概要
RNNとCNN(とBackward RNN)を組み合わせることで、精度の高い応答文生成(=Natural Language Generation、以下NLG)を行った研究
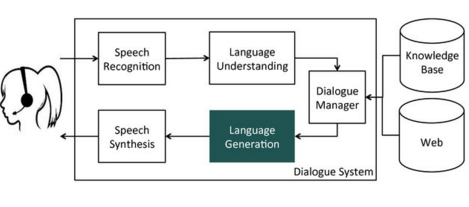
NLGは、対話において以下のパートを担う。Dialog Managerからの指示に基づき、応答文を生成する。
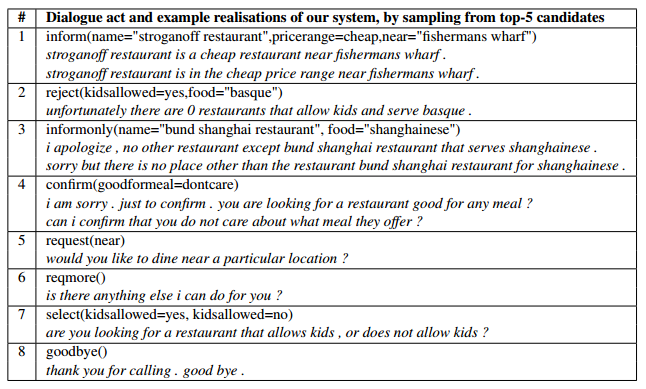
「Dialog Managerからの指示」は、一般的にact typeとattribute(slot)-valueのペアで表される。以下の#1の場合、「inform」がact type、そしてname="stroganoff restaurant"やpricerange=cheapなどがattribute(slot)-value pairとなる。これを自然な文書(stroganoff restaurant is a cheap restaurant near...)にするのがNLGの役割である。
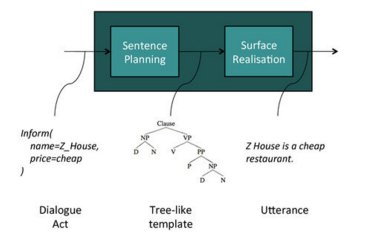
NLGは、大きく分けてSentence PlanningとSurface Realizationの2つのパートがある。Sentence Plannningは指示を文書の構成に落とし込む処理で、Surface Realizationでこれを実際の文書にする。
これらの処理は、以下の問題を抱えている。
- 人手でルールを作ると複雑なうえに、あまり多くのパターン(言い回し)を生成できない
- 確率モデルでやろうとすると、語の意味など細かいアノテーションを行ったデータが多く必要
今回の研究では、RNNを使うことで複雑なルールをデータから学習させると共に、CNNによるバリデーション(+逆方向から構築したBackward RNNでもチェック)を行うことで少ないデータでも精度の高い文章を生成できるようにした。
アーキテクチャ
全体図は以下の通り。RNNで文を生成、その結果をCNN・Backward RNN、また文内の構成を評価するERRを加味して評価して、ランキングを行う。
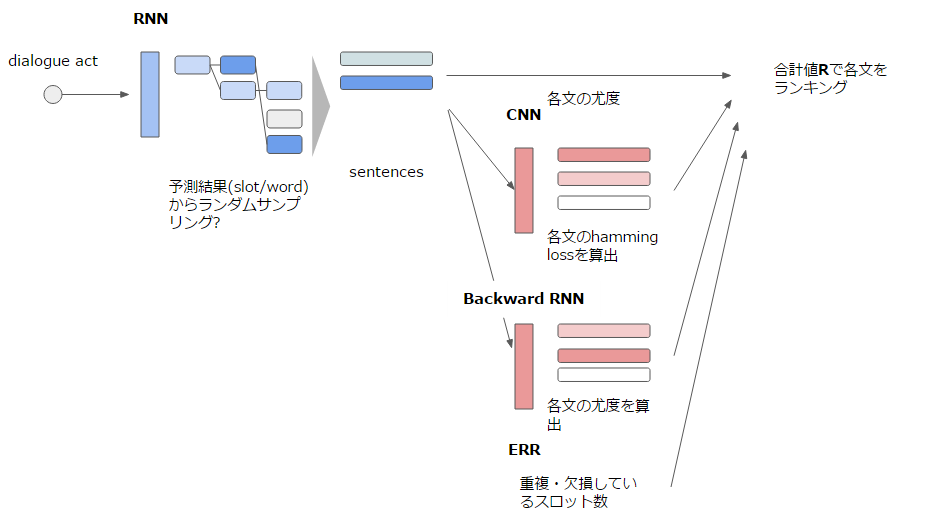
RNN: Recurrent Generation Model
RNNの構造は以下のようになっており、2つの入力を取る。
- Dialogの指示をベクトル化したもの(act type、slotの種別と値の有無、それぞれを0/1のベクトルで表現し結合したもの※)
