「チコちゃんに叱られる!」はNHKの番組です。チコちゃんの素朴な疑問に答えられないと「ボーっと生きてんじゃねーよ!」と叱られるという番組です。ちなみにこの記事を書いている12月末ではさだまさし先生がゲストで登場しました(さだまさしアドヴェントカレンダーを懐かしく思い出します)。
この番組の中で「チコの部屋」というしりとりゲームをするコーナーがあります。チコちゃんは5才とは思えない語彙力でゲストを圧倒するのですが、これを見ていた私は大人げなくチコちゃんにどうにか勝ちたいと思いました。
 出典: [NHK 「チコちゃんに叱られる!」より](https://www4.nhk.or.jp/chikochan/)
出典: [NHK 「チコちゃんに叱られる!」より](https://www4.nhk.or.jp/chikochan/)
そして生まれたのが、体はNuxt x Firebase、頭脳はPython x 自然言語処理で構成されたその名もチカちゃんです(イラストはまだない)。全体の構成とデータの流れは以下のような感じになっています。
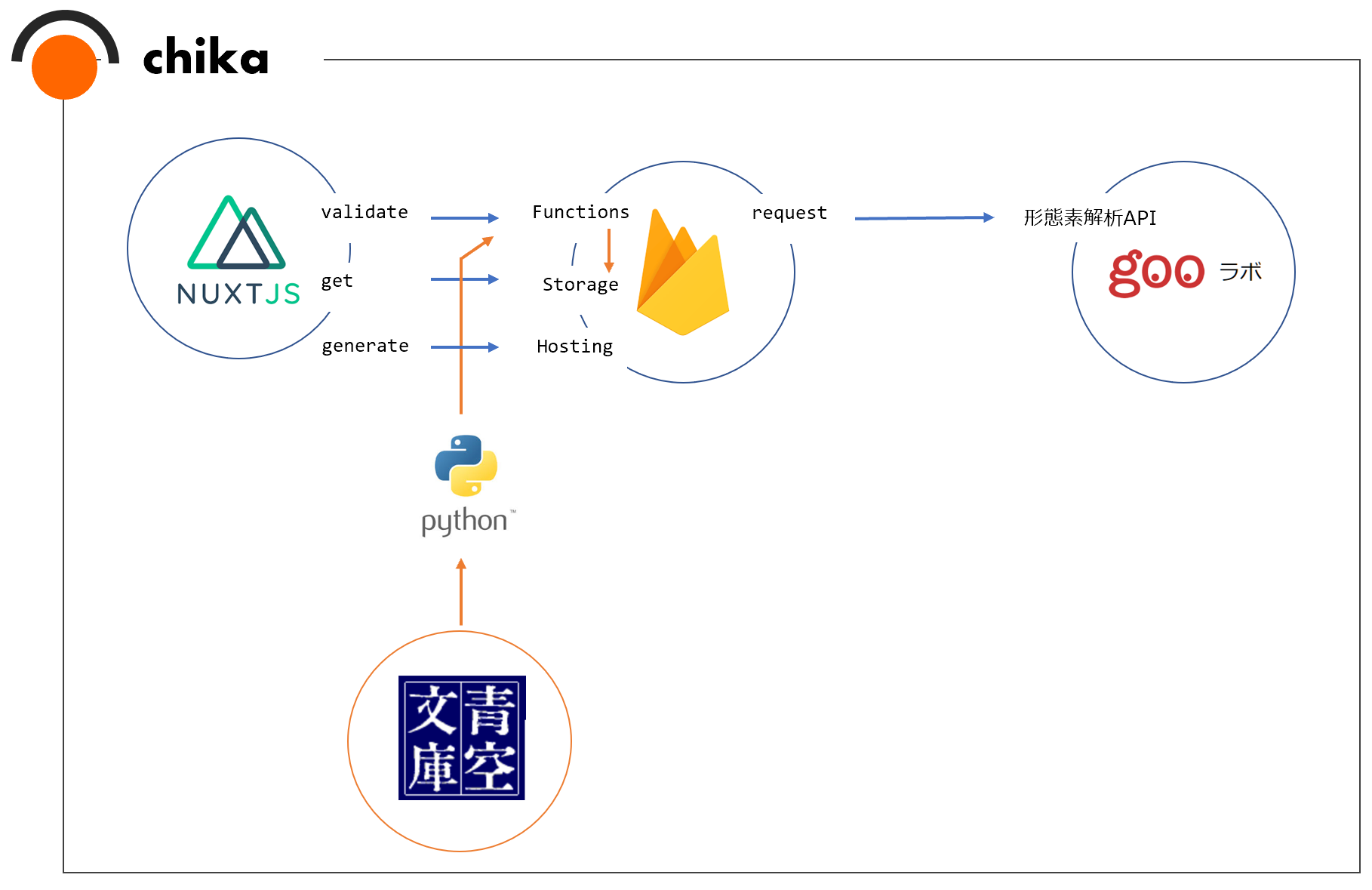
実装はこちらです。
icoxfog417/chika: Japanese Shiritori Master Chika
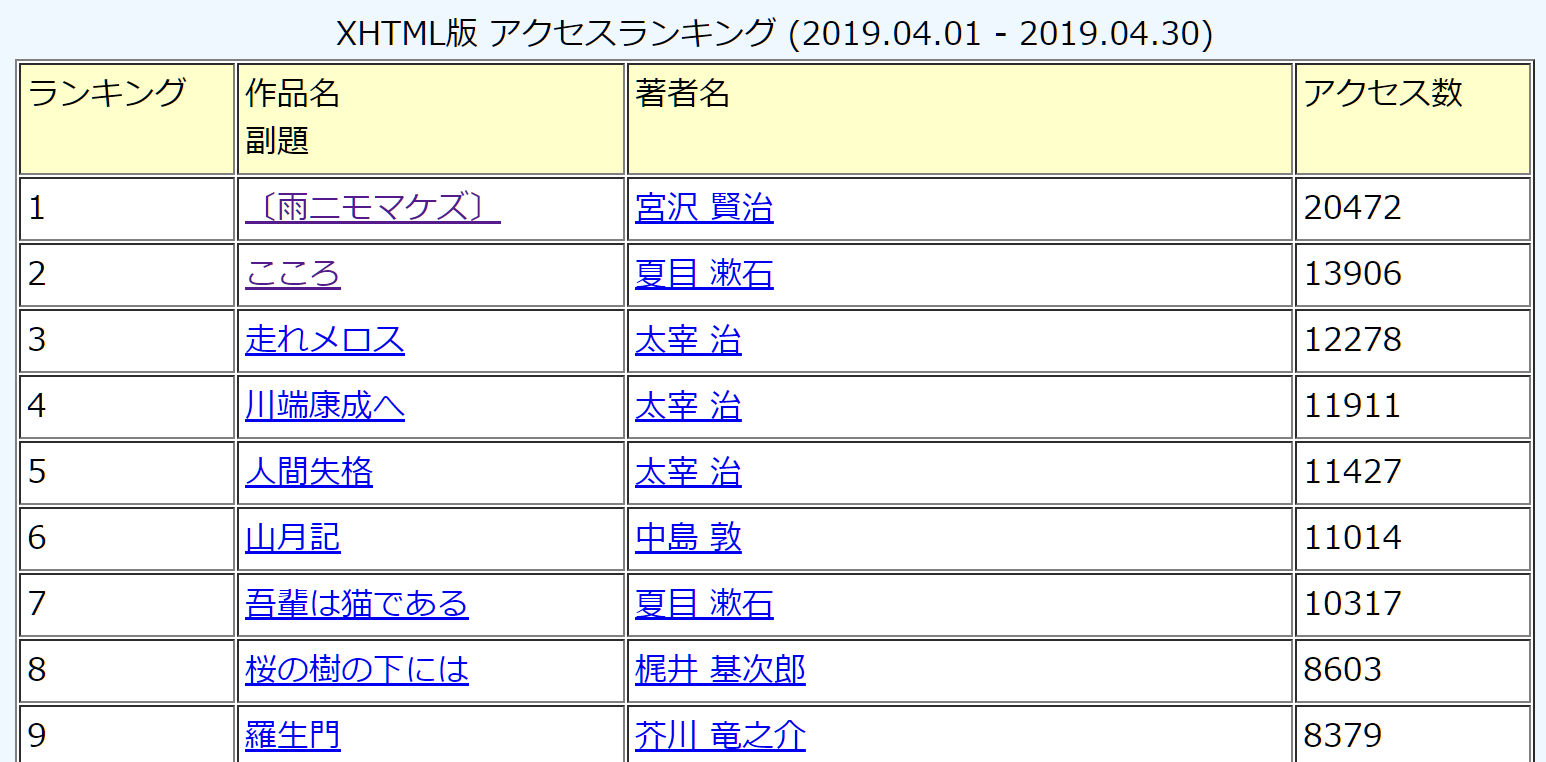
チカちゃんの開発では、チコちゃんに負けない教養を身に着けることを意識しました。そのため、単純な辞書系のデータ(Wikipediaなど)ではなく、文学作品から語彙を取得しています。具体的には青空文庫の2019年4月のアクセスランキングトップ500から語彙を取得しています。
実際のアプリケーションの画面は以下になります(↓の画像をクリックするとアプリケーションに飛びます)。

実際の作品にふれられるよう、単語が使われている文と作品へのリンクを付与しています(そして縦書きです)。一部未実装なしりとりのルールはありますが、そこそこ遊べると思います。これでチコちゃんに負けない頭脳を目指す!
