いずれにせよこれでWeb API経由で予測モデルを利用することができるようになりました。
Azure Machine Learningを利用することで手軽にモデルを構築できるほか、Web API経由で様々なプラットフォームから学習・予測をさせることができるようになります。
インストールの手間などもなくすぐに使うことができるので、勉強用・初めての機械学習アプリケーション開発用には良いプラットフォームではないかと思います。