- 文の単語をslotに置き換えたもの(delixicalisation)
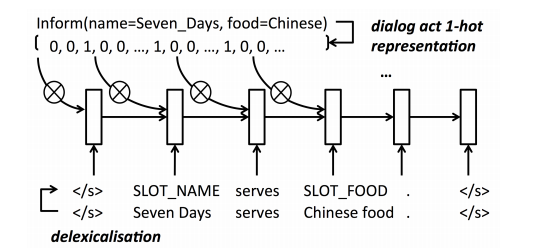
※性質の違う0/1のベクトルを結合しちゃっていいのかという気はするが。。。
前者(Dialogの指示)は途中で変わらないので、biasのような固定値になる。ただし、Gate(図中の×○マーク)を通過させることで値の調整を行っている。このGateは以下ような効果を狙ったものである。
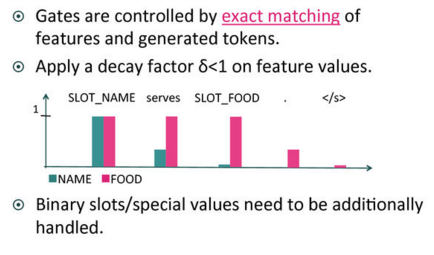
SLOT_NAMEがDialogの指示に含まれており、実際にそれが予測された場合δ<1により次回以降の出現確率が抑制される。これにより、いったん出現したslotが再度発生しないよう調整している。
しかし、このRNNだけだと以下の問題がある。
- delixicalizationに失敗するケース(food=dont_careなど、後者の単語から前者が推測不可能なもの)に対応できない
- 前の単語からしか予測ができない(単純な例としては、後ろの単語がumbrellaならanにしないといけない、など単語は前以外の周辺の単語にも影響を受ける)
要は、考慮できる単語を前のものだけから周辺に拡張しないと対応できないということである。そこで登場するのがCNNとなる。
CNN: Convolutional Sentence Model
下図はSentenceの特定長を切り出して(※)、それをK個のレイヤにオーバーラッピングするようマッピングすることで、畳み込みを行っている。
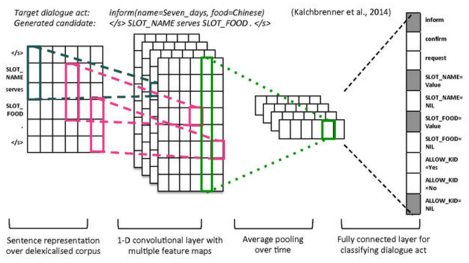
※画像のように固定長でないため、どこまで畳み込めるかは文の長さによってかなり異なる。これで意味があるのかという点はかなり疑問。要原論文チェックA Convolutional Neural Network for Modelling Sentences
これにより、act type、各slotの出現確率を予測している。
Backward RNN reranking
文章系だとBidirectionalをやると精度が上がるが、今回のモデルでBidirectionalをやるのは至難の業なので、Backwardで学習させたRNNを別途用意してその結果を加味することにする。
学習
- RNN: 予測単語の分散表現と実際の単語のそれとを比較、目的関数はcross entropy
