最近出たAzure Cosmos DBでは5種類のConsistency Levelからマッチするものを選択してデプロイできるようですね。また少し古いですが「Consistencyを考慮してFacebookが自身の作ったCassandraではなくHBaseを採用」 みたいな記事が出たときは驚いたりしました。
そんな感じで "Consistency" というのは重要のようです。
データストアへの興味は分散DBMS開発を経験して持つようになったのですが、最近 "Consistency" について調べてみましたので整理もかねて書いてみたいと思います。また、基本をおさえることが重要と思ったので(もう10年前の論文になってしまいましたが)Amazon Dynamoの論文 "Dynamo: Amazon's Highly Available Key-value Store" にもふれてみたいと思います。
よくわからないCAPのCとACIDのC
Consistencyというのはよくわからないです。例えばPublickeyの「クラウド上のリレーショナルデータベースはなぜ難しいのか? BASEとCAP定理について」という記事ではCAPのCとACIDのCの混同があったようです(修正線がひかれています)。
http://d.hatena.ne.jp/winplus/20091023/1256305279 によると下記のように書かれています。
・ACIDのC:口座Aから送金を行うとき、その前後でAの口座残高が負になるような額を送金することはできない。
・CAPのC:口座Aから送金を行った後に口座Aの残金を確認すれば、かならず送金後の金額である。
これ以外にも下記のWebページでもCAPのCとACIDのCについて考察しています。
- The confusing CAP and ACID wording
