機械学習も含めた、データの活用は現場主体のほうが上手くいくという実感があります。大体、トップダウンで行うようなものは以下のような感じになるためです。
そうすると・・・
- じんこうちのうコンサルタント(自称)があらわれた!
- 「機械学習を使うには、業務の分析が欠かせません。ひいては、まずコンサルティング契約(x百万)を結んでいただきそのあとに・・・」
- じんこうちのうサービス(自称)があらわれた!
- 「弊社のサービスを使えば簡単ですよ!噂のディープラーニングで高精度な画像認識、音声認識を約束します!え、データは画像でも音声でもない?大丈夫です!なんといっても汎用ですから!」
- アイ・オー・ティー・ロボットがあらわれた!
- 「モクヒョウにセンサーをつけてブンセキ・・・モクヒョウにセンサーをつけてブンセキ・・・モクヒョウにセンサーをつけてブンセキ・・・」
しかも・・・
- しゃちょうは、じんこうちのうにあやつられている!
- 「じんこうちのうといったら、○トソンだろう。まず○トソン使わないと」
- しすてむだいじんは、たいわぼっとにあやつられている!
- 「これからは、なんにでも話しかけられるようになるんですよ。検索ボックスなんて論外です」
- しすてむけんきゅういんは、でぃーぷらーにんぐにあやつられている!
- 「ディープラーニングじゃない?それは人工知能じゃないですし、機械学習でもありませんよ(笑)」
はい。
