機械学習を利用する際は、データの前処理から始まって適切なモデルを選んでパラメーターを最適化して・・・というように多くの作業が伴います。
ただ、この作業の少なくない部分は定型的なものです。前処理でいえば、数値データに対しては正規化を行う、カテゴリー変数は0/1の特徴量へ変換する(ダミー変数化)、といった処理はどんな場合でもとりあえず実行する処理になります。
もちろん高度な特徴量エンジニアリングなどは話が別ですが、データがあったときに定型的な作業をさくっと行い、とりあえず基礎的なモデルでどれぐらいの精度が出るのかを見てみたい、というシーンはよくあるものです。
そこで、そんな作業を自動化するための仕組みを開発しました。名前はkaruraといいます。
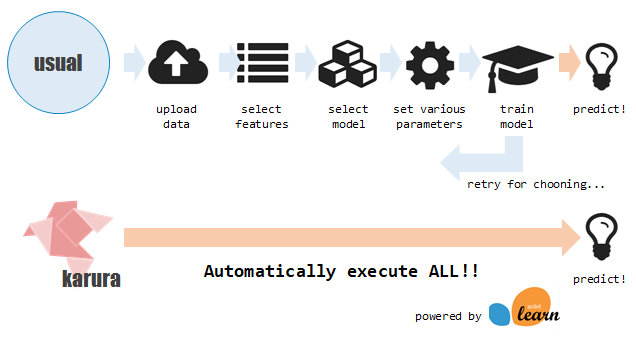
コンセプトとしてはこの図のように、モデルを作るにあたっての定型的な一連の作業を自動化する、といったものです。図中にあるように、scikit-learnの機能をフルフルに活用して作成しています。その点についても本記事で紹介していきたいと思います。
karuraのアーキテクチャ
karuraは、insightと呼ばれる処理を積んでプロセスを構築する仕組みになります。
insightは、「どういう時に」「どういう処理をすべきか」という2つの処理がまとまったものになります。
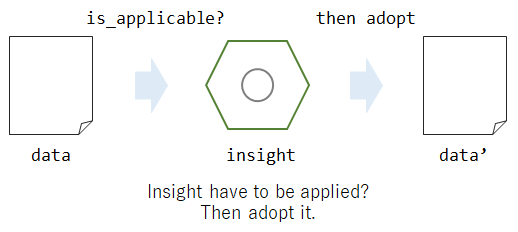
例えば、NAFrequencyCheckInsightでは、あるカラムに「NAがxx%以上入っていたら」「列を削除する」、というような処理が実装されています。
もちろん、列を落とすか落とさないかはケースバイケースだったりするので、ここで対話的に処理を挟み込むことも可能です。
insightは前処理用、特徴量選択用、モデル構築用といった種類に分かれており、種類によって適用される順番が変わります(同じ種類の処理の場合は追加した順に適用されます)。この順序は、InsightIndexで定義されています。
最終的にはこんな感じの実装になります。

もちろん使用するinsightは任意ですし、オリジナルのinsightを作成することも可能です(Insightを継承して作成可能)。
こうして一度プロセスを作っておけば、様々なデータに対して使いまわすことが可能です。作成したモデルは予測用モデルに変換することもできるため、すぐにAPI化することも可能です。
簡単なJupyter Notebookを用意しておいたので、利用方法を見てみたい方はぜひご参考ください。
ツールへの組み込み
karuraは業務アプリケーションへの組み込みを想定しており、以下のプラットフォームと連携が可能です。
Slackとの連携
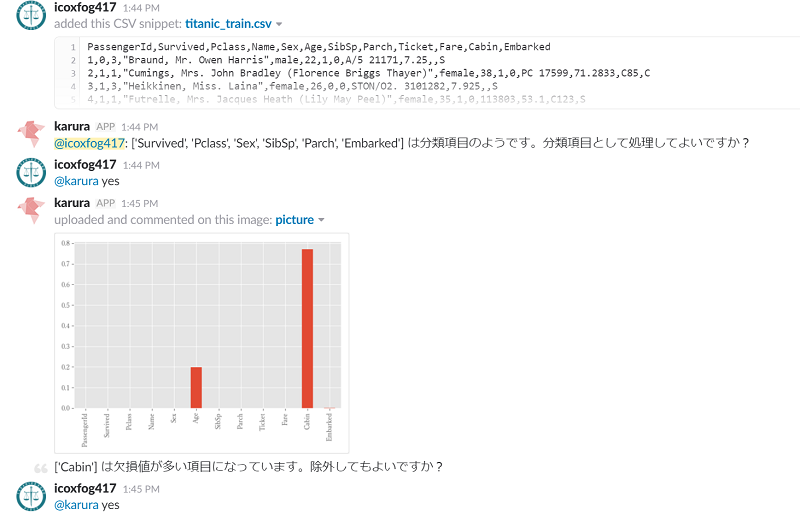
karuraをSlack botとして利用することができます。
 (ちなみに複数言語対応をしており、現状日本語/英語を設定することが可能です)
(ちなみに複数言語対応をしており、現状日本語/英語を設定することが可能です)
Slack botとして使用する場合は、csvなどのデータファイルをアップロードするとkaruraが分析を開始します(分析プロセスについては、上述の通り事前に定義しておきます)。分析する上で確認が必要なところは、対話形式で確認が行われます(Insightを定義する際に、automaticをFalseにすると確認を待つようになります)。
なお、karuraではこうしたデータを解析する上で確認しなければならない点をユーザーに教える、というのも重要な機能と位置付けています。というのも、構築したモデルの予測結果を解釈するにはデータに関する知見が必要不可欠なためです。
そのため、karuraの中では説明力が担保されたモデルを利用しています。またなるべく早い改善サイクルを回すため、学習が軽いモデルを利用しています。端的に言うとディープなモデルは使ってないです。