- yohei-y:weblog: CAPのCとACIDのC
- クラウド時代の分散データベースを支える技術の応用と進歩 - kuenishi's blog
ACIDのCは銀行口座の例で分かりやすいですが、CAPのCは「別のクライアントの書き込みがちゃんと読めるか(言動に一貫性があるか)」=「何らかの Consistency Model (後述)を満たしているか」という風に理解しています。
Eventual Consistency
ところでEventual Consistencyというのも、これらと違うように思えます。
よく「複数ノードからなるシステムで各ノードがいずれ同じレプリカをもつようになる」という説明を見ます。内部的な動作の話だけで外部から見える振る舞いについての言及はなく、クライアントはどう接すればよいのかわからない気がします。
これはEventual Consistencyでは、ノード間のデータの複製に一貫性がないだけでなくクライアントから見える振る舞いにおいても一貫性がないということでしょうか?後述の「最新データを読んで再度読んだときにデータが巻き戻るケース(Quorum版)」で考えてみました。
私の好きなConsistency Model
並行システム・分散システムの読み書きの振る舞いをモデル化したものをConsistency Modelと呼ぶらしいです。
既存のConsistency Modelを意識することで、要領をえない説明をして怒られたり、複雑でよく分からないオレオレConsistency Modelにおちいったりするのを防げると思います(アプリケーションから分散DBを利用する場合やアプリケーションに分散システムを提供する場合など)。
そこで私の好きなConsistency Modelについて少し紹介したいと思います。
-
Strict Consistency
- いつ読んでも最新の値が読める(直前に書かれた値が読める)というものです。シンプルです。
