出題範囲
分野1:データエンジニアリング (20%)
分野2:探索的データ解析 (24%)
分野3:モデリング (36%)
分野4:機械学習の実装と運用 (20%)
出題範囲
試験ガイド
機械学習用語
- ユーザーエクスペリエンス向上
- 協調フィルタリング
- 従業員の滞在・離脱
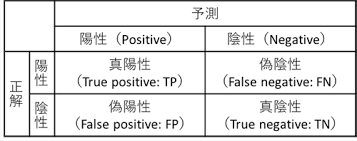
- 分類モデル
- 混同行列を使って視覚化
- 分類モデル
- F1スコア
- モデルを選択する際に適合率と再現率に基づくメトリック使用
- 販売予測、天気、数値予測する機械学習モデルの作成
- 線形回帰
- 国勢調査記録などの高次元データ分析
- 主成分分析(PCA)
- 教師なし。データセット内の次元(特徴の数)を削減
- K-means
- 教師なし。データ内の個別のグループ発見
- サポートベクターマシン
- 教師あり。データのグループ分離、分類と回帰の両方の目的で使用できる
- 主成分分析(PCA)
- 外れ値対処
- 対数変換
- 堅牢な標準化
- 一部欠落している値発見
- 連鎖方程式(MICE)による多重代入
- モデルの過剰適合を解決
- Object2vec
- ハイパーパラメータの値を増やしてドロップアウトを使用
- 適用される正則化を増やす
- 特徴選択
- Object2vec
- 画像に存在するアイテム検出
- オブジェクト検出
- 不正な取引検出のトレーニング
- Synthetic Minority Oversampling Technique(SMOTE)を適用
- 感情を分析するベースラインMLモデル
- 多項ロジット回帰
- ロジスティック回帰
- 二項ロジスティック回帰
- ソーシャルプログラムを決定する顧客セグメンテーションタスクの解決に使用
- 多項ロジット回帰
- カテゴリの特徴を数値に変換
- ワンホットエンコーディング
- k-NN
- インデックスベースのアルゴリズムです。分類または回帰にノンパラメトリック手法を使用します。
- リカレントニューラルネットワーク
- シーケンシャルデータを処理するための推奨アルゴリズム
- ランダムカットフォレスト
- データセット内の異常なデータポイントを検出、Amazon Kinesis Data Analyticsの機能
- Object2Vec
- Amazon SageMakerの組み込みアルゴリズム
- クレームが準拠しているかどうかを分類できる教師ありモデルをトレーニングする
- BlazingText
- Word2Vec
- 因数分解マシン
- ワンホットエンコーディング
- 正規化
- ランダムアプローチ
- トレーニングデータのオーバーフィッテングへの対処
- ハイパーパラメータの調整、正則化、ドロップアウトの有効化、早期停止
- テキストの前処理のステップ
- 文章の単語化、大文字を全て小文字に変換、ストップワードの削除
- 画像に対しての高いパターン認識能力を持つアルゴリズム
- 畳み込みニューラルネットワーク(CNN)
AWSサービス
-
CSVデータをParquet形式に変換したい
-
Kinesis Firehose
-
Pollyでの誤発音への対処
-
Pronunciation Lexicon 発音辞書
-
S3バケットのメタデータをクエリしたい
-
Athena
-
SageMakerの監視
-
CloudWatch
-
スペイン語の音声ファイルの分析&翻訳
-
Transcribe、Comprehend、Translate
-
RDSに保存されているデータをSageMakerで分析したい
-
Data PiplineでRDSからS3へデータコピーしてから分析
-
SageMakerノートブックインスタンスへのアクセス制限
-
IAMポリシー
-
Sagemekerでカスタムアルゴリズム作成時に使用するサービス
-
ECR、S3
-
イメージ分析やビデオ分析の機能をアプリに追加したい
-
Rekognition
-
Amazon Elastic Inference
- コスト削減
- 高価なGPUベースのインスタンスにお金を払うことなく、推論のワークロードを加速したい
-
Amazon Personalize
- Amazon.com がリアルタイムのパーソナライズされたレコメンデーションに使用するのと同じ機械学習 (ML) テクノロジーを使用してアプリケーションを構築可能
-
Amazon Polly
- 音声応答システム用にプレーンテキストドキュメントを音声に変換
-
Amazon Forecast
- ターゲットの時系列および関連する時系列データセットの欠落値を処理するための多数の「充填」メソッド
-
Amazon Comprehend
- 非構造化データの洞察と関係を明らかにするのに役立ちます。テキストの言語を識別します
-
Amazon Rekognition
- 機械学習による画像とビデオの分析
-
Amazon Transcribe
- 音声をテキストにすばやく正確に変換する
-
Amazon SageMaker
- 素早くプロセスを回せるようにするためのサービス
- 機械学習のインフラ構築・運用を自動化するだけなく、様々な機能がある
- 機械学習の流れ
- 開発 学習に使うコードを記述、小規模データ動作確認、学習ライブラリ郡がインストール済みのインスタンスを提供
- 学習 大量のGPU、大規模データの処理、試行錯誤の繰り返し
- 推論 大量のCPUやGPU、継続的なデプロイ
- 開発&学習
- データサイエンティストが開発環境で作業
- 開発・学習を同じ1代のインスタンスで実施
- Deep LearningであればGPUインスタンスを使用
- 問題
- 環境構築が大変
- 複数の学習ジョブを並列で実行するのが大変
- 複数マシンを使った分散不学習をいzつげんするのが大変
- 学習結果を管理するのが大変
- 推論
- エンジニアが プロダクション環境に構築
- 問題
- 推論用のAPIサーバ構築とメンテが大変
- エッジデバイスへのデプロイが大変
- バッチ推論の仕組みを構築するのが面倒
- 機械学習である問題を解決するのがSageMaker
- Juupyter Notebook
- 開発環境
- Juupyter Notebook
- パイプラインモード
- データがコンテナに直接ストリーミングされます。トレーニングジョブのパフォーマンスが向上します。
- トレーニングジョブによって Amazon S3 内のデータが直接ストリーミングされます。
- データがストリーミングされることにより、トレーニングジョブがより早く開始され、また、スループットが向上します。
- トレーニングインスタンス用 Amazon EBS ボリュームのサイズが小さくなります。
結果
合格