本記事は、機械学習について現場主体の活用を実践するための一つのアイデア+実装になります。
具体的には、以下3点を重視しています。
- 簡単に組み込める
- 簡単に使える
- 何度もやり直せる
つまり、日頃使用している業務システムに簡単に組み込むことができ、しかも操作が簡単で、間違えても何回もやり直せる、ということです。今回は業務システムとしてkintoneを利用し、そこに組み込む形で実装を行いました。その仕組みと機能について、以下で解説していこうと思います。
なお、本記事はCybozu Days 2016 kintone hackでの発表内容が元になっています。プレゼンの最中では触れることができなかった、技術的な点についても本記事では触れていこうと思います。
利用イメージ: 1クリックでデータ予測
以下は、物件管理のkintoneアプリケーションになります。ここには、物件の名前や各種特徴(駅からの徒歩時間や築年数など・・・)が入力されています。
「これくらいの物件の家賃はどれくらいなんだろう?」と思ったら、「予測する」のボタンを押します。そうすると、学習した結果を基に家賃の予測値を入れてくれます。

活用に必要なのは、このボタンを押すだけです。これを実現する仕組みを、今回karuraと名付けて開発しました。karuraで予測の機能を使うために必要なのは、3ステップのみです。もちろん、このステップにじんこうちのうコンサルタントはひつようありません。
利用方法: 3ステップでデータ活用