- 1ノードだけのシステムや分散システムでもマスターノードが存在する(選出される)+同期レプリの場合にStrict Consistencyの場合が多そうです。
-
Causal Consistency
- 書き込み直後に最新のデータが読めるとは限りませんが、どのクライアントから見てもデータの変遷は同じというものです。
- Message QueueなどのPersistent Communication機能をもつ場合、このConsistencyをみたすと思います (メッセージを書いた直後だと最新データは読めませんがメッセージがデータノードに反映されれば読めるため)。
-
Read-your-writes Consistency
- 例えばSNSに自分の近況を書いていつまでも自分のタイムラインに表示されないと不安ですが、このConsistencyなら自分の投稿がすぐ読めるので不安になって連投してしまうことがありません。安心です。
蛇足
例えばGoogle Cloud Datastoreのベースの Megastoreの論文 によると、読み書きするマスターノードをEntity Group単位で分割して読み書きをローカルトランザクションに落とし込んでStrict Consistencyを担保しているようです。
またGlobal Indexではテーブルのレコード更新とともにインデックスの更新メッセージがMessage Queueに一旦書き込まれ、その後インデックス更新が実行されるようです。
ではインデックスを使う読み込みはCausal Consistencyでは?と思ったのですが、インデックスが指し示す先のレコードデータとの整合性がとれない(Entity Groupが異なる)ためEventual Consistencyになるという意味だと理解しました: https://cloud.google.com/datastore/docs/articles/balancing-strong-and-eventual-consistency-with-google-cloud-datastore/?hl=ja#h.4xdytk3hj44
最新データを読めた後に再度読んだら古いデータに巻き戻るケース(Quorum版)
ここでは Eventual Consistency の振る舞いはよくわからないと感じた点を書いていきたいと思います。
https://docs.microsoft.com/ja-jp/azure/cosmos-db/consistency-levels#a-nameconsistency-levelsa一貫性レベル
によるとEventual Consistencyは「クライアントは、過去に認識した値よりも古い値を取得する可能性があります」とあり、取得する値の新しさがばらつく可能性があるようです(少なくともAzureの定義においては)。
Dynamo系データストアにおいて1ノードにしか読み書きをおこなわないモードではもちろん値の新しさにばらつきが発生しますが、ここではQuorumの設定をしていた場合でもデータが巻き戻るケースがないか?を考えてみたいと思います(間違っているかもしれません)。
想定するデータストア
ここでは、多くのDnynamo系データストアが持っているであろう下記の機能を持つデータストアを想定したいと思います。
-
Quorum
- ここではデータのレプリカを2つ持つとして、3ノード中2ノードに書き込めたら書き込み成功、2ノードから同じデータが読み込めたら読み込み成功とします。
- この場合、障害さえ発生しなければ書き込み完了後に読めばStrict Consistencyな気がします(3ノード中2ノードに書き込めば3ノード中2ノードから読めるので)。
-