karuraの用途は「定型的な作業を自動化してさくっと確認する」というものなので、高精度なモデルを時間をかけて作るというところはそもそも機能として落としています。「手軽に素早く」モデルを作成することで、このままじゃ精度出ないぞ、データの項目を追加しないと/ちゃんと空白のデータを入力するようにしないと、と気づくためのツールにしています。
こうした機能に絞り込んでいる背景については、以下の資料で詳しく書いているためご興味があれば参照いただければと思います。
機械学習を活用するための、3本の柱~教育型の機械学習ツールの必要性~
kintoneとの連携
業務アプリが簡単に作れるプラットフォームであるkintoneに組み込むことも可能です。kintoneで作成したアプリの中のデータを使って、簡単にモデルの作成を試してみることができます。
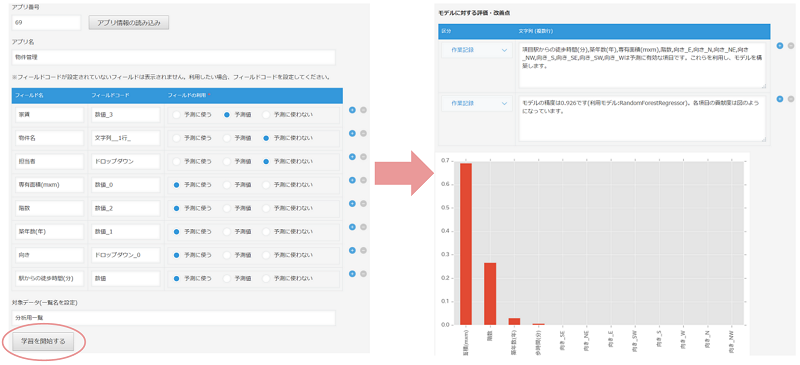
- 分析したいアプリの番号を入力する
- アプリの項目の中で、予測に使いたい項目と予測する項目を選択
- 学習ボタンを押す
これだけで分析は完了です。分析したアプリのほうにプラグインをインストールすれば、karuraに予測させた値を入力することも可能です。この点については以前ハンズオンを行ったので、興味がおありの方はぜひ試してみていただければと思います。
なお、業務アプリの中のデータをそのまま分析にかけて上手くいくなんていうことはほとんどありません。実際は精度があまり出ず、どんな項目が悪いのか、どういう項目を足したらいいのか、そうした検討が進んでいくことになります。
こうした作業をkintoneアプリ上で行うのはつらいので、実際の値と予測結果の一括ダウンロード機能と、ファイルアップロードによる再学習機能を搭載しています。
これによって、データに関する様々な仮説を検証することが可能です。
karuraの実装
karuraの中身はscikit-learnをフルに活用して作成されています。
- 前処理: sklearn.preprocessing
- 特徴量選択: sklearn.feature_selection
- モデル選択・最適化: sklearn.model_selection
そして、予測API化するために全処理をPipelineでまとめています。
機械学習はいい精度のモデルができた、で終わりではなく、それを活用しなければ意味がありません。そして作成したモデルには当然前処理済みのデータを入力する必要があり、また予測値については正規化やインデックス化が行われているため逆変換を行う必要があります。
つまり、モデルを「全ての前処理」と「ラベルの逆変換」でサンドイッチして初めて使えるAPIになるわけです。モデルで精度が出た!と思ってもそこに至るまでの累々たる前処理を見て「これを全部実装してモデルに渡さんといかんのか・・・」と気が遠くなることがしばしばあります。
karuraでは分析時に使ったinsightを予測のためのTransformerに変換する処理を実装することで、モデルを構築するためのプロセス(insightを順次適用していく)が定まれば予測のためのプロセス(Transformerを順次適用していく)に変換できるようにしています。
数値を正規化するinsightであるNumericalScalingInsightでは、get_transformerが実装されており、分析時に判明した正規化用の平均や分散といったパラメーターが予測のためのTransformerに引き継がれるようになっています(実際はStandardScaler/MinMaxScalerで処理されますが)。
現在は自然言語/画像の項目に対応できていないのでsklearn.feature_extractionはまだ使用されてないですが、こちらは今後使うことになるかもしれません。
karuraはGitHubで開発中なので、ぜひ活用いただければと思います!
chakki-works/karura
(Starをいただければ励みになりますm(_ _)m)