上記の、ワンクリックでのデータ予測をするために必要なのは、全3ステップです。
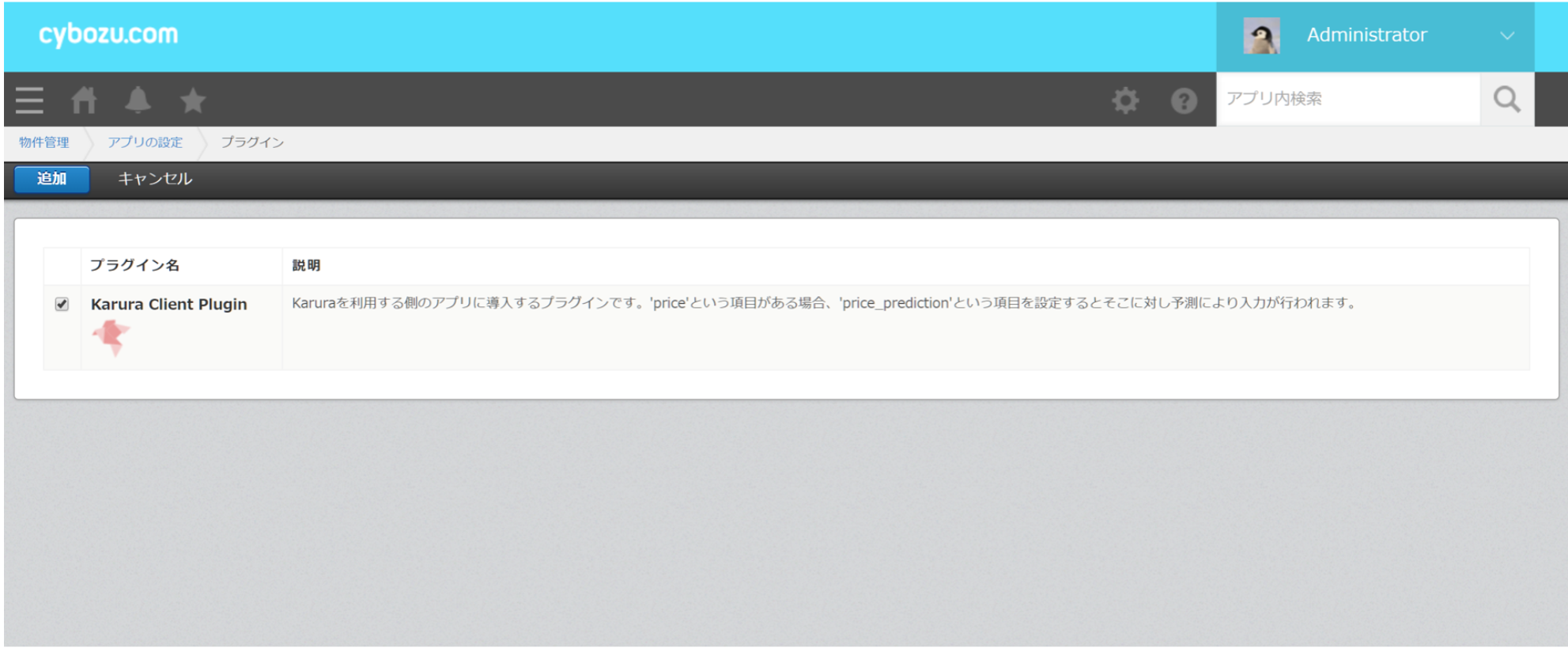
kintoneにプラグインを入れる
予測機能を利用したいアプリに、プラグインを入れます。
予測値を入れるフィールドを用意する
予測値を入れるフィールドを用意しておきます。これを別途用意するのは、人の入力した値と予測値の比較を行ったりすることもあると想定しているためです。
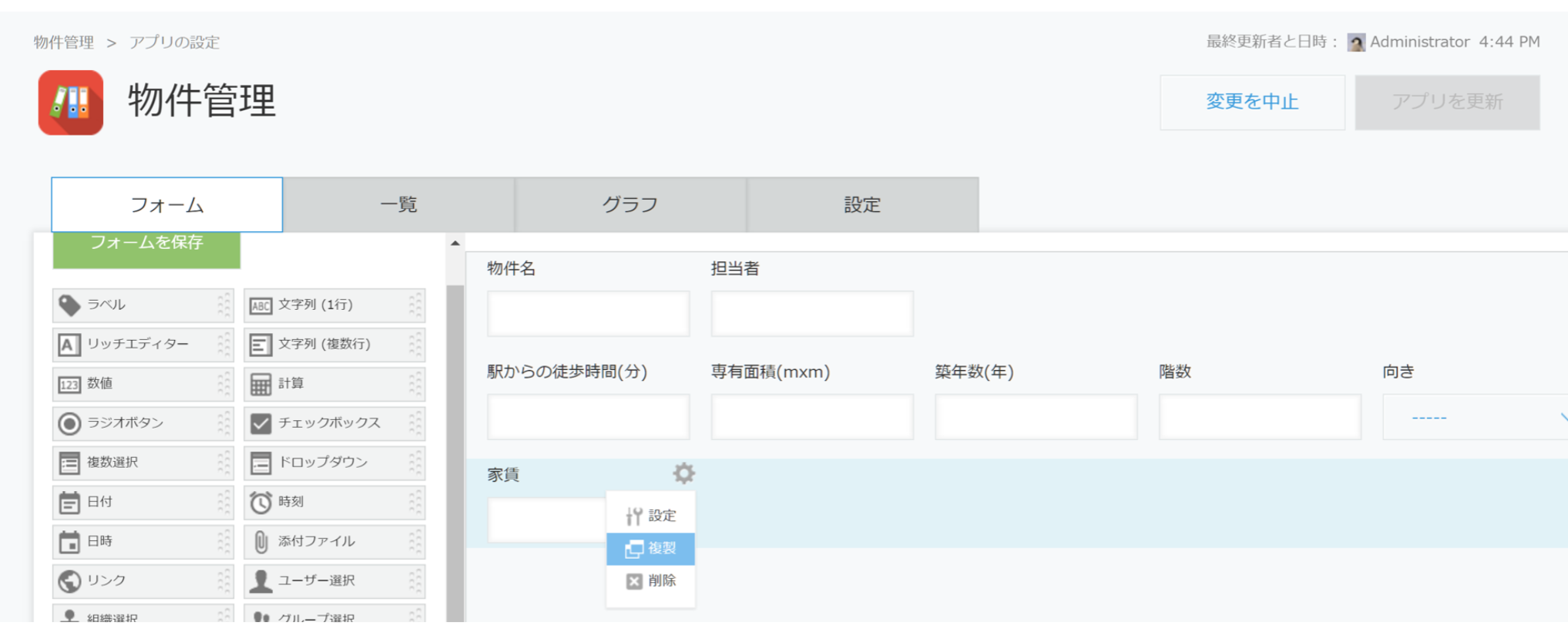
なお、予測値を入れるフィールドは「_prediction」で終わるフィールド名を付けます。
学習させる
ここからは、学習をするためのアプリ(karura)側で作業を行います。先ほどの、予測機能を入れたい物件管理アプリの番号を入れて、アプリ情報を読み込みます。そして、「予測に使うフィールド」と「予測したいフィールド」を設定します。
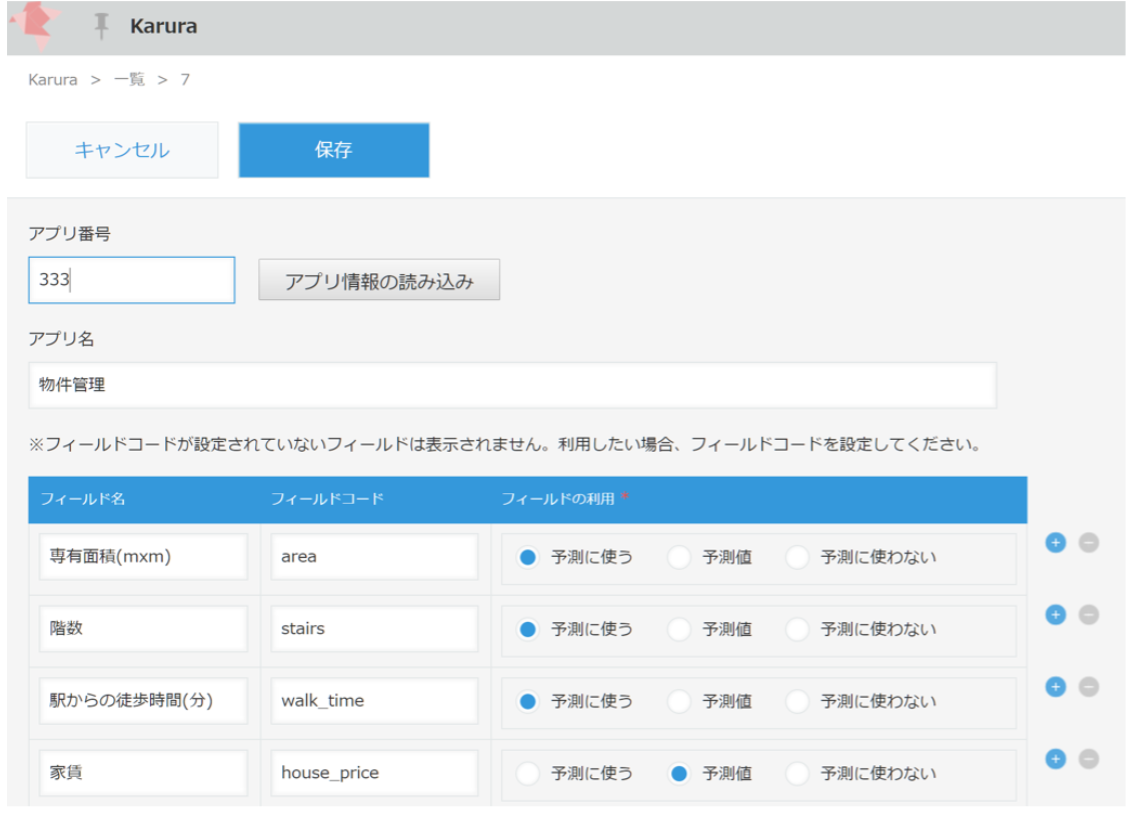
これを設定したら、学習ボタンを押します。
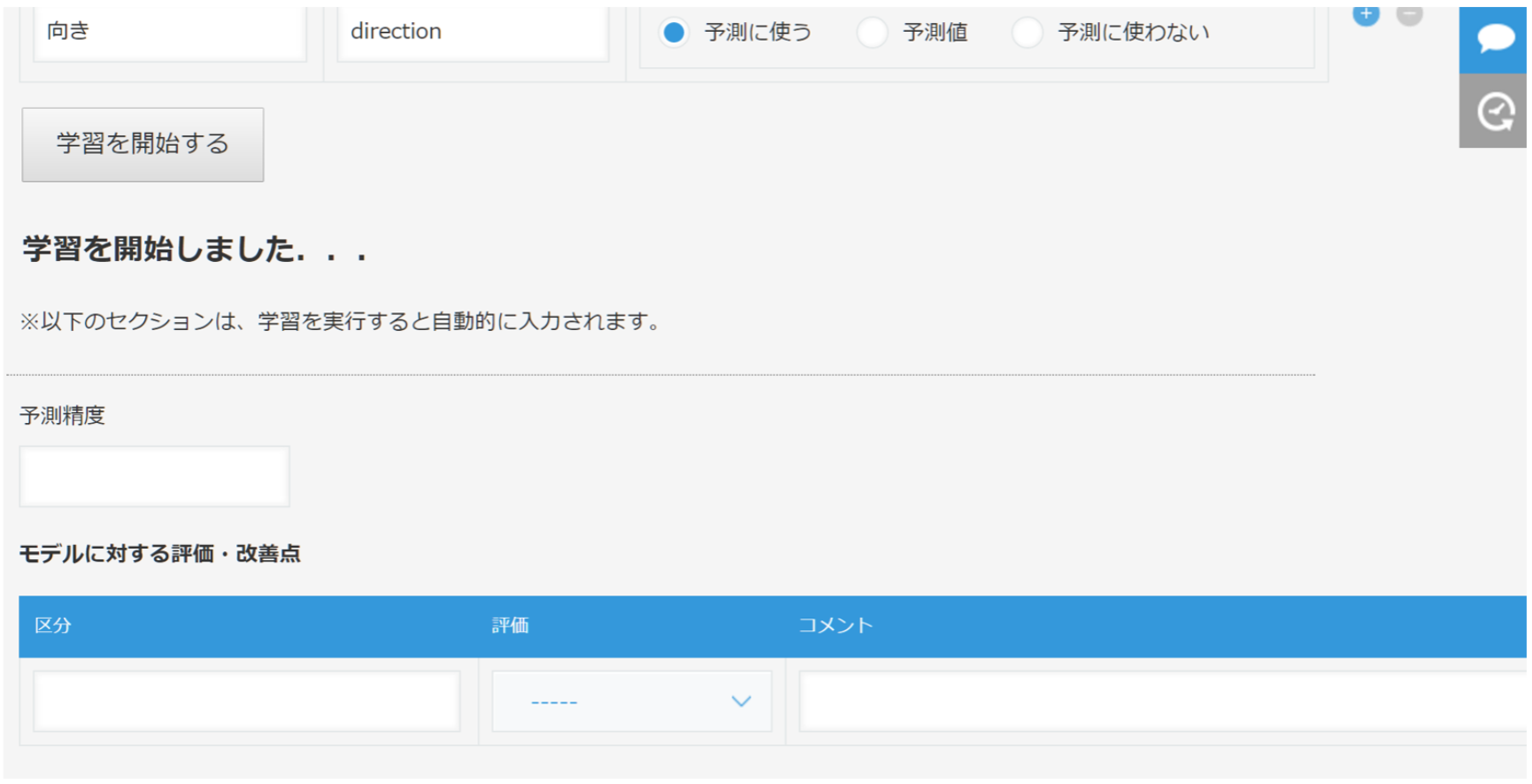
学習が完了すると、以下のように予測精度と、モデル改善のためのアドバイスが表示されます。
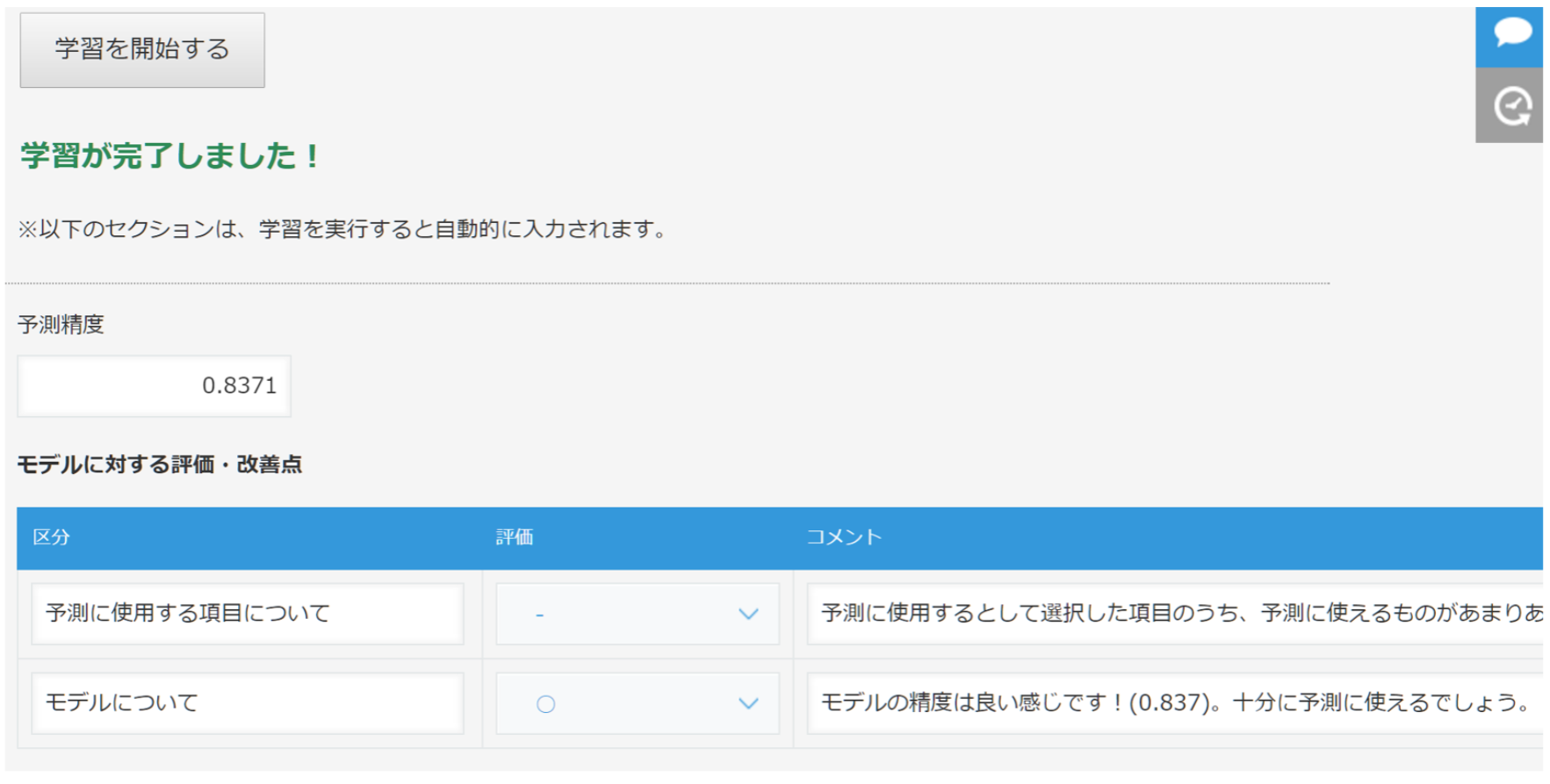