チカちゃんのここがすごい!
しりとりをしつつ日本の古典に触れることで語彙と教養が同時に身に着く!
チカちゃんのここがすごくない!
大人げない!
ここから先は、使用した技術についてポイントを解説を行っていこうと思います。
- Firebase
- Nuxt
- Pythonによる自然言語処理
Firebase
近年のアプリケーション開発では、フロントエンドとバックエンドをAPIで連携させることが多いです。これにより、フロントエンドは表示機能、バックエンドはデータ処理に集中できます。いわゆるマイクロサービスの構成です。
Firebaseは、「バックエンド」の実装を楽にしてくれるサービスです。Firebaseを使用することで、開発する側は「フロントエンド」に集中できるだけでなく様々なフロントエンド媒体(モバイル、Web、ゲームなど)でバックエンド処理を使いまわすことができます、
以下は、Firebaseの設定画面です。「バックエンド」に必要な機能がすべてそろっていることがわかると思います。

- Authentication: 認証
- Database: データの保存/読み取り
- Storage: 静的データの保存/配信
- Hosting: アプリケーションのホスティング
- Functions: ビジネスロジック/定期処理の実装
- 実体はCloud Functionなので、GCP側でも実装可能
- ML Kitを使用することで、機械学習機能も使用できる(画像認識など)
実装だけでなく、テスト・アクセス分析などアプリケーションの改善サイクルを回すための機能も提供されています。アプリケーション開発者の強い味方と言えるでしょう。料金も、無料のSpark/無償枠のある従量課金のBlazeが用意されており、ちょっとしたアプリケーションなら無料枠の範囲で作成可能です(ただし油断はしない方がいいので、アラートは設定しておくのが吉)。
Firebaseは以下から使い始めることが可能です。
Firebaseの設定/使い方については既にわかりやすいチュートリアルがたくさんあります。以下の記事がわかりやすかったです。
前述の通り、今回はフロントエンドにNuxtを使用しているのでそれを前提とした記事になっています。1点注意があり、Nuxtのホスティングには2つ方法があります。
- SPA:
nuxt generateでコンテンツを生成し、それをHostingする - SSR: フロントエンドをHostingするだけでなく、SSRをCloud Functionで稼働させる
Nuxtはサーバーサイドレンダリング(SSR)の機能があります。これは、サーバー側で事前にレンダリングを行いフロントエンドに配信する機能です。「サーバー側で」と述べた通り、SSRの機能はいわゆる「バックエンド」側の処理になります。そのため"Hosting"ではなく"Functions"として実装する必要があります。
つまり、"2"の方法では「フロントエンド」としてのNuxtと「バックエンド」(SSR)としてのNuxt 2つをデプロイする必要があるということです。
"2"の実装方法は以下で解説されています。フロントエンド用はsrc、バックエンド用はfunctionsでフォルダを分けるのが通例のようです。
