新しい技術を身に付けたい!と思って検索をしても、検索上位に来る記事が「わかりやすい」かというとそうではない、ということはよくあります。
記事のビュー数、またQiitaのいいね数やはてブ数は、この参考にはなりますが体感として高ければいいというものでもない印象です。
そこで、こうした文章の「評判」だけでなく、文章そのものの構成や書き振りなどに注目して、その「わかりやすさ」を評価できないか?ということで実験的に行ってみたものが以下の「Elephant Sense」になります。
chakki-works/elephant_sense
(Starを頂ければ励みになりますm(_ _)m)
※名前の由来は、象の感覚って実はものすごいらしいという話から
開発に際しては基本的な自然言語処理/機械学習の手続き踏んで行ったので、その過程を本記事でご紹介したいと思います。
ゴール
事前にQiitaの記事を対象に、「単純に検索した場合」「いいね数が高いものを抽出した場合」とで、どれぐらいわかりやすいと感じられる記事があるかを調べてみました(この時の「わかりやすさ」は主観で評価しました。以降のフェーズで、この感覚をどう扱うか説明してきます)。
その結果、以下のような状態であることがわかりました。

いいねを基準に抽出しても5割には到達しない・・・という状況のようだったので、まずは半分はわかりやすいと感じられる状態にしたい、というところをゴールに設定します。

先行研究
文章のわかりやすさに対する評価、というのは先行研究がいくつかあります。英語圏で有名なものは、以下の2つの指標です(「読みやすさの評価指標(1)」のブログに詳しいです)。
- Flesch Reading Ease
- 一文あたりの単語数(文の長さ)、一単語あたりの音節数を利用して算出する
- Flesch-Kincaid Grade Level
- Flesch Reading Easeと同様の特徴を使うが、低い方が高学年向けになる(=難しい)
つまり、「多くの単語が詰め込まれた長い文はわかりにくい」ということですね。逆に適切な文長で、利用されている単語が全体として少なければスコアはよくなります。
ちなみにMS Wordではこの指標を算出することが可能です。試しに計測してみるのも良いかもしれません。
この指標の用途ですが、主に特定の文章が小学生向けか、高校生向けか、といったテキストの難易度の測定に利用されています。国内では以下のような研究の取り組みがあります。
ただ、何も教科書的な文章を想定しているため、そのスコアは文章に含まれている教育漢字とひらがなの割合などに大きく左右され、今回の技術ブログのように、標準表記で書かれているテキストの文章レベルを測定・推定するには限界がある印象です(この点は、「日本語学習者にとって読みやすい文章について」でも指摘されています)。
近い研究としては、以下の計算機マニュアルのわかりやすさの測定についての研究がありました。
こちらの研究ではマニュアルにおける表現の品質として、以下2つの観点を提示しています。
- 表現の正確さ:内容の正しさ、表記の正しさ(文法誤りなど)
- 表現の品質:理解しやすいか、読みやすいか、使いやすいか(検索性)、図表は具体的か、例示は適切かなど
技術ブログ的にいえば、「書いている内容が合っているか」と「書き方は適切か」という二点ということです。この研究と同様、今回は「表現の品質」にフォーカスします(表現が正確かどうかは外部知識が必要なため)。後述しますが、利用する特徴量についてもこの研究を参考にさせて頂きました。
その他、文の特徴に関する研究として以下の論文にもざっと目を通しました(直近のNIPS/EMNLPあたりを参考に)。
- Document Summarization Using Sentence Features
- Extractive Summarization Using Supervised and Semi-supervised Learning
- Recognizing contextual polarity in phrase-level sentiment analysis