これで準備は終了です。アプリケーション側で、予測機能が使えるようになりました。このデモは割と単純な値予測ですが、クラス分類や非線形の予測にも対応しています。そして、利用者側は値の予測なのかクラス分類かどうかを支持する必要はありません。それは自動的に判断して内部でモデルを切り替えています。
実現のための仕組み: 全自動機械学習
この仕組み、karuraは、機械学習で面倒なところを全部カットしています。
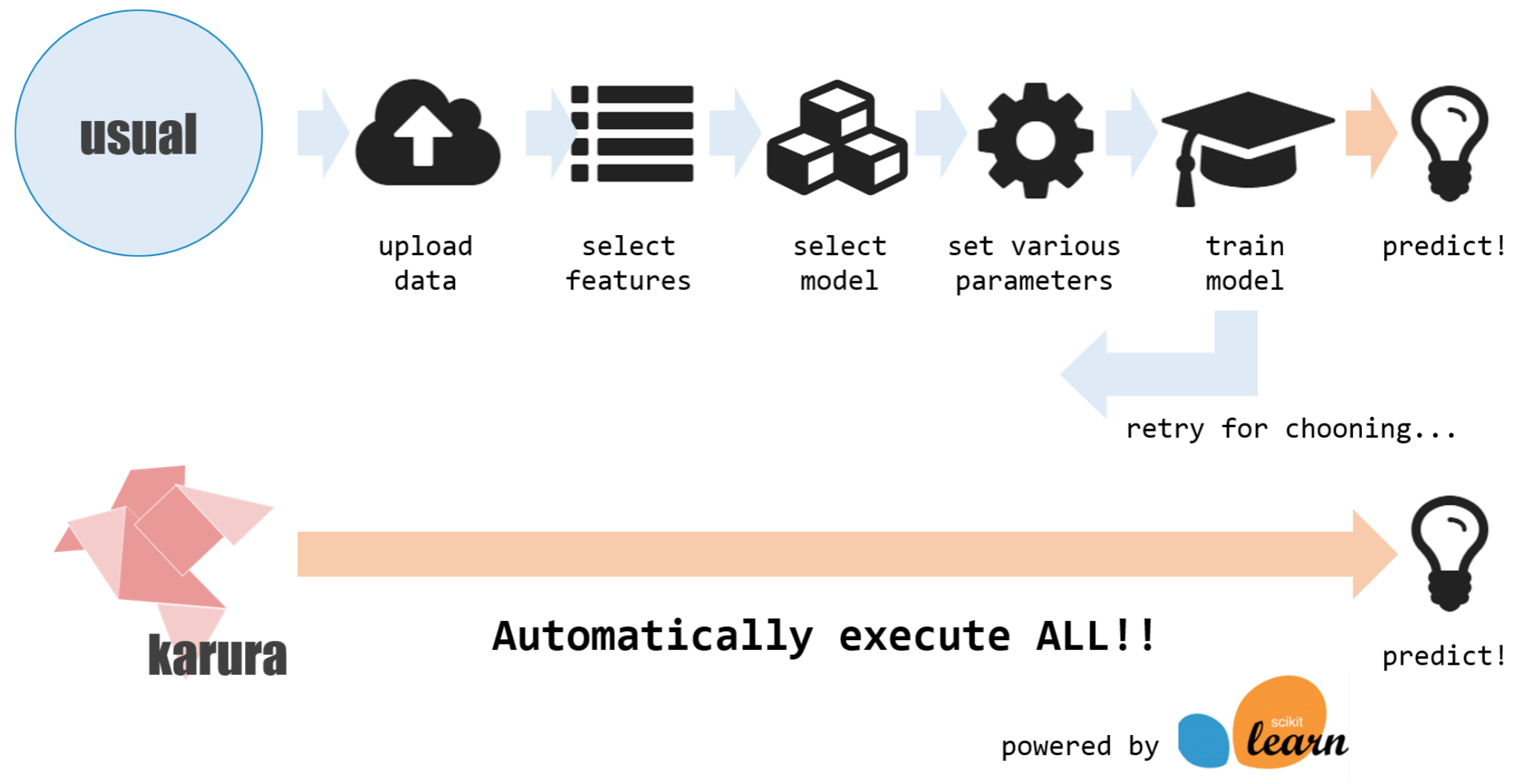
上図にある通り、以下のような点を自動的に行います。
- データの抽出
- 特徴量の選択
- モデルの選択
- モデルのパラメーターチューニング
「自動的に」というと何かものすごいことをやっているようですが、これらはすべて普通にできることを普通にやっているだけです。具体的には、以下のような感じです。
- データの抽出: kintone APIを使って対象のアプリからデータを抽出
- 特徴量の選択: scikit-learnのFeature Selection
- モデルの選択: scikit-learnが公表しているモデル選択のマップをベースに選択
- モデルのパラメーターチューニング: scikit-learnのGridSearchCVでチューニング
少し工夫しているのは、特徴量の定義の箇所です。具体的には、以下の操作を内部的に行っています。
- 量的変数/カテゴリ変数の判断
- 特徴量ごとの正則化と、そのパラメーターの保存
以下では、上記も含めた自動化のためのポイントについて解説をしていきたいと思います。