ただ、"2"の方法はあまりお勧めしません。あれ、どっちのNode/Nuxtで開発してるんだっけ?という混乱が生じて思わぬバグを踏む可能性があるためです(なおCloud Functionで使えるNode.jsのバージョンは限定されており、使用可能なバージョンを選択する必要があります)。SSRが必須でない限り、"1"でやる方が簡単だと思います。事前にサイトを生成してしまうので、動的なSSRが必要ない限り速度も速くなります。
Nuxt
NuxtはVue.jsをコアとして開発されたアプリケーションフレームワークです。Vue.jsはフロントエンドを実装するための「ライブラリ」なので、モジュール化の方法やそれに伴うフォルダ構成、また開発ツール(BABELとか)は開発者の選択にゆだねられています。これらはほっておくと無法地帯になりがちなので、それらについてのベストプラクティスを「フレームワーク」としてまとめたものがNuxtになります。
Nuxtの開発で必要な知識は、Vue.jsとVuexが中心になります。特に、Vuexの状態管理パターンは事前に読んでおく価値があります。以下は、Vuexの状態管理フローと、フローを実装するNuxtのフォルダを矢印で示した図です。
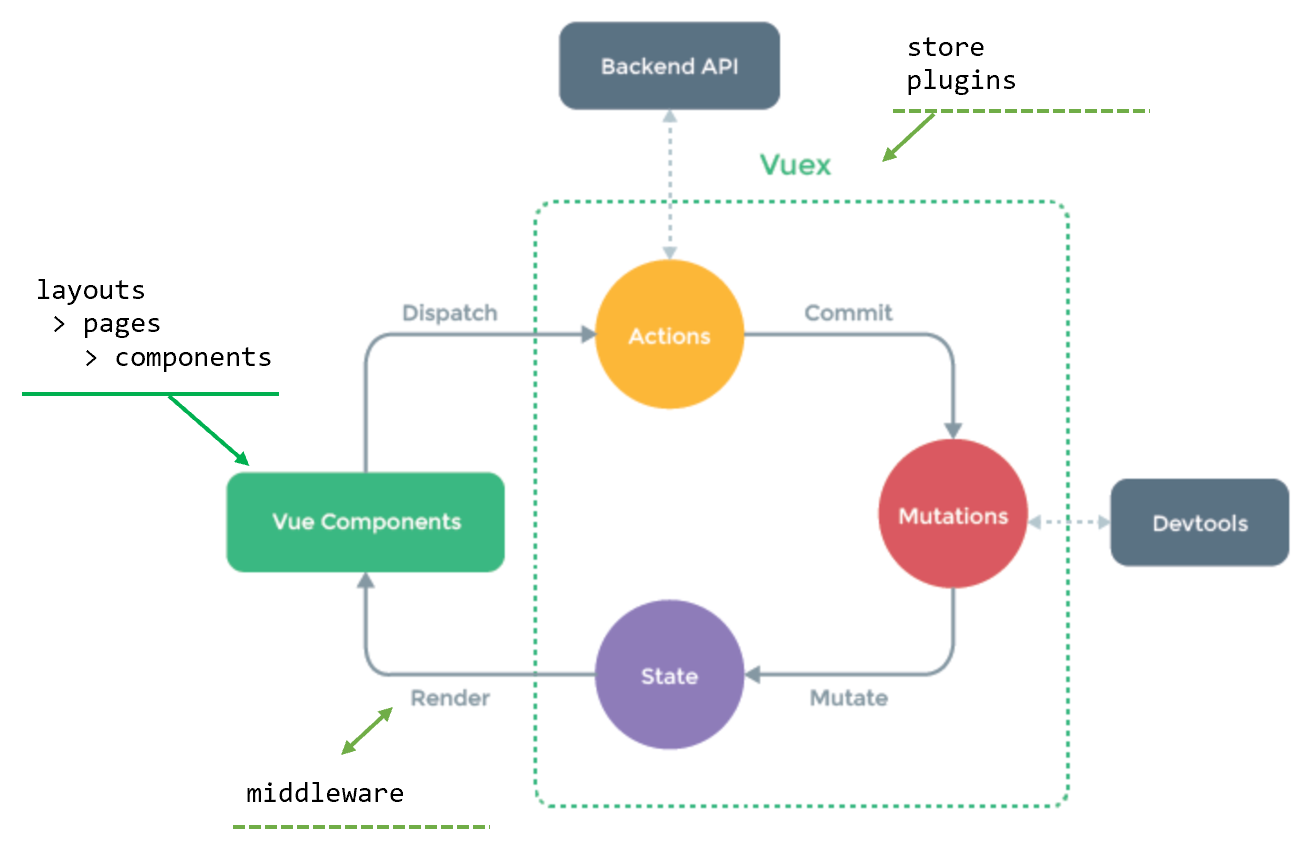
- Vue Component
- 表示(画面)を担当します。
- Nuxtのフォルダでは、
layoutsでページのテンプレート、pagesで各種ページ、componentsでページのパーツを定義します。
- Vuex(Actions/Mutations/State)
- アプリケーションの状態はすべて
Stateで管理します。Stateを更新できるのはMutationsだけです。 -
Mutationsは同期処理でないといけないというルールがあります。「同期的なMutations前後以外でStoreの値が変わることはない」という制約を課すことで、アプリケーションの状態変化を追いやすくする意図があります(多分)。この制約がないと、様々かつ非同期で実行され得るActionsを全部追跡しないといけなくなります。 - Componentからは
Actionを呼び出し(dispatch)、ActionsからはMutationsを呼び出します(commit)。 - 共通処理は
pluginsに切り出します。 -
middlewareはページ遷移時のフック処理を実装できる機能です。これにより権限によるページ遷移などを実装できます。
- アプリケーションの状態はすべて
Firebaseの開発では、様々なパッケージが提供されています。これらを使用して開発を行っていきます。
-
firebase- Firebaseの各種機能(データを保存する
firestoreや関数呼び出しのfunctionsなど)を呼び出すことができます。
- Firebaseの各種機能(データを保存する
-
firebase-admin-
firebaseとほぼ同じ機能ですが、Functions(サーバーサイド)で使用されることを想定しています。参考: Firebase Authentication vs Firebase Admin
-
-
firebase-tools- Firebaseへのデプロイなどを行うためのツールです。
Store/Plugin vs Functions
どこまでNuxtで実装して、どこからFunctionsで実装したほうがいいのか、というのは悩ましいポイントです。今回はビジネスロジックに相当する部分(しりとりチェックの一部)をFunctionsで実装しました。Functionsは異なるアプリケーション媒体から使えるので、媒体独自の処理・ローカルデータを用いた処理・レイテンシが問題になる処理など以外はFunctionsで実装したほうがいいのかもしれません。