Read Repair
- データを読んだときに各ノード間でデータの不整合を検知した場合に修復をおこないます。
-
Hinted Handoff
- 担当ノードにデータが書き込めなかった場合、別ノードにとりあえず書いておいて、後から書き込めなかったノードを修復します。
データが巻き戻る場合の動作
データを保持するサーバーが3ノード、クライアントが3つあるとします。1クライアントが書き込もうとしており、2クライアントがデータを読もうとしています。
クライアントaがノードAから k1: v1 を読み込みます
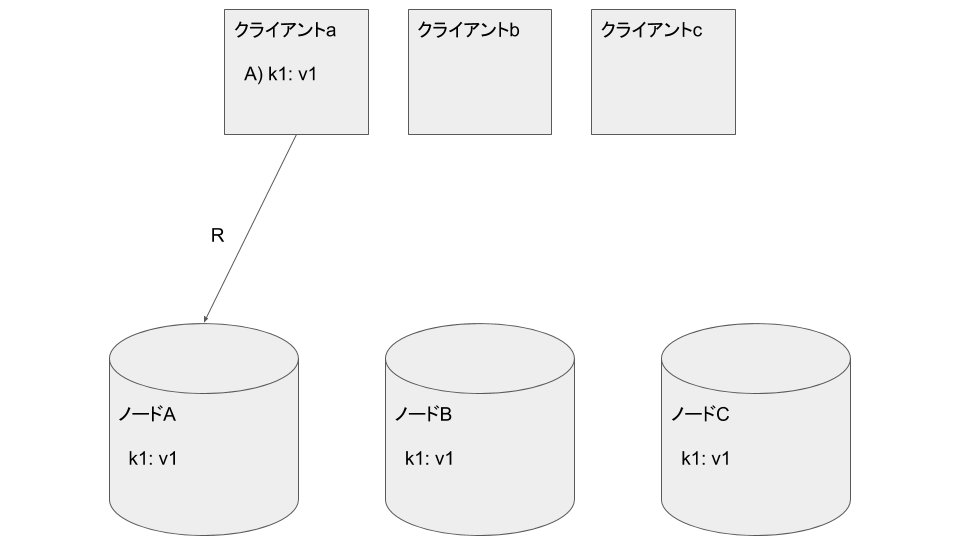
クライアントbがノードAに k1: v2 を書き込みます
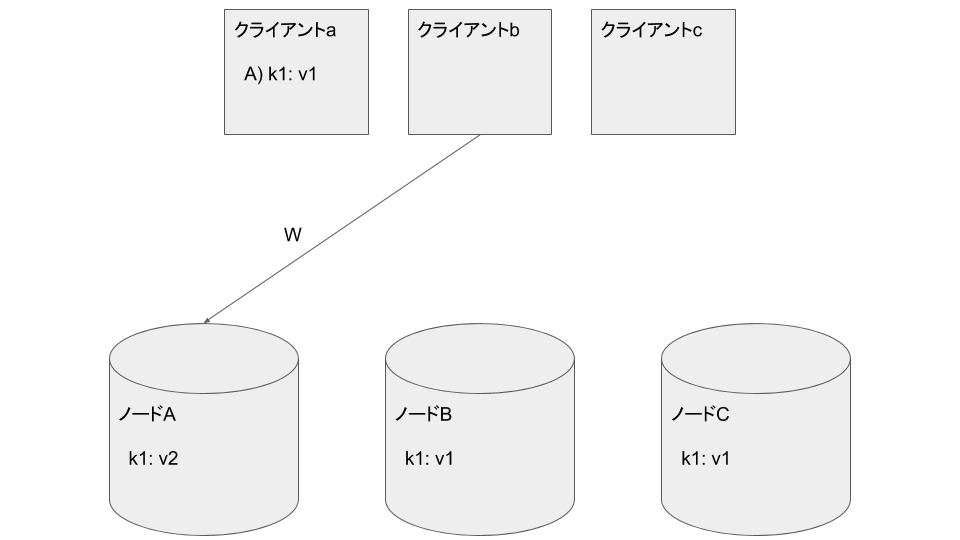
クライアントbがノードBに k1: v2 を書き込もうとしますが一時的なNW障害で失敗したとします。Hinted Handoff領域に失敗した旨を記録します:
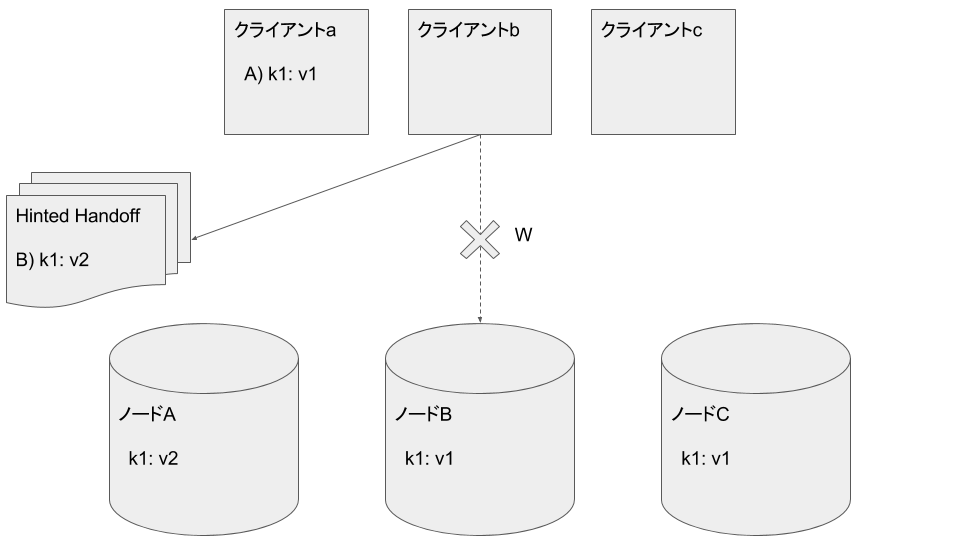
クライアントbがノードCに k1: v2 を書き込みます
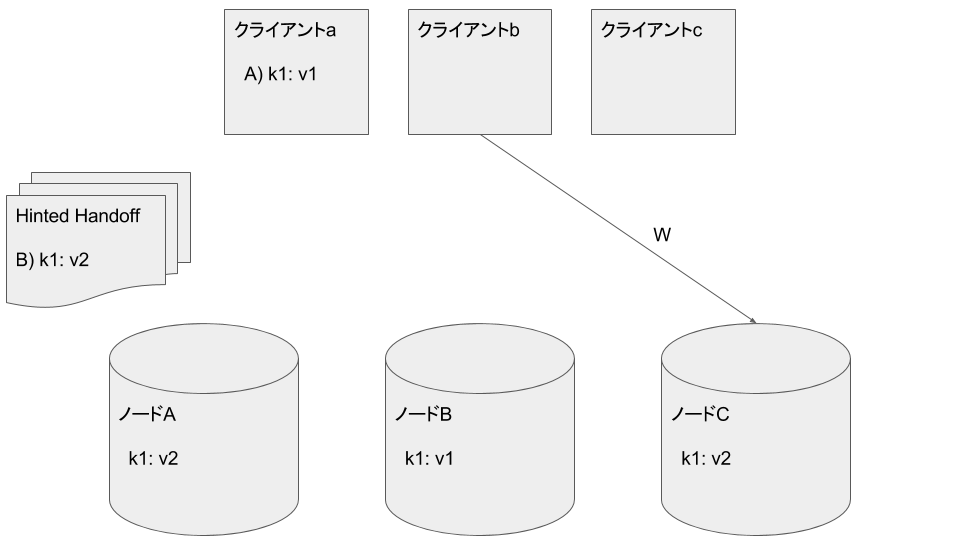
クライアントcがノードA, Cから k1: v2 を読み込みます。最新のデータを取得できました:
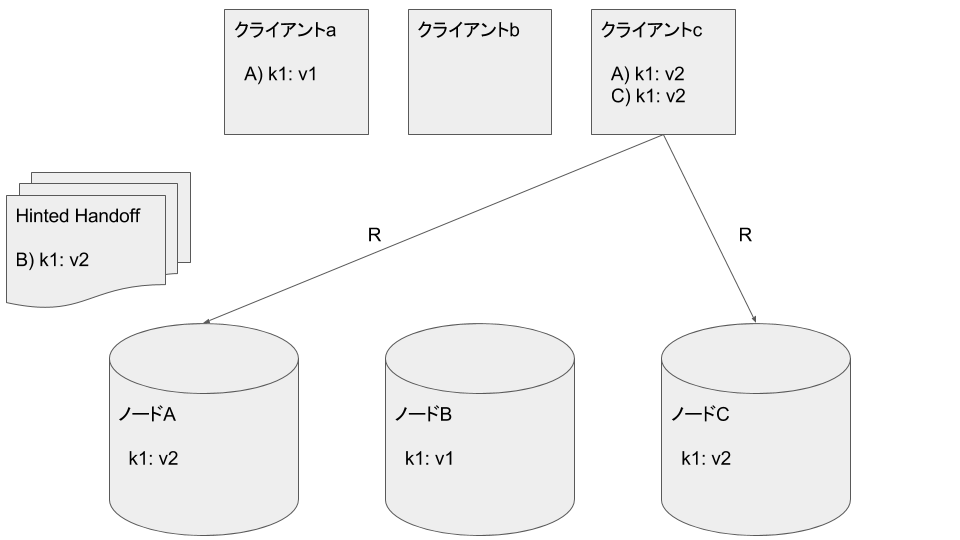
ノードCが故障後に復旧したとします
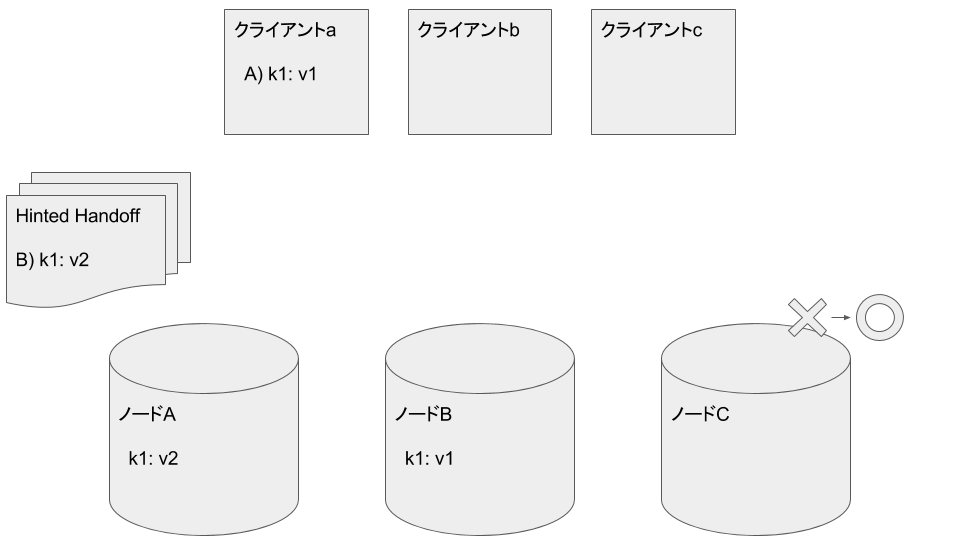
クライアントaがノードCから読み込みを試みますが復旧したてのため失敗します
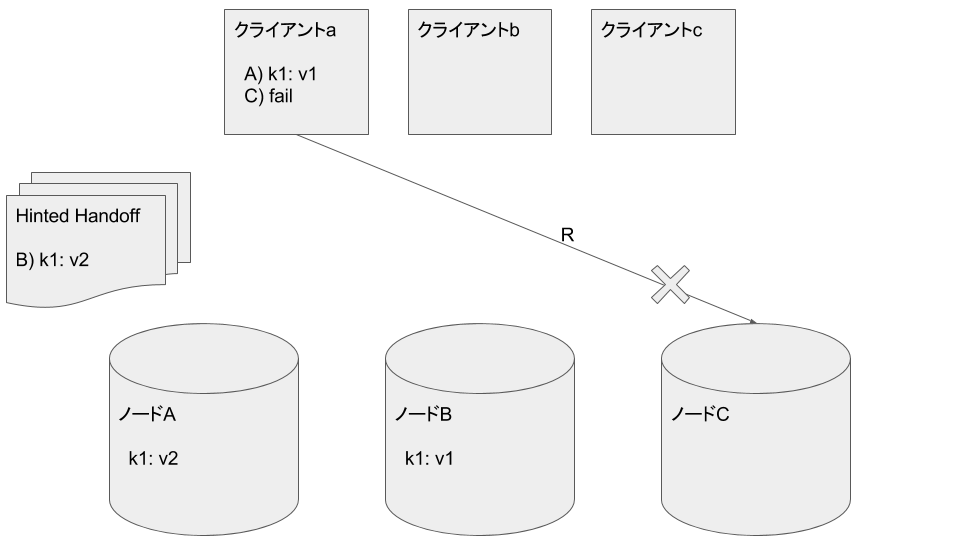
クライアントaがノードBから k1: v1 を読み込みます