- CNN: 予測dialog actと実際dialog actを比較(act typeごとにslot値を合計?)、目的関数はcross entropy。学習中、10trainingごとにL2正規化項を付与(という手法があるらしいMikolov 2011bを参照)
学習方法はSGD、RNNは当然BPTT。
Bidirectionalを加えた3つのネットワークは、事前学習済みのword-embeddingを共有する(※どこで使ってるのか謎。slot以外の単語表現?)。
セットアップ
今回のモデルは、サンフランシスコのレストランを紹介するものとしている。
-
8 act types: inform, confirm, rejectなど
-
12 attributes(slots): name, count, foodなど
-
3577対話を収集(恐らくdialog actベースのデータ)
-
ここからランダムにサンプリングし、Amazon Mechanical Turk(クラウドソーシングのサービス)にDialog actに沿う自然な英語を入力してもらった
-
結果1006のサンプル対話から5193の発話が収集できた(action type(=語彙?)数では228->delixicalizationに使用するための語彙辞書と思われる)
-
Theanoで実装
-
データの割り振りは、トレーニング:バリデーション:テスト=3:1:1
-
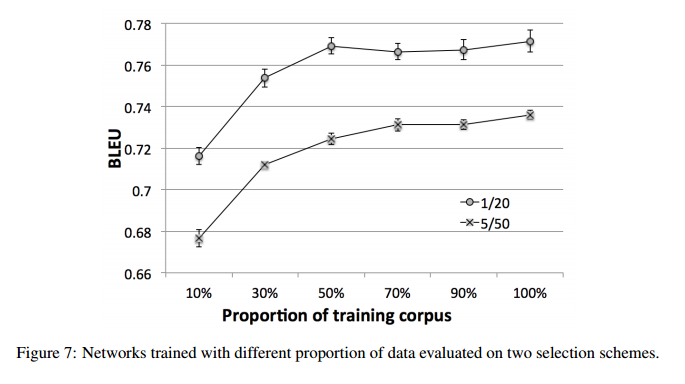
結果は初期値によってかなり異なるので、結果には10の別々に初期化したネットワークの平均を用いた
結果
精度は上がった。また、人間による主観的な評価でも既存指標より有意に良い結果が得られた。
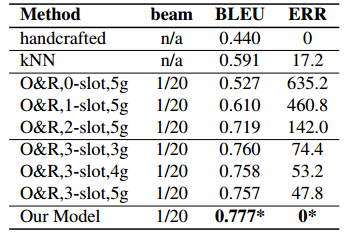
今回導入したCNN、Backward RNNの効果についても検証した。
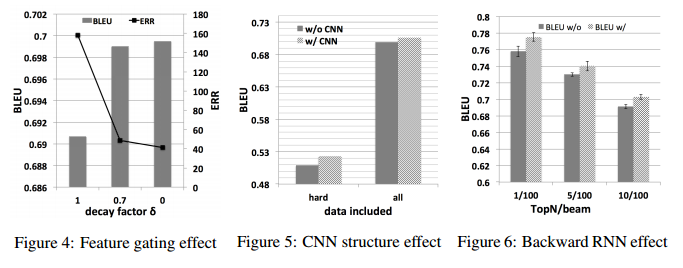
特にGateとCNNの結果は顕著。Gateはδ=0(一回登場したら二度と出現させない)が最も良かった。
また、トレーニングデータの数についても検証を行った。一つの最良の回答(1-best utterance)を常に返す(=バリエーションなし?)で良いなら、今回使用した半分の2000程度のデータで十分に効果が得られそうだった。top-5からある程度バリエーションを持たせて回答する場合は、70%程度(4156)は必要そうである。