- Analyzing Linguistic Knowledge in Sequential Model of Sentence
データの用意
今回は機械学習を利用することは決めていたので、何はともあれデータが必要です。具体的には、「この記事はわかりやすい/わかりにくい」といったアノテーションがされたデータということです。
通常、アノテーションを行うにあたってはまずタスクをしっかりと設計することが重要になります。
この方式については、以下の書籍にとてもよくまとまっているので、テキストデータのアノテーションを行う際は一度目を通しておくと良いと思います。
Natural Language Annotation for Machine Learning
今回、「わかりやすさ」について「後輩に読ませられるか」という基準にすることにしました。これは、アノテーターの知識によってわかりやすさがぶれることを回避するためです。そして、その評価は0/1で行うことにしました。これは、段階の定義が難しかったのと評価に動員できるのがチームの3人だけだったので、なるべく揺らぎがないようにする必要があったためです(さらっと書いてますが、この「わかりやすさ」をどうアノテートするかはだいぶ議論がありました)。
また、対象となるコーパスはQiitaから取ることにしました。つまり今回は「Qiitaの記事に対して後輩に読ませられるかどうかを0/1で評価」し、そのスコアを予測することで「わかりやすいと感じられる記事の量を50%に増やす」のが目的になります(上記の書籍によれば、アノテーションの作業とその先の達成したいタスクがきちんと連結しているのが重要とのことでした)。
アノテーションは100件の記事に対して行いました。ただ、無作為に抽出するといいね数が少ない記事が大半になってしまうのでそこは調整しました。
最終的なアノテーション結果は以下のようになりました(3人で行なったので、3がMAX(全員が1をつけた)になります)。
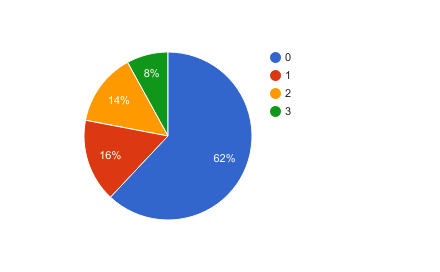
こちらのデータを利用し、モデルの構築を行なっていきます。
モデルの構築
ニューラルネット依存症になっているとここでWord2VecでもかましてRNNでエンコードするとかそんな感じになりがちですが、今回はベースラインになるようなモデルをきっちり作ることにしました。
先行研究を参考にし、候補にした特徴量は以下の通りです。
- Length Feature
- 文の長さ(平均・最大・最小)
- 見出しの長さ
- セクションの長さ
- 文章の長さ
- Counting Feature
- 単語数
- 単語TF/IDF
- ひらがな/カタカナ/漢字/英字/数字の割合
- 句読点の数
- 改行の数
- 強調語の数(カギカッコ/ダブルクウォーテーションのペア)
- 箇条書きの数・割合(全文数に対する)
- 見出しの数・割合(全文数に対する)
- 図の数(image)・割合(全文数に対する)
自然言語における特徴量は、基本的に「長さ」か「数」のどちらかに大きく分けられるというイメージです。「数」は、さらに母数を伴うことで「頻度(確率)」、前提条件をつけることで「条件付き確率」が導出できます。
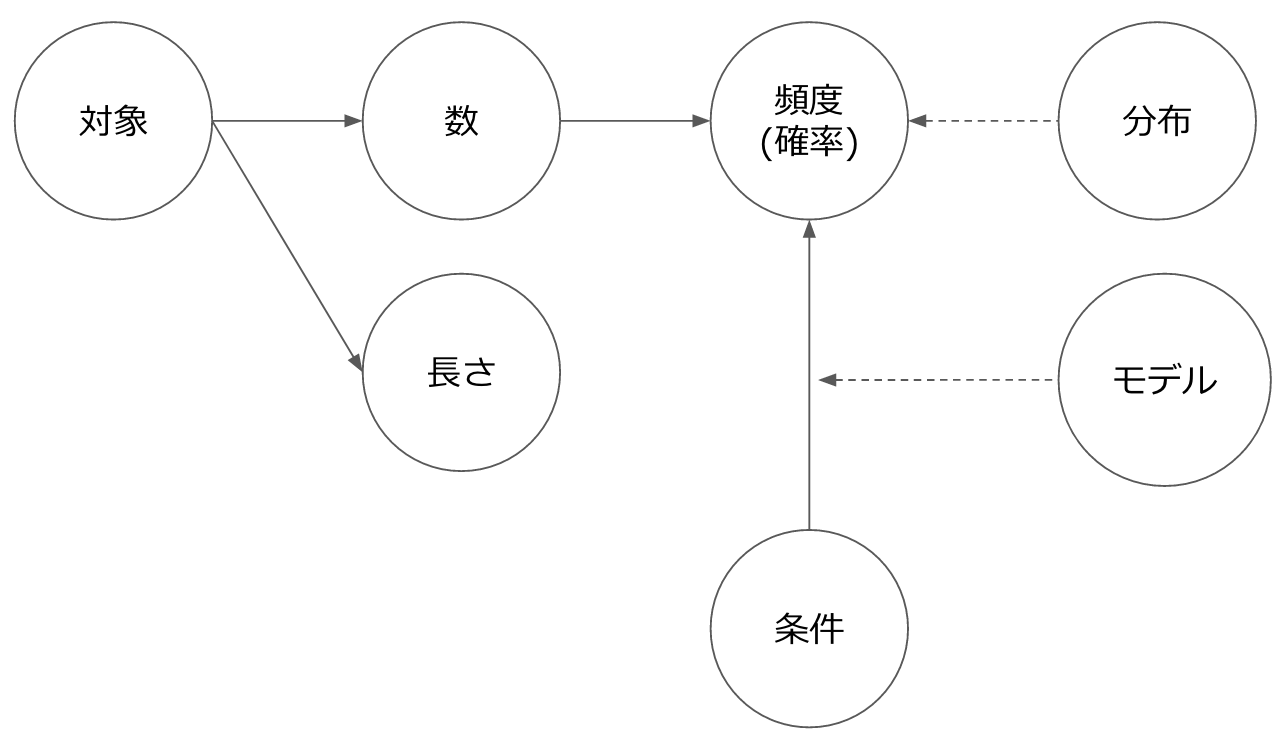
単語についても、今回は前処理を結構丁寧にやりました(この辺りは@Hironsanがあとで解説してくれるはず)。
リストアップした特徴量を利用してシンプルなRandomForestを利用し、テストを行なってみました(RandomForestは、各特徴量の貢献度が簡単にわかるのでその点も良いです)。
実際にモデルを構築した結果はこちらになります。
elephant_sense/notebooks/feature_test.ipynb

データセットは小さいですが、大分精度は高いものになっています。特徴量をみると、以下のものがよく効いているようです。