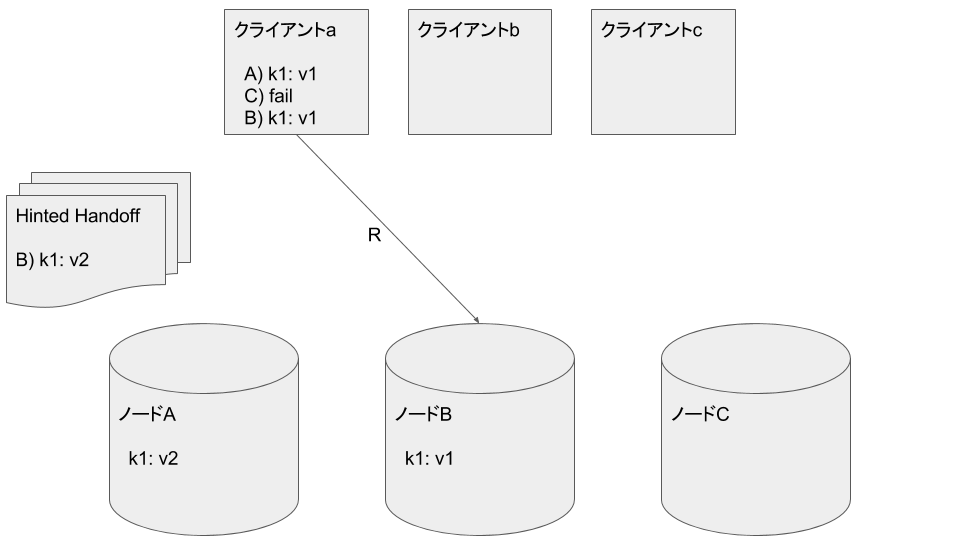
Read RepairによりクライアントaはノードCに k1: v1 を書き込みます。
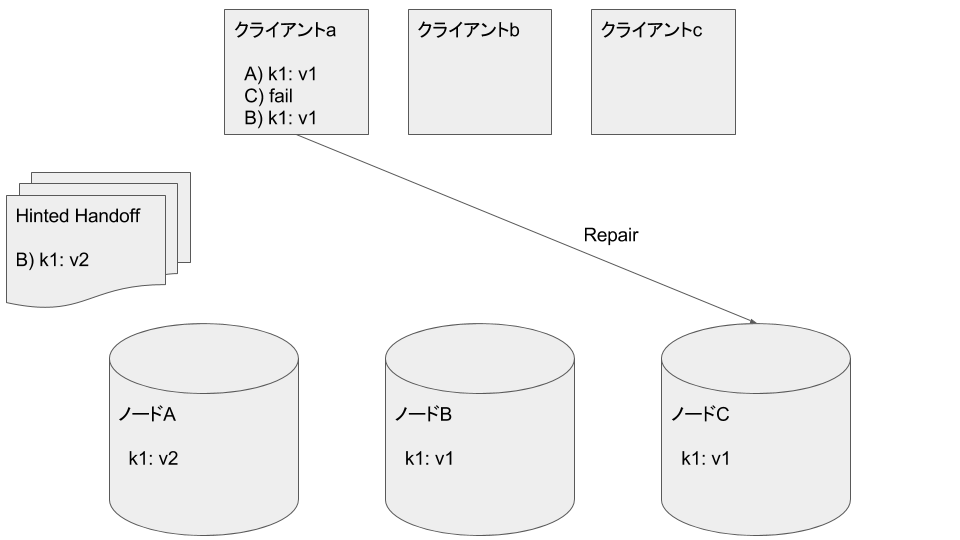
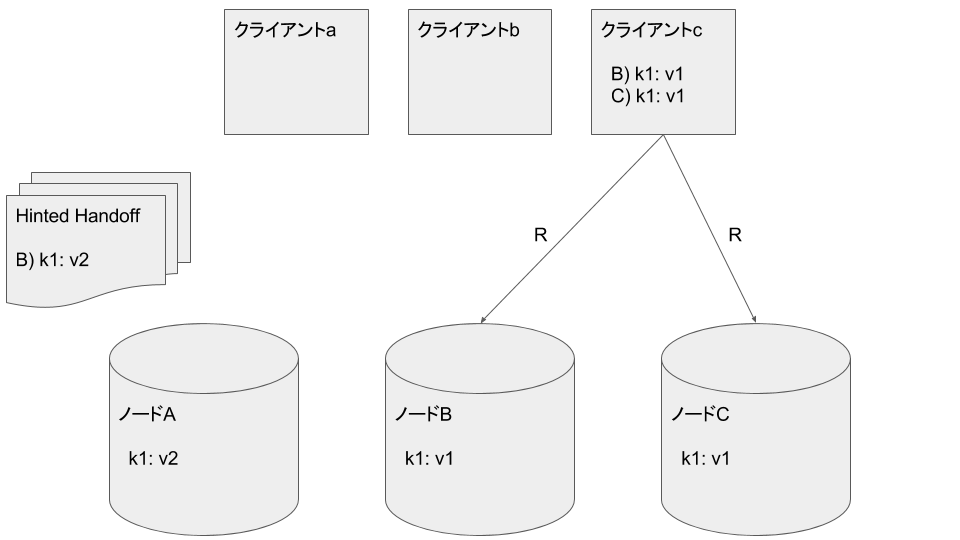
クライアントcがノードB, Cから k1: v1 を読み込みます。クライアントcはひとつまえのデータを取得したことになります:
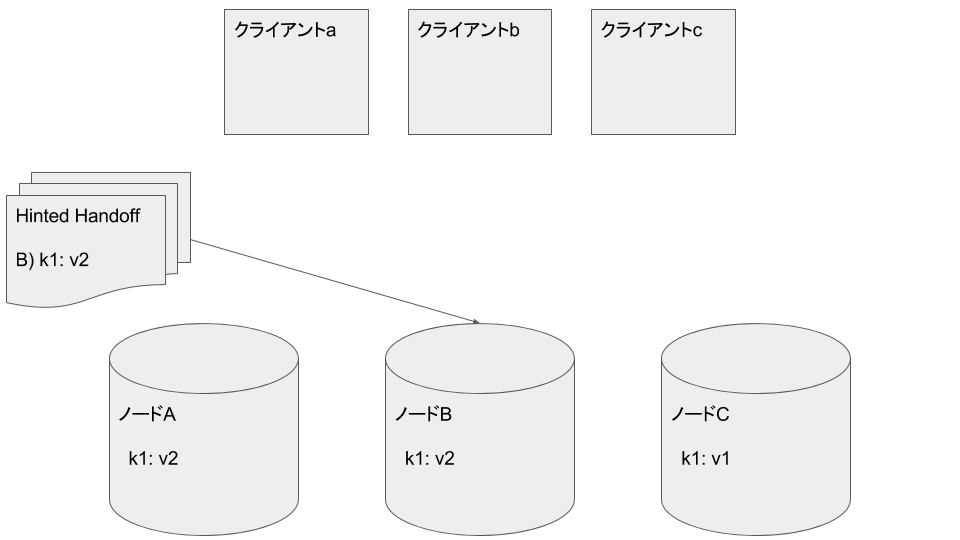
Hinted Handoff に記録された失敗にもとづきノードBに k1: v2 が書き込まれます
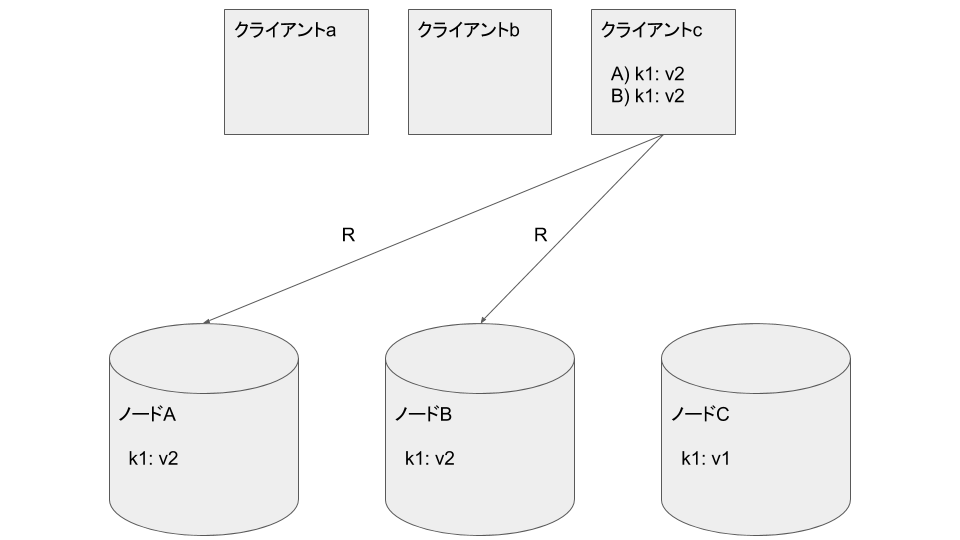
クライアントcはノードA, Bから k1: v2 を読み込みます。最新のデータが読めました:
このような状況は「実際にはほとんど発生しない/不整合を減らす多くの機能が実装されている」と思います。例えば、Dynamoの論文には "In our next experiment, the number of versions returned to the shopping cart service was profiled for a period of 24 hours. During this period, 99.94% of requests saw exactly one version; 0.00057% of requests saw 2 versions; 0.00047% of requests saw 3 versions and 0.00009% of requests saw 4 versions. This shows that divergent versions are created rarely." と書かれており、不整合はほとんどありません。