量的変数/カテゴリ変数の判断
特徴量、つまりkintone上のアプリの項目には、数値が入るものもあれば、曜日のように区分が入るものもあります。
区分がはいるもの(曜日なら月・火・水・・・)は、単純に数値に変換して扱ってしまうのは適切ではありません。例えば、0=月曜、1=火曜、2=水曜、としたとき、火曜日の二倍が水曜なのか?火曜日+火曜日=水曜日なのか?というと意味をなしません。そのため、各値は独立に扱ってやる必要があります。
こうした区分を表す変数はカテゴリ変数と呼ばれ、特徴量とする際はそれぞれの値を項目として捉えます(月曜=True/False、火曜=True/False・・・という感じで、値ごとに項目とする)。逆に、普通に数値として扱って問題ないもの(温度や金額など)を量的変数と呼びます。
これをユーザー側に考えさせるのは負担になるので、今回はフィールド項目の種別で量的変数/カテゴリ変数を推定しています。具体的には、ドロップダウンリストやラジオボタンの項目であればカテゴリ変数とみなす、といった具合です。これはkintoneのフォーム設計上の方APIを利用すればわかるので、ユーザーはあえて指定する必要はありません。
これと同様に、予測したい値として指定したフィールドがカテゴリ変数か量的変数かで、分類問題なのか値予測問題なのかを識別しています。