- image_count: 図の数
- sentence_max_length: 文の最大長
- user_followers_count: ユーザーのフォロワーの数
「信頼できる人が書いていて、適切な文長で書かれていて図が含まれている」ということですね。特に図の有無は大きく効いていました。
「ユーザーのフォロワーの数」は今回の趣旨に反しており、Qiita独自の特徴のため当初は入れない方針でしたが、精度+今後他の文章に応用する際も「書いた人」に関する情報は何かしらの形で取れるということで入れることにしました。
なお、今回の比較対象となるいいねのみで分類してみた結果は以下になります。
elephant_sense/notebooks/like_based_classifier.ipynb

こちらをみると、「わかりやすい」文章(1)の予測ができていないことがわかります。そういった意味では、今回のモデルは思ったよりも役立ちそうです。
アプリケーションへの組み込み
構築したモデルを組み込んで、実際に使えるアプリケーションを作成してみます。
アプリケーションに機械学習モデルを組み込むとき、そのモデルで利用した正規化のためのオブジェクト(今回StandardScaler)も必要になる点に注意してください。モデルを作るときに正規化を行なっていたのなら、当然予測をする際にも正規化が必要になります。
フロントエンドは簡易さ重視で、Vue.js/axiosで構築しました。axiosはhttpリクエストを送るためのライブラリで、サーバーサイド(Node)でも使えるほかクライアント側のサポートもしっかりしています(特にXSRF Cookie対応はありがたかった)。
出来上がったアプリケーションはHerokuへデプロイしました。今回はscikit-learnなどを利用しているため通常のデプロイは難しいので、Dockerを利用したデプロイを行なっています。
Container Registry and Runtime
今まではbuildpack職人にならないといけなかったので、これは便利(ただ、プロキシ環境からは使えないのでちと辛い)。
デプロイしたアプリケーションは以下になります。
しかし・・・遅い!本当は評価対象の投稿をもっと増やしたいのですが、パフォーマンスの関係で絞っています(今は50件の検索結果をスコアリングして表示しています)。一応並列処理化などもしているのですが、やはり各文章をhtmlパースして特徴を抽出して・・・とやっているので、かなり遅くなってしまいます。ここはフロントエンド側の工夫も含めて、改善が必要だなと思います。
表示結果については、まあまあ、といった印象です。ただ、目標の50%に達するにはやはりより多くの文章を評価してから表示しないといけないので、上のパフォーマンス問題と表裏一体なところはあります。
なお、スコアの表示にはmeterタグを利用しています。今回の開発で初めて存在を知りました。progressのタグもそうですが、意外と知らないタグもあるなと。
今後
問題設定・データの収集・モデルの構築・アプリケーション化、と一通りのプロセスをへて、そこそこできたかなという印象です。
これがより進化すれば、設計書やAPIドキュメントなどに適用しドキュメントの品質向上を行なったり、新規参入したメンバが「よくまとまった」文章を探すのをサポートするのに使えるのではないかと考えています。
現在、私の所属するチームchakkiでは、「すべての人がティータイム(15:00)までに帰れる社会」を、機械学習/自然言語処理によって実現しようという試みを行なっています。まずは自分達からということで、システム開発における自然言語情報(ドキュメントやレビュー、そしてソースコードなど)を対象に現在は活動を行なっています。
 [@chakki_works](https://twitter.com/chakki_works)
[@chakki_works](https://twitter.com/chakki_works)
興味がある方は、ぜひ話を聞きに来て頂ければと思います!