ただ、Eventual Consistencyとだけ書いてあった場合は機能が複雑にからまりあって振る舞いがよくわからないと感じました。
なぜDynamoがNoSQLの流行を牽引できたのか(ポエム)
NoSQLの流行はDynamoの論文からはじまったのではないかと思っています(要出典)。
HBaseなどのCP型のデータストアは書き込みの段階から読み取り時のConsistencyを考慮していますが、DynamoのようなAP型のデータストアは読み取り時に一工夫必要となるかわりに
- 書き込みを(読み込みも)ストールさせないですむ (高可用性)
- スケールアウトしやすい
- 障害復旧もしやすい
- Inconsistencyは確率的にはほとんどない
という点をアピールできたのが大きかったのではないでしょうか?
いままでデータストアにおいてはConsistencyは必須と考えられていたところに「なくても問題ない」のをアピールできたので、インパクトがあったのだと思います。Eventual ConsistencyでOKなサービスにおいてAP型のデータストアは競合データストアに対して完全に有意な立場をとれたのだと思います。
高可用性
特に書き込みの高可用性について論文中では何度もアピールされています ('always-on', 'always writable', 'to ensure that writes are never rejected', 'high availability where updates are not rejected even in the wake of network partitions or server failures', 'no updates are rejected due to failures or concurrent writes')。