今回は、汎用的なしりとりルールをFunctionsで実装しました。
- 意味のある単語か
- しりをとっているか(前回単語の末尾を送信)
- 「ん」がついていないか
しりとりでは単語の「読み」がわからないと話にならないので(「平等院鳳凰堂」の場合、先頭の文字は「ビ」で最後の文字は「ウ」)、読みの取得をgooの形態素解析APIで行いチェックしています。
逆に、ローカルデータを用いたルールの実装はクライアント側で行っています(=しりとりのやり取りを逐一サーバーには送っていません)。
- 既出の単語でないか
Functionsの開発は以下のチュートリアルがわかりやすいです。
- regionは、FirestoreのFunctionsは今のところus-central1のみのようです。。
- 外部への送信は請求登録なしでは無理のようです。 Error: getaddrinfo EAI_AGAIN
- アプリケーションから呼び出す場合は、デフォルトの
onRequestではなくonCallを使用する必要があります(そうでないと、恒例のCORSエラーが発生します)。
Get from Firestore
データの補完・取得はFirestoreから行っています。Realtime Databaseとどちらがいいの、と気になりますが基本的には後発のFirestoreの方が良いようです。
Realtime Database vs. Cloud Firestore — Which Database is Suitable for your Mobile App
しりとりでは使われていない単語を「ランダムに」抜く必要があります。xxから始まる単語を全部抜いてサンプルする・・・なんてことをやっていた日にはえらい量を通信しないといけないので、今回は各単語(ドキュメント)にIDを振り、IDを生成/指定してデータを取得しています。
Firestoreからのデータ取得は、以下のチュートリアルがわかりやすいです。
Pythonによる自然言語処理
データの取得は青空文庫から行いました。アクセスランキングが提供されていたので、そこから各作品のURLを取得し、XHTMLファイルのデータをダウンロードしています。サイトに負荷をかけないよう、一回アクセスしたページはhtmlを保存して次回からアクセスせずに処理できるようにしています。
形態素解析にはJanomeを使用しています。単語は複数の形態素に分かれるケースがあるため(平等院鳳凰堂なら平等/院/鳳凰/堂、など)、これを連結する必要があります。JanomeにはこれをサポートするAnalyzerという機能があります。Analyzerは、形態素解析における定型的な処理(前処理、フィルタ、マージ)などをパイプラインで実装できる機能です。
名詞を連結して複合名詞にするCompoundNounFilter、また名詞のみを取り出すのに使えるPOSKeepFilterはデフォルトで提供されているので、今回はこれらを使用しました。
なるべく各作品・頭の単語が均等になるよう単語を取りましたがやはり偏りがでました(前処理が足りず、一部変な開始単語もありますが)。

ここで取得したデータをFunctions経由でFirestoreに登録して、チカちゃんの頭脳としています。
チカちゃんとしりとりをして、豊富な教養をもって2020年を迎えましょう!