ただ、現在自然言語が入るようなフィールドには対応できていません(具体的には、コメントやタイトルといったテキストが入るフィールド)。こうしたフィールドも、自動的に分散表現などを用いて特徴量化できれば良いなと考えています。
特徴量ごとの正規化と、そのパラメーターの保存
データは正規化してやる必要がある、というのは常識ですが、その正規化と正規化のためのパラメーター(平均・分散)の保存を実行しています。正規化のためのパラメーターを保存しておくのは、予測をする際も正規化が必要なためです。
特徴量の選択
特徴量の選択には、scikit-learnのFeatureSelectionを用いています。使い方としては以下のような感じです。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
X, y = iris.data, iris.target
X_new = SelectKBest(chi2, k=2).fit_transform(X, y) # choose best 2 feature
print(X_new.shape)
これは、端的には各特徴量単独で分類/予測を行ってみてどれだけ精度が出るかを計測し、それをもって各特徴量の貢献度を見るというものです。これで不要な特徴量を削除して、簡素なモデルにしています。それと共に、内部的には「どの項目がどれくらい効いているか」を保持していて、ユーザーへのアドバイスに利用できるようにしています。
ただ、特徴量の最大個数と足切をする特徴量の閾値は今適当に設定をしているので(一応kintoneのアプリの項目数的にこれくらいかなという値にはしている)、そこのところの調整は今後の課題です。
モデルの選択/パラメーターチューニング
モデルの選択とパラメーターチューニングには、scikit-learnのGridSearchCVを用いています。使い方としては、以下のような感じです。
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
candidates = [{'kernel': ['rbf'], 'gamma': [1e-3, 1e-4], 'C': [1, 10, 100]},
{'kernel': ['linear'], 'C': [1, 10, 100]}]
clf = GridSearchCV(SVC(C=1), candidates, cv=5, scoring="f1")
clf.fit(digits.data, digits.target)
print(clf.best_estimator_)
for params, mean_score, scores in clf.grid_scores_:
print("%0.3f (+/-%0.03f) for %r" % (mean_score, scores.std() / 2, params))