いくつかのノードが利用できない状態でも、書き込めるノードに書き込めればOK、読み込めるノードから読み込めればOKなので可用性はとても高そうです(そのためにある程度のConsistencyが犠牲に)。
ただそのため、データ読み取り時にアプリケーション側で何らかの競合解決が必要なケースもあるとも書かれています。複数クライアントが同時に書き散らかしてそのままになっている場合など、読み込み時に正当なデータが何なのか決める必要があるようです。論文中では競合解決の方法として、各ノードから読んだ各データをマージする方法(ショッピングカート向け)、タイムスタンプを見て書き込み時刻が最後のものを正当とする方法などが上げられています。
DynamoとDynamoDBの違い
公開サービスのDynamoDBは詳細が公開されいませんが(Dynamoに近そうですが)、Dynamoとくらべて信頼できそうな気がしますよね(Strong Consistency云々の記述がありますし)。
DynamoDBでは、Dynamoで必要だったアプリケーション側のConflict Resolutionが不要だったり、「DynamoDBでは3つのAZ間で同期レプリをしている」という記述をみたのでDynamoとは結構違うのかもしれません。
下記のStack Overflowの回答でCassandraの実装をヒントにどのような実装なのかを考察しており興味深いです。
参考にした文献
- Cosmos DB
- FacebookのHBase利用
- Dynamo: Amazon's Highly Available Key-value Store
- CAP/ACID
- Consistency Model
- Google Cloud Datastore
- DynamoDBの同期レプリ
- Data loss