こちらは、モデル(estimator)とそのパラメーターのレンジを渡すと、そのレンジの範囲(の組み合わせ)を全探索してくれる、というものです(超便利)。これで、簡単に最も精度の高いパラメーターの組み合わせを得ることができます。これを候補となるモデルごとで行い、最終的には最も精度の高いモデルとそのパラメーターを保存します。
この候補となるモデルは、scikit-learnの提供しているモデル選択のmapを参考にしています。といってもあまり複雑なことはしていなくて、値予測ならElasticNetとSVR、クラス分類ならSVMをカーネルを変えながら試す、という感じです。
karuraではこうして全自動機械学習を実現していますが、これまでの点に何も高度な技術はありません。全て既存のノウハウと機能を積み重ねたものです。ここにディープラーニング的な要素は一切ありません。鉄板と呼べる作業を粛々と行うという体で実装しました。しかし、それだけでいわゆる「データ予測」の大半をカバーできると考えています。
最近のいわゆる人工知能界隈は、とんでもない工夫を凝らした超絶ラーメン(高価)を競っているような趣があります。そうではなく、町のラーメン屋のような「そうそう、これでいいんだよ」という機能をしっかり提供していくのもまた重要ではないかと思います。
karuraの実装はGitHubで公開しており、kintoneがあれば試しに使ってみることが可能です(個別に使う場合はプラグインやJavaScriptカスタマイズの中身を書き換える必要があり、そこは今後直していく予定です)。興味がある方は、ぜひ